HRegionServer异常下线问题
==版本==
Hadoop:2.7.1
HBase:1.2.1
Zookeeper:3.4.6
==现象==
HBase集群启动一段时间之后,一部分HRegionServer会异常下线重启(用systemctl启动的,所以会重启)

==日志==
-- ::, WARN [regionserver/dscn34/10.11.2.32:] util.Sleeper: We slept 54143ms instead of 3000ms, this is likely due to a long garbage collecting pause and it's usually bad, see http://hbase.apache.org/book.html#trouble.rs.runtime.zkexpired
2018-09-21 00:27:51,972 INFO [dscn34,16020,1537407400327_ChoreService_2] regionserver.HRegionServer: dscn34,16020,1537407400327-MemstoreFlusherChore requesting flush of DBN_DHL,91,1473221287052.36e00f06c2b59dc4283f5d73ee91efed. because if has an old edit so flush to free WALs after random delay 77512ms
2018-09-21 00:27:51,972 WARN [JvmPauseMonitor] util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 51038ms
GC pool 'ParNew' had collection(s): count=1 time=41ms
2018-09-21 00:27:51,972 INFO [dscn34,16020,1537407400327_ChoreService_2] regionserver.HRegionServer: dscn34,16020,1537407400327-MemstoreFlusherChore requesting flush of DBN_FEDEX,24,1473221280323.b0e731a473f4c6d692dd5e2aa520289a. because if has an old edit so flush to free WALs after random delay 12692ms
2018-09-21 00:27:51,972 INFO [dscn34,16020,1537407400327_ChoreService_2] regionserver.HRegionServer: dscn34,16020,1537407400327-MemstoreFlusherChore requesting flush of DBN_ZTO,722417400271,1522145895300.7d6038e7685346c2a0e13924f123d83e. because if has an old edit so flush to free WALs after random delay 233845ms
2018-09-21 00:27:51,980 INFO [dscn34,16020,1537407400327_ChoreService_2] regionserver.HRegionServer: dscn34,16020,1537407400327-MemstoreFlusherChore requesting flush of DBN_EMS,7837291049398,1534937258760.041625bd69778d1db922c3965ca7cf08. because if has an old edit so flush to free WALs after random delay 179626ms
2018-09-21 00:27:51,980 INFO [dscn34,16020,1537407400327_ChoreService_2] regionserver.HRegionServer: dscn34,16020,1537407400327-MemstoreFlusherChore requesting flush of DBN_APEX,56,1478569982861.aee12cc19b94ea7615a8ba75b6e9f9c6. because if has an old edit so flush to free WALs after random delay 96643ms
2018-09-21 00:27:51,992 WARN [PriorityRpcServer.handler=10,queue=0,port=16020] ipc.RpcServer: (responseTooSlow): {"call":"Scan(org.apache.hadoop.hbase.protobuf.generated.ClientProtos$ScanRequest)","starttimems":1537460820587,"responsesize":1763,"method":"Scan","processingtimems":51404,"client":"10.11.2.32:43512","queuetimems":0,"class":"HRegionServer"}
2018-09-21 00:27:51,994 WARN [PriorityRpcServer.handler=1,queue=1,port=16020] ipc.RpcServer: (responseTooSlow): {"call":"Scan(org.apache.hadoop.hbase.protobuf.generated.ClientProtos$ScanRequest)","starttimems":1537460820588,"responsesize":1851,"method":"Scan","processingtimems":51393,"client":"10.11.2.4:49553","queuetimems":0,"class":"HRegionServer"}
2018-09-21 00:27:51,994 WARN [ResponseProcessor for block BP-1370501599-10.11.2.4-1466755309516:blk_1198373776_124709107] hdfs.DFSClient: Slow ReadProcessor read fields took 51384ms (threshold=30000ms); ack: seqno: 53686 status: SUCCESS status: SUCCESS downstreamAckTimeNanos: 353471 4: "\000\000", targets: [10.11.2.32:50010, 10.11.2.15:50010]
2018-09-21 00:27:51,994 WARN [sync.4] hdfs.DFSClient: Slow waitForAckedSeqno took 51398ms (threshold=30000ms)
2018-09-21 00:27:51,994 WARN [sync.0] hdfs.DFSClient: Slow waitForAckedSeqno took 51398ms (threshold=30000ms)
2018-09-21 00:27:52,000 WARN [sync.2] hdfs.DFSClient: Slow waitForAckedSeqno took 51404ms (threshold=30000ms)
2018-09-21 00:27:52,000 INFO [sync.2] wal.FSHLog: Slow sync cost: 51404 ms, current pipeline: [10.11.2.32:50010, 10.11.2.15:50010]
2018-09-21 00:27:52,000 WARN [PriorityRpcServer.handler=7,queue=1,port=16020] ipc.RpcServer: (responseTooSlow): {"call":"Multi(org.apache.hadoop.hbase.protobuf.generated.ClientProtos$MultiRequest)","starttimems":1537460820589,"responsesize":8,"method":"Multi","processingtimems":51411,"client":"10.11.2.25:41292","queuetimems":0,"class":"HRegionServer"}
2018-09-21 00:27:52,000 WARN [PriorityRpcServer.handler=12,queue=0,port=16020] ipc.RpcServer: (responseTooSlow): {"call":"Multi(org.apache.hadoop.hbase.protobuf.generated.ClientProtos$MultiRequest)","starttimems":1537460820589,"responsesize":8,"method":"Multi","processingtimems":51411,"client":"10.11.2.30:60065","queuetimems":0,"class":"HRegionServer"}
2018-09-21 00:27:52,000 WARN [PriorityRpcServer.handler=18,queue=0,port=16020] ipc.RpcServer: (responseTooSlow): {"call":"Multi(org.apache.hadoop.hbase.protobuf.generated.ClientProtos$MultiRequest)","starttimems":1537460820591,"responsesize":8,"method":"Multi","processingtimems":51409,"client":"10.11.2.31:50843","queuetimems":0,"class":"HRegionServer"}
2018-09-21 00:27:52,000 WARN [ResponseProcessor for block BP-1370501599-10.11.2.4-1466755309516:blk_1198373776_124709107] hdfs.DFSClient: DFSOutputStream ResponseProcessor exception for block BP-1370501599-10.11.2.4-1466755309516:blk_1198373776_124709107
java.io.EOFException: Premature EOF: no length prefix available
at org.apache.hadoop.hdfs.protocolPB.PBHelper.vintPrefixed(PBHelper.java:2000)
at org.apache.hadoop.hdfs.protocol.datatransfer.PipelineAck.readFields(PipelineAck.java:176)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer$ResponseProcessor.run(DFSOutputStream.java:798)
2018-09-21 00:27:52,000 WARN [sync.3] hdfs.DFSClient: Slow waitForAckedSeqno took 51404ms (threshold=30000ms)
2018-09-21 00:27:52,001 INFO [sync.3] wal.FSHLog: Slow sync cost: 51405 ms, current pipeline: [10.11.2.32:50010, 10.11.2.15:50010]
2018-09-21 00:27:51,999 WARN [PriorityRpcServer.handler=17,queue=1,port=16020] ipc.RpcServer: (responseTooSlow): {"call":"Multi(org.apache.hadoop.hbase.protobuf.generated.ClientProtos$MultiRequest)","starttimems":1537460820588,"responsesize":8,"method":"Multi","processingtimems":51410,"client":"10.11.2.33:37983","queuetimems":0,"class":"HRegionServer"}
2018-09-21 00:27:51,999 WARN [PriorityRpcServer.handler=13,queue=1,port=16020] ipc.RpcServer: (responseTooSlow): {"call":"Multi(org.apache.hadoop.hbase.protobuf.generated.ClientProtos$MultiRequest)","starttimems":1537460820594,"responsesize":8,"method":"Multi","processingtimems":51404,"client":"10.11.2.31:51053","queuetimems":0,"class":"HRegionServer"}
2018-09-21 00:27:52,001 WARN [PriorityRpcServer.handler=0,queue=0,port=16020] ipc.RpcServer: (responseTooSlow): {"call":"Multi(org.apache.hadoop.hbase.protobuf.generated.ClientProtos$MultiRequest)","starttimems":1537460820589,"responsesize":8,"method":"Multi","processingtimems":51412,"client":"10.11.2.31:50956","queuetimems":0,"class":"HRegionServer"}
2018-09-21 00:27:52,001 WARN [PriorityRpcServer.handler=14,queue=0,port=16020] ipc.RpcServer: (responseTooSlow): {"call":"Scan(org.apache.hadoop.hbase.protobuf.generated.ClientProtos$ScanRequest)","starttimems":1537460820596,"responsesize":987,"method":"Scan","processingtimems":51405,"client":"10.11.2.32:42054","queuetimems":0,"class":"HRegionServer"}
2018-09-21 00:27:52,001 WARN [DataStreamer for file /hbase/WALs/dscn34,16020,1537407400327/dscn34%2C16020%2C1537407400327.default.1537460773988 block BP-1370501599-10.11.2.4-1466755309516:blk_1198373776_124709107] hdfs.DFSClient: Error Recovery for block BP-1370501599-10.11.2.4-1466755309516:blk_1198373776_124709107 in pipeline 10.11.2.32:50010, 10.11.2.15:50010: bad datanode 10.11.2.32:50010
2018-09-21 00:27:51,994 INFO [sync.4] wal.FSHLog: Slow sync cost: 51398 ms, current pipeline: [10.11.2.32:50010, 10.11.2.15:50010]
2018-09-21 00:27:51,994 WARN [sync.1] hdfs.DFSClient: Slow waitForAckedSeqno took 51398ms (threshold=30000ms)
2018-09-21 00:27:52,001 WARN [PriorityRpcServer.handler=2,queue=0,port=16020] ipc.RpcServer: (responseTooSlow): {"call":"Multi(org.apache.hadoop.hbase.protobuf.generated.ClientProtos$MultiRequest)","starttimems":1537460820588,"responsesize":8,"method":"Multi","processingtimems":51413,"client":"10.11.2.24:36206","queuetimems":0,"class":"HRegionServer"}
2018-09-21 00:27:52,000 WARN [PriorityRpcServer.handler=4,queue=0,port=16020] ipc.RpcServer: (responseTooSlow): {"call":"Multi(org.apache.hadoop.hbase.protobuf.generated.ClientProtos$MultiRequest)","starttimems":1537460820590,"responsesize":8,"method":"Multi","processingtimems":51410,"client":"10.11.2.25:41236","queuetimems":0,"class":"HRegionServer"}
2018-09-21 00:27:52,000 WARN [PriorityRpcServer.handler=19,queue=1,port=16020] ipc.RpcServer: (responseTooSlow): {"call":"Multi(org.apache.hadoop.hbase.protobuf.generated.ClientProtos$MultiRequest)","starttimems":1537460820589,"responsesize":8,"method":"Multi","processingtimems":51411,"client":"10.11.2.25:41436","queuetimems":0,"class":"HRegionServer"}
2018-09-21 00:27:52,002 WARN [PriorityRpcServer.handler=15,queue=1,port=16020] ipc.RpcServer: (responseTooSlow): {"call":"Multi(org.apache.hadoop.hbase.protobuf.generated.ClientProtos$MultiRequest)","starttimems":1537460820589,"responsesize":8,"method":"Multi","processingtimems":51413,"client":"10.11.2.31:51096","queuetimems":0,"class":"HRegionServer"}
2018-09-21 00:27:52,002 WARN [sync.1] wal.FSHLog: HDFS pipeline error detected. Found 1 replicas but expecting no less than 2 replicas. Requesting close of WAL. current pipeline: [10.11.2.15:50010]
2018-09-21 00:27:52,002 INFO [sync.1] wal.FSHLog: Slow sync cost: 51406 ms, current pipeline: [10.11.2.15:50010]
2018-09-21 00:27:52,000 INFO [sync.0] wal.FSHLog: Slow sync cost: 51404 ms, current pipeline: [10.11.2.32:50010, 10.11.2.15:50010]
2018-09-21 00:27:52,002 WARN [PriorityRpcServer.handler=8,queue=0,port=16020] ipc.RpcServer: (responseTooSlow): {"call":"Multi(org.apache.hadoop.hbase.protobuf.generated.ClientProtos$MultiRequest)","starttimems":1537460820590,"responsesize":8,"method":"Multi","processingtimems":51412,"client":"10.11.2.32:47637","queuetimems":0,"class":"HRegionServer"}
2018-09-21 00:27:52,007 WARN [PriorityRpcServer.handler=5,queue=1,port=16020] ipc.RpcServer: (responseTooSlow): {"call":"Multi(org.apache.hadoop.hbase.protobuf.generated.ClientProtos$MultiRequest)","starttimems":1537460820591,"responsesize":8,"method":"Multi","processingtimems":51411,"client":"10.11.2.32:47398","queuetimems":0,"class":"HRegionServer"}
2018-09-21 00:27:52,026 WARN [DataStreamer for file /hbase/WALs/dscn34,16020,1537407400327/dscn34%2C16020%2C1537407400327.default.1537460773988 block BP-1370501599-10.11.2.4-1466755309516:blk_1198373776_124709107] hdfs.DFSClient: DataStreamer Exception
org.apache.hadoop.ipc.RemoteException(java.io.IOException): BP-1370501599-10.11.2.4-1466755309516:blk_1198373776_124709107 does not exist or is not under Constructionblk_1198373776_124710071
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkUCBlock(FSNamesystem.java:6238)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.updateBlockForPipeline(FSNamesystem.java:6305)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.updateBlockForPipeline(NameNodeRpcServer.java:804)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.updateBlockForPipeline(ClientNamenodeProtocolServerSideTranslatorPB.java:955)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:616)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:969)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2049)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2045)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2043) at org.apache.hadoop.ipc.Client.call(Client.java:1411)
at org.apache.hadoop.ipc.Client.call(Client.java:1364)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:206)
at com.sun.proxy.$Proxy16.updateBlockForPipeline(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.updateBlockForPipeline(ClientNamenodeProtocolTranslatorPB.java:832)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at com.sun.proxy.$Proxy17.updateBlockForPipeline(Unknown Source)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.hadoop.hbase.fs.HFileSystem$1.invoke(HFileSystem.java:279)
at com.sun.proxy.$Proxy18.updateBlockForPipeline(Unknown Source)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.setupPipelineForAppendOrRecovery(DFSOutputStream.java:1188)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.processDatanodeError(DFSOutputStream.java:933)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:487)
2018-09-21 00:27:52,026 FATAL [regionserver/dscn34/10.11.2.32:16020.logRoller] regionserver.LogRoller: Aborting
java.io.IOException: cannot get log writer
at org.apache.hadoop.hbase.wal.DefaultWALProvider.createWriter(DefaultWALProvider.java:365)
at org.apache.hadoop.hbase.regionserver.wal.FSHLog.createWriterInstance(FSHLog.java:724)
at org.apache.hadoop.hbase.regionserver.wal.FSHLog.rollWriter(FSHLog.java:689)
at org.apache.hadoop.hbase.regionserver.LogRoller.run(LogRoller.java:148)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.io.FileNotFoundException: Parent directory doesn't exist: /hbase/WALs/dscn34,,
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.verifyParentDir(FSDirectory.java:)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInternal(FSNamesystem.java:)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInt(FSNamesystem.java:)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFile(FSNamesystem.java:)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.create(NameNodeRpcServer.java:)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.create(ClientNamenodeProtocolServerSideTranslatorPB.java:)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:)
at org.apache.hadoop.ipc.Server$Handler$.run(Server.java:)
at org.apache.hadoop.ipc.Server$Handler$.run(Server.java:)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:) at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:)
at java.lang.reflect.Constructor.newInstance(Constructor.java:)
at org.apache.hadoop.ipc.RemoteException.instantiateException(RemoteException.java:)
at org.apache.hadoop.ipc.RemoteException.unwrapRemoteException(RemoteException.java:)
at org.apache.hadoop.hdfs.DFSOutputStream.newStreamForCreate(DFSOutputStream.java:)
at org.apache.hadoop.hdfs.DFSClient.create(DFSClient.java:)
at org.apache.hadoop.hdfs.DFSClient.create(DFSClient.java:)
at org.apache.hadoop.hdfs.DistributedFileSystem$.doCall(DistributedFileSystem.java:)
at org.apache.hadoop.hdfs.DistributedFileSystem$.doCall(DistributedFileSystem.java:)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:)
at org.apache.hadoop.hdfs.DistributedFileSystem.createNonRecursive(DistributedFileSystem.java:)
at org.apache.hadoop.fs.FileSystem.createNonRecursive(FileSystem.java:)
at org.apache.hadoop.fs.FileSystem.createNonRecursive(FileSystem.java:)
at org.apache.hadoop.hbase.regionserver.wal.ProtobufLogWriter.init(ProtobufLogWriter.java:)
at org.apache.hadoop.hbase.wal.DefaultWALProvider.createWriter(DefaultWALProvider.java:)
... more
Caused by: org.apache.hadoop.ipc.RemoteException(java.io.FileNotFoundException): Parent directory doesn't exist: /hbase/WALs/dscn34,16020,1537407400327
at org.apache.hadoop.hdfs.server.namenode.FSDirectory.verifyParentDir(FSDirectory.java:1722)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInternal(FSNamesystem.java:2520)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInt(FSNamesystem.java:2452)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFile(FSNamesystem.java:2335)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.create(NameNodeRpcServer.java:623)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.create(ClientNamenodeProtocolServerSideTranslatorPB.java:397)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:616)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:969)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2049)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2045)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2043) at org.apache.hadoop.ipc.Client.call(Client.java:1411)
at org.apache.hadoop.ipc.Client.call(Client.java:1364)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:206)
at com.sun.proxy.$Proxy16.create(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.create(ClientNamenodeProtocolTranslatorPB.java:264)
at sun.reflect.GeneratedMethodAccessor24.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at com.sun.proxy.$Proxy17.create(Unknown Source)
at sun.reflect.GeneratedMethodAccessor24.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.hadoop.hbase.fs.HFileSystem$1.invoke(HFileSystem.java:279)
at com.sun.proxy.$Proxy18.create(Unknown Source)
at org.apache.hadoop.hdfs.DFSOutputStream.newStreamForCreate(DFSOutputStream.java:1612)
... 14 more
==原因==
从下线的HRegionServer的日志中可以看到GC花了51038ms。
网友说多数情况时以内GC的时间过长,超过了HRegionServer与ZK的连接时间,
被判定为异常,所以HRegionServer才被迫下线。
那么,HBase连接Zookeeper的连接超时时间是多少呢?
从HBase的配置页面上看到的信息是这样的,没有超过GC时间

来看看HBase官网对这个配置项的介绍,
<property>
<name>zookeeper.session.timeout</name>
<value></value>
<description>ZooKeeper session timeout in milliseconds. It is used in two different ways.
First, this value is used in the ZK client that HBase uses to connect to the ensemble.
It is also used by HBase when it starts a ZK server and it is passed as the 'maxSessionTimeout'. See
http://hadoop.apache.org/zookeeper/docs/current/zookeeperProgrammers.html#ch_zkSessions.
For example, if a HBase region server connects to a ZK ensemble that's also managed by HBase, then the
session timeout will be the one specified by this configuration. But, a region server that connects
to an ensemble managed with a different configuration will be subjected that ensemble's maxSessionTimeout. So,
even though HBase might propose using seconds, the ensemble can have a max timeout lower than this and
it will take precedence. The current default that ZK ships with is seconds, which is lower than HBase's.
</description>
</property>
注意看最后的一句话:
HBase建议的时间是90秒,如果全局中有比这个值低的,将优先使用这个低的值,需要注意的是zk的默认时间是40秒。
OK,非常重要的线索,那我们来看看zk的超时时间吧。
先来看看zk源码中,对sessionTimeOut时间的计算方式
如图:
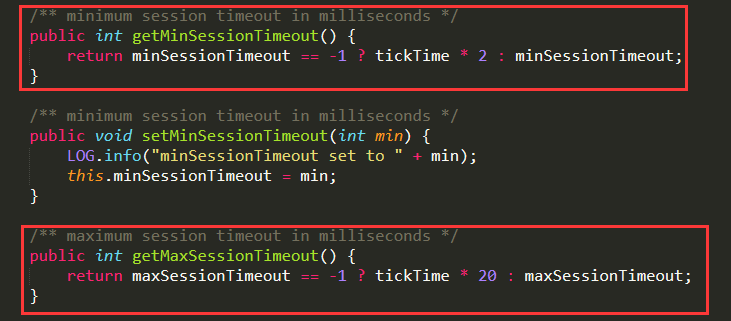
代码如下:
/** minimum session timeout in milliseconds */
public int getMinSessionTimeout() {
return minSessionTimeout == -1 ? tickTime * 2 : minSessionTimeout;
} /** maximum session timeout in milliseconds */
public int getMaxSessionTimeout() {
return maxSessionTimeout == -1 ? tickTime * 20 : maxSessionTimeout;
}
再来看看zk的启动日志中,可以看到tickTime为默认的2000,
所以,zk的连接最大超时时间应该是2000 * 20 = 40000,即40s。
也就是说HRegionServer与ZK的连接超时时间实际为40秒。
-- ::, [myid:] - INFO [main:QuorumPeer@] - tickTime set to
-- ::, [myid:] - INFO [main:QuorumPeer@] - minSessionTimeout set to -
-- ::, [myid:] - INFO [main:QuorumPeer@] - maxSessionTimeout set to -
到这里基本上已经知道答案了,HBase的GC一共花费了50多秒,
超过了与ZK的连接时间,被判定为异常,所以被强制下线。
==解决==
广大网友给了解决办法,就是调整JVM参数。
HBase配置文件:hbase-env.sh
调优项目:
-XX:+UseParNewGC:设置年轻代为并行收集。
-XX:+UseConcMarkSweepGC:使用CMS内存收集 。
-XX:+UseCompressedClassPointers:压缩类指针。
-XX:+UseCompressedOops:压缩对象指针。
-XX:+UseCMSCompactAtFullCollection:使用并发收集器时,开启对年老代的压缩。
-XX:CMSInitiatingOccupancyFraction=80:使用cms作为垃圾回收使用80%后开始CMS收集。
配置结果如图:

修改完配置文件之后,重启HBase集群,使用jinfo查看一下HRegionServer的JVM配置是否生效。

==结果==
HBase运行几天之后,没有发生HRegionServer异常下线的情况
==注意==
在使用下面这两个JVM参数的时候,JVM的HeapSize不能超过32G
-XX:+UseCompressedClassPointers
-XX:+UseCompressedOops
如果超过32G会出现一下错误提示:

--END--
HRegionServer异常下线问题的更多相关文章
- 经纪xx系统节点VIP案例介绍和深入分析异常
系统环境 硬件平台 & 操作 IBM 570 操作系统版本号 AIX 5.3 物理内存 32G Oracle 产品及版本号 10.2.0.5 RAC 业务类型 OLTP 背 ...
- Solr In Action 笔记(3) 之 SolrCloud基础
Solr In Action 笔记(3) 之 SolrCloud基础 在Solr中,一个索引的实例称之为Core,而在SolrCloud中,一个索引的实例称之为Shard:Shard 又分为leade ...
- Signalr 实现心跳包
项目分析: 一个实时的IM坐席系统,客户端和坐席使用IM通信,客户端使用android和ios的app,坐席使用web. web端可以保留自己的登录状态,但为防止意外情况的发生(如浏览器异常关闭,断网 ...
- HslCommunication组件库使用说明 (转载)
一个由个人开发的组件库,携带了一些众多的功能,包含了数据网络通信,文件上传下载,日志组件,PLC访问类,还有一些其他的基础类库. nuget地址:https://www.nuget.org/packa ...
- springboot-admin自定义事件通知
springboot-admin组建已经提供了很多开箱即用的通知器(例如邮件),但在有些业务场景下我们需要做一些企业内部的通知渠道,这就需要我们来自定义通知器. 实现其实很简单,只需要往spring注 ...
- HslCommunication组件库使用说明
一个由个人开发的组件库,携带了一些众多的功能,包含了数据网络通信,文件上传下载,日志组件,PLC访问类,还有一些其他的基础类库. nuget地址:https://www.nuget.org/packa ...
- Oracle DG备库强制switch_over过程
故障描述: 主库异常下线,需要将备库强制启动为主库,切断日志时提示需要介质恢复,执行介质恢复后,再激活日志即可进行切换 1. 执行alter database recover managed sta ...
- NIO--2-代码
package com.study.nio; import java.io.IOException; import java.net.InetSocketAddress; import java.ni ...
- 解析Ceph: 恢复与数据一致性
转自:https://www.ustack.com/blog/ceph-internal-recovery-and-consistency/ 作为一个面向大规模的分布式存储系统,故障处理是作为一个常态 ...
随机推荐
- git超详细教程留着当手册
GitHub操作流程 : 第一次提交 : 方案一 : 本地创建项目根目录, 然后与远程GitHub关联, 之后的操作一样; -- 初始化Git仓库 :git init ; -- 提交改变到缓存 :gi ...
- 6. 纯 CSS 绘制一颗闪闪发光的璀璨钻石
原文地址:https://segmentfault.com/a/1190000014652116 HTML代码: <div class="diamond"> <s ...
- Sum All Numbers in a Range(两数之间数字总和)
题目:我们会传递给你一个包含两个数字的数组.返回这两个数字和它们之间所有数字的和. 最小的数字并非总在最前面. /*方法一: 公式法 (首+末)*项数/2 */ /*两个数比较大小的函数*/ func ...
- linux 之 压缩 / 解压
压缩解压 tar 即可压缩也可以解压 c 压缩 如果没有z.j参数,则表示,只打包,不压缩. 就说, t 查看 z 以gzip方式压缩 相当于 gzip ?.. j 以bzip方式压缩 bzip2 ? ...
- 49. jdk-6u45-linux-i586.bin安装步骤
# chmod u+x ./jdk-6u45-linux-i586.bin 1.# ./jdk-6u45-linux-i586.bin 在按提示输入yes后,jdk被解压到./jdk1.6.0_45目 ...
- Table-Driven Design 表驱动设计
注:本文所有代码来自 http://www.codeproject.com/Articles/42732/Table-driven-Approach 在许多程序中,经常需要处理那些拥有种种色色不同特性 ...
- css上下或者上中下 自适应布局
方法就是头部不变,中间和底部绝对定位 *{ margin: ; padding: ; } div{ text-align: center; font-size: 30px; } .header,.fo ...
- jsp button onclick
<input type="button" value="MD5哈希转换" onclick="javascript:document.getEle ...
- zookeeper的配置参数详解(zoo.cfg)
配置参数详解(主要是%ZOOKEEPER_HOME%/conf/zoo.cfg文件) 参数名 说明 clientPort 客户端连接server的端口,即对外服务端口,一般设置为2181吧. data ...
- python, Django csrf token的问题
环境 Window 7 Python2.7 Django1.4.1 sqlite3 问题 在使用Django搭建好测试环境后,写了一个提交POST表单提交留言的测试页面. 如图: 填写表单,点击“提交 ...