python网络爬虫入门(一)
爬虫系列的第一篇文章,本篇帮助不大(只能教你利用requests库获取HTML),后续篇(二)会有案例讲解。
python版本:python 3.7.0b1
IDE:PyCharm 2016.3.2
涉及模块:requests & builtwith & whois
模块安装方法:Win+R 进入cmd, 进入文件夹Scripts
命令:pip install requests / pip install requests / pip install whois(如不能正确安装,请留言或自行百度解决)
如要在PyCharm中使用库,先添加一下(添加方法)。
话不多说,先上代码:
#coding : utf-8
import requests
import builtwith #引入所需python库
print("开始爬取")
url = "https://www.wenjiwu.com/doc/uqzlni.html" #爬取对象网址
r = requests.get(url) #requests模块get方法
print (r.status_code) #xxx.status_code方法,返回值若为200,则爬取成功
print (r.text) #xxx.text方法,得到URL对应HTML源码
print (builtwith.parse(url)) #builtwith模块将URL作为参数,返回该网站使用的技术
(url网址随意,baidu, imooc...都可以)
脚本运行结果:
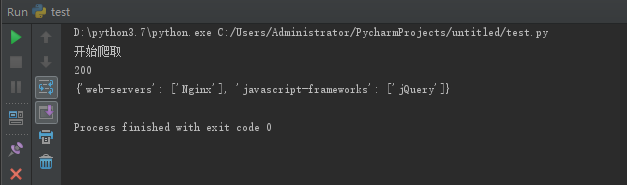
可以看到,程序正常运行,返回值200,爬取成功,builtwith模块得到了示例网站 web-servers: Nginx(服务器类型,详细了解),
使用了jQuery的javascript框架。但是碍于篇幅,其中HTML源码内容运行时注释掉了,不要惊讶!!!
r.text 结果(部分):

(内容无意中伤 Single Dog, Me too #_# )
补充:写成函数形式
#coding : utf-8
import requests
import whois
import builtwith def download(url, x):
print ("downloading...")
ans = requests.get(url)
islink = ans.status_code # '''通行码'''
user = whois.whois(url) #'''网站所有者'''
pattern = builtwith.parse(url) #'''网站类型'''
result = ans.text #'''网站内容HTML'''
if islink == 200:
print ("successfully link!")
else:
print ("Sorry, it is no found!")
if x == 'y':
print ('owner: ', user)
print ('pattern: ', pattern)
print ('text: ', result)
return result
else:
return 000
url = "https://www.baidu.com"
download(url, 'y')
补充:把爬取的内容写入txt文件
# 写入*.txt文件
f = open("D:\python3.7\\testf.txt", mode='a', errors='ignore')
for x in ans.text:
f.write(x)
f.close()
文件地址随意,errors=‘ignore’是为了防止诸如 ...'\xe7'..., illegal multibyte sequence转码问题的出现。
转载请注明出处,欢迎留言讨论。
python网络爬虫入门(一)的更多相关文章
- python网络爬虫入门范例
python网络爬虫入门范例 Windows用户建议安装anaconda,因为有些套件难以安装. 安装使用pip install * 找出所有含有特定标签的HTML元素 找出含有特定CSS属性的元素 ...
- Python网络爬虫入门篇
1. 预备知识 学习者需要预先掌握Python的数字类型.字符串类型.分支.循环.函数.列表类型.字典类型.文件和第三方库使用等概念和编程方法. 2. Python爬虫基本流程 a. 发送请求 使用 ...
- Python网络爬虫入门实战(爬取最近7天的天气以及最高/最低气温)
_ 前言 本文文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Bo_wen 最近两天学习了一下python,并自己写了一个 ...
- python网络爬虫入门(二)
刚去看了一下,18年2月份写了第一篇关于爬虫的文章(仅仅介绍了使用requests库去获取HTML代码),一年多之后看来很稚嫩也没有多少参考的意义,但没想着要去修改它,留着也是一个回忆吧.至少证明着我 ...
- python网络爬虫-入门(二)
为什么要学网络爬虫 可以替代人工从网页中找到数据并复制粘贴到excel中,这种重复性的工作不仅浪费时间还一不留神还会出错----解决无法自动化和无法实时获取数据 对于这些公开数据的应用价值,我 ...
- python网络爬虫-入门(一)
前言 1.爬虫程序是Dt(Data Technology,数据技术)收集信息的基础,爬取到目标网站的资料后,就可以分析和建立应用了. 2.python是一个简单.有效的语言,爬虫所需要的获取.存储.整 ...
- Python网络爬虫实战(一)快速入门
本系列从零开始阐述如何编写Python网络爬虫,以及网络爬虫中容易遇到的问题,比如具有反爬,加密的网站,还有爬虫拿不到数据,以及登录验证等问题,会伴随大量网站的爬虫实战来进行. 我们编写网络爬虫最主要 ...
- python网络爬虫之入门[一]
目录 前言 一.探讨什么是python网络爬虫? 二.一个针对于网络传输的抓包工具fiddler 三.学习request模块来爬取第一个网页 * 扩展内容(爬取top250的网页) 后记 @(目录) ...
- python网络爬虫实战之快速入门
本系列从零开始阐述如何编写Python网络爬虫,以及网络爬虫中容易遇到的问题,比如具有反爬,加密的网站,还有爬虫拿不到数据,以及登录验证等问题,会伴随大量网站的爬虫实战来进行. 我们编写网络爬虫最主要 ...
随机推荐
- 使用 Kubeadm 升级 Kubernetes 版本
升级最新版 kubelet kubeadm kubectl (阿里云镜像) cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kuberne ...
- Android--Activity中使用Intent传值
Intent,又称为意图,是一种运行时绑定机制,它能在程序运行的过程中链接两个不同的组件(Activity.Service.BroadcastReceiver).通过Intent,程序可以向Andro ...
- Day2----Python学习之路笔记(2)
学习路线: Day1 Day2 Day3 Day4 Day5 ...待续 一.简单回顾一下昨天的内容 1. 昨天了解到了一些编码的知识 1.1. 我们写好的.py文件头没有加# -*- coding: ...
- salesforce零基础学习(九十二)使用Ant Migration Tool 实现Metadata迁移
我们在做项目时经常会使用changeset作为部署工具,但是某些场景使用changeset会比较难操作,比如当我们在sandbox将apex class更改名字想要部署到生产的org或者其他环境的or ...
- C#.Net Core 操作Docker中的redis数据库
做软件开发的人,会在本机安装很多开发时要用到的软件,比如数据库,有MS SQL Server,MySQL,等,如果每种数据库都按照在本机确实有点乱,这个时候我们就想用虚拟机来隔离,这样就不会扰乱本机一 ...
- 1.let命令总结
1.let用法类似于var,但是let只在所在代码块有效 { let a = 10; var b = 1; } a // ReferenceError: a is not defined. b // ...
- Bootstrap-3-Typeahead
是Bootstrap-3-Typeahead,不是Twitter open source的typeahead,两者用法有差异.外加如果配合原生的Bootstrap3 的话推荐还是用这个.(当然Twit ...
- man sm-notify(sm-notify命令中文手册)
本人译作集合:http://www.cnblogs.com/f-ck-need-u/p/7048359.html sm-notify命令是用来发送重启通知信息给NFS对端的,在锁状态恢复过程中起着至关 ...
- python理解描述符(descriptor)
Descriptor基础 python中的描述符可以用来定义触发自动执行的代码,它像是一个对象属性操作(访问.赋值.删除)的代理类一样.前面介绍过的property是描述符的一种. 大致流程是这样的: ...
- vs 中引用自己创建程序集出现小叹号
出现的问题: 原因是.net frame work版本不一致 解决方法: 项目单击右键-->属性: 改为与你要引用的项目的程序集的版本一致即可