15行Python 仿百度搜索引擎
开发工具:PyCharm
开发环境:python3.6 + flask + requests
开发流程:
1. 启动一个web服务
from flask import Flask
app = Flask(__name__)
if __name__ == '__main__':
app.run(host='127.0.0.1', port=6666)
2. 增加app.route装饰器
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return 'Hello World'
if __name__ == '__main__':
app.run(host='127.0.0.1', port=5000)
3. 增加index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>仿百度搜索</title>
<style type="text/css">
.align-center{
position:fixed;left:30%;top:30%;margin-left:width/2;margin-top:height/2;
}
</style>
</head>
<body>
<form action="/s" method="get">
<div class="align-center">
<input type="search" name="key"> <input type="submit" value="搜索"><br>
</div>
</form>
</body>
</html>
index.html
4. 增加 render_template
from flask import Flask
from flask import render_template
app = Flask(__name__) @app.route('/')
def index():
return render_template('index.html')
if __name__ == '__main__':
app.run(host='127.0.0.1', port=5000)
5. 增加返回结果
@app.route('/s')
def search():
return 'Hello World'
6. spider.py
import requests def getBdMsg(keyword):
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"}
res = requests.get('https://www.baidu.com/s?wd={}'.format(keyword), headers = headers).text
return res
7. 获取搜索框关键字,通过爬虫程序搜索,获得百度搜索结果
from flask import Flask
from flask import render_template
from flask import request
from spider import getBdMsg
app = Flask(__name__) @app.route('/')
def index():
return render_template('index.html') @app.route('/s')
def search():
keyword = request.args.get("key")
text = getBdMsg(keyword)
return text if __name__ == '__main__':
app.run(host='127.0.0.1', port=5000)
8. 修改spider.py的返回结果,通过链式replace(),替换百度图标和“百度一下”
return res.replace('//www.baidu.com/img/baidu_jgylogo3.gif','static/images/google.png').replace('百度一下', 'Google')

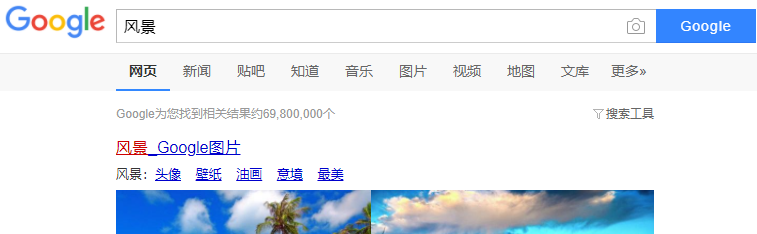
附完整源码:
# -*- coding: utf-8 -*-
# @Time : 2018/3/19 12:46
# @Author : TanRong
# @Software: PyCharm
# @File : search.py from flask import Flask
from flask import render_template
from spider import getBdMsg
from flask import request # Flask(__name__).run()
app = Flask(__name__) #app.route装饰器
@app.route('/')
def index():
return render_template('index.html') @app.route('/s')
def search():
keyword = request.args.get('key')
text = getBdMsg(keyword)
return text if __name__ == '__main__':
app.run()
search.py
# -*- coding: utf-8 -*-
# @Time : 2018/3/21 18:07
# @Author : TanRong
# @Software: PyCharm
# @File : spider.py import requests def getBdMsg(keyword):
# 必须加上请求头,这样才是浏览器请求,不然无返回结果
# F12 - NetWork - Requeset Headers - UserAgent
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"}
res = requests.get('https://www.baidu.com/s?wd={}'.format(keyword), headers = headers).text
return res.replace('//www.baidu.com/img/baidu_jgylogo3.gif','static/images/google.png').replace('百度一下','Google').replace('百度','Google') #链式replace() if __name__ == '__main__':
getBdMsg('风景')
spider.py
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>仿百度搜索</title>
<style type="text/css">
.align-center{
position:fixed;left:30%;top:30%;margin-left:width/2;margin-top:height/2;
}
</style>
</head>
<body>
<form action="/s" method="get">
<div class="align-center">
<input type="search" name="key"> <input type="submit" value="搜索"><br>
</div>
</form>
</body>
</html>
index.html
15行Python 仿百度搜索引擎的更多相关文章
- 15行python代码,帮你理解令牌桶算法
本文转载自: http://www.tuicool.com/articles/aEBNRnU 在网络中传输数据时,为了防止网络拥塞,需限制流出网络的流量,使流量以比较均匀的速度向外发送,令牌桶算法 ...
- 15行python代码实现人脸识别
方法一:face_recognition import cv2 import face_recognition img_path = "C:/Users/CJK/Desktop/1.jpg& ...
- 仿百度壁纸客户端(五)——实现搜索动画GestureDetector手势识别,动态更新搜索关键字
仿百度壁纸客户端(五)--实现搜索动画GestureDetector手势识别,动态更新搜索关键字 百度壁纸系列 仿百度壁纸客户端(一)--主框架搭建,自定义Tab + ViewPager + Frag ...
- 百度搜索引擎关键字URL采集爬虫优化行业定投方案高效获得行业流量-代码篇
需要结合:<百度搜索引擎关键字URL采集爬虫优化行业定投方案高效获得行业流量--笔记篇> 一起看. #!/user/bin/env python # -*- coding:utf-8 -* ...
- WPF仿百度Echarts人口迁移图
GitHub地址:https://github.com/ptddqr/wpf-echarts-map/tree/master 关于大名鼎鼎的百度Echarts我就不多说了 不了解的朋友直接看官方的例子 ...
- 一个 11 行 Python 代码实现的神经网络
一个 11 行 Python 代码实现的神经网络 2015/12/02 · 实践项目 · 15 评论· 神经网络 分享到:18 本文由 伯乐在线 - 耶鲁怕冷 翻译,Namco 校稿.未经许可,禁止转 ...
- js仿百度文库文档上传页面的分类选择器_第二版
仿百度文库文档上传页面的多级联动分类选择器第二版,支持在一个页面同一时候使用多个分类选择器. 此版本号把HTML,CSS,以及图片都封装到"category.js"中.解决因文件路 ...
- 仿百度壁纸客户端(六)——完结篇之Gallery画廊实现壁纸预览已经项目细节优化
仿百度壁纸客户端(六)--完结篇之Gallery画廊实现壁纸预览已经项目细节优化 百度壁纸系列 仿百度壁纸客户端(一)--主框架搭建,自定义Tab + ViewPager + Fragment 仿百度 ...
- JAVA仿百度分页
最近在做一个仿百度网盘的网页小应用,找到了一个优雅简洁的分页插件,和百度搜索的分页很相似,对他进行了二次封装,拿出来跟大家分享下 插件源码 /** * This jQuery plugin displ ...
随机推荐
- 04 if条件判断 流程控制
条件判断 if 语法一: if 条件: # 条件成立时执行的子代码块 代码1 代码2 代码3 示例: sex='female' age=18 is_beautiful=True if sex == ' ...
- python中的各种锁
一.全局解释器锁(GIL) 1.什么是全局解释器锁 在同一个进程中只要有一个线程获取了全局解释器(cpu)的使用权限,那么其他的线程就必须等待该线程的全局解释器(cpu)使 用权消失后才能使用全局解释 ...
- Android广播机制
原文出处: Android总结篇系列:Android广播机制 1.Android广播机制概述 Android广播分为两个方面:广播发送者和广播接收者,通常情况下,BroadcastReceiver指的 ...
- CodeCraft-19 and Codeforces Round #537 (Div. 2) 题解
传送门 D. Destroy the Colony 首先明确题意:除了规定的两种(或一种)字母要在同侧以外,其他字母也必须在同侧. 发现当每种字母在左/右边确定之后,方案数就确定了,就是分组的方案数乘 ...
- css之relative
一.relative对absolute的限制作用 1.限制left/top/right/bottom定位.absolute默认是在也没的左上角,当父类设定为relative,absolute就被限制在 ...
- Struts2中类数据封装的方式
第一种方式:属性驱动提供对应属性的set方法进行数据的封装.表单的哪些属性需要封装数据,那么在对应的Action类中提供该属性的set方法即可.表单中的数据提交,最终找到Action类中的setXxx ...
- easyui生成合并行,合计计算价格
easyui生成合并行,合计计算价格 注:本文来源: 原创 一:图样你效果图 二:代码实现 1:datagrid 列展示: window.dataGrid = $("#dataGrid&qu ...
- js小方法积累,将一个数组按照n个一份,分成若干数组
// 把一个数组按照一定长度分割成若干数组 function group(array, subGroupLength) { let index = 0; let newArray = []; whil ...
- laravel 配置设置
public function updateRegisterSetting(Request $request, Configuration $config) { $conf = $request-&g ...
- laravel 分类的列表查询
public function index(Request $request, ResponseFactoryContract $response, QuestionModel $questionMo ...