流式大数据计算实践(1)----Hadoop单机模式
一、前言
1、从今天开始进行流式大数据计算的实践之路,需要完成一个车辆实时热力图
2、技术选型:HBase作为数据仓库,Storm作为流式计算框架,ECharts作为热力图的展示
3、计划使用两台虚拟机来打一个小型的分布式系统,使用Ubuntu系统
二、HBase简介
1、HBase是基于HDFS(Hadoop分布式文件系统)的NoSQL数据库,采用k-v的存储方式,所以查询速度相对比较快。
2、下面画图比较HBase与传统的RDS(关系型数据库)数据库的区别
(1)RDS,经常用的比如MySQL、SQLServer等数据库,通过指定第几行第几列就可以唯一确定找到数据

(2)HBase
①首先需要指定row key(行键)来找到某一行,row key是一个可以由用户指定的字符串,保证其唯一,排序则是按照字典顺序
②指定column family(列族)找到某个列族,在设计时,官方建议列族设置的越少越好(保证查询速度,并且不容易出bug)
③指定colume(列名)找到某一列,一个列族会有多个列
④指定version来找到cell(单元格,单元格内存放着具体的数据),单元格的目的是为每一列设置多个版本,可以用时间戳代替
综上可以看出,当需要查询一个数据时的表达式应是------(行键:列族:列:版本号),才能唯一确定一个值,当然版本号可以省略,当省略时,默认取最后一个版本的值返回

三、环境搭建
1、首先准备两台Ubuntu虚拟机,我使用的是VirtualBox虚拟机,Ubuntu系统为16.04 x64,并保证其在同一局域网
2、我直接用su切换到root下,方便使用,但要注意不要输错命令
3、安装ssh,用xshell登录方便使用
apt-get install openssh-server
4、集群中机器访问使用主机名访问,所以修改主机名,一台为storm1,一台为storm2,修改完成后需要重启机器生效
vim /etc/hostname storm1 reboot
5、配置hosts文件,保证集群内的机器可以通过主机名找到其他机器
vim /etc/hosts 192.168.3.77 storm1
192.168.3.78 storm2
6、配置SSH免密登录,具体配置参见教程,确保两台机可以互相ssh登录对方
7、安装JDK
(1)下载jdk的tar.gz包,然后解压
tar zxvf jdk-8u191-linux-x64.tar.gz
(2)配置环境变量
vim /etc/profile #set java env
export JAVA_HOME=/work/soft/jdk1.8.0_191
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH source /etc/profile
8、安装Hadoop
(1)搭建单机模式
(2)下载hadoop的tar.gz包,然后解压
(3)配置环境变量(注意默认的JAVA_HOME会报错,所以要改路径)
vim /etc/profile #set hadoop env
export HADOOP_HOME=/work/soft/hadoop-2.6.4
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME export JAVA_HOME=/work/soft/jdk1.8.0_191 source /etc/profile
(3)配置hadoop-env.sh(设置jvm的使用内存和日志文件夹),要记得创建好日志文件夹
vim /work/soft/hadoop-2.6.4/etc/hadoop/hadoop-env.sh export HADOOP_NAMENODE_OPTS=" -Xms1024m -Xmx1024m -XX:+UseParallelGC"
export HADOOP_DATANODE_OPTS=" -Xms1024m -Xmx1024m"
export HADOOP_LOG_DIR=/work/hadoop/logs
(4)配置core-site.xml(配置Hadoop的Web属性 )
vim /work/soft/hadoop-2.6.4/etc/hadoop/core-site.xml <configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://storm1:8020</value>
</property>
</configuration>
(5)配置hdfs-site.xml(要记得创建好对应的文件夹,所有的节点的配置文件都是一样设置)
①设置hdfs的数据备份数量
②设置namenode节点存储文件的位置
③设置datanode节点存储文件的位置
vim /work/soft/hadoop-2.6.4/etc/hadoop/hdfs-site.xml <configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///work/hadoop/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///work/hadoop/dn</value>
</property>
</configuration>
(6)格式化namenode
hdfs namenode -format
(7)启动单机模式
$HADOOP_PREFIX/sbin/start-dfs.sh
(8)访问hadoop的控制台http://192.168.3.77:50070/
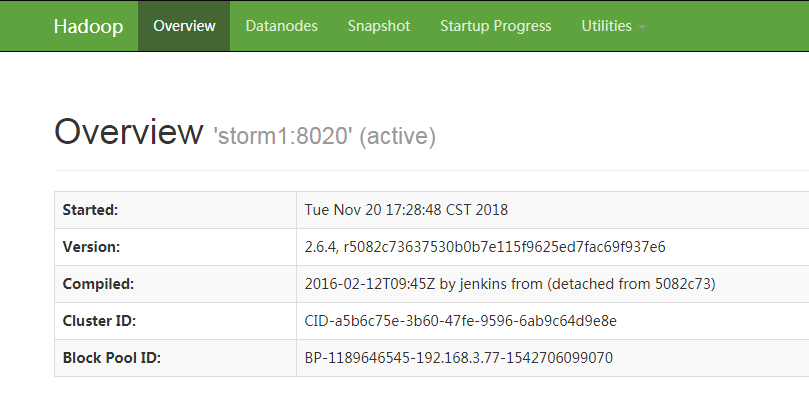
(9)停止单机版集群
stop-dfs.sh
流式大数据计算实践(1)----Hadoop单机模式的更多相关文章
- 流式大数据计算实践(2)----Hadoop集群和Zookeeper
一.前言 1.上一文搭建好了Hadoop单机模式,这一文继续搭建Hadoop集群 二.搭建Hadoop集群 1.根据上文的流程得到两台单机模式的机器,并保证两台单机模式正常启动,记得第二台机器core ...
- 流式大数据计算实践(6)----Storm简介&使用&安装
一.前言 1.这一文开始进入Storm流式计算框架的学习 二.Storm简介 1.Storm与Hadoop的区别就是,Hadoop是一个离线执行的作业,执行完毕就结束了,而Storm是可以源源不断的接 ...
- 流式大数据计算实践(4)----HBase安装
一.前言 1.前面我们搭建好了高可用的Hadoop集群,本文正式开始搭建HBase 2.HBase简介 (1)Master节点负责管理数据,类似Hadoop里面的namenode,但是他只负责建表改表 ...
- 流式大数据计算实践(3)----高可用的Hadoop集群
一.前言 1.上文中我们已经搭建好了Hadoop和Zookeeper的集群,这一文来将Hadoop集群变得高可用 2.由于Hadoop集群是主从节点的模式,如果集群中的namenode主节点挂掉,那么 ...
- 流式大数据计算实践(7)----Hive安装
一.前言 1.这一文学习使用Hive 二.Hive介绍与安装 Hive介绍:Hive是基于Hadoop的一个数据仓库工具,可以通过HQL语句(类似SQL)来操作HDFS上面的数据,其原理就是将用户写的 ...
- 流式大数据计算实践(5)----HBase使用&SpringBoot集成
一.前言 1.上文中我们搭建好了一套HBase集群环境,这一文我们学习一下HBase的基本操作和客户端API的使用 二.shell操作 先通过命令进入HBase的命令行操作 /work/soft/hb ...
- 大数据计算框架Hadoop, Spark和MPI
转自:https://www.cnblogs.com/reed/p/7730338.html 今天做题,其中一道是 请简要描述一下Hadoop, Spark, MPI三种计算框架的特点以及分别适用于什 ...
- 大数据软件安装之Hadoop(Apache)(数据存储及计算)
大数据软件安装之Hadoop(Apache)(数据存储及计算) 一.生产环境准备 1.修改主机名 vim /etc/sysconfig/network 2.修改静态ip vim /etc/udev/r ...
- 大数据计算平台Spark内核解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着 Spark在大数据计算领域的暂露头角,越来越多 ...
随机推荐
- 2019.03.28 bzoj3325: [Scoi2013]密码(manacher+模拟)
传送门 题意: 现在有一个nnn个小写字母组成的字符串sss. 然后给你nnn个数aia_iai,aia_iai表示以sis_isi为中心的最长回文串串长. 再给你n−1n-1n−1个数bib_ ...
- ireport图形化界面生成pdf文档
一.ireport软件安装 1.下载软件的官网 https://community.jaspersoft.com/project/ireport-designer/releases 2.安装软件 ...
- 手机端-万种bt在线观看器,安卓正版下载
安卓正版下载, 点击下载 无广告,完全免费!寻找任何你想要的资源!
- 对状压dp的一点理解
此dp可以理解为最暴力的dp,因为他需要遍历每个状态,所以将会出现2^n的情况数量,所以明显的标志就是数据不能太多(好像是<=15?),然后遍历所有状态的姿势就是用二进制来表示,01串,1表示 ...
- java性能分析工具
jcmd:向JVM发送诊断的命令,jvm未必会全部响应,有些需要在jvm开启相应功能才能响应.个人平时用的不是很多. SampleA: 添加 jcmd pid VM.native_mem ...
- window7 32位部署django
window7 32位安装环境,所有的软件都用32位的,如果你想要用64位的软件需要操作系统和下面的相关软件都换成64位,我是在虚拟机上装了win7 32版做的测试. 软件下载地址: python2. ...
- Django+easyui 快速开发
Django的使用我们可以查看上一篇博客,今天我们要在Django中使用easyui快速开发,在我们安装好Django, 我们可以道改地址那一下easyui 官方API文档(http://downlo ...
- Oracle数据库---用户与角色
Oracle数据库---用户与角色 2019年02月26日 10:56:10 俊杰梓 阅读数:21 标签: 数据库 更多 个人分类: 数据库 版权声明:版权所有,转载请注明出处.谢谢 https: ...
- 写在HTTP协议之前
1.网络模型 OSI模型即:开放系统互连参考模型(Open System Interconnect 简称OSI)是国际标准化组织(ISO)和国际电报电话咨询委员会(CCITT)联合制定的开放系统互连参 ...
- 复习java基础
十进制转换成二进制: 方法:整除法,计数方式从右往左,二进制中非0即1.例子如下: 计数方式是从右往左进行,然后填写数字的顺序是余数优先 二进制转换成十进制: 方法:乘二法,例如二进制数字为: ...