[MCM] K-mean聚类与DBSCAN聚类 Python
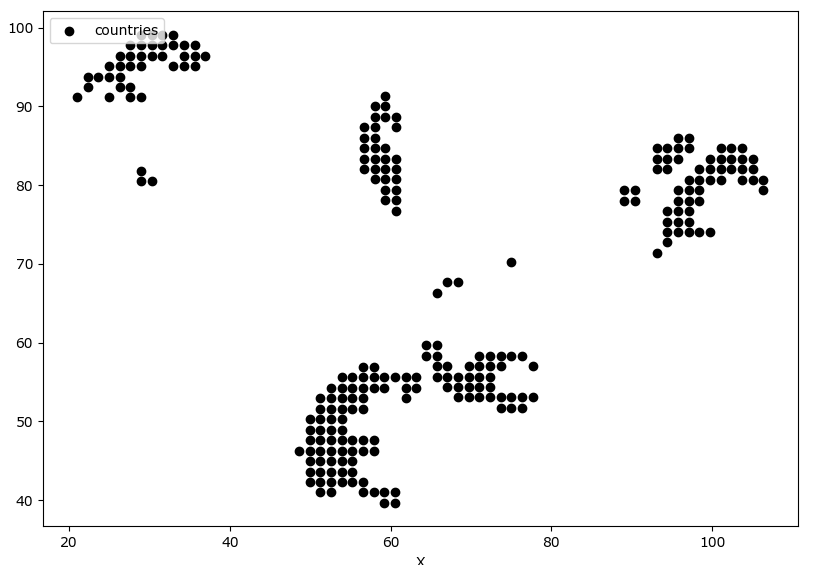
import matplotlib.pyplot as plt X=[56.70466067,56.70466067,56.70466067,56.70466067,56.70466067,58.03256629,58.03256629,58.03256629,58.03256629,58.03256629,58.03256629,58.03256629,58.03256629,59.3604719,59.3604719,59.3604719,59.3604719,59.3604719,59.3604719,59.3604719,59.3604719,59.3604719,60.68837752,60.68837752,60.68837752,60.68837752,60.68837752,60.68837752,60.68837752,60.68837752,21.00466067,22.33256629,22.33256629,23.6604719,24.98837752,24.98837752,24.98837752,26.31628314,26.31628314,26.31628314,26.31628314,27.64418876,27.64418876,27.64418876,27.64418876,27.64418876,28.97209438,28.97209438,28.97209438,28.97209438,28.97209438,28.97209438,28.97209438,30.3,30.3,30.3,30.3,31.62790562,31.62790562,31.62790562,32.95581124,32.95581124,32.95581124,34.28371686,34.28371686,34.28371686,35.61162248,35.61162248,35.61162248,36.9395281,89.10466067,89.10466067,90.43256629,90.43256629,93.08837752,93.08837752,93.08837752,93.08837752,94.41628314,94.41628314,94.41628314,94.41628314,94.41628314,94.41628314,94.41628314,95.74418876,95.74418876,95.74418876,95.74418876,95.74418876,95.74418876,95.74418876,95.74418876,97.07209438,97.07209438,97.07209438,97.07209438,97.07209438,97.07209438,97.07209438,97.07209438,98.4,98.4,98.4,98.4,98.4,99.72790562,99.72790562,99.72790562,99.72790562,101.0558112,101.0558112,101.0558112,101.0558112,102.3837169,102.3837169,102.3837169,103.7116225,103.7116225,103.7116225,103.7116225,105.0395281,105.0395281,105.0395281,106.3674337,106.3674337,64.40466067,64.40466067,65.73256629,65.73256629,65.73256629,65.73256629,65.73256629,67.0604719,67.0604719,67.0604719,67.0604719,68.38837752,68.38837752,68.38837752,68.38837752,69.71628314,69.71628314,69.71628314,69.71628314,71.04418876,71.04418876,71.04418876,71.04418876,71.04418876,72.37209438,72.37209438,72.37209438,72.37209438,72.37209438,73.7,73.7,73.7,73.7,75.02790562,75.02790562,75.02790562,75.02790562,76.35581124,76.35581124,76.35581124,77.68371686,77.68371686,48.60466067,49.93256629,49.93256629,49.93256629,49.93256629,49.93256629,49.93256629,49.93256629,51.2604719,51.2604719,51.2604719,51.2604719,51.2604719,51.2604719,51.2604719,51.2604719,51.2604719,51.2604719,52.58837752,52.58837752,52.58837752,52.58837752,52.58837752,52.58837752,52.58837752,52.58837752,52.58837752,52.58837752,52.58837752,53.91628314,53.91628314,53.91628314,53.91628314,53.91628314,53.91628314,53.91628314,53.91628314,53.91628314,53.91628314,53.91628314,55.24418876,55.24418876,55.24418876,55.24418876,55.24418876,55.24418876,55.24418876,55.24418876,55.24418876,56.57209438,56.57209438,56.57209438,56.57209438,56.57209438,56.57209438,56.57209438,56.57209438,56.57209438,57.9,57.9,57.9,57.9,57.9,57.9,59.22790562,59.22790562,59.22790562,59.22790562,60.55581124,60.55581124,60.55581124,61.88371686,61.88371686,61.88371686,63.21162248,63.21162248]
Y=[82.04418876,83.37209438,84.7,86.02790562,87.35581124,80.71628314,82.04418876,83.37209438,84.7,86.02790562,87.35581124,88.68371686,90.01162248,78.0604719,79.38837752,80.71628314,82.04418876,83.37209438,84.7,88.68371686,90.01162248,91.3395281,76.73256629,78.0604719,79.38837752,80.71628314,82.04418876,83.37209438,87.35581124,88.68371686,91.12790562,92.45581124,93.78371686,93.78371686,91.12790562,93.78371686,95.11162248,92.45581124,93.78371686,95.11162248,96.4395281,91.12790562,92.45581124,95.11162248,96.4395281,97.76743371,80.50466067,81.83256629,91.12790562,95.11162248,96.4395281,97.76743371,99.09533933,80.50466067,96.4395281,97.76743371,99.09533933,96.4395281,97.76743371,99.09533933,95.11162248,97.76743371,99.09533933,95.11162248,96.4395281,97.76743371,95.11162248,96.4395281,97.76743371,96.4395281,78.02790562,79.35581124,78.02790562,79.35581124,71.38837752,82.01162248,83.3395281,84.66743371,72.71628314,74.04418876,75.37209438,76.7,82.01162248,83.3395281,84.66743371,74.04418876,75.37209438,76.7,78.02790562,79.35581124,83.3395281,84.66743371,85.99533933,74.04418876,75.37209438,76.7,78.02790562,79.35581124,80.68371686,84.66743371,85.99533933,74.04418876,78.02790562,79.35581124,80.68371686,82.01162248,74.04418876,80.68371686,82.01162248,83.3395281,80.68371686,82.01162248,83.3395281,84.66743371,82.01162248,83.3395281,84.66743371,80.68371686,82.01162248,83.3395281,84.66743371,80.68371686,82.01162248,83.3395281,79.35581124,80.68371686,58.34418876,59.67209438,55.68837752,57.01628314,58.34418876,59.67209438,66.31162248,54.3604719,55.68837752,57.01628314,67.6395281,53.03256629,54.3604719,55.68837752,67.6395281,53.03256629,54.3604719,55.68837752,57.01628314,53.03256629,54.3604719,55.68837752,57.01628314,58.34418876,53.03256629,54.3604719,55.68837752,57.01628314,58.34418876,51.70466067,53.03256629,57.01628314,58.34418876,51.70466067,53.03256629,58.34418876,70.29533933,51.70466067,53.03256629,58.34418876,53.03256629,57.01628314,46.27209438,42.28837752,43.61628314,44.94418876,46.27209438,47.6,48.92790562,50.25581124,40.9604719,42.28837752,43.61628314,44.94418876,46.27209438,47.6,48.92790562,50.25581124,51.58371686,52.91162248,40.9604719,42.28837752,43.61628314,44.94418876,46.27209438,47.6,48.92790562,50.25581124,51.58371686,52.91162248,54.2395281,42.28837752,43.61628314,44.94418876,46.27209438,47.6,48.92790562,50.25581124,51.58371686,52.91162248,54.2395281,55.56743371,42.28837752,43.61628314,44.94418876,46.27209438,47.6,51.58371686,52.91162248,54.2395281,55.56743371,40.9604719,42.28837752,46.27209438,47.6,51.58371686,52.91162248,54.2395281,55.56743371,56.89533933,40.9604719,46.27209438,47.6,54.2395281,55.56743371,56.89533933,39.63256629,40.9604719,54.2395281,55.56743371,39.63256629,40.9604719,55.56743371,52.91162248,54.2395281,55.56743371,54.2395281,55.56743371] #绘制数据分布图
plt.scatter(X,Y, c = "k", marker='o', label='countries')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend(loc=2)
plt.show()
离散点绘图
DBSCAN
基本概念:
2. 边界点:在半径Eps内点的数量小于MinPts,但是落在核心点的邻域内
3. 噪音点:既不是核心点也不是边界点的点
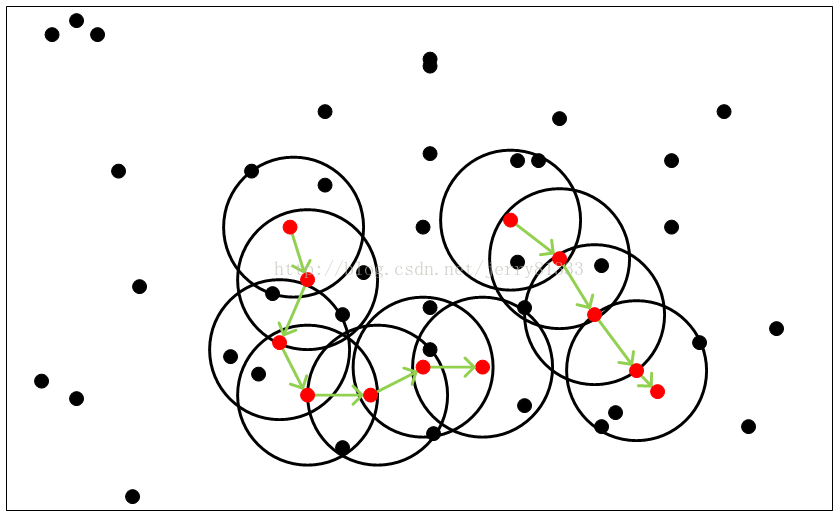
算法优点:
算法缺点:
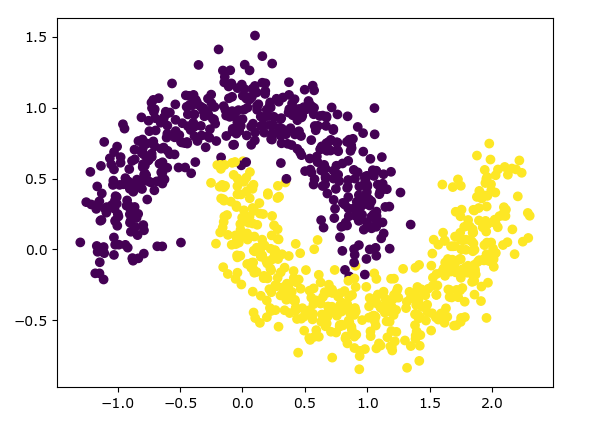
from sklearn.datasets.samples_generator import make_moons
import matplotlib.pyplot as plt
import time
from sklearn.cluster import KMeans
from sklearn.cluster import DBSCAN X, y_true = make_moons(n_samples=1000, noise=0.15) #y_true是提前做绘图分类标识 plt.scatter(X[:, 0], X[:, 1], c=y_true)
plt.show() # Kmeans
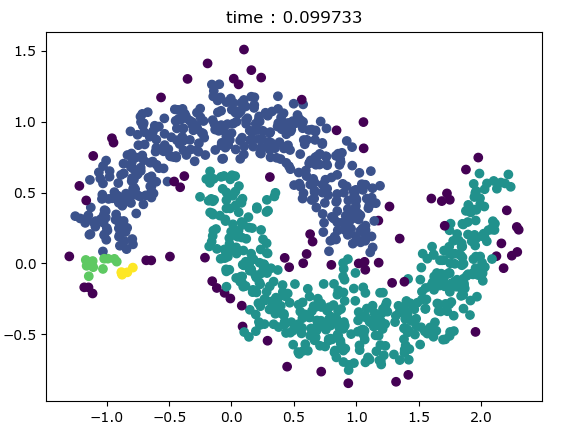
t0 = time.time()
kmeans = KMeans(init='k-means++', n_clusters=2, random_state=8).fit(X)
t = time.time() - t0
plt.scatter(X[:, 0], X[:, 1], c=kmeans.labels_)
plt.title('time : %f' % t)
plt.show() # DBSCAN
t0 = time.time()
dbscan = DBSCAN(eps=.1, min_samples=6).fit(X)
t = time.time() - t0
plt.scatter(X[:, 0], X[:, 1], c=dbscan.labels_)
plt.title('time : %f' % t)
plt.show()
代码
原数据绘图
K-mean聚类绘图

DBSCAN聚类
[MCM] K-mean聚类与DBSCAN聚类 Python的更多相关文章
- DBSCAN聚类︱scikit-learn中一种基于密度的聚类方式
一.DBSCAN聚类概述 基于密度的方法的特点是不依赖于距离,而是依赖于密度,从而克服基于距离的算法只能发现"球形"聚簇的缺点. DBSCAN的核心思想是从某个核心点出发,不断向密 ...
- (数据科学学习手札15)DBSCAN密度聚类法原理简介&Python与R的实现
DBSCAN算法是一种很典型的密度聚类法,它与K-means等只能对凸样本集进行聚类的算法不同,它也可以处理非凸集. 关于DBSCAN算法的原理,笔者觉得下面这篇写的甚是清楚练达,推荐大家阅读: ht ...
- 聚类算法:K均值、凝聚层次聚类和DBSCAN
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- 常见聚类算法——K均值、凝聚层次聚类和DBSCAN比较
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- K均值聚类和DBSCAN介绍
K均值(K-means)聚类 问题定义:给定数据$\vec{x}_1,\vec{x}_2,\cdots,\vec{x}_n$,将它们分到不同的$K$个簇(cluster)中.定义$\vec{c}=(c ...
- 基于密度聚类的DBSCAN和kmeans算法比较
根据各行业特性,人们提出了多种聚类算法,简单分为:基于层次.划分.密度.图论.网格和模型的几大类. 其中,基于密度的聚类算法以DBSCAN最具有代表性. 场景 一 假设有如下图的一组数据, 生成数据 ...
- 用scikit-learn学习DBSCAN聚类
在DBSCAN密度聚类算法中,我们对DBSCAN聚类算法的原理做了总结,本文就对如何用scikit-learn来学习DBSCAN聚类做一个总结,重点讲述参数的意义和需要调参的参数. 1. scikit ...
- 机器学习入门-DBSCAN聚类算法
DBSCAN 聚类算法又称为密度聚类,是一种不断发张下线而不断扩张的算法,主要的参数是半径r和k值 DBSCAN的几个概念: 核心对象:某个点的密度达到算法设定的阈值则其为核心点,核心点的意思就是一个 ...
- 简单易学的机器学习算法—基于密度的聚类算法DBSCAN
简单易学的机器学习算法-基于密度的聚类算法DBSCAN 一.基于密度的聚类算法的概述 我想了解下基于密度的聚类算法,熟悉下基于密度的聚类算法与基于距离的聚类算法,如K-Means算法之间的区别. ...
随机推荐
- java过滤器(过滤器排序)
java过滤器(过滤器排序) 定义过滤器顺序是很简单的:匹配请求的过滤器将按照它们出现在部署描述符或者编程式配置中的顺序添加到过滤器链中(记住,如果同时再部署描述符或者编程式配置中设置了一些过滤器,那 ...
- 3款网页jQuery抽奖实例演示
实例演示 实例演示 实例演示
- 04-HTML-图片标签
<html> <head> <title>图片标签学习</title> <meta charset="utf-8"/> ...
- 唯一索引的一种使用情景【有则U无则I】
这个知识点是最近一位面试老师问我的,当时对这种方法不了解,所以只能说那个中效率低的方法了,也就是先进性select判断,然后在执行更新或者插入操作,显然这种是很麻烦的,也自我反思一下,确实有很多的知识 ...
- Eclipse For JavaSE安装、配置、测试
Eclipse For JavaSE安装.配置.测试(win7_64bit) 目录 1.概述 2.本文用到的工具 3.安装与配置 4.JavaSE开发测试 5.ADT安装与Android开发测试 6. ...
- 轻松搭建Xposed Hook
0x2.导入xposed库文件XposedBridgeApi-XX.jar,将库文件放在app/lib目录下,自己创建一个lib目录,别放在libs目录下,否则会出错,然后导入库,修改 Scope 为 ...
- Vue之resource请求数据
导入resource文件 <script src="https://cdn.staticfile.org/vue-resource/1.5.1/vue-resource.min.js& ...
- Testlink1.9.17使用方法(第六章 测试计划制定)
第六章 测试计划制定 QQ交流群:585499566 在TestLink系统中,一个完整的测试计划包括:集成测试阶段.系统测试阶段. 一. 创建测试计划 1,点击主页上[测试计划管理] 2,在“测试计 ...
- Java:字节流和字符流(输入流和输出流)
本文内容: 什么是流 字节流 字符流 首发日期:2018-07-24 什么是流 流是个抽象的概念,是对输入输出设备的抽象,输入流可以看作一个输入通道,输出流可以看作一个输出通道. 输入流是相对程序而言 ...
- JS json字符串转对象、对象转字符串
JSON是javascript原生格式,在JavaScript中处理json数据不需要任何特殊的API或者工具包. JSON中,有两种结构:对象和数组. 在数据传输流中,json是以文本,即字符串的形 ...