高并发编程之synchronized
一、什么是线程?
/**
* synchronized关键字,对某个对象加锁
* @author Wuyouxin
*
*/
public class T { private int count = 10;
private Object obj = new Object(); public void m (){
synchronized(obj){//任何线程想要执行下面代码就必须先要拿到obj的锁。
count--;
System.out.println(Thread.currentThread().getName() + " count:" + count);
}
}
}
如果想要执行synchronized里面的这段代码,就必须获取到obj这个对象的锁,如果多和线程同时执行时,A线程获取到了obj对象并且加锁,B对象来执行这段代码获取到obj对象 ,但是发现obj对象已经被锁定,所以就会等待A线程执行完这段代码并释放锁,等A对象释放之后B对象再锁定obj对象再执行。这就是简单的互斥锁。上面代码中我们锁定的是obj对象但是在正常开发中不会去专门new一个对象来锁定,所以我们一般是是锁定自身,在使用这个方法前先new本身的对象再去执行。而且synchronized锁定的是对象,而不是代码块。
public void m (){
synchronized(this){//任何线程想要执行下面代码就必须先要拿到T类的对象的锁。
count--;
System.out.println(Thread.currentThread().getName() + " count:" + count);
}
}
如果一个方法执行,需要锁定到本身的对象还有一种写法。
public synchronized void m (){ //等同于在方法块中synchronized(this){}
count--;
System.out.println(Thread.currentThread().getName() + " count:" + count);
}
当一个synchronized修饰一个静态方法时,静态方法不需要new对象出来就可以直接方法,这时锁定的是T.class对象
public class T {
private static int count = 10;
public synchronized static void m1 (){
count--;
}
public static void m2 (){
synchronized(T.class){ //这个方法跟上面方法等价
count--;
}
}
}
我们看下面代码:
public class T implements Runnable{
private int count = 10;
@Override
public /*synchronized*/ void run() {
count--;
System.out.println(Thread.currentThread().getName() + " count:" + count);
}
public static void main(String[] args) {
T t = new T();
for (int i=0; i<5 ; i++){
new Thread(t, "thread" +i).start();
}
}
}
这里我们将synchronized注释起来,去运行这段代码。
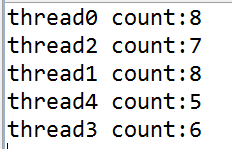
我们发现thread0和thread1输出了同样的结果,这是怎么回事呢?这里其实发生了线程重入的问题,当thread0执行完成count--之后还没来得及打印,线程thread1进来打断了thread0发现count是9,然后减一后输出8,然后thread0再输出,但是这时count已经变成8了所以也输出了8。如果我们加上synchronized,则每一个线程执行时都要获取到T的锁并且锁定后才会执行,这样几不会出现线程重入的情况。
二、在现在中synchronized方法与普通方法可以同时执行么?
我们看下面代码:
/**
* synchronized方法与非synchronized方法可以同时运行么?
* @author Wuyouxin
*
*/
public class T { public synchronized void m1(){
System.out.println(Thread.currentThread().getName() + "m1 start");
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "m1 end");
} public void m2 (){
System.out.println(Thread.currentThread().getName() + "m2 start");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "m2 end");
} public static void main(String[] args) {
final T t = new T(); Runnable run1 = new Runnable() {
@Override
public void run() {
t.m1();
}
};
new Thread(run1, "thread1").start(); Runnable run2 = new Runnable() {
@Override
public void run() {
t.m2();
}
};
new Thread(run2, "thread2").start();
}
}
答案是当然可以,因为只有synchronized方法才会去获取对象锁,而非synchronized不需要获取对象锁,所以可以一起执行,并不会互相影响。
三、脏读问题
对写业务方法加锁,对读业务不加锁,容易产生脏读。我们看下面代码:
/**
* 对写业务加锁,对读业务不加锁,容易产生脏读问题
* @author Wuyouxin
*
*/
public class Account {
private String name;
private double balance; /**
* 设置余额
* @param name
* @param balance
*/
public synchronized void set (String name, double balance){
this.name = name;
try {
Thread.sleep(2000);
} catch (Exception e) {
}
this.balance = balance;
} /**
* 根据名字获取余额
* @param name
* @return
*/
public double get (String name){
return this.balance;
} public static void main(String[] args) {
final Account account = new Account(); new Thread(new Runnable() {
@Override
public void run() {
account.set("张三", 100);
}
}).start(); try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
} System.out.println(account.get("张三")); try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
} System.out.println(account.get("张三")); }
}
在上面这段代码中,我们对写业务进行加锁,而读没有加锁,结果2次输出第一次为0.0第二次为100.0。我们发现2次读到的数据不一致,这就是脏读,而在实际的开发中我们应当去根据业务逻辑去判断如果读的方法不要求数据完全一致,则不需要加锁,这样可以提高效率。如果读的方法完全要求读取数据一致则必须加锁,否则会出现脏读的情况。
四、锁重入
一个同步方法可以调用另一个同步方法,一个线程已经拥有某个对象的锁,再次申请时任然会获得该对象的锁,也就是说synchronized的锁是可以重入的。
/**
* 一个同步方法可以调用另一个同步方法,一个线程已经拥有某个对象的锁,
* 再次申请时任然会获得该对象的锁,也就是说synchronized的锁是可以重入的。
* @author Wuyouxin
*
*/
public class T { synchronized void m1 (){
System.out.println("m1 start");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
m2();
} synchronized void m2 (){
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("m2");
}
}
锁重入还有一种情况就是子类调用父类的同步方法。
/**
* 继承中,子类调用父类的同步方法。
* @author Wuyouxin
*
*/
public class T1 { synchronized void m(){
System.out.println("m start");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("m end");
} public static void main(String[] args) {
new T2().m();
}
} class T2 extends T1 {
@Override
synchronized void m (){
System.out.println("m2 stard");
super.m();
System.out.println("m2 end");
}
}
五、遇到异常释放锁
程序在执行过程中,如果遇到异常,默认情况所会被释放,所以,在并发编程中,有异常要多加小心,不然可能会发生不一致的情况。
比如,在一个web app处理过程中,多个servlet线程共同访问同一个资源,这时如果异常处理不合适,在第一个线程中抛出异常,其他线程就会进入同步代码区,有可能会访问到异常产生时的数据。因此要非常小心的处理同步业务逻辑中的异常。
我们看下面代码:
/**
* 程序在执行过程中,如果遇到异常,默认情况所会被释放,
* 所以,在并发编程中,有异常要多加小心,不然可能会发生不一致的情况。
* @author Wuyouxin
*
*/
public class T {
int count = 0;
synchronized void m(){
System.out.println(Thread.currentThread().getName()+" start");
while (true){
count ++;
System.out.println(Thread.currentThread().getName()+ " count=" + count);
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
} if (count == 5){
int i = 1/0;//这里会产生异常,导致锁释放,如果不想让锁释放需要捕获异常
}
}
} public static void main(String[] args) {
final T t = new T();
new Thread(new Runnable() {
@Override
public void run() {
t.m();
}
}, "T1").start(); new Thread(new Runnable() {
@Override
public void run() {
t.m();
}
}, "T2").start();
}
}
上面代码在执行时首先T1线程进入m方法,并且将t对象锁定,如果不出异常T1线程将一直执行m()方法的循环,T2线程无法进入,但是在count=5时出现异常,T1线程释放锁,T2线程进入继续执行,但是拿到的count数据时T1线程执行之后的数据,这里在实际开发中如果不做异常处理则有可能拿到错误的数据继续执行。所以在多线程开发中要特别注意异常的处理。
六、volatile 关键字
volatile关键字,使一个变量在多个线程之间可见,A,B线程都用到一个变量,java默认是A线程中保留一份copy,这样如果B线程修改了该变量,则A线程未必知道。使用vilatile关键字,会让所有线程都会读取到变量的修改值。
在下面的代码中,running是存在于堆内存的t对象中,当线程t1开始运行的时候,会把running值从内存中读取到t1线程的工作区中,在运行过程中之间使用这个copy,并不会每次都去读取堆内存,这样,当主线程修改running的值之后,t1线程感知不到,所以不会停止运行。
/**
* volatile关键字,使一个变量在多个线程之间可见,A,B线程都用到一个变量,
* java默认是A线程中保留一份copy,这样如果B线程修改了该变量,则A线程未必知道。
* 使用vilatile关键字,会让所有线程都会读取到变量的修改值。
* 在下面的代码中,running是存在于堆内存的t对象中,当线程t1开始运行的时候,
* 会把running值从内存中读取到t1线程的工作区中,在运行过程中之间使用这个copy,
* 并不会每次都去读取堆内存,这样,当主线程修改running的值之后,
* t1线程感知不到,所以不会停止运行。
* @author Wuyouxin
*
*/
public class T { /*volatile*/ boolean running = true; void m (){
System.out.println("m.start");
while (running){
}
System.out.println("m.end");
} public static void main(String[] args) {
final T t = new T();
new Thread(new Runnable() {
@Override
public void run() {
t.m();
}
}, "t1").start(); try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
t.running = false;
}
}
使用volatile后当堆内存中running发生改变之后会强制所有线程都去堆内存中读取running的值。
volatile并不能保证多个线程共同修改running变量时所带来的不一致问题,也就是说volatile不能替代synchronized
/**
* volatile并不能保证多个线程共同修改running变量时所带来的不一致问题,
* 也就是说volatile不能替代synchronized
* @author Wuyouxin
*
*/
public class T {
volatile int count = 0;
/*synchronized*/ void m(){
for (int i = 0; i < 10000; i++) {
count ++;
}
} public static void main(String[] args) {
List<Thread> threads = new ArrayList<Thread>();
final T t = new T();
for (int i = 0; i < 10; i++) {
threads.add(new Thread(new Runnable() {
@Override
public void run() {
t.m();
}
}, "Thread-" + i));
} for (Thread thread : threads) {
thread.start();
} for (Thread thread : threads) {
try {
thread.join();//让主线程等待子线程运行结束之后再执行
} catch (InterruptedException e) {
e.printStackTrace();
}
} System.out.println(t.count);
}
}
这段代码执行之后的结果我们理想状态应该是100000但是实际执行确实一个比100000小的一个随机数,这是什么原因呢?因为volatile只保证可见性而不能像synchronized一样既可以保证可见性也可以保证原子性。在线程1在读到count的值++之后往内存中写入的过程中,线程2开始执行,发现内存中的值还是线程1没有写入的值拿到后再++再写入内存,这样导致两个线程写入了同样的值,所有最后的结果要小于100000。
七、AtomXXX类
如果在操作中仅仅是数字的++,--等操作,java提高了一些原子操作的类AtomXXX类,AtomXXX类本身方法都是原子性的,但是不能保证多个方法连续调用是原则性的。
我们看下面代码:
/**
* 如果再操作中仅仅是数字的++,--等操作,java提高了一些原子操作的类AtomXXX类
*
* @author Wuyouxin
*
*/
public class T {
AtomicInteger count = new AtomicInteger(0); //这里可以不用synchronized,AtomicInteger方法内部使用了更底层的方式保证原子性
/*synchronized*/ void m (){
for (int i = 0; i < 10000; i++) {
count.incrementAndGet();//相当于count++,但是还保证原子性
}
} public static void main(String[] args) {
final T t = new T();
List<Thread> threads = new ArrayList<Thread>();
for (int i = 0; i < 10; i++) {
threads.add(new Thread(new Runnable() {
@Override
public void run() {
t.m();
}
}, "thread-" + i));
} for (Thread thread : threads) {
thread.start();
} for (Thread thread : threads) {
try {
} catch (InterruptedException e) {
e.printStackTrace();
}
} System.out.println(t.count);
}
}
AtomXXX类本身方法都是原子性的,但是不能保证多个方法连续调用是原子性的。
我们看下面代码:
/*synchronized*/ void m (){
for (int i = 0; i < 10000; i++) {
if (count.get()<1000){ //count.get()也具有原子性
count.incrementAndGet();
}
}
}
我们把上面的m方法修改成这个样子,加入一个if判断,而且这个判断的count.gat()方法也具有原子性,但是在这两个方法之间不具有原子性,也有可能会被其他线程打断。当线程1达到999的时候还没+1,但是被线程2打断进入+1,而线程1又+1就变成1001了。
八、synchronized优化
synchronized中的代码越少效率越高。我们来比较下面2个方法:
public class T {
int count = 0;
synchronized void m1(){
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
//业务逻辑中只有下面代码需要同步,这时不应该给所有方法上锁
count ++;
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
void m2(){
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
//采用细粒度的锁可以使线程争用时间变短,提高效率
synchronized (this) {
count ++;
}
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
上面m1方法给整个方法都上了锁,而m2只给count++上了锁,m2的锁粒度更细,所以执行效率更高。
九、避免被锁定的对象引用发生改变
当一个对象被锁定时t1对象锁定对象的引用发生改变时,t2线程就会发现新的对象没有被锁定,则会进入方法锁定新的对象,所以应当避免被锁定的对象的引用发生改变。
我们看下面代码:
/**
* 锁定某对象o,如果o的属性发生改变,不影响锁的使用
* 但是如果o改变成另外一个对象,则锁定的对象发生变化,
* 应该避免将锁定对象的引用变成另外的对象
* @author Wuyouxin
*
*/
public class T { Object o = new Object(); void m (){
synchronized(o){
while(true){
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName());
}
}
} public static void main(String[] args) {
final T t = new T();
new Thread(new Runnable() { @Override
public void run() {
t.m();
}
}, "t1").start(); try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
} Thread t2 = new Thread(new Runnable() { @Override
public void run() {
t.m();
}
}, "t2");
//锁定的对象发生变化,当执行到这时发现new出来的o没有被锁定则t2开始执行,如果没有这句话
//t2就永远不会执行
t.o = new Object();
t2.start();
} }
上面代码中由于T中的o发生了引用的对象发生了改变,导致t2线程和t1线程同时进入了m方法,这样就会导致出现数据混乱,失去了同步的意义。
由上述代码也可以证明锁是锁在堆内存中的对象上,而不是栈内存的引用变量上。
十、避免使用字符串常量作为锁
不要以字符串常量作为锁定对象,在下面的例子中,m1和m2其实锁定的是同一个对象这种情况还会发生比较诡异的现象,比如你用到一个类库,在该类库中代码锁定了字符串“Hello”,但是你读不到源码,所以你在自己的代码中也锁定了“Hello”,这时候就有可能发生比较诡异的死锁阻塞。因为你的线程和你用到的类库不经意间使用了同一把锁。
/**
* 不要以字符串常量作为锁定对象,在下面的例子中,m1和m2其实锁定的是同一个对象
* 这种情况还会发生比较诡异的现象,比如你用到一个类库,
* 在该类库中代码锁定了字符串“Hello”,但是你读不到源码,所以你在自己的代码中
* 也锁定了“Hello”,这时候就有可能发生比较诡异的死锁阻塞。
* 因为你的线程和你用到的类库不经意间使用了同一把锁。
* @author Wuyouxin
*
*/
public class T { //这两个对象其实是同一个对象,放在字符串池中
String s1 = "Hello";
String s2 = "Hello"; void m1(){
synchronized (s1) { }
} void m2(){
synchronized (s2) { }
}
}
十一、淘宝曾经的面试题
实现一个容器提供两个方法 add和size,写两个线程,线程1添加10个元素到容器中,线程2进行监控,当容器内元素达到5时,线程2给出提示并结束。
我们看下面方法:
/**
* 实现一个容器提供两个方法 add和size,写两个线程,线程1添加10个元素到容器中,
* 线程2进行监控,当容器内元素达到5时,线程2给出提示并结束。
* @author Wuyouxin
*
*/
public class MyContainer1 {
//这里一定要加volatile,否则线程2无法监测到堆内存中 的list
volatile List<Object> list = new ArrayList<Object>(); public void add (Object o){
list.add(o);
} public int size (){
return list.size();
} public static void main(String[] args) {
final MyContainer1 c = new MyContainer1(); new Thread(new Runnable() { @Override
public void run() {
for (int i = 0; i < 10; i++) {
c.add(new Object());
System.out.println("add:" + i);
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
} }
}, "t1").start(); new Thread(new Runnable() { @Override
public void run() {
while (true){
if(c.size() == 5)
break;
}
System.out.println("结束");
}
}, "t2").start();
} }
上面代码我们需要注意的是在list之前一定要加volatile关键字,否则线程2无法获得list的变化。还存在一个问题,这里方法没有加锁,如果再加入几个线程,就会导致list的数据不精确,这里就需要使用到锁。但是,t2线程的死循环很浪费cpu,如果不使用死循环,该怎么做。
我们看下面代码:
/**
* 这里就要使用wait和notify做到,
* wait会让t2对象进入等待状态并且释放锁,而t1在执行到
* c.size()==5时使用notify唤醒等待的线程。
* 需要注意的是,这种方法必须要让t2先执行,也就是先让t2监听才可以
* @author Wuyouxin
*
*/
public class MyContainer2 { //这里一定要加volatile,否则线程2无法监测到堆内存中 的list
volatile List<Object> list = new ArrayList<Object>(); public void add (Object o){
list.add(o);
} public int size (){
return list.size();
} public static void main(String[] args) {
final MyContainer2 c = new MyContainer2(); final Object lock = new Object(); new Thread(new Runnable() {
@Override
public void run() {
synchronized (lock) {
System.out.println("t2启动 ");
if(c.size() != 5){
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("结束");
}
}
}, "t2").start(); try {
TimeUnit.SECONDS.sleep(1);
} catch (Exception e) {
} new Thread(new Runnable() { @Override
public void run() {
System.out.println("t1启动");
synchronized (lock) {
for (int i = 0; i < 10; i++) {
c.add(new Object());
System.out.println("add:" + i);
if (c.size() == 5){
lock.notify();
}
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}, "t1").start();
}
}
这里就要使用wait和notify做到,wait会让t2对象进入等待状态并且释放锁,而t1在执行到c.size()==5时使用notify唤醒等待的线程。需要注意的是,这种方法必须要让t2先执行,也就是先让t2监听才可以。但是上面代码也存在一个问题,t2是在t1执行结束之后才结束,而不是c.size()==5时立刻结束。这是因为wait等待会释放锁,但是notify唤醒不会释放锁,所以才会导致t2要在t1之后才结束。这里我们就需要让t1线程运行notify唤醒其他线程之后再调用wait等待并释放锁,而t2线程需要结束之后再使用notify去唤醒其他线程。
所以应当是下面这样:
/**
* 但是上面代码也存在一个问题,t2是在t1执行结束之后才结束,
* 而不是c.size()==5时立刻结束。这是因为wait等待会释放锁,
* 但是notify唤醒不会释放锁,所以才会导致t2要在t1之后才结束。
* 这里我们就需要让t1线程运行notify唤醒其他线程之后再调用wait等待并释放锁,
* 而t2线程需要结束之后再使用notify去唤醒其他线程
* @author Wuyouxin
*
*/
public class MyContainer2 { //这里一定要加volatile,否则线程2无法监测到堆内存中 的list
volatile List<Object> list = new ArrayList<Object>(); public void add (Object o){
list.add(o);
} public int size (){
return list.size();
} public static void main(String[] args) {
final MyContainer2 c = new MyContainer2(); final Object lock = new Object(); new Thread(new Runnable() {
@Override
public void run() {
synchronized (lock) {
System.out.println("t2启动 ");
if(c.size() != 5){
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("结束");
lock.notify();
}
}
}, "t2").start(); try {
TimeUnit.SECONDS.sleep(1);
} catch (Exception e) {
} new Thread(new Runnable() { @Override
public void run() {
System.out.println("t1启动");
synchronized (lock) {
for (int i = 0; i < 10; i++) {
c.add(new Object());
System.out.println("add:" + i);
if (c.size() == 5){
lock.notify();
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}, "t1").start();
}
}
但是上面的通讯太复杂了,如果只涉及到通讯而不涉及到同步时 synchronized wait/notify就会显得太重了,这时就应该考虑使用countdownlatch/cyclicbarrier/semaphore,使用Latch(门闩)代替wait notify来进行通知,好处是通信方式简单,同时还可以指定等待时间,使用await和countdown方法代替wait和notify,CountDownLatch不涉及锁定,当count的值为零时当前线程继续运行。
/**
* 但是上面的通讯太复杂了,如果只涉及到通讯而不涉及到同步时 synchronized wait/notify
* 就会显得太重了,这时就应该考虑使用countdownlatch/cyclicbarrier/semaphore,
* 使用Latch(门闩)代替wait notify来进行通知,好处是通信方式简单,同时还可以指定等待时间,
* 使用await和countdown方法代替wait和notify,CountDownLatch不涉及锁定,
* 当count的值为零时当前线程继续运行。
* @author Wuyouxin
*
*/
public class MyContainer3 { volatile List<Object> list = new ArrayList<Object>(); public void add (Object o){
list.add(o);
} public int size (){
return list.size();
} public static void main(String[] args) {
final MyContainer3 c = new MyContainer3(); final CountDownLatch lock = new CountDownLatch(1); new Thread(new Runnable() {
@Override
public void run() {
System.out.println("t2启动 ");
if(c.size() != 5){
try {
lock.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("结束");
}
}, "t2").start(); try {
TimeUnit.SECONDS.sleep(1);
} catch (Exception e) {
} new Thread(new Runnable() { @Override
public void run() {
System.out.println("t1启动");
for (int i = 0; i < 10; i++) {
c.add(new Object());
System.out.println("add:" + i);
if (c.size() == 5){
lock.countDown();
}
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}, "t1").start();
}
}
-------------------- END ---------------------
最后附上作者的微信公众号地址和博客地址
公众号:wuyouxin_gzh

Herrt灬凌夜:https://www.cnblogs.com/wuyx/
高并发编程之synchronized的更多相关文章
- Java并发编程之synchronized关键字
整理一下synchronized关键字相关的知识点. 在多线程并发编程中synchronized扮演着相当重要的角色,synchronized关键字是用来控制线程同步的,可以保证在同一个时刻,只有一个 ...
- 高并发编程之ReentrantLock
上文学习jvm提供的同步方法synchronized的用法,一些常见的业务类型以及一道以前阿里的面试题,从中学习到了一些并发编程的一些规则以及建议,本文主要学习jdk提供的同步方法reentrantL ...
- 并发编程之synchronized锁(一)
一.设计同步器的意义 多线程编程中,有可能会出现多个线程同时访问同一个共享.可变资源的情况,这个资源我们称之其为临界资源:这种资源可能是:对象.变量.文件等. 共享:资源可以由多个线程同时访问 可变: ...
- 并发编程之synchronized(二)------jvm对synchronized的优化
一.锁的粗化 看如下代码 public class Test { StringBuffer stb = new StringBuffer(); public void test1(){ //jvm的优 ...
- Java并发编程之synchronized
在Java编程中,为了保证线程安全,有3种不同的思路1.互斥同步:包括synchronized和lock等. 2.非阻塞同步:如AtomicInteger的increaseAndGet()方法等. 3 ...
- Java 多线程并发编程之 Synchronized 关键字
synchronized 关键字解析 同步锁依赖于对象,每个对象都有一个同步锁. 现有一成员变量 Test,当线程 A 调用 Test 的 synchronized 方法,线程 A 获得 Test 的 ...
- 并发编程之synchronized关键字
synchronized关键字 synchronized关键字最主要的三种使用方式的总结 1.修饰实例方法,作用于当前对象实例加锁,进入同步代码块前要获得当前对象实例的锁 2.修饰静态方法,作用于当前 ...
- 并发编程之J.U.C的第二篇
并发编程之J.U.C的第二篇 3.2 StampedLock 4. Semaphore Semaphore原理 5. CountdownLatch 6. CyclicBarrier 7.线程安全集合类 ...
- 并发编程之:CountDownLatch
大家好,我是小黑,一个在互联网苟且偷生的农民工. 先问大家一个问题,在主线程中创建多个线程,在这多个线程被启动之后,主线程需要等子线程执行完之后才能接着执行自己的代码,应该怎么实现呢? Thread. ...
随机推荐
- pf
here Pro 排列n个不同的数成为长度为p的序列 每两个相同的数之间至少要隔着m个数 求排列总方案数 Input 三个整数 n,m,p output 输出一个数字表示序列组成方法,由于结果可能很大 ...
- 【CC2530强化实训04】定时器间隔定时实现按键N连击
[CC2530强化实训04]定时器间隔定时实现按键N连击 [题目要求] 2018年全国职业院校技能大赛“物联网技术应用”国赛(高职组)中关于感知层开发的难度陡然增大,三个题目均在Zigbee ...
- UNIX网络编程 第1章:简介和TCP/IP
1.1 按1.9节未尾的步骤找出你自己的网络拓扑的信息. 1.2 获取本书示例的源代码(见前言),编译并测试图1-5所示的TCP时间获取客户程序.运行这个程序若干次,每次以不同IP地址作为命令行参数. ...
- Java并发编程(4)--生产者与消费者模式介绍
一.前言 这种模式在生活是最常见的,那么它的场景是什么样的呢? 下面是我假象的,假设有一个仓库,仓库有一个生产者和一个消费者,消费者过来消费的时候会检测仓库中是否有库存,如果没有了则等待生产,如果有就 ...
- 【codeforces】【比赛题解】#861 CF Round #434 (Div.2)
本来是rated,现在变成unrated,你说气不气. 链接. [A]k-凑整 题意: 一个正整数\(n\)的\(k\)-凑整数是最小的正整数\(x\)使得\(x\)在十进制下末尾有\(k\)个或更多 ...
- HTML 多张图片无缝连接
<table border="0" cellspacing="0" cellpadding="0" style="heigh ...
- RNN BPTT
双向LSTM
- 【鬼脸原创】谷歌扩展--知乎V2.0
目的: 用键盘替代鼠标,做一个安静刷知乎的美男(女)子! 功能: 功能 按键 说明 直接定位到搜索框 q 打开 首页 w 打开 话题 e 打开 发现 r 打开 消息 m 打开 ...
- java基础68 JavaScript城市联动框(网页知识)
1.城市联动框 <!doctype html> <html> <head> <meta charset="utf-8"> <t ...
- 洛谷P3367并查集
传送门 #include <iostream> #include <cstdio> #include <cstring> #include <algorith ...