Hadoop生态圈-使用MapReduce处理HBase数据
Hadoop生态圈-使用MapReduce处理HBase数据
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.对HBase表中数据进行单词统计(TableInputFormat)
1>.准备环境
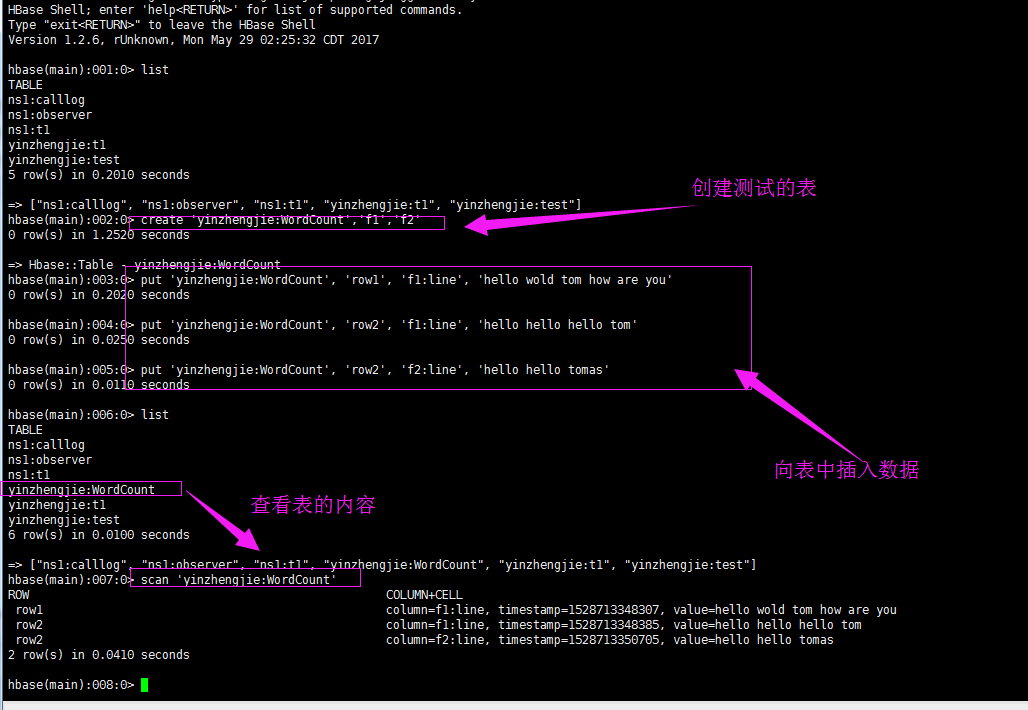
create_namespace 'yinzhengjie'
create 'yinzhengjie:WordCount','f1','f2'
put 'yinzhengjie:WordCount', 'row1', 'f1:line', 'hello wold tom how are you'
put 'yinzhengjie:WordCount', 'row2', 'f1:line', 'hello hello hello tom'
put 'yinzhengjie:WordCount', 'row2', 'f2:line', 'hello hello tomas'
scan 'yinzhengjie:WordCount'
2>.编写Map端代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.hbase.tableinput; import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException;
import java.util.List; /**
* 使用hbase表做wordcount
*/
public class TableInputMapper extends Mapper<ImmutableBytesWritable,Result, Text,IntWritable> { /**
*
* @param key : 可以理解为HBase中的rowkey
* @param value : 输入端的结果集
* @param context : 和reduce端进行数据传输的上下文
*/
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
//将输入端的结果集编程一个集合
List<Cell> cells = value.listCells();
//遍历集合,拿到每个元素的值,然后在按照空格进行切分,并将处理的结果传给reduce端
for (Cell cell : cells) {
String line = Bytes.toString(CellUtil.cloneValue(cell));
String[] arr = line.split(" ");
for(String word : arr){
context.write(new Text(word), new IntWritable(1));
}
}
}
}
3>.编写Reducer端代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.hbase.tableinput; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class TableInputReducer extends Reducer<Text,IntWritable,Text,IntWritable> { @Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
context.write(key,new IntWritable(sum));
}
}
4>.编写主程序代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.hbase.tableinput; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.mapreduce.TableInputFormat;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import static org.apache.hadoop.hbase.mapreduce.TableInputFormat.INPUT_TABLE;
import static org.apache.hadoop.hbase.mapreduce.TableInputFormat.SCAN_COLUMN_FAMILY; public class App { public static void main(String[] args) throws Exception {
//创建一个conf对象
Configuration conf = HBaseConfiguration.create();
//设置输入表,即指定源数据来自HBase的那个表
conf.set(INPUT_TABLE,"yinzhengjie:WordCount");
//设置扫描列族
conf.set(SCAN_COLUMN_FAMILY,"f1");
//创建一个任务对象job,别忘记把conf传进去哟!
Job job = Job.getInstance(conf);
//给任务起个名字
job.setJobName("Table WC");
//指定main函数所在的类,也就是当前所在的类名
job.setJarByClass(App.class);
//设置自定义的Map程序和Reduce程序
job.setMapperClass(TableInputMapper.class);
job.setReducerClass(TableInputReducer.class);
//设置输入格式
job.setInputFormatClass(TableInputFormat.class);
//设置输出路径
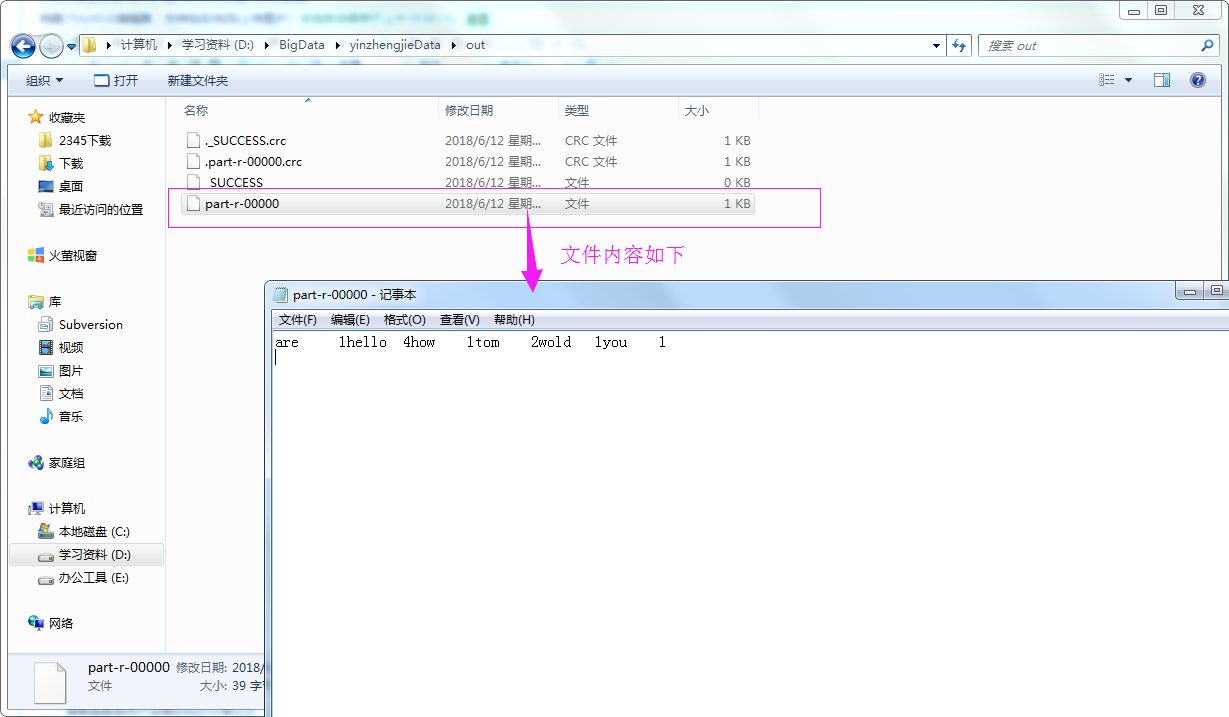
FileOutputFormat.setOutputPath(job,new Path("file:///D:\\BigData\\yinzhengjieData\\out"));
//设置输出k-v
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//等待任务执行结束
job.waitForCompletion(true);
}
}
5>.查看测试结果
二.将本地文件进行单词统计的结果输出到HBase中(TableOutputFormat)
1>.准备环境
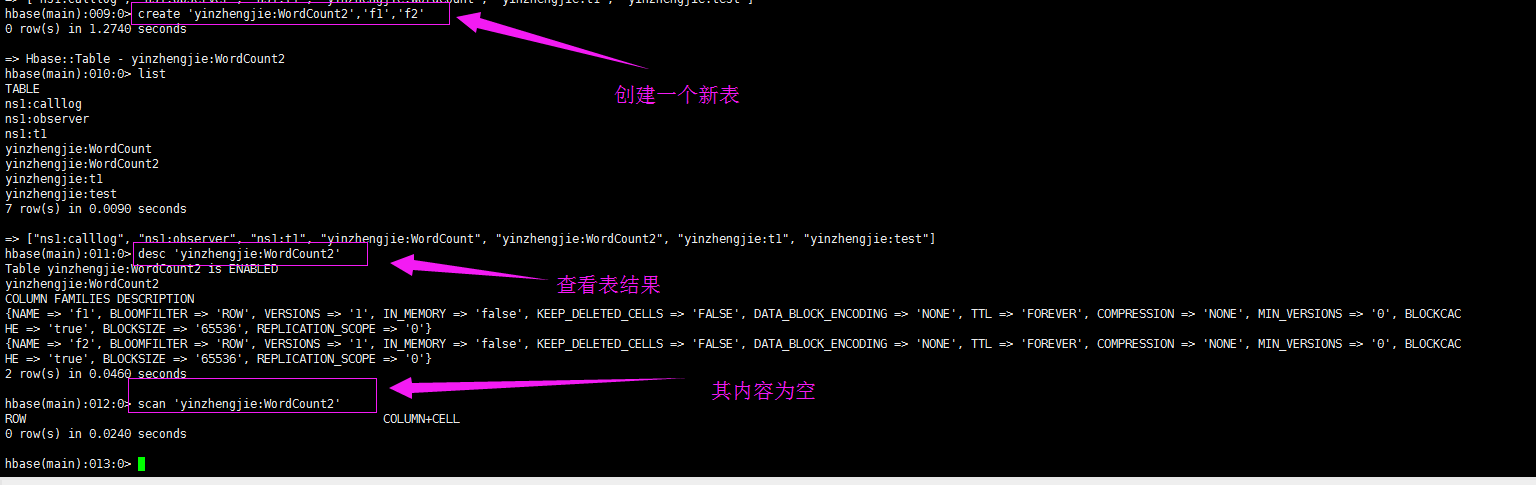
list
create 'yinzhengjie:WordCount2','f1','f2'
list
desc 'yinzhengjie:WordCount2'
scan 'yinzhengjie:WordCount2'
2>.编写Map端代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.hbase.tableoutput; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException; public class TableOutputMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//得到一行数据
String line = value.toString();
//按空格进行切分
String[] arr = line.split(" ");
//遍历切分后的数据,并将每个单词数的赋初始值为1
for (String word : arr){
context.write(new Text(word),new IntWritable(1));
}
}
}
3>.编写Reducer端代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.hbase.tableoutput; import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException; public class TableOutputReducer extends Reducer<Text,IntWritable,NullWritable,Put> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//对同一个key的出现的次数进行相加操作,算出一个单词出现的次数
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
} /**
* 注意,“key.toString().length() > 0”的目的是排除空串,所谓空转就是两个连续的空格链接在一起,
* 比如“hello world”,有两个空格,如果以空格切分的话,由于有两个空格,因此hello和world之间会被切割
* 两次,这也就意味着会出现三个对象,即"hello","","world"。由于这个空串("")的长度为0,因此,如果我
* 们指向统计单词的个数,只需要让长度大于0,就可以轻松过滤出“hello”和“world”两个参数啦!
*/
if(key.toString().length() > 0){
Put put = new Put(Bytes.toBytes(key.toString()));
//添加每列的数据
put.addColumn(Bytes.toBytes("f1"),Bytes.toBytes("count"),Bytes.toBytes(sum+""));
context.write(NullWritable.get(),put);
}
}
}
4>.编写主程序代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.hbase.tableoutput; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; public class App {
public static void main(String[] args) throws Exception {
//创建一个conf对象
Configuration conf = HBaseConfiguration.create();
//设置输出表,即指定将数据存储在哪个HBase表
conf.set(TableOutputFormat.OUTPUT_TABLE,"yinzhengjie:WordCount2");
//创建一个任务对象job,别忘记把conf传进去哟!
Job job = Job.getInstance(conf);
//给任务起个名字
job.setJobName("Table WordCount2");
//指定main函数所在的类,也就是当前所在的类名
job.setJarByClass(App.class);
//设置自定义的Map程序和Reduce程序
job.setMapperClass(TableOutputMapper.class);
job.setReducerClass(TableOutputReducer.class);
//设置输出格式
job.setOutputFormatClass(TableOutputFormat.class);
//设置输入路径
FileInputFormat.addInputPath(job,new Path("file:///D:\\BigData\\yinzhengjieData\\word.txt"));
//设置输出k-v
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Put.class);
//设置map端输出k-v
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//等待任务执行结束
job.waitForCompletion(true);
}
}
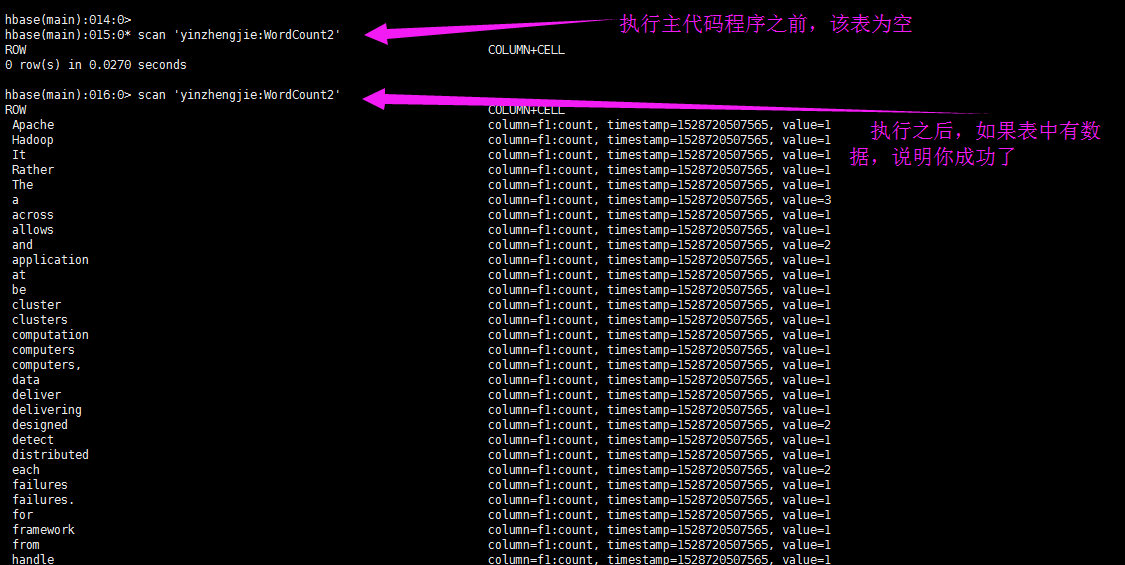
5>.查看测试结果(需要执行主代码程序)
hbase(main)::* scan 'yinzhengjie:WordCount2'
ROW COLUMN+CELL
row(s) in 0.0270 seconds hbase(main)::> scan 'yinzhengjie:WordCount2'
ROW COLUMN+CELL
Apache column=f1:count, timestamp=, value=
Hadoop column=f1:count, timestamp=, value=
It column=f1:count, timestamp=, value=
Rather column=f1:count, timestamp=, value=
The column=f1:count, timestamp=, value=
a column=f1:count, timestamp=, value=
across column=f1:count, timestamp=, value=
allows column=f1:count, timestamp=, value=
and column=f1:count, timestamp=, value=
application column=f1:count, timestamp=, value=
at column=f1:count, timestamp=, value=
be column=f1:count, timestamp=, value=
cluster column=f1:count, timestamp=, value=
clusters column=f1:count, timestamp=, value=
computation column=f1:count, timestamp=, value=
computers column=f1:count, timestamp=, value=
computers, column=f1:count, timestamp=, value=
data column=f1:count, timestamp=, value=
deliver column=f1:count, timestamp=, value=
delivering column=f1:count, timestamp=, value=
designed column=f1:count, timestamp=, value=
detect column=f1:count, timestamp=, value=
distributed column=f1:count, timestamp=, value=
each column=f1:count, timestamp=, value=
failures column=f1:count, timestamp=, value=
failures. column=f1:count, timestamp=, value=
for column=f1:count, timestamp=, value=
framework column=f1:count, timestamp=, value=
from column=f1:count, timestamp=, value=
handle column=f1:count, timestamp=, value=
hardware column=f1:count, timestamp=, value=
high-availability, column=f1:count, timestamp=, value=
highly-available column=f1:count, timestamp=, value=
is column=f1:count, timestamp=, value=
itself column=f1:count, timestamp=, value=
large column=f1:count, timestamp=, value=
layer, column=f1:count, timestamp=, value=
library column=f1:count, timestamp=, value=
local column=f1:count, timestamp=, value=
machines, column=f1:count, timestamp=, value=
may column=f1:count, timestamp=, value=
models. column=f1:count, timestamp=, value=
of column=f1:count, timestamp=, value=
offering column=f1:count, timestamp=, value=
on column=f1:count, timestamp=, value=
processing column=f1:count, timestamp=, value=
programming column=f1:count, timestamp=, value=
prone column=f1:count, timestamp=, value=
rely column=f1:count, timestamp=, value=
scale column=f1:count, timestamp=, value=
servers column=f1:count, timestamp=, value=
service column=f1:count, timestamp=, value=
sets column=f1:count, timestamp=, value=
simple column=f1:count, timestamp=, value=
single column=f1:count, timestamp=, value=
so column=f1:count, timestamp=, value=
software column=f1:count, timestamp=, value=
storage. column=f1:count, timestamp=, value=
than column=f1:count, timestamp=, value=
that column=f1:count, timestamp=, value=
the column=f1:count, timestamp=, value=
thousands column=f1:count, timestamp=, value=
to column=f1:count, timestamp=, value=
top column=f1:count, timestamp=, value=
up column=f1:count, timestamp=, value=
using column=f1:count, timestamp=, value=
which column=f1:count, timestamp=, value=
row(s) in 0.1600 seconds hbase(main)::>
hbase(main):016:0> scan 'yinzhengjie:WordCount2'
Hadoop生态圈-使用MapReduce处理HBase数据的更多相关文章
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- 使用MapReduce读取HBase数据存储到MySQL
Mapper读取HBase数据 package MapReduce; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hba ...
- hadoop2的mapreduce操作hbase数据
1.从hbase中取数据,再把计算结果插入hbase中 package com.yeliang; import java.io.IOException; import org.apache.hadoo ...
- 大数据和Hadoop生态圈
大数据和Hadoop生态圈 一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop ...
- Hadoop专业解决方案-第1章 大数据和Hadoop生态圈
一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop生态圈小组已经翻译完成,在此 ...
- 脱离JVM? Hadoop生态圈的挣扎与演化
本文由知乎<大数据应用与实践>专栏 李呈祥授权发布,版权所有归作者,转载请联系作者! 新世纪以来,互联网及个人终端的普及,传统行业的信息化及物联网的发展等产业变化产生了大量的数据,远远超出 ...
- Hadoop生态圈介绍及入门(转)
本帖最后由 howtodown 于 2015-4-2 23:15 编辑 问题导读 1.Hadoop生态圈介绍了哪些组件,分别都是什么? 2.大数据与Hadoop是什么关系? 本章主要内容: 理解大数据 ...
- Hbase框架原理及相关的知识点理解、Hbase访问MapReduce、Hbase访问Java API、Hbase shell及Hbase性能优化总结
转自:http://blog.csdn.net/zhongwen7710/article/details/39577431 本blog的内容包含: 第一部分:Hbase框架原理理解 第二部分:Hbas ...
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
随机推荐
- 20162325 金立清 S2 W3 C13
20162325 2017-2018-2 <程序设计与数据结构>第3周学习总结 教材学习内容概要 查找是在一组项内找到指定目标或是确定目标不存在的过程 高效的查找使得比较的次数最少 Com ...
- web10 动态action的应用
电影网站:www.aikan66.com 项目网站:www.aikan66.com游戏网站:www.aikan66.com图片网站:www.aikan66.com书籍网站:www.aikan66.co ...
- 1001. A+B Format (20)题解
git链接 作业描述 Calculate a + b and output the sum in standard format -- that is, the digits must be sepa ...
- 团队作业7——第二次项目冲刺(Beta版本12.04——12.07)
1.当天站立式会议照片 本次会议在5号公寓3楼召开,本次会议内容:①:熟悉每个人想做的模块.②:根据项目要求还没做的完成. 2.每个人的工作 经过会议讨论后确定了每个人的分工 组员 任务 陈福鹏 实现 ...
- week4d:个人博客作业
7,程序结果的显示 1,界面 2,选第一选项. 3,输入3个数后. 4,选择第一个. 5,输入第4个数字. 6,再次进行一轮游戏. 7,选择是否要看历史记录. 8,进入下一轮游戏. 9,开始第二轮数字 ...
- 个人作业-week3案例分析
第一部分 软件调研测评(必应词典移动端) 找到的bug: 在词汇量测试中每个单词给用户思考的时间太短,只有五秒钟.导致很多似曾相识的单词还没来得及想起就已经过了.如果说测的是用户记忆深刻的单词,那些记 ...
- 关于对JSON.parse()与JSON.stringify()的理解
JSON.parse()与JSON.stringify()的区别 JSON.parse()[从一个字符串中解析出json对象] 例子: //定义一个字符串 var data='{"nam ...
- Boa服务器移植
Boa是一种非常小巧的Web服务器,其可执行代码只有大约60KB左右.作为一种单任务Web服务器,Boa只能依次完成用户的请求,而不会fork出新的进程来处理并发连接请求.但Boa支持CGI,能够为C ...
- win7 32位 import cv2 失败 ImportError:DLL load fail:找不到指定模块
引起问题的可能性太多,这里记录比较一下比较少见的错误原因 缺少dll文件 https://www.dll-files.com/api-ms-win-downlevel-shlwapi-l1-1-0.d ...
- php三种方法从控制结构或脚本中跳出
PHP中,如果希望停止一段代码,根据需要达到的效果不同,可以有三种方法实现: 1. break: 如果在循环中使用了break语句,脚本就会从循环体后面的第一条语句开始执行: 2. continue: ...