论文讨论&&思考《Deformable Convolutional Networks》
这篇论文真是让我又爱又恨,可以说是我看过的最认真也是最多次的几篇paper之一了,首先deformable conv的思想我觉得非常好,通过end-to-end的思想来做这件事也是极其的make sense的,但是一直觉得哪里有问题,之前说不上来,最近想通了几点,先初步说几句,等把他们的代码跑通并且实验好自己的几个想法后可以再来聊一聊。首先我是做semantic segmentation的,所以只想说说关于这方面的问题。
直接看这篇paper的话可能会觉得ji feng的这篇工作非常棒,但实际上在我看来还是噱头多一点(我完全主观的胡说八道),deformable conv是STN和DFF两篇工作的结合,前者提供了bilinear sample的思路和具体的bp,后者提供了warp的思路和方法,不过好像说的也不是很准确。。我暂时的理解是这样的:deformable conv就是把deep feature flow中的flow换成了可学习的offset。接下来分为亮点和槽点来说一说。
一、亮点
亮点说实话还是很多的,首先解决了STN(spatial transform network)的实用性问题,因为STN是对整个feature map做transform的动作,例如学习出一个linear transform的 matrix,这个在做minist的时候当然是极其合理的,但是在真实世界中,这个动作不仅不合理而且意义不大的,因为复杂场景下的信息很多,背景也很多,那么它是怎么做的呢?
首先我想先说一个很重要的误区,很多人以为deformable conv学习的是个deformabe 的kernel,比方说本来是一个3*3相互连接的kernel,最后变成了一个没个位置都有一个offset的kernel。实际情况并不是这样的,作者并没有对kernel学习offset,而是对feature的每个位置学习一个offset,一步一步的解释就是:首先有一个原始的feature map F,在上面做channel为18的3*3的卷积,得到channel=18的feature map F_offset,然后再对F做deformable conv并且传入offset 的值F_offset,在新得到的结果上,每个值对应原来的feature map F上是从一个3*3的kernel上计算得到的,每个值对应的F上的3*3的区域上的每个值都有x、y方向上的两个offset,这3*3*2=18的值就由刚才传入的F_offset决定。。。。貌似说的有点绕,其实理清楚关键的一点就是:学习出来的offset是channel=18并且和原 feature map一样大小的,对应的是main branch上做deformable conv时候每位置上的kernel的每个位置的offset。
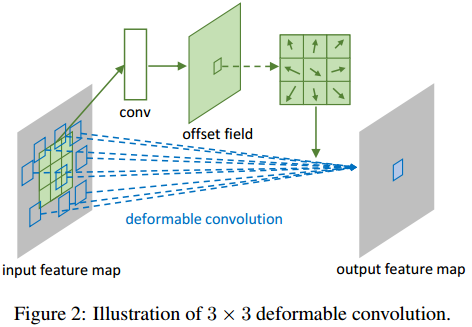
知乎上有个人说了一句我特别赞同的话:用bilinear的方法代替weight的方法,即用采样代替权重的方法。这个思维是可以发散开来做更多的工作的,这也是我觉得这篇paper最棒的地方。
二、槽点
这个其实我今天写篇blog的重点。。。我对offset能否学习到极其的的不看好,虽然最后还要看实验的效果和实际的结果,当我想说两点。
1、从feature的需求来看,senmantic segmentation对于feature的需求是跟detection不同的,这个问题其实jifeng Dai和kaiming的R-FCN中都提到过,然后semantic segmentation需要的feature不会过于关注什么旋转平移不变性,也就是物体的旋转平移对结果是有影响的,他们对position是care的,这个问题有时间我想再看看R-FCN讨论一发,因此这里直接用feature 通过一层卷积就可以学习到offset,我是怀疑的。
2.上面的怀疑其实有点没道理,这次有个稍微有那么一丢丢的怀疑,bilinear sample其实是一个分段线性函数,所以逻辑上在bp的时候,你要想你的目的是让loss下降的话,就不能让你的step太大以至于超过来当前的线性区间,也就是你在当前四个点中算出来梯度,如果你更新后跳到另外四个点上来,理论上这次的gradient的更新就是错误的,loss是不一定下降的,但是话说回来,如果不跳到另外四个点,这个offset永远限制在当前四个点里面的话,也是毫无意义的。话再说回来,因为整个feature map还是smooth的,这也跟图像的性质有关,所以我们还是比较相信只要你的lr不是很大,loss还是会下降的。
三、总结
总的来说这是一篇很有意义的工作,在我看来,任何能启发之后的工作和引起人思考的工作都是很有意义的,无论它work不work,在benchmark跑的怎么样。
还有些东西我想等实验跑完再来说说,所以待续~
论文讨论&&思考《Deformable Convolutional Networks》的更多相关文章
- 图像处理论文详解 | Deformable Convolutional Networks | CVPR | 2017
文章转自同一作者的微信公众号:[机器学习炼丹术] 论文名称:"Deformable Convolutional Networks" 论文链接:https://arxiv.org/a ...
- 目标检测论文阅读:Deformable Convolutional Networks
https://blog.csdn.net/qq_21949357/article/details/80538255 这篇论文其实读起来还是比较难懂的,主要是细节部分很需要推敲,尤其是deformab ...
- 论文阅读笔记三十八:Deformable Convolutional Networks(ECCV2017)
论文源址:https://arxiv.org/abs/1703.06211 开源项目:https://github.com/msracver/Deformable-ConvNets 摘要 卷积神经网络 ...
- 深度学习方法(十三):卷积神经网络结构变化——可变形卷积网络deformable convolutional networks
上一篇我们介绍了:深度学习方法(十二):卷积神经网络结构变化--Spatial Transformer Networks,STN创造性地在CNN结构中装入了一个可学习的仿射变换,目的是增加CNN的旋转 ...
- Deformable Convolutional Networks
1 空洞卷积 1.1 理解空洞卷积 在图像分割领域,图像输入到CNN(典型的网络比如FCN)中,FCN先像传统的CNN那样对图像做卷积再pooling,降低图像尺寸的同时增大感受野,但是由于图像分割预 ...
- VGGNet论文翻译-Very Deep Convolutional Networks for Large-Scale Image Recognition
Very Deep Convolutional Networks for Large-Scale Image Recognition Karen Simonyan[‡] & Andrew Zi ...
- [论文理解] Learning Efficient Convolutional Networks through Network Slimming
Learning Efficient Convolutional Networks through Network Slimming 简介 这是我看的第一篇模型压缩方面的论文,应该也算比较出名的一篇吧 ...
- 论文学习:Fully Convolutional Networks for Semantic Segmentation
发表于2015年这篇<Fully Convolutional Networks for Semantic Segmentation>在图像语义分割领域举足轻重. 1 CNN 与 FCN 通 ...
- [论文阅读]VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION(VGGNet)
VGGNet由牛津大学的视觉几何组(Visual Geometry Group)提出,是ILSVRC-2014中定位任务第一名和分类任务第二名.本文的主要贡献点就是使用小的卷积核(3x3)来增加网络的 ...
随机推荐
- python 函数 练习
# 2.写函数,接收n个数字,求这些参数数字的和. def sum_func(*args): total = 0 for i in args: total += i return total prin ...
- 嵌入式框架Zorb Framework搭建四:状态机的实现
我是卓波,我是一名嵌入式工程师,我万万没想到我会在这里跟大家吹牛皮. 嵌入式框架Zorb Framework搭建过程 嵌入式框架Zorb Framework搭建一:嵌入式环境搭建.调试输出和建立时间系 ...
- Python3爬虫(六) 解析库的使用之Beautiful Soup
Infi-chu: http://www.cnblogs.com/Infi-chu/ Beautiful Soup 借助网页的结构和属性等特性来解析网页,这样就可以省去复杂的正则表达式的编写. Bea ...
- 【SAPUI5】ODataを構成するもの
はじめに SAPUI5でアプリケーションを作るにあたり.ODataは避けては通れないトピックです.結構広いテーマなので.5-7回くらいに分けて書きたいと思います.1回目はODataの概要について説明し ...
- 数据库 MySQL part2
表记录的操作 增 1.插入一条记录 语法:insert [into] tab_name (field1,filed2,.......) values (value1,value2,.......); ...
- struts2官方 中文教程 系列七:消息资源文件
介绍 在本教程中,我们将探索使用Struts 2消息资源功能(也称为 resource bundles 资源绑定).消息资源提供了一种简单的方法,可以将文本放在一个视图页面中,通过应用程序,创建表单字 ...
- linux mysql root 忘记密码了,完美解决-费元星站长
修改MySQL的配置文件(默认为/etc/my.cnf),在[mysqld]下添加一行skip-grant-tables 保存配置文件后,重启MySQL服务 service mysqld rest ...
- Anytime项目开发记录0
Anytime,中文名:我很忙. 开发者:孤独的猫咪神. 这个项目会持续更新,直到我决定不再维护这个APP. 2014年3月10日:近日有事,暂时断更.希望可以会尽快完事. 2014年3月27日:很抱 ...
- 「日常训练」Greedy Arkady (CFR476D2C)
不用问为啥完全一致,那个CSDN的也是我的,我搬过来了而已. 题意(Codeforces 965C) $k$人分$n$个糖果,每个糖果至多属于1个人.A某人是第一个拿糖果的.(这点很重要!!) 他$x ...
- Qt 在Label上面绘制罗盘
自己写的一个小小的电子罗盘的一个小程序,不过是项目的一部分,只可以贴绘制部分代码 效果如下图 首先开始自己写的时候,虽然知道Qt 的坐标系是从左上角开始的,所以,使用了算法,在绘制后,在移动回来,但是 ...