JAVA使用Gecco爬虫 抓取网页内容(附Demo)
JAVA 爬虫工具有挺多的,但是Gecco是一个挺轻量方便的工具。
先上项目结构图。
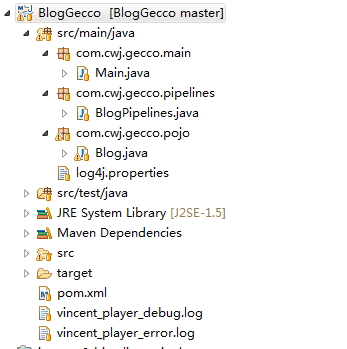
这是一个 JAVASE的 MAVEN 项目,要添加包依赖,其他就四个文件。log4j.properties 加上三个java类。
1、先配置log4j.properties
log4j.rootLogger=INFO,Console,File
log4j.appender.Console=org.apache.log4j.ConsoleAppender
log4j.appender.Console.Target=System.out
log4j.appender.Console.layout = org.apache.log4j.PatternLayout
log4j.appender.Console.layout.ConversionPattern=[%c] - %m%n log4j.appender.File = org.apache.log4j.RollingFileAppender
log4j.appender.File.File = logs/ssm.log
log4j.appender.File.MaxFileSize = 10MB
log4j.appender.File.Threshold = ALL
log4j.appender.File.layout = org.apache.log4j.PatternLayout
log4j.appender.File.layout.ConversionPattern =[%p] [%d{yyyy-MM-dd HH\:mm\:ss}][%c]%m%n
2、接下来着手写Blog.java,里面都有注释 不解释
package com.cwj.gecco.pojo; import com.geccocrawler.gecco.annotation.Gecco;
import com.geccocrawler.gecco.annotation.HtmlField;
import com.geccocrawler.gecco.annotation.Request;
import com.geccocrawler.gecco.request.HttpRequest;
import com.geccocrawler.gecco.spider.SpiderBean; /**
* @author cwj
* 2017年8月6日
* Blog实体类,运行主函数从这里开始解析
* matchUrl:要抓包的目标地址
* pipelines:跳转到下个pipelines
*/
@Gecco(matchUrl="http://www.cnblogs.com/boychen/p/7226831.html",pipelines="blogPipelines")
public class Blog implements SpiderBean{
/**
* 向指定URL发送GET方法的请求
*/
@Request
private HttpRequest request; /**
* 抓去这个路径下所有的内容
*/
@HtmlField(cssPath = "body div#cnblogs_post_body")
private String content; public HttpRequest getRequest() {
return request;
} public void setRequest(HttpRequest request) {
this.request = request;
} public String getContent() {
return content;
} public void setContent(String content) {
this.content = content;
} }
3、BlogPipelines.java
package com.cwj.gecco.pipelines; import com.cwj.gecco.pojo.Blog;
import com.geccocrawler.gecco.annotation.PipelineName;
import com.geccocrawler.gecco.pipeline.Pipeline; /**
* @author cwj
* 2017年8月6日
* 运行完Blog.java 根据@PipelineName 来这里
*/
@PipelineName(value="blogPipelines")
public class BlogPipelines implements Pipeline<Blog>{ /**
* 将抓取到的内容进行处理 这里是打印在控制台
*/
public void process(Blog blog) {
System.out.println(blog.getContent());
} }
4、最后便是在main中调用
package com.cwj.gecco.main;
import com.geccocrawler.gecco.GeccoEngine;
public class Main {
public static void main(String[] args) {
GeccoEngine.create()
//工程的包路径
.classpath("com.cwj.gecco")
//开始抓取的页面地址
.start("http://www.cnblogs.com/boychen/p/7226831.html")
//开启几个爬虫线程
.thread(10)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(5)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
5、抓取到内容,日志文件被我删除 有警告
附上源码地址 https://github.com/BeautifulMeet/Gecco
JAVA使用Gecco爬虫 抓取网页内容(附Demo)的更多相关文章
- Java豆瓣电影爬虫——抓取电影详情和电影短评数据
一直想做个这样的爬虫:定制自己的种子,爬取想要的数据,做点力所能及的小分析.正好,这段时间宝宝出生,一边陪宝宝和宝妈,一边把自己做的这个豆瓣电影爬虫的数据采集部分跑起来.现在做一个概要的介绍和演示. ...
- PHP爬虫抓取网页内容 (simple_html_dom.php)
使用simple_html_dom.php,下载|文档 因为抓取的只是一个网页,所以比较简单,整个网站的下次再研究,可能用Python来做爬虫会好些. <meta http-equiv=&quo ...
- paip.抓取网页内容--java php python
paip.抓取网页内容--java php python.txt 作者Attilax 艾龙, EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:http://blog ...
- Java 实现 HttpClients+jsoup,Jsoup,htmlunit,Headless Chrome 爬虫抓取数据
最近整理一下手头上搞过的一些爬虫,有HttpClients+jsoup,Jsoup,htmlunit,HeadlessChrome 一,HttpClients+jsoup,这是第一代比较low,很快就 ...
- 爬虫学习一系列:urllib2抓取网页内容
爬虫学习一系列:urllib2抓取网页内容 所谓网页抓取,就是把URL地址中指定的网络资源从网络中读取出来,保存到本地.我们平时在浏览器中通过网址浏览网页,只不过我们看到的是解析过的页面效果,而通过程 ...
- 爬虫技术 -- 进阶学习(七)简单爬虫抓取示例(附c#代码)
这是我的第一个爬虫代码...算是一份测试版的代码.大牛大神别喷... 通过给定一个初始的地址startPiont然后对网页进行捕捉,然后通过正则表达式对网址进行匹配. List<string&g ...
- 爬虫技术(四)-- 简单爬虫抓取示例(附c#代码)
这是我的第一个爬虫代码...算是一份测试版的代码.大牛大神别喷... 通过给定一个初始的地址startPiont然后对网页进行捕捉,然后通过正则表达式对网址进行匹配. List<string&g ...
- 使用Jsoup函数包抓取网页内容
之前写过一篇用Java抓取网页内容的文章,当时是用url.openStream()函数创建一个流,然后用BufferedReader把这个inputstream读取进来.抓取的结果是一整个字符串.如果 ...
- c#抓取网页内容乱码的解决方案
写过爬虫的同学都知道,这是个很常见的问题了,一般处理思路是: 使用HttpWebRequest发送请求,HttpWebResponse来接收,判断HttpWebResponse中”Content-Ty ...
随机推荐
- (快速幂)Key Set--hdu--5363
链接: http://acm.hdu.edu.cn/showproblem.php?pid=5363 http://acm.hust.edu.cn/vjudge/contest/view.action ...
- CGA填充算法之种子填充算法
CGA填充算法之种子填充算法 平面区域填充算法是计算机图形学领域的一个很重要的算法,区域填充即给出一个区域的边界 (也可以是没有边界,只是给出指定颜色),要求将边界范围内的所有象素单元都修改成指定的颜 ...
- line tension
<!DOCTYPE html> <html> <head> <title>tension</title> <script type=& ...
- 团队博客-第三周:需求改进&系统设计(科利尔拉弗队)
针对课堂讨论环节老师和其他组的问题及建议,对修改选题及需求进行修改 需求规格说明书: 1.打开网页,弹出询问时候创建账号.是:分配数字组成账号,用户填写密码,确定登录进入首页:否,用已有账号登录(传参 ...
- ASP.NET 中 <%= %> 与 <%: %> 的区别
做个备忘 <%= %> 内容原封不动输出 <%: %> 对内容进行编码后输出 即:<%: str %> 等价于 <%= Html.Encode(str) %& ...
- Oracle/PLSQL: BitAnd Function
BITAND 函数 本文介绍 Microsoft Excel 中 BITAND 函数的公式语法和用法. 说明 返回两个数的按位“与”. 语法 BITAND( number1, number2) BIT ...
- 深入理解Aspnet Core之Identity(3)
主题 账户管理一个比较常见的功能就是密码强度策略,Identity已经内置了一个通用的可配置的策略,我们一般情况下可以直接拿来用即可.本篇我会介绍一些Identity内置的密码策略类:Password ...
- 在Windows安装Reids 详解
今天安装了redis,记录点经验 因为Redis项目没有正式支持Windows. 但Microsoft开发和维护一个针对Windows 64版的redis. 下载地址在微软的GitHub上,地址:ht ...
- jQuery-Load方法
1.load() 介绍:load() 方法通过 AJAX 请求从服务器加载数据,并把返回的数据放置到指定的元素中 该方法是最简单的从服务器获取数据的方法.它几乎与 $.get(url, data, s ...
- Interesting JavaScript
作者:ManfredHu 链接:http://www.manfredhu.com/2016/07/07/20-interestingJavascript 声明:版权所有,转载请保留本段信息,否则请不要 ...