Virtual DOM的简单实现
了解React的同学都知道,React提供了一个高效的视图更新机制:Virtual DOM,因为DOM天生就慢,所以操作DOM的时候要小心翼翼,稍微改动就会触发重绘重排,大量消耗性能。
1.Virtual DOM
Virtual DOM是利用JS的原生对象来模拟DOM,既然DOM是对象,我们也可以用原生的对象来表示DOM。
var element = {tagName: 'ul', // 节点标签名props: {class: 'list' // 节点的属性,ID,class...},children: [ // 该节点的子节点{tagName: 'li', props: {class: 'item'}, children: ['item one']},{tagName: 'li', props: {class: 'item'}, children: ['item two']},{tagName: 'li', props: {class: 'item'}, children: ['item three']}]}
对应成相应的HTML结构为:
<ul class="list"><li class="item">item one</li><li class="item">item two</li><li class="item">item three</li></ul>
但是这又有什么用呢?不还是要操作DOM吗?
开头我们就说过,Virtual DOM是一个高效的视图更新机制,没错,主要在更新。怎么更新呢,那就要用到了我们之前用JS对象模拟的DOM树了,就叫它对象树把,我们对比前后两棵对象树,比较出需要更新视图的地方,对需要更新视图的地方才进行DOM操作,不需要更新的地方自然什么都不做,这就避免了性能的不必要浪费,变相的提升了性能。
总之Virtual DOM算法主要包括这几步:
初始化视图的时候,用原生JS对象表示DOM树,生成一个对象树,然后根据这个对象树来生成一个真正的DOM树,插入到文档中。
当状态更新的时候,重新生成一个对象树,将新旧两个对象树做对比,记录差异。
把记录的差异应用到第一步生成的真正的DOM树上,视图跟新完成
其实就是一个双缓冲的原理,既然CPU这么快,读取硬盘又这么慢,我们就在中间加一个Cache。那么,既然DOM操作也慢,我们们就可以在JS和DOM之间也加一个Cache,这个Cache就是我们的Virtual DOM了。
其实说白了Virtual DOM的原理就是只更新需要更新的地方,其他的一概不管。
2.用对象树表示DOM树
用JS对象表示DOM节点还是比较容易的,我们这需要记录DOM节点的节点类型、属性、还有子节点就好了。
class objectTree {constructor (tagName, props, children) {this.tagName = tagNamethis.props = propsthis.children = children}}
我们可以通过这种方式创建一个对象树:
var ul = new objectTree('ul', {id: 'list'}, [createObjectTree('li', {class: 'item'}, ['Item 1']),createObjectTree('li', {class: 'item'}, ['Item 2']),createObjectTree('li', {class: 'item'}, ['Item 3'])])
对象树存在一个render方法来将对象树转换成真正的DOM树:
objectTree.prototype.render = function () {var elm = document.createElement(this.tagName)var props = this.props// 设置DOM节点的属性for (var key in props) {elm.setAttribute(key, props[key])}var children = this.children || []children.forEach((child) => {// 如果子节点也是对象树,则递归渲染,否则就是文本节点var childElm = (child instanceof objectTree) ? child.render() : document.createTextNode(child)elm.appendChild(childElm)})return elm}
我们就可以将生成好的DOM树插入到文档里了
var ul = new objectTree('ul', {id: 'list'}, [new objectTree('li', {class: 'item'}, ['Item 1']),new objectTree('li', {class: 'item'}, ['Item 2']),new objectTree('li', {class: 'item'}, ['Item 3'])])console.log(ul)document.body.appendChild(ul.render())
我们生成的DOM已经添加到文档里了
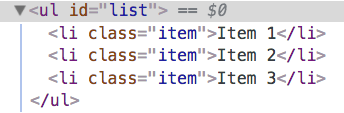
3.比较两个对象树的差异
所谓Virtual DOM的diff算法,就是比较两个对象树的差异,也正是Virtual DOM的核心。
传统的比较两棵树差异的算法,时间复杂度是O(n^3),大量操作DOM的时候肯定是接受不了的。所以React做了妥协,React结合WEB界面的特点,做了两个简单的假设,使得算法的复杂度降低到了O(n)。
相同的组件产生相似的DOM树,不同的组件产生不同的DOM树。
对于同一层次的一组子节点,它们可以通过唯一的id进行区分。
不同节点类型的比较
不同节点类型分为两种情况:
节点类型不同。
节点类型相同,但是属性不同。
先看第一种情况,如果是我们会怎么做呢?肯定是直接删除老的节点,然后在老节点的位置上将新节点插入。React也和我们的想法一样,也符合我们对真实DOM操作的理解。
如果将老节点删除,那么老节点的子节点也同时被删除,并且子节点也不会参与后续的比较。这也是算法复杂度能降低到O(n)的原因之一。
既然节点类型不同是这样操作的,那么组件也是一样的逻辑了。应用第一个假设,不同组件之间有不同的DOM树,与其花时间比较它们的DOM结构,还不如创建一个新的组件加到原来的组件上。
从不同节点的操作上我们可以推断,React的diff算法是只对对象树逐层比较。
逐层进行节点比较
在React中对树的算法非常简单,那就是对两棵树同一层次的节点进行比较。
有一张非常经典的图:
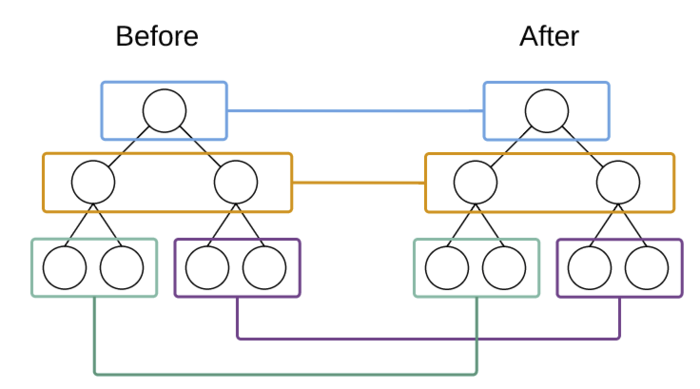
React只会对相同颜色方框内的DOM节点进行比较,即同一个父节点下的所有子节点。当发现节点已经不存在,则该节点及其子节点会被完全删除掉,不会用于进一步的比较。这样只需要对树进行一次遍历,便能完成整个DOM树的比较。
考虑下如果有这样的DOM结构的变化:

我们想的操作是:R.remove(A), D.append(A)
但是因为React只会对同一层次的节点进行比较,当发现新的对象树中没有A节点时,就会完全删除A,同理,会新创建一个A节点作为D的子节点。实际React的操作是:A.destroy(), A = new A(), A.append(new B()), A.append(new C()), D.append(A)
由此我们可以根据React只对同一层次的节点比较可以作出的优化是:尽量不要跨层级的修改DOM。
相同节点类型的比较
刚才我们说过,相通节点类型属性可能不同,React会对属性进行重设,但要注意:Virtual DOM中style必须是个对象。
renderA: <div style={{color: 'red'}} />renderB: <div style={{fontWeight: 'bold'}} />=> [removeStyle color], [addStyle font-weight 'bold']
key值的使用
我们经常在遍历一个数组或列表需要一个标识一个唯一的key,这个key是干什么的呢?
这是初始视图:
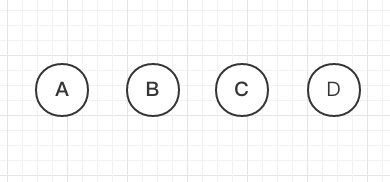
我们现在想在它们中间加一个F,也就是一个insert操作。
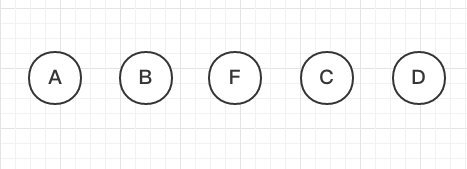
如果每个节点没有一个唯一的key,React不能识别每个节点,那React就会将C更新成F,将D更新成C,最后在末尾插入一个D。
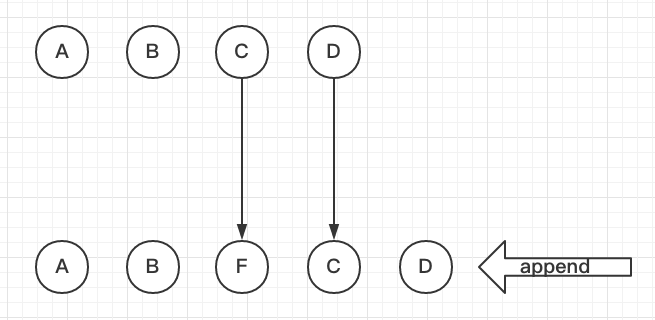
如果每个节点有一个唯一的key做标识,React会找到正确的位置去插入新的节点,从而提高了视图更新的效率。
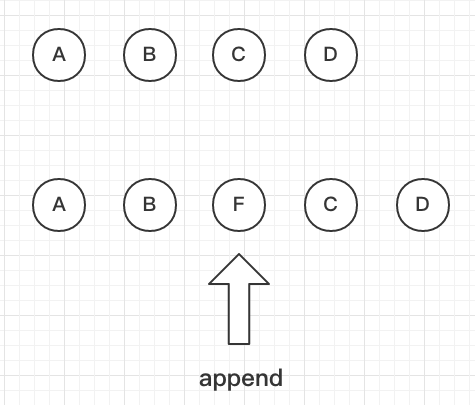
对于key我们可以给出的优化是:给每个列表元素加上一个唯一的key
4.diff算法的简单实现
我们先对两棵对象树做一个深度优先的遍历,这样每一个节点都有一个唯一的标记:
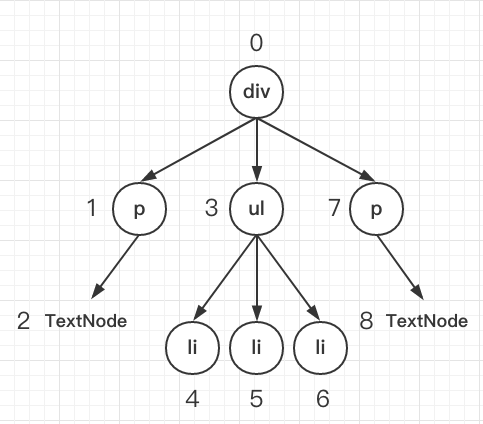
在深度优先遍历的时候,每遍历到一个节点就把该节点和新的的树进行对比。如果有差异的话就记录到一个对象里面。
// diff 函数,对比两棵树function diff (oldTree, newTree) {var index = 0 // 当前节点的标志var patches = {} // 用来记录每个节点差异的对象dfsWalk(oldTree, newTree, index, patches)return patches}// 对两棵树进行深度优先遍历function dfsWalk (oldNode, newNode, index, patches) {// 对比oldNode和newNode的不同,记录下来patches[index] = [...]diffChildren(oldNode.children, newNode.children, index, patches)}// 遍历子节点function diffChildren (oldChildren, newChildren, index, patches) {var leftNode = nullvar currentNodeIndex = indexoldChildren.forEach(function (child, i) {var newChild = newChildren[i]currentNodeIndex = (leftNode && leftNode.count) // 计算节点的标识? currentNodeIndex + leftNode.count + 1: currentNodeIndex + 1dfsWalk(child, newChild, currentNodeIndex, patches) // 深度遍历子节点leftNode = child})}
例如,上面的div和新的div有差异,当前的标记是0,那么
patches[0] = [{difference}, {difference}, ...] // 用数组存储新旧节点的不同
那我们所说的差异是什么呢?
节点被替换
增加、删除、移动子节点
修改了节点的属性
若是文本节点,则文本内容可能会被改变
所以我们定义了几种类型:
var REPLACE = 0var REORDER = 1var PROPS = 2var TEXT = 3
举个例子,如果最外层的div被换成了section,则相应的记录如下:
patches[0] = [{type: REPALCE,node: newNode // el('section', props, children)}]
其他变化同理。
5.patch方法的实现
我们比较完了两棵对象树的差异,接下来就是将差异应用到DOM上了。这个过程有点像打补丁,所以我们叫它patch。
我们第一步构建出来的对象树和真正的DOM树的属性、结构是一样的,所以我们可以对DOM树进行一次深度优先遍历,遍历的时候按着diff生成的patch对象进行patch操作,修改需要patch的地方。
我们还要根据不同的差异进行不同的DOM操作。
function patch (node, patches) {var walker = {index: 0}dfsWalk(node, walker, patches)}function dfsWalk (node, walker, patches) {var currentPatches = patches[walker.index] // 从patches拿出当前节点的差异var len = node.childNodes? node.childNodes.length: 0for (var i = 0; i < len; i++) { // 深度遍历子节点var child = node.childNodes[i]walker.index++dfsWalk(child, walker, patches)}if (currentPatches) {applyPatches(node, currentPatches) // 对当前节点进行DOM操作}}function applyPatches (node, currentPatches) {currentPatches.forEach(function (currentPatch) {switch (currentPatch.type) {case REPLACE:node.parentNode.replaceChild(currentPatch.node.render(), node)breakcase REORDER:reorderChildren(node, currentPatch.moves)breakcase PROPS:setProps(node, currentPatch.props)breakcase TEXT:node.textContent = currentPatch.contentbreakdefault:throw new Error('Unknown patch type ' + currentPatch.type)}})}
看过了别人的文章,也借鉴了别人的思想,加上自己的总结,代码正在整理中。
Virtual DOM的简单实现的更多相关文章
- virtual dom 简单了解
管理应用程序状态和用户界面的同步一直是前端UI开发复杂性的主要来源.目前出现了不同的方式来处理这个问题.本文简单讨论其中一种方式virtual dom. 文章概要: virtual dom 基本概念, ...
- 个人对于Virtual DOM的一些理解
之前一直认为react的Virtual DOM操作会比传统的操作DOM要快,这其实是错误的,React 从来没有说过 "React 比原生操作 DOM 快".如果没有 Virtua ...
- 【vue系列】Virtual DOM 真的比操作原生 DOM 快吗?
一.前言 网上都说操作真实dom怎么怎么慢,这儿有个例子:http://chrisharrington.github.io/demos/performance/,例子循环2000个随机数组,点击按钮重 ...
- React virtual DOM explained in simple English/简单语言解释React的虚拟DOM
初学React,其中一个很重要的概念是虚拟DOM,看了一篇文章,顺带翻译一下. If you are using React or learning React, you must have hear ...
- 简单说明 Virtual DOM 为啥快
Virtual DOM 就是用 JS 的对象来描述 DOM 结构的一个 DOM 树.如: var element = { tagName: 'ul', // 节点标签名 props: { // DOM ...
- 抛开react,如何理解virtual dom和immutability
去年以来,React的出现为前端框架设计和编程模式吹来了一阵春风.很多概念,无论是原本已有的.还是由React首先提出的,都因为React的流行而倍受关注,成为大家研究和学习的热点.本篇分享主要就聚焦 ...
- 深度剖析:如何实现一个 Virtual DOM 算法
本文转载自:https://github.com/livoras/blog/issues/13 目录: 1 前言 2 对前端应用状态管理思考 3 Virtual DOM 算法 4 算法实现 4.1 步 ...
- Virtual DOM 算法
前端 virtual-dom react.js javascript 目录: 1 前言 2 对前端应用状态管理思考 3 Virtual DOM 算法 4 算法实现 4.1 步骤一:用JS对象模拟DOM ...
- React v16-alpha 从virtual dom 到 dom 源码简读
一.物料准备 1.克隆react源码, github 地址:https://github.com/facebook/react.git 2.安装gulp 3.在react源码根目录下: $npm in ...
随机推荐
- CUDA和OpenGL互操作经典博文赏析和学习
1.使用cuda+opengl图形互操作性实现MPR.原学位论文学习:实时交互的医学图像可视化.在该论文的第5.1.1节. 2.cuda与opengl互操作之PBO 3.cuda与opengl互操作之 ...
- 测试html报告 github python3版本
github源码下载地址:https://github.com/huilansame/HTMLTestRunner_PY3/archive/master.zip 解压后进入文件找到文件:HTMLTes ...
- B. A Leapfrog in the Array
http://codeforces.com/problemset/problem/949/B Dima is a beginner programmer. During his working pro ...
- 基于Jq的手写插件
<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8&quo ...
- mysql where语句多条件查询是and和or联合使用bug
公司项目中有段功能是全局搜索框和下拉列表的联合查询,在联调开发中发现单独用下拉查询是正确的,单独用全局搜索框也是正确的,测试发现是sql语法有问题. 问题截图: 出现问题的核心还是在于搜索框是用于多个 ...
- 卸载JLink驱动弹出“could not open INSTALL.LOG file”的解决方法
我的操作环境是Windows 10 64位,JLink驱动的版本是V4.96. 最近好久不用STM32了,打算把JLink驱动卸载掉,但是无论是用JLink驱动自带的卸载程序还是控制面板来卸载,都会弹 ...
- react fake double , bind click and dblclick on the same element
smartClick:function(id,name,waiter,e){ var desk = $$(e.currentTarget).data('raw'); if(this.lastClick ...
- 用margin实现两列布局中的自适应列
<div id="wrapper"> <div id="col1"> "fixed" </div> &l ...
- jQuery学习- 层叠选择器
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- STM32通用定时器配置
一.STM32通用定时器原理 STM32 系列的CPU,有多达8个定时器,其中TIM1和TIM8是能够产生三对PWM互补输出的高级定时器,常用于三相电机的驱动,它们的时钟由APB2的输出产生.其它6个 ...