scrapy shell命令的【选项】简介
在使用scrapy shell测试某网站时,其返回400 Bad Request,那么,更改User-Agent请求头信息再试。
DEBUG: Crawled () <GET https://www.某网站.com> (referer: None)
可是,怎么更改呢?
使用scrapy shell --help命令查看其用法:
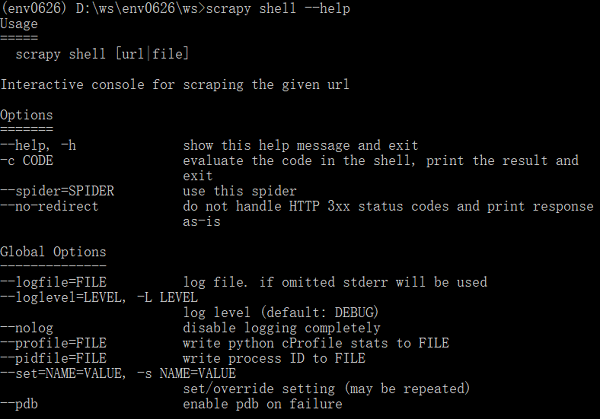
Options中没有找到相应的选项;
Global Options呢?里面的--set/-s命令可以设置/重写配置。
使用-s选项更改了User-Agent配置,再测试某网站,成功返回页面(状态200):
...>scrapy shell -s USER_AGENT="Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36" https://www.某网站.com
2018-07-15 12:11:00 [scrapy.core.engine] DEBUG: Crawled () <GET https://www.某网站.com> (referer: None)
--------翻篇--------
说明,其实,这个-s的用法并非自己通过上面步骤知道的(之前一直关注Options下面的选项,忽略了Global Options,觉得没用吗?),而是通过网页搜索,然后见到下面的文章:
scrapy shell 用法(慢慢更新...) 原文作者:木木&侃侃(一位园友,原文链接)

更进一步:在Scrapy的源码中会对相关配置项有更详细的信息。
打开C:\Python36\Lib\site-packages\scrapy\commands目录,可以在里面看到各种内置的Scrapy命令的Python文件,其中,shell.py正是scrapy shell命令的源文件。

从源码可以看到,里面定义了Command类——继承了scrapy.commands.ScrapyCommand,在Command的add_options函数中,添加了三个选项:
-c:evaluate the code in the shell, print the result and exit(执行一段解析代码?)
--spider:use this spider
--no-redirect:do not handle HTTP 3xx status codes and print response as-is
没有发现-s选项,那么,-s选项来自哪儿呢?看看scrapy.commands.ScrapyCommand的源码(__init__.py文件中)。可以发现,其下的add_options函数中添加了-s选项:
def add_options(self, parser):
"""
Populate option parse with options available for this command
"""
group = OptionGroup(parser, "Global Options")
group.add_option("--logfile", metavar="FILE",
help="log file. if omitted stderr will be used")
group.add_option("-L", "--loglevel", metavar="LEVEL", default=None,
help="log level (default: %s)" % self.settings['LOG_LEVEL'])
group.add_option("--nolog", action="store_true",
help="disable logging completely")
group.add_option("--profile", metavar="FILE", default=None,
help="write python cProfile stats to FILE")
group.add_option("--pidfile", metavar="FILE",
help="write process ID to FILE")
group.add_option("-s", "--set", action="append", default=[], metavar="NAME=VALUE",
help="set/override setting (may be repeated)")
group.add_option("--pdb", action="store_true", help="enable pdb on failure") parser.add_option_group(group)
好了,源头找到了。
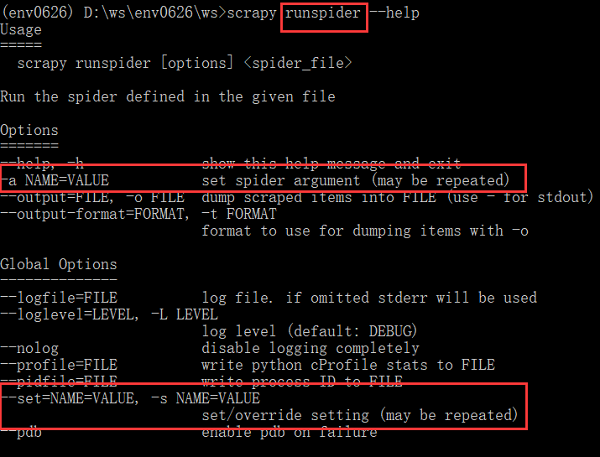
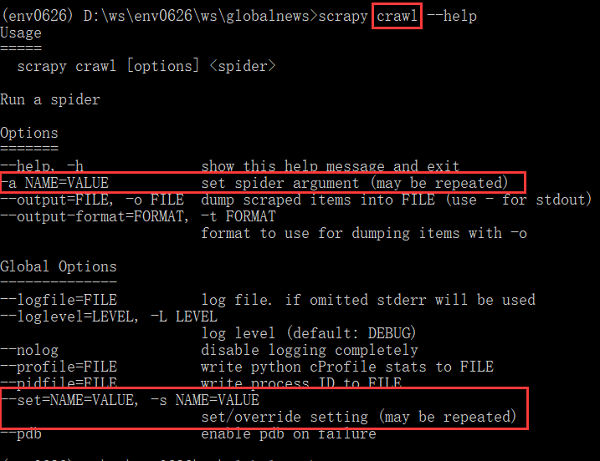
可是,之前在寻找方法时发现,scrapy crawl、runspider提供了-a选项来设置/重写配置,可是,已经有了-s选项了,为何还要增加-a选项呢?两者有什么区别?
从其解释来看,-a选项仅仅修改spider的参数,而-s可以设置的范围更广泛,包括官文Settings中所有配置吧!(未测试)
parser.add_option("-a", dest="spargs", action="append", default=[], metavar="NAME=VALUE",
help="set spider argument (may be repeated)")
--------翻篇--------
实践1:scrapy shell的-c选项
(env0626) D:\ws\env0626\ws>scrapy shell -c "response.xpath('//title/text()')" https://www.baidu.com
输出:
2018-07-15 13:07:23 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.baidu.com> (referer: None)
[<Selector xpath='//title/text()' data='百度一下,你就知道'>]
实践2:scrapy runspider -a选项和-s选项修改User-Agent请求头
# -*- coding: utf-8 -*-
import scrapy class MousiteSpider(scrapy.Spider):
name = 'mousite'
allowed_domains = ['www.zhihu.com']
start_urls = ['https://www.zhihu.com/'] def parse(self, response):
yield response.xpath('//title/text()')
测试结果:-a选项无法获取数据,返回400;-s选项可以,返回200;
-a选项:
(env0626) D:\ws\env0626\ws>scrapy runspider -a USER_AGENT="Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36" mousite.py
DEBUG: Crawled (400) <GET https://www.zhihu.com/> (referer: None)
INFO: Ignoring response <400 https://www.zhihu.com/>: HTTP status code is not handled or not allowed
-s选项:
(env0626) D:\ws\env0626\ws>scrapy runspider -s USER_AGENT="Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36" mousite.py
DEBUG: Crawled (200) <GET https://www.zhihu.com/> (referer: None)
{'title': [<Selector xpath='//title/text()' data='知乎 - 发现更大的世界'>]}
看来,两者还是有差别的。
注意,上面的试验都是在Scrapy项目外执行()。
scrapy shell命令的【选项】简介的更多相关文章
- 在Scrapy项目【内外】使用scrapy shell命令抓取 某网站首页的初步情况
Windows 10家庭中文版,Python 3.6.3,Scrapy 1.5.0, 时隔一月,再次玩Scrapy项目,希望这次可以玩的更进一步. 本文展示使用在 Scrapy项目内.项目外scrap ...
- Linux下shell命令执行过程简介
Linux是如何寻找命令路径的:http://c.biancheng.net/view/5969.html Linux上命令运行的基本过程:https://blog.csdn.net/hjx5200/ ...
- 安装ipython,使用scrapy shell来验证xpath选择的结果 | How to install iPython and how does it work with Scrapy Shell
1. scrapy shell 是scrapy包的一个很好的交互性工具,目前我使用它主要用于验证xpath选择的结果.安装好了scrapy之后,就能够直接在cmd上操作scrapy shell了. 具 ...
- scrapy shell 用法(慢慢更新...)
scrapy shell 命令 1.scrapy shell url #url指你所需要爬的网址 2.有些网址数据的爬取需要user-agent,scrapy shell中可以直接添加头文件, 第①种 ...
- Scrapy的shell命令(转)
scrapy python MrZONT 2015年08月29日发布 ...
- Scrapy命令行工具简介
Windows 10家庭中文版,Python 3.6.4,virtualenv 16.0.0,Scrapy 1.5.0, 在最初使用Scrapy时,使用编辑器或IDE手动编写模块来创建爬虫(Spide ...
- 4-3 调试代码命令 scrapy shell http://blog.jobbole.com/114496/(入口url)
调试代码命令 scrapy shell http://blog.jobbole.com/114496/(入口url)
- linux + shell 命令等
Linux命令[注意:建议用UltraEdit打开] 一.文件处理命令 1.命令格式与目录处理命令 ls –a[查看隐藏文件] ls –l[查看文件信息长格式显示] ls –d[查看指定目录的详细信息 ...
- VxWorks操作系统shell命令与调试方法总结
VxWorks下的调试手段 主要介绍在Tornado集成开发环境下的调试方法,和利用支撑定位问题的步骤.思路. 1 Tornado的调试工具 嵌入式实时操作系统VxWorks和集成开发 ...
随机推荐
- ZJOI 2018 一试记
ZJOI一试几天,天微冷,雨.倒是考试当天近午时分出了太阳. 开题前的一刻,心情反而平静了,窗外泛着淡金色的日光照进来,仿佛今天的我并不是所谓来冲击省队,而只是来经历一场洗礼. 开题了,虽然有一点小插 ...
- CF321E Ciel and Gondolas 【决策单调性dp】
题目链接 CF321E 题解 题意:将\(n\)个人分成\(K\)段,每段的人两两之间产生代价,求最小代价和 容易设\(f[k][i]\)表示前\(i\)个人分成\(k\)段的最小代价和 设\(val ...
- Java考试题之六
QUESTION 134 Given:11. class Snoochy {12. Boochy booch;13. public Snoochy() { booch = new Boochy(thi ...
- kafka 多线程消费
一. 1.Kafka的消费并行度依赖Topic配置的分区数,如分区数为10,那么最多10台机器来并行消费(每台机器只能开启一个线程),或者一台机器消费(10个线程并行消费).即消费并行度和分区数一致. ...
- php 中的错误处理机制
php 里有一套错误处理机制,可以使用 set_error_handler 接管 php 错误处理,也可以使用 trigger_error 函数主动抛出一个错误. set_error_handler( ...
- ROI align解释
转自:blog.leanote.com/post/afanti.deng@gmail.com/b5f4f526490b ROI Align 是在Mask-RCNN这篇论文里提出的一种区域特征聚集方式, ...
- python---方法解析顺序MRO(Method Resolution Order)<以及解决类中super方法>
MRO了解: 对于支持继承的编程语言来说,其方法(属性)可能定义在当前类,也可能来自于基类,所以在方法调用时就需要对当前类和基类进行搜索以确定方法所在的位置.而搜索的顺序就是所谓的「方法解析顺序」(M ...
- bzoj千题计划122:bzoj1034: [ZJOI2008]泡泡堂BNB
http://www.lydsy.com/JudgeOnline/problem.php?id=1034 从小到大排序后 最大得分: 1.自己最小的>对方最小的,赢一场 2.自己最大的>对 ...
- 翻译: 星球生成 II
翻译: 星球生成 II 本文翻译自Planet Generation - Part II 译者: FreeBlues 以下为译文: 概述 在前一章 我解释了如何为星球创建一个几何球体. 在本文中, 我 ...
- ECMAScript6语法检查规范错误信息说明
项目中使用ECMAScript6的时候经查会使用语法检查,下面是常见错误信息的汇总: “Missing semicolon.” : “缺少分号.”, “Use the function form of ...