python 把一文件包含中文的字符写到另外文件乱码 UnicodeDecodeError: 'gbk' codec can't decode byte 0xac in position
报错的代码是:
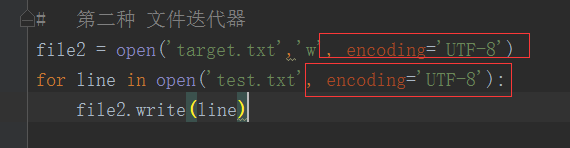
file2 = open('target.txt','w')
for line in open('test.txt'):
file2.write(line)
原因:文件编码不一致导致
解决方案: 加上编码限制
python 把一文件包含中文的字符写到另外文件乱码 UnicodeDecodeError: 'gbk' codec can't decode byte 0xac in position的更多相关文章
- 【python】python读取文件报错UnicodeDecodeError: 'gbk' codec can't decode byte 0xac in position 2: illegal multibyte sequence
python读取文件报错UnicodeDecodeError: 'gbk' codec can't decode byte 0xac in position 2: illegal multibyte ...
- python 读取文件时报错UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 205: illegal multib
python 读取文件时报错UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 205: illegal multib ...
- python 读取文件时报错UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 205: illegal multibyte sequence
python读取文件时提示"UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 205: illegal m ...
- python 读取文件时报错: UnicodeDecodeError: 'gbk' codec can't decode byte 0xa4 in position 127: illegal multibyte sequence
UnicodeDecodeError: 'gbk' codec can't decode byte 0xa4 in position 127: illegal multibyte sequence p ...
- Python读取CSV文件,报错:UnicodeDecodeError: 'gbk' codec can't decode byte 0xa7 in position 727: illegal multibyte sequence
Python读取CSV文件,报错:UnicodeDecodeError: 'gbk' codec can't decode byte 0xa7 in position 727: illegal mul ...
- Python文件访问编码格式问题UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position xx: 解决方案
1.Python读取文件 # .打开文件 file = open("ReadMe") # .读取文件类容 text = file.read() print(text) # .关闭文 ...
- python读取txt文件时报错UnicodeDecodeError: 'gbk' codec can't decode byte 0x8e in position 8: illegal multibyte sequence
python读取文件时报错UnicodeDecodeError: 'gbk' codec can't decode byte 0x8e in position 8: illegal multibyte ...
- Python读取文件时出现UnicodeDecodeError 'gbk' codec can't decode byte 0x80 in position x
Python在读取文件时 with open('article.txt') as f: # 打开新的文本 text_new = f.read() # 读取文本数据出现错误: UnicodeDecode ...
- Python读取文件时出现UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position xx: 解决方案
Python在读取文件时 with open('article.txt') as f: # 打开新的文本 text_new = f.read() # 读取文本数据 出现错误: UnicodeDecod ...
随机推荐
- PAT甲 1012. The Best Rank (25) 2016-09-09 23:09 28人阅读 评论(0) 收藏
1012. The Best Rank (25) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue To eval ...
- LoadRunner 技巧之 IP欺骗 (推荐)
IP欺骗也是也loadrunner自带的一个非常有用的功能. 需要使用ip欺骗的原因:1.当某个IP的访问过于频繁,或者访问量过大是,服务器会拒绝访问请求,这时候通过IP欺骗可以增加访问频率和访问量, ...
- ActiveMq 配置多队列
一直在赶项目,好久没有写博文了,中间偶尔有些代码什么的,也都是放到github了,不过大多都是测试代码,毕竟有些成型的东西是给公司写的,鉴于职业道德,还是不好公开. 言归正传,这两天在接入第三方的收费 ...
- python 判断是否为中文
python在执行代码过程是不知道这个字符是什么意思的.是否是中文,而是把所有代码翻译成二进制也就是000111这种形式,机器可以看懂的语言. 也就是在计算机中所有的字符都是有数字来表示的.汉字也是有 ...
- Redis Sentinel基本介绍(翻译以及总结)
目录 Redis Sentinel介绍 分布式的Redis Sentinel 快速开始 获取Sentinel 启动Sentinel 部署Sentinel的基本要求 配置Sentinel 其他的Sent ...
- 解决EF没有生成字段和表说明
找了很多资料,终于找到一篇真正能解决ef生成字段说明,注释的文章,收藏不了,于是转载 本文章为转载,原文地址 项目中使用了EF框架,使用的是Database-First方式,因为数据库已经存在,所以采 ...
- ASP .Net Core路由(Route) - 纸壳CMS的关键
关于纸壳CMS 纸壳CMS是一个开源免费的,可视化设计,在线编辑的内容管理系统.基于ASP .Net Core开发,插件式设计: GitHub:https://github.com/SeriaWei/ ...
- NetCore入门篇:(三)Net Core项目Nuget及Bower包管理
一.创建项目 1.如何创建项目,参照上一篇文章 二.程序包介绍 1.Net Core的程序包分前后端两种,后端用nuget,前端用bower. 2.与Net 不同,Net Core引用nuget包时, ...
- C# 成员变量和属性的区别
之前一直在C#中使用这两者, 却一直不知道成员变量和属性还是不一样的两种概念. 不过说不一样, 也不是完全对. 简单举个例子: public class myclass { public string ...
- winform :DataGridView添加一列checkbox
#region 添加checkbox列 public void AddCheckBox() { DataGridViewCheckBoxColumn columncb = new D ...