利用python实现《数据挖掘——概念与技术》一书中描述的Apriori算法
from itertools import combinations data = [['I1', 'I2', 'I5'], ['I2', 'I4'], ['I2', 'I3'], ['I1', 'I2', 'I4'], ['I1', 'I3'],
['I2', 'I3'], ['I1', 'I3'], ['I1', 'I2', 'I3', 'I5'], ['I1', 'I2', 'I3']] # 候选集生成
# 输入:
# f_set: k-1项集, k:项集个数
# 输出:
# k_cand:k项候选集
def apriori_gen(f_set, k):
k_cand = []
temp = [frozenset(l) for l in combinations(f_set, k)]
for t in temp:
if has_infrequent_subset(t, f_set):
del t
else:
k_cand.append(t)
return k_cand # 非频繁项集的超集也是非频繁的
def has_infrequent_subset(c_set, f_set):
for subset in c_set:
if not frozenset([subset]).issubset(f_set):
return True
return False # 输入(绝对)最小支持度, min_sup
# 输出:全部频繁项集(不包括一项集), all_f_set
def get_f_set(min_sup=2):
all_f_set = []
L1 = frozenset([d for ds in data for d in ds])
k = 2
size = len(L1)
while k <= size:
c_k = frozenset(apriori_gen(L1, k))
for c in c_k:
count = 0
for d in data:
if c.issubset(frozenset(d)):
count += 1
if count >= min_sup:
all_f_set.append((c, count))
k += 1
return all_f_set if __name__ == '__main__':
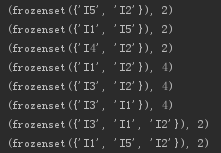
all_frequent_set = get_f_set()
for i in all_frequent_set:
print(i)
利用python实现《数据挖掘——概念与技术》一书中描述的Apriori算法的更多相关文章
- 从《数据挖掘概念与技术》到《Web数据挖掘》
从<数据挖掘概念与技术>到<Web数据挖掘> 认真读过<数据挖掘概念与技术>的第一章后,对数据挖掘有了更加深刻的了解.数据挖掘是知识发展过程的一个步骤.知识发展的过 ...
- 数据挖掘入门系列教程(四点五)之Apriori算法
目录 数据挖掘入门系列教程(四点五)之Apriori算法 频繁(项集)数据的评判标准 Apriori 算法流程 结尾 数据挖掘入门系列教程(四点五)之Apriori算法 Apriori(先验)算法关联 ...
- 【EatBook】-NO.2.EatBook.2.JavaArchitecture.1.001-《修炼Java开发技术在架构中体验设计模式和算法之美》-
1.0.0 Summary Tittle:[EatBook]-NO.2.EatBook.2.JavaArchitecture.1.001-<修炼Java开发技术在架构中体验设计模式和算法之美&g ...
- 利用 Python 练习数据挖掘
本文由 伯乐在线 - 顾星竹 翻译,Namco 校稿.未经许可,禁止转载!英文出处:Giuseppe Vettigli.欢迎加入翻译组. 覆盖使用Python进行数据挖掘查找和描述数据结构模式的实践工 ...
- 【读书笔记-数据挖掘概念与技术】数据仓库与联机分析处理(OLAP)
之前看了认识数据以及数据的预处理,那么,处理之后的数据放在哪儿呢?就放在一个叫“数据仓库”的地方. 数据仓库的基本概念: 数据仓库的定义——面向主题的.集成的.时变的.非易失的 操作数据库系统VS数据 ...
- 数据挖掘概念与技术15--为快速高维OLAP预计算壳片段
1. 论数据立方体预计算的多种策略的优弊 (1)计算完全立方体:需要耗费大量的存储空间和不切实际的计算时间. (2)计算冰山立方体:优于计算完全立方体,但在某种情况下,依然需要大量的存储空间和计算时间 ...
- 《修炼Java开发技术 在架构中体验设计模式和算法之美》 - 书摘精要
(P7) 建议直接加入到软件公司中去,这样会学到很多实际的东西: 程序员最主要的发展方向是资深技术专家,无论是 Java..Net 还是数据库领域,都要首先成为专家,然后才可能继续发展为架构师: 增强 ...
- 利用Python进行数据分析_Pandas_数据加载、存储与文件格式
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 1 pandas读取文件的解析函数 read_csv 读取带分隔符的数据,默认 ...
- 利用Python进行数据分析_Pandas_层次化索引
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 层次化索引主要解决低纬度形式处理高纬度数据的问题 import pandas ...
随机推荐
- Maven学习篇一:eclipse构建运行maven web项目
1.new->other->maven project->next 2.选择创建简单项目(或者直接去掉勾,在后面选择maven-archetype-webapp) 3.设置坐标,名称 ...
- html-框架标签的使用
<frameset> - rows:按照行进行划分 ** <frameset rows="80,*"> - cols:按照列进行划分 ** <fram ...
- 再学UML-Bug管理系统UML2.0建模实例(一)
1.项目概述 随着软件项目规模和复杂性的增大,有效跟踪和管理项目中存在的缺陷Bug变得越来越重要.每一个软件企业都需要妥善处理软件中的缺陷,这将直接关系到软件过程质量与软件产品质量,但并非 ...
- laravel 接入蚂蚁金服SDK(以支付宝APP支付为例)开发步骤
一.创建应用及配置 首先需要到蚂蚁金服开放平台(https://docs.open.alipay.com)注册应用,获取应用id(APP_ID),并且配置应用,主要是签约应用,这个需要审核,一般2-5 ...
- Sendip 命令行发包工具,支持IP、TCP、UDP等
Sendip是一个linux平台的命令行发数据包工具,目前(2018年2月)支持的协议有ipv4.ipv6.icmp.tcp.udp.bgp.rip.ntp,作者表示其他协议将会后面支持,当他有空写的 ...
- 关于GitHubGit
一.Github项目地址:https://github.com/gyguyt/Helloworld123 二.什么是Github? Git是一款免费.开源的分布式版本控制系统,用于敏捷高效地处理任何或 ...
- POJ-3104 Drying---二分答案判断是否可行
题目链接: https://cn.vjudge.net/problem/POJ-3104 题目大意: 有一些衣服,每件衣服有一定水量,有一个烘干机,每次可以烘一件衣服,每分钟可以烘掉k滴水.每件衣服每 ...
- IOS开发之——IOS模拟器调试蓝牙BLE
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/zhenyu5211314/article/details/24399887 因为在iPhone 4s ...
- lua 语句学习
就如同C里的if else,while,do,repeat.就看lua里怎么用: 1.首先看if else t = {1,2,3} local i = 1 if t[i] and t[i] % 2 = ...
- python:进程操作
一.多进程应用 import socket from multiprocessing import Process def talk(conn): conn.send(b'connected') re ...