SGD训练时收敛速度的变化研究。
一个典型的SGD过程中,一个epoch内的一批样本的平均梯度与梯度方差,在下图中得到了展示。
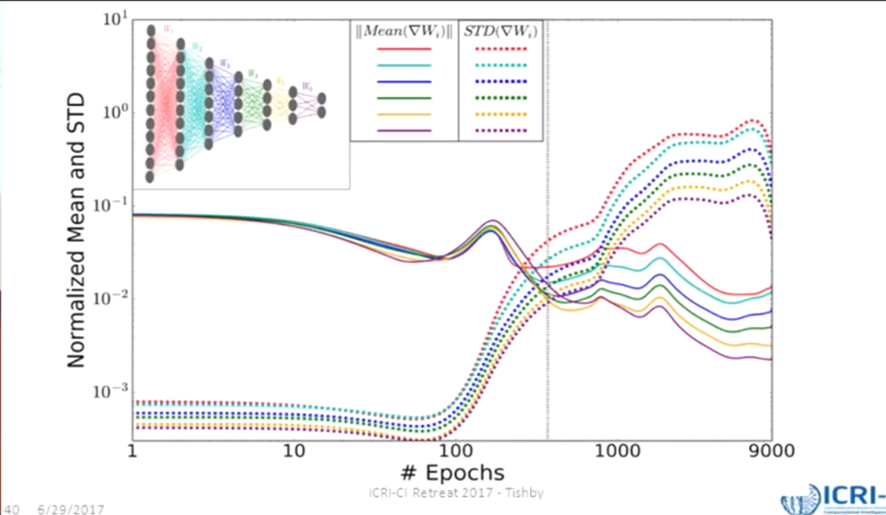
无论什么样的网络结构,无论是哪一层网络的梯度,大体上都遵循下面这样的规律:
高信号/噪音比一段时间之后,信号/噪音比逐渐降低,收敛速度减缓,梯度的方差增大,梯度均值减小。
噪音增加的作用及其必要性会在另一篇文章中阐述,这里仅讨论噪音的产生对于模型收敛速度能够产生怎样的影响。
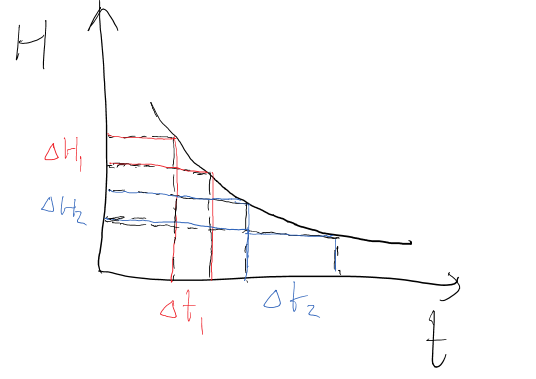
首先定义模型收敛速度:训练后期,噪音梯度导致权重更新时,导致系统新增的熵 H(混乱度)对于SGD迭代次数 t 的导数。
对于第k层的权重的梯度,每一轮(时间t)更新:
\[\frac{\partial {{\mathbf{W}}^{\left( k \right)}}}{\partial t}=-\nabla \operatorname{E}({{\mathbf{W}}^{\left( k \right)}})+\beta _{\left( k \right)}^{-1}\xi \left( t \right)\]
其中E是全局损失函数, $\beta $是信号/噪音比,$\xi $是高斯白噪音, $P\left( \xi \left( t \right) \right)=Norm\left( 0,\sigma \left( t \right) \right)$ ,方差$\sigma \left( t \right)$随着时间增加而变大。
因为使用高噪音进行梯度下降更新权重W时引进了额外的熵,考虑熵的变化$\Delta H({{\mathbf{W}}^{(k)}})$
假设将损失函数E分割成非常多个小区间,问题转化为:$\Delta H({{\mathbf{W}}^{(k)}})\text{=}\Delta H({{\text{E}}_{1}}({{\mathbf{W}}^{(k)}}),{{\text{E}}_{2}}({{\mathbf{W}}^{(k)}})......{{\text{E}}_{N}}({{\mathbf{W}}^{(k)}}))$
已知$\operatorname{H}\left( E \right)=-\underset{\text{i}}{\mathop{\sum }}\,p\left( {{\text{E}}_{\text{i}}} \right)\log p\left( {{\text{E}}_{\text{i}}} \right)$
\[\frac{\partial \operatorname{H}}{\partial p}=-\left( \sum\limits_{\text{i}}{\log \left( p\left( {{E}_{i}} \right) \right)+1} \right)\]
又已知系统达到热平衡后,使熵最大的p(W)分布是玻尔兹曼分布(参见Boltzmann与最大熵的关联文章)
${{p}_{E={{E}_{i}}}}\left( \mathbf{W} \right)=\frac{1}{\text{Z}}{{\text{e}}^{-\beta {{E}_{i}}\left( \mathbf{W} \right)}}$ ,Z是配分函数partition function $Z=\sum\limits_{E'}{{{e}^{-\beta E'(\mathbf{W})}}}$
考虑热平衡附近时,p怎样随着E改变:
\[\frac{\partial p}{\partial E}=\frac{\partial }{\partial {{E}_{\text{i}}}}\left( {{{e}^{-\beta {{E}_{i}}}}}/{\left( {{e}^{-\beta {{E}_{i}}}}+\sum\nolimits_{k\ne i}{{{e}^{-\beta {{E}_{k}}}}} \right)}\; \right)=-\beta p(1-p)\]
使用链式法则得到:
$\frac{\partial \text{H}}{\partial t}=\sum\limits_{i}{\frac{\partial \text{H}}{\partial {{p}_{i}}}\frac{\partial {{p}_{i}}}{\partial {{\text{E}}_{i}}}\frac{\partial {{\text{E}}_{i}}}{\partial \mathbf{W}}\frac{\partial \mathbf{W}}{\partial t}}$
训练到接近收敛时,尽管每次更新权重时计算的loss的白噪音会越来越大,但全局loss E会稳定得多,并且逐渐下降到一个比较小的区间内,所以只考虑该区间内对应的$\Delta \text{H}$以及$\Delta \text{t}$,带入前面求出的偏导得到:
\[\frac{\partial H}{\partial t}=\sum\limits_{\text{i}}{\left( \log \left( {{p}_{\text{i}}} \right)+1 \right)\beta {{p}_{i}}(1-{{p}_{i}})\nabla {{E}_{i}}(\mathbf{W})(-\nabla {{E}_{i}}(\mathbf{W})+\beta _{(k)}^{-1}\xi (t))}\]
噪音项在求期望时被平均成0,同时使用泰勒级数在p=1附近展开ln(p) :$\ln (p)=(p-1)-\frac{1}{2}{{(p-1)}^{2}}+\frac{1}{3}{{(p-1)}^{3}}-......$
可推出
$(\log (p)+1)(1-p)=-p\log p+1-p+\log p\approx -p\log p+1-p+(p-1)-\frac{1}{2}{{(p-1)}^{2}}=-p\log p-\frac{1}{2}{{(p-1)}^{2}}$
当p_i接近1时,忽略二次项,得到熵H,既 -plogp
继续带入可得(注意beta后面是预期值符号,不是损失函数E)
\[\frac{\partial H}{\partial t}\approx \beta \sum\limits_{\text{i}}{-{{p}_{i}}{{\left( \nabla {{E}_{i}}(\mathbf{W}) \right)}^{2}}}H=-\beta \operatorname{E}\left[ {{\left( \nabla E(\mathbf{W}) \right)}^{2}} \right]H\]
这里看出当训练时在全局loss逐渐收敛到一个小区间E_i内,p_i趋近于1,这时候熵的该变量与训练迭代次数满足上述微分方程。
解微分方程得到:
$H=H_{0}\exp\left(-\beta\mathbb{E}\left[(\nabla E(W))^{2}\right])t\right)$
该方程只在全局loss相对稳定之后成立,此时SGD噪音带来的熵随训练时间的增加而指数减少。
半衰期之前一直被当做常量来看待,但其实半衰期随着全局梯度平方的预期值的减小,会逐渐增大。
也就是说要从噪音里引入固定量的熵,所消耗的时间(迭代轮数)会越来越多,甚至比普通的指数衰减花费更多的时间。
第k层权重更新噪音引入的熵 会以 给定下一层特征层时输入数据X的熵 的形式展现。
\[\Delta H(\delta {{\mathbf{W}}^{(k)}})=\Delta H(X|{{T}^{(k+1)}})\]
噪音引入的熵的作用,会在下面几篇介绍信息瓶颈理论的文章里详细阐述。
SGD训练时收敛速度的变化研究。的更多相关文章
- 将caffe训练时loss的变化曲线用matlab绘制出来
1. 首先是提取 训练日志文件; 2. 然后是matlab代码: clear all; close all; clc; log_file = '/home/wangxiao/Downloads/43_ ...
- DenseNet算法详解——思路就是highway,DneseNet在训练时十分消耗内存
论文笔记:Densely Connected Convolutional Networks(DenseNet模型详解) 2017年09月28日 11:58:49 阅读数:1814 [ 转载自http: ...
- caffe︱深度学习参数调优杂记+caffe训练时的问题+dropout/batch Normalization
一.深度学习中常用的调节参数 本节为笔者上课笔记(CDA深度学习实战课程第一期) 1.学习率 步长的选择:你走的距离长短,越短当然不会错过,但是耗时间.步长的选择比较麻烦.步长越小,越容易得到局部最优 ...
- 理解dropout——本质是通过阻止特征检测器的共同作用来防止过拟合 Dropout是指在模型训练时随机让网络某些隐含层节点的权重不工作,不工作的那些节点可以暂时认为不是网络结构的一部分,但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了
理解dropout from:http://blog.csdn.net/stdcoutzyx/article/details/49022443 http://www.cnblogs.com/torna ...
- caffe下训练时遇到的一些问题汇总
1.报错:“db_lmdb.hpp:14] Check failed:mdb_status ==0(112 vs.0)磁盘空间不足.” 这问题是由于lmdb在windows下无法使用lmdb的库,所以 ...
- 基于google earth engine 云计算平台的全国水体变化研究
第一个博客密码忘记了,今天才来开通第二个博客,时间已经过去两年了,三年的硕士生涯,真的是感慨良多,最有收获的一段时光,莫过于在实验室一个人敲着代码了,研三来得到中科院深圳先进院,在这里开始了新的研究生 ...
- A TensorBoard plugin for visualizing arbitrary tensors in a video as your network trains.Beholder是一个TensorBoard插件,用于在模型训练时查看视频帧。
Beholder is a TensorBoard plugin for viewing frames of a video while your model trains. It comes wit ...
- 使用Deeplearning4j进行GPU训练时,出错的解决方法
一.问题 使用deeplearning4j进行GPU训练时,可能会出现java.lang.UnsatisfiedLinkError: no jnicudnn in java.library.path错 ...
- Android8.0运行时权限策略变化和适配方案
版权声明:转载必须注明本文转自严振杰的博客:http://blog.yanzhenjie.comAndroid8.0也就是Android O即将要发布了,有很多新特性,目前我们可以通过AndroidS ...
随机推荐
- bochs的bochsrc说明
########################################## Configuration file for bochs ################### ...
- leetcode978
class Solution(object): def maxTurbulenceSize(self, A: 'List[int]') -> int: n = len(A) if n == 1: ...
- [CSS3]环形进度条
来源:https://codepen.io/eZ0/pen/eZXNzd 点击上面链接有源码有示例. .ko-progress-circle { width: 120px; height: 120px ...
- redis锁机制介绍与实例
转自:https://m.jb51.net/article/154421.htm 今天小编就为大家分享一篇关于redis锁机制介绍与实例,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要 ...
- [FE] 有效开展一个前端项目2 (vuejs-templates/webpack)
1.安装 nodejs.npm $ curl -sL https://deb.nodesource.com/setup_10.x | sudo -E bash - $ sudo apt-get i ...
- open()函数 linux中open函数使用
来源:http://www.cnblogs.com/songfeixiang/p/3733855.html linux中open函数使用 open函数用来打开一个设备,他返回的是一个整型变量,如果 ...
- Scratch 数字游戏
本想用Scratch给女儿做一个类似舒尔特方格的程序来认识数字和提升专注,想想这对刚刚3岁的孩子来说还是比较困难的,于是只做了3*3的方格,来认识数字1-9. 游戏地址:Random 9 v0.21 ...
- 关于导入zepto出错的问题
一.前言 webpack在配置多页面开发的时候 ,发现用 import 导入 Zepto 时,会报 Uncaught TypeError: Cannot read property 'createEl ...
- 3/1 AT指令集
一.背景 由于机器与传输时的信号类型不通,机器处理的是数字信号,而传输时是模拟信号,故,要实现这两者间的交互,就需要一个介质,之前是靠硬件,靠人工,硬件使用modem(猫): 现在通过一种命令来实现自 ...
- 使用autohotkey修改方向键、回车和启动程序
具体步骤 下载并安装autohotkey. 在你觉得合适的地方鼠标右键-新建-autohotkey script(脚本):或者创建一个别的文件,再把后缀改成ahk也可以 一个新建的ahk文档里面会有这 ...