python基础 ---time,datetime,collections)--时间模块&collections 模块
python中的time和datetime模块是时间方面的模块 time模块中时间表现的格式主要有三种:
1、timestamp:时间戳,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量
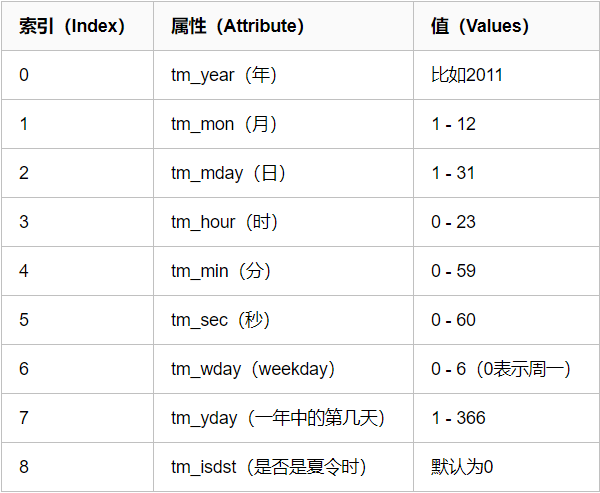
2、struct_time:时间元组,共有九个元素组。
3、format time :格式化时间,已格式化的结构使时间更具可读性。包括自定义格式和固定格式。
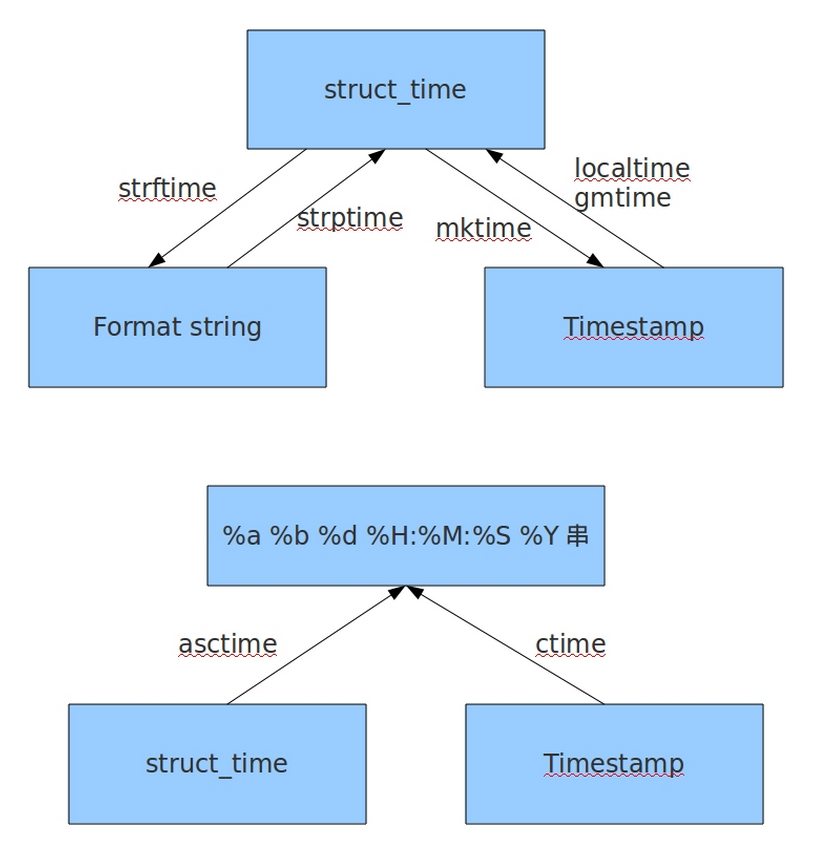
2.格式化字符串时间: 格式化的时间字符串(Format String): ‘1999-12-06’
python中时间日期格式化符号:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
3.结构化时间:元组(struct_time) struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
#导入时间模块
>>>import time #时间戳
>>>time.time()
1500875844.800804 #时间字符串
>>>time.strftime("%Y-%m-%d %X")
'2017-07-24 13:54:37'
>>>time.strftime("%Y-%m-%d %H-%M-%S")
'2017-07-24 13-55-04' #时间元组:localtime将一个时间戳转换为当前时区的struct_time
time.localtime()
time.struct_time(tm_year=, tm_mon=, tm_mday=,
tm_hour=, tm_min=, tm_sec=,
tm_wday=, tm_yday=, tm_isdst=)
time的生成方法和time格式的转换
生成时间
import time
生成时间戳格式的时间:
print(time.time()) #是机器看的时间,拿到的是float类型的
time = 1553066161.9998 生成结构化格式的时间:
print(time.localtime()) #用在修改时间是使用的,得到一个命名元祖time.struct_time
time = time.struct_time(tm_year=2019, tm_mon=3, tm_mday=20, tm_hour=15, tm_min=16, tm_sec=1, tm_wday=2, tm_yday=79, tm_isdst=0) 生成字符串格式的时间:
print(time.strftime('%Y-%m-%d %H;%M:%S')) #或者'%Y-%m-%d %X/x
time = 2019-03-20 15:17:04 时间格式转换
注意:字符串格式的时间不能与时间戳格式的时间相互转换 转换顺序:字符串时间 <----->结构化时间<---->时间戳
字符串时间---->结构化时间
t = '2018-11-30 12:30:00'
f = time.strptime(t,'%Y-%m-%d %H:%M':%S) 结构化时间---->字符串时间
t = time.localtime()
f = time.strftime('%Y-%m-%d %H:%M:%S',t) 结构化时间---->时间戳时间
t = time.localtime()
f = (time.mktime(t)) 时间戳时间---->格式化时间
t = time.time()
f = time.localtime(t) 注意:
time.strftime() #获取当前字符串时间
timt.time()=1553052418.0508 #获取当时间时间戳
时间戳--结构化 time.localtime(time.time())
结构化--时间戳 time.mktime(f) #f =time.struct_time(tm_year=2019, tm_mon=3, tm_mday=20, tm_hour=11, tm_min=25, tm_sec=56, tm_wday=2, tm_yday=79, tm_isdst=0)
结构化--字符串 time.strftime('%Y-%m-%d %H:%M:%S',f) f=结构化时间 格式可以少写
字符串--结构化 f =time.strptime('2019-03-20 10:40:00','%Y-%m-%d %H:%M:%S') 格式可以少写
time 练习
t = time.time() #获取当前时间戳
t1 = t - 30*86400 #按照30天算,求出30天之前的时间戳
old_time = time.localtime(t1) #将时间戳时间转换成字符串时间
print(time.strftime('%Y-%m-%d %X',old_time))
t = '2018-11-30 12:30:00'
t1 = time.strptime(t,'%Y-%m-%d %H:%M:%S') #将字符串时间转成格式化时间
t2 =time.mktime(t1 ) + 60*60*2 #将格式化时间转成时间戳+7200秒
t3 = time.localtime(t2)
print(time.strftime('%Y-%m-%d %H:%M:%S',t3))
2.datetime模块
from datetime import datetime ,timedelta
f =datetime.now() #精确到毫秒 datetime.now()拿到的是时间对象
f1=datetime.timestamp(f) #将时间对象转成时间戳
f2=datetime.fromtimestamp(f1) #将时间戳转换成时间对象
f3= datetime.strptime('1984-1-29','%Y-%m-%d') #将字符串转成时间戳
f5 = datetime.strftime(f,'%Y-%m-%d') #将时间对象转成字符串 当前时间减去2个小时
print(datetime.now() - timedelta(hours=2)) #这个是datetime的精华 注意;datetime没有结构化时间
注意:将a格式的转化为b格式的时间,就应该用b将a包起来,比如将结构化的时间转成字符串时间print(time.strftime('%Y-%m-%d %X',time.localtime()))
3.数据结构的补充(官方文档)
Counter:计数器
引入模块:from collections import Counter
Counter 集成于 dict 类,因此也可以使用字典的方法,此类返回一个以元素为 key 、元素个数为 value 的 Counter 对象集合 #读取history中执行过最多的十条命令
import os
from collections import Counter
c = Counter()
with open(os.path.expanduser('~/.bash_history')) as cmd_info:
for line in cmd_info:
cmd = line.strip().split()
if cmd:
c[cmd[0]]+=1
print(c.most_common(10)) 常用操作:
sum(c.values()) # 所有计数的总数
c.clear() # 重置Counter对象,注意不是删除
list(c) # 将c中的键转为列表
set(c) # 将c中的键转为set
dict(c) # 将c中的键值对转为字典
c.items() # 转为(elem, cnt)格式的列表
Counter(dict(list_of_pairs)) # 从(elem, cnt)格式的列表转换为Counter类对象
c.most_common()[:-n:-1] # 取出计数最少的n-1个元素
c += Counter() # 移除0和负值
文章
nametuple:命名函数
引入模块:from collections import namedtuple
namedtuple是一个函数,它用来创建一个自定义的tuple对象,并且规定了tuple元素的个数,并可以用属性而不是索引来引用tuple的某个元素。
这样一来,我们用namedtuple可以很方便地定义一种数据类型,它具备tuple的不变性,又可以根据属性来引用,使用十分方便 #当元组的元素较多时们就可以使用命名元组来明确标明每个元素是什么意思
tu = namedtuple('people',['name','age','sex','hobby']) #是一个类
print(tu('kobe','','man','抽烟,喝酒烫头'))
ll =tu('kobe','','man','抽烟,喝酒烫头') #实例化一个类。对象
print(ll.name) #调用名字之后返回值
nametuple:命名函数
引入模块:from collections import namedtuple
namedtuple是一个函数,它用来创建一个自定义的tuple对象,并且规定了tuple元素的个数,并可以用属性而不是索引来引用tuple的某个元素。
这样一来,我们用namedtuple可以很方便地定义一种数据类型,它具备tuple的不变性,又可以根据属性来引用,使用十分方便 #当元组的元素较多时们就可以使用命名元组来明确标明每个元素是什么意思
tu = namedtuple('people',['name','age','sex','hobby']) #是一个类
print(tu('kobe','','man','抽烟,喝酒烫头'))
ll =tu('kobe','','man','抽烟,喝酒烫头') #实例化一个类。对象
print(ll.name) #调用名字之后返回值
deque:双端队列
导入模块
from collections import deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。deque是为了高效实现插入和删除操作的双向列表。
适合用于队列和栈: #增
d = deque([1,2,3,4,5])
d.append(10)
print(d)
d.appendleft(-10)
print(d)
d.insert(2,9999) #在索引为2的地方添加999
print(d)
#删
print(d.pop())
print(d.popleft()) deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
defaultdict:默认字典
导入模块:from collections import defaultdict
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict: from collections import defaultdict
dd = defaultdict(lambda: 'N/A')
dd['key1'] = 'abc'
dd['key1'] # key1存在
'abc'
dd['key2'] # key2不存在,返回默认值
'N/A' 注意:默认值是调用函数返回的,而函数在创建defaultdict对象时传入。除了在Key不存在时返回默认值,defaultdict的其他行为跟dict是完全一样的。
ordereddict
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
from collections import OrderedDict
d = dict([('a', 1), ('b', 2), ('c', 3)])
print(d)
{'a': 1, 'c': 3, 'b': 2} #dict的key是无序的 od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
OrderedDict([('a', 1), ('b', 2), ('c', 3)]) #OrderedDict的key是有序的
注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序: >>> od = OrderedDict()
>>> od['z'] = 1
>>> od['y'] = 2
>>> od['x'] = 3
>>> od.keys() # 按照插入的Key的顺序返回
['z', 'y', 'x']
OrderedDict可以实现一个FIFO(先进先出)的dict,当容量超出限制时,先删除最早添加的Key:
python基础 ---time,datetime,collections)--时间模块&collections 模块的更多相关文章
- python基础语法12 内置模块 json,pickle,collections,openpyxl模块
json模块 json模块: 是一个序列化模块. json: 是一个 “第三方” 的特殊数据格式. 可以将python数据类型 ----> json数据格式 ----> 字符串 ----& ...
- python基础(6)---set、collections介绍
1.set(集合) set和dict类似,也是一组key的集合,但不存储value.由于key不能重复,所以,在set中,没有重复的key. 集合和我们数学中集合的概念是一样的,也有交集.并集.差集. ...
- python基础编程:生成器、迭代器、time模块、序列化模块、反序列化模块、日志模块
目录: 生成器 迭代器 模块 time 序列化 反序列化 日志 一.生成器 列表生成式: a = [1,2,3,3,4,5,6,7,8,9,10] a = [i+1 for i in a ] prin ...
- python基础——14(shelve/shutil/random/logging模块/标准流)
一.标准流 1.1.标准输入流 res = sys.stdin.read(3) 可以设置读取的字节数 print(res) res = sys.stdin.readline() print(res) ...
- python 使用time / datetime进行时间、时间戳、日期转换
python 使用time 进行时间.时间戳.日期格式转换 #!/usr/bin/python3 # -*- coding: utf-8 -*- # @Time : 2017/11/7 15:53 # ...
- 第六篇:python基础_6 内置函数与常用模块(一)
本篇内容 内置函数 匿名函数 re模块 time模块 random模块 os模块 sys模块 json与pickle模块 shelve模块 一. 内置函数 1.定义 内置函数又被称为工厂函数. 2.常 ...
- python基础之正则表达式爬虫应用,configparser模块和subprocess模块
正则表达式爬虫应用(校花网) 1 import requests 2 import re 3 import json 4 #定义函数返回网页的字符串信息 5 def getPage_str(url): ...
- Python基础之datetime、sys模块
1.datetime模块 1)datetime.datetime.now(),返回各当前时间.日期类型. datetime.datetime.now(),返回当前日期. import datetime ...
- Py修行路 python基础 (二十一)logging日志模块 json序列化 正则表达式(re)
一.日志模块 两种配置方式:1.config函数 2.logger #1.config函数 不能输出到屏幕 #2.logger对象 (获取别人的信息,需要两个数据流:文件流和屏幕流需要将数据从两个数据 ...
随机推荐
- LeetCode 106. Construct Binary Tree from Inorder and Postorder Traversal 由中序和后序遍历建立二叉树 C++
Given inorder and postorder traversal of a tree, construct the binary tree. Note:You may assume that ...
- IVIEW TREE问题总结
1. API得到的tree数组数据,在前端构造成iview tree格式,无法编辑或者无法再次选中的问题: 由于VUE不能检测到数据或对象的变动,官网文档有解释 由于 JavaScript 的限制,V ...
- ENVI_REGISTER_DOIT( )函数
Envi_Register_Doit()函数利用控制点为裸数据定义投影坐标. 当将裸数据转为等经纬度投影时(Geographic),控制点pts中的经度值没有负值,0E~180E~360E,西经不 ...
- Mac安装Python3后,如何将默认执行的Python2改为Pyhton3
Mac 笔记本电脑系统自带的Python版本一般是Python 2.7,如果安装了Python 3.x,在终端中输入python命令后,输出的信息还是Python 2.7,问题就是如何将Mac系统默认 ...
- sed的替换元字符的语法
\(和\)用于保存正则表达式的一部分,而\1和\2用于保存回调的部分. 例如: 将sample.txt,内容如下 1...........55...........1010..........1010 ...
- dojo里添加目录树
其实循环生成目录树这个方法不仅仅局限于在使用dojo的情况下,只要明白了其中的原理,在任何一种语言下都能动态循环生成. 1. 数据结构 在这里先说明一下数据结构,我这里循环生成目录树的数据结构是像这样 ...
- Mybatis级联:关联、集合和鉴别器的使用
Mybatis中级联有关联(association).集合(collection).鉴别器(discriminator)三种.其中,association对应一对一关系.collection对应一对多 ...
- Maven打包后的文件存在中文乱码
发现打包的js文件虽然是UTF-8格式的编码,但是有中文有乱码 可设置jvm的编码,两种方法: 在系统的环境变量中添加一个变量,名为: JAVA_TOOL_OPTIONS, 值为:-Dfile.enc ...
- c#实现文件写入数据表/以二进制流保存到数据库,并实现下载
上传: 1.上传文件先保存到服务器 File.SaveAs(path) 2.sql(文件和sql在一个服务器上)进行保存操作: insert into File(filename,filebody ...
- vs中添加库文件WinMM.Lib
C:\Program Files (x86)\Microsoft SDKs\Windows\v7.1A\Lib\WinMM.Lib;