机器学习算法总结(九)——降维(SVD, PCA)
降维是机器学习中很重要的一种思想。在机器学习中经常会碰到一些高维的数据集,而在高维数据情形下会出现数据样本稀疏,距离计算等困难,这类问题是所有机器学习方法共同面临的严重问题,称之为“ 维度灾难 ”。另外在高维特征中容易出现特征之间的线性相关,这也就意味着有的特征是冗余存在的。基于这些问题,降维思想就出现了。
降维方法有很多,而且分为线性降维和非线性降维,本篇文章主要讲解线性降维。
1、奇异值分解(SVD)
为什么先介绍SVD算法,因为在后面的PCA算法的实现用到了SVD算法。SVD算法不光可以用于降维算法中的特征分解,还可以用于推荐系统,以及自然语言处理等领域。是很多机器学习算法的基石。
在线性代数中我们学过矩阵(在这里的矩阵必须是$n × n$的方阵)的特征分解,矩阵A和特征值、特征向量之间的关系如下
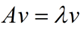
将A矩阵做特征分解,特征向量$Q$是一组正交向量,具体表达式如下

在这里因为$Q$中$n$个特征向量为标准正交基,满足$Q^T = Q^{-1}$,也就是说$Q$为酉矩阵。
矩阵的特征值分解的局限性比较大,要求矩阵A必须是方阵(即行和列必须相等的矩阵),那么对于一般的矩阵该如何做分解?
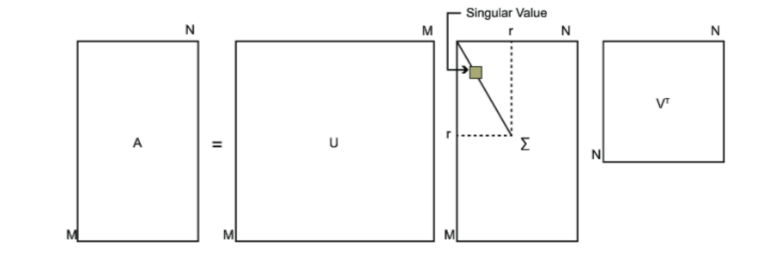
奇异值分解就可以处理这些一般性的矩阵,假设现在矩阵A是一个$m × n$的矩阵,我们可以将它的奇异值分解写成下面的形式
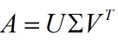
在这里$U$是$m × m$的矩阵,$\Sigma$是$m × n$的矩阵(除对角线上的值,其余的值全为0),$V$是$n × n$的矩阵。在这里矩阵$U$和$V$都是酉矩阵,也就是说满足$U^TU = I$,$V^TV = I$(其中$I$为单位矩阵)。对于SVD的定义如下图
矩阵$A^TA$是一个$n × n$的方阵,我们对该方阵做特征值分解,可以得到下面的表达式
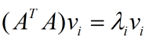
我们将这里得到的向量$v_i$称为右奇异向量。通过该值我们可以得到$u_i$(左奇异向量,方阵U中的向量)和$\sigma_i$(矩阵$\Sigma$中对角线上的值,也就是我们的奇异值)
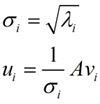
对于奇异值,它跟我们特征分解中的特征值相似,在奇异值矩阵$\Sigma$中也是按照从大到小排列的,而且奇异值减小的特别快。在很多情况下,前10%甚至前1%的奇异值的和就占总和的99%以上的比例。也就是说我们可以用最大的K个奇异值和对应的左右奇异向量来近似的描述矩阵,如下图所示
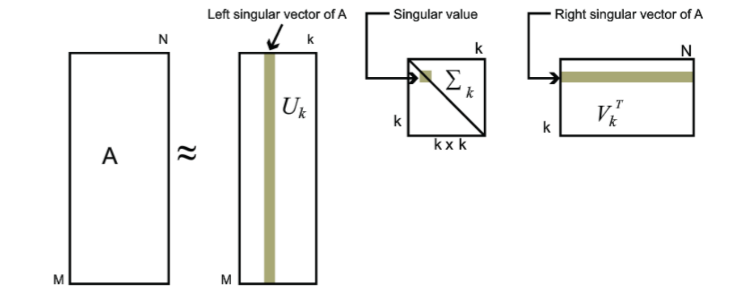
具体表达式如下
$A_{m × n} = U_{m × m} {\Sigma}_{m × n} V^T_{n × n} ≈ U_{m × k} {\Sigma}_{k × k} V^T_{k × n}$
在并行化计算下,奇异值分解是非常快的。但是奇异值分解出的矩阵解释性不强,有点黑盒子的感觉,不过还是在很多领域有着使用。
2、主成分分析(PCA)
PCA算法可以说是最常用的算法,在数据压缩,消除冗余等领域有着广泛的使用。
先来回顾下向量的內积,假设存在两条发自原点的有向线段A和B,如下图所示
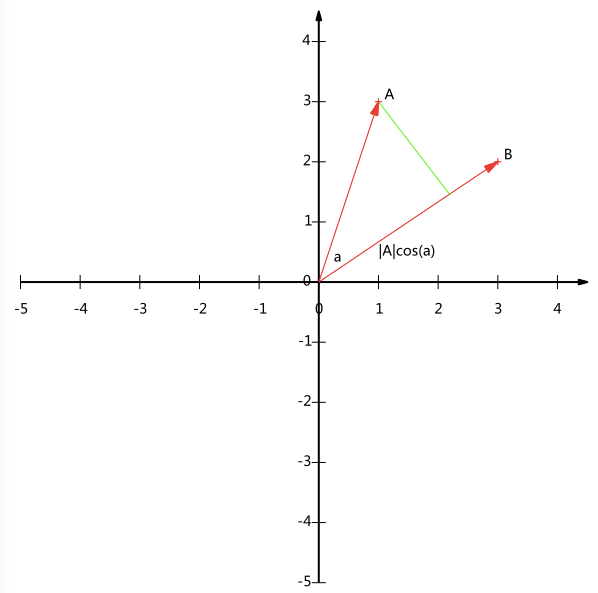
设$\alpha$是两个向量之间的夹角,则向量的內积可以表示为

此时假设向量B的模为1,则上面的式子可以表示为
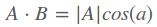
也就是说当向量B的模为1时,向量A与B的內积等于向量A在向量B上的投影的矢量长度(提醒:这个特性结合后面的基)
确定一个向量不能只是单单的靠该直线的本身,也和该直线所在的坐标系有关,对于二维空间内向量$(x,y)$事实上可以表示为

在这里(1, 0)和(0, 1)叫做二维空间中的一组基(也就是我们的x,y单位坐标轴),如下图所示
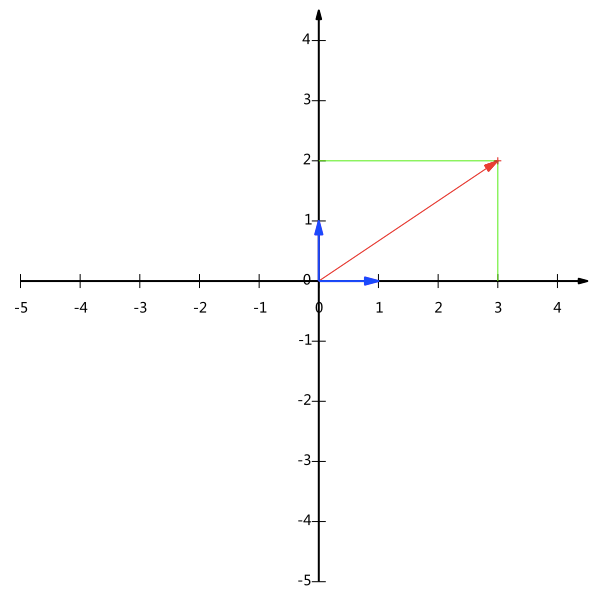
事实上对于一条直线我们可以选择任意两个线性无关的单位向量(选择单位向量是因为便于计算,参考上面的提醒)来表示它的基,如下图所示我们用两条单位对角线作为基(在这里我们选择的基是正交的,因为正交基具有较好的性质,因此一般都选择正交基)
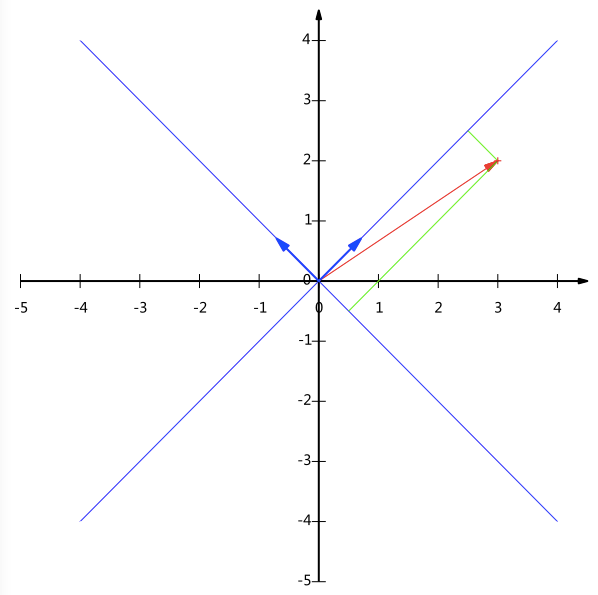
有了这些理解之后,我们可以认为两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间(提醒:该结论会结合下面的PCA中从高维到低维的映射来讨论)
首先假设在低维空间存在这样一个超平面,将数据从高维映射到该超平面上会使得样本之间的方差最大(样本之间方差最大,也就意味着样本在映射到低维之后仍能较好的保留各样本之间的差异性。若映射后存在大量的样本重合,则映射后的样本中会存在大量无用的样本)假定对样本做中心化处理,也就是使得样本的均值为0,则所有样本的方差和可以表示为
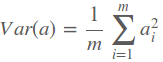
因此我们只要找到一组基,使得样本投影到每个基上的方差最大,但是这样存在一个问题,因为在寻找每个基时都是满足方差最大,这可能会导致后面的基和前面的基重合,这样就没有意义。因此单纯的选择方差最大的方向显然是不合适的,我们引入一个约束条件。在寻找这样一组正交基时,我们不仅要使得映射后的方差最大,还要使得各特征之间的协方差为0(协方差表示特征之间的相关性,使得特征都线性无关)协方差表示如下
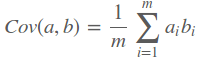
那么对于方差和协方差有没有一个可以同时表达这两个值的东西呢?协方差矩阵就可以,协方差矩阵是对称矩阵,矩阵的对角线上是方差,其余的值都是协方差,其具体表示如下
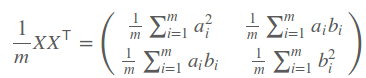
那么问题就好求解了,我们只要将协方差矩阵进行对角化,对角化后的矩阵除了对角线上的值,其余的值都为0
设原始数据矩阵X对应的协方差矩阵为$C$,而$P$是一组基按行组成的矩阵,设$Y=PX$,则$Y$为$X$对$P$做基变换后的数据。设$Y$的协方差矩阵为$D$,我们推导一下$D$与$C$的关系
$D = Y {Y^T} = P X {X^T} {P^T} = P C {P^T}$
优化目标变成了寻找一个矩阵$P$,满足是正交基矩阵,并且对角元素按从大到小依次排列,那么$P$的前$K$行就是要寻找的基,用$P$的前$K$行组成的矩阵乘以$X$就使得$X$从$N$维降到了$K$维并满足上述优化条件。
因此现在我们只需要对协方差矩阵C做对角化就好了,而且由于C是实对称矩阵,因此满足不同特征值下的特征向量两两正交。对协方差矩阵C做对角化

然后我们要找的$P$就是
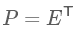
得到$P$之后就可以直接求得我们降维后的矩阵$Y = PX$(注意:这里对于矩阵$X$做左乘是会压缩行的,也就是矩阵$Y$的行数要少于矩阵$X$,因此原始矩阵$X$是$n * m$,其中$n$是特征数,$m$是样本数)。这就是整个PCA的简单理解流程
事实上在数据量很大时,求协方差矩阵,然后在进行特征分解是一个很慢的过程,因此在PCA背后的实现也是借助奇异值分解来做的,在这里我们只要求得奇异值分解中的左奇异向量或右奇异向量中的一个(具体求哪个是要根据你的X向量的书写方式的,即行数是样本数还是特征数,总之左奇异向量是用来压缩行数,右奇异向量是用来压缩列数,而我们的目的是要压缩特征数)
在我们的PCA转换中是一个线性转换,因此也被称为线性降维。但有时数据不是线性的,无法用线性降维获得好的结果,那么这里就引入了我们的核PCA方法来处理这些问题,具体表达式如下
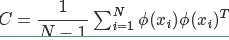
只需要在求协方差矩阵时,将数据先映射到高维(根据低维不可分的数据在高维必定可分的原理),然后再对这高维的数据进行PCA降维处理,为了减少计算量,像支持向量机中那样用核函数来处理求内积的问题。这类方法就是核主成分分析方法(KPCA),KPCA由于要做核运算,因此计算量比PCA大很多。
机器学习算法总结(九)——降维(SVD, PCA)的更多相关文章
- Andrew Ng机器学习算法入门(九):逻辑回归
逻辑回归 先前所讲的线性回归主要是一个预测问题,根据已知的数据去预测接下来的情况.线性回归中的房价的例子就很好地说明了这个问题. 然后在现实世界中,很多问题不是预测问题而是一个分类问题. 如邮件是否为 ...
- 机器学习算法-PCA降维技术
机器学习算法-PCA降维 一.引言 在实际的数据分析问题中我们遇到的问题通常有较高维数的特征,在进行实际的数据分析的时候,我们并不会将所有的特征都用于算法的训练,而是挑选出我们认为可能对目标有影响的特 ...
- Python机器学习笔记 使用scikit-learn工具进行PCA降维
之前总结过关于PCA的知识:深入学习主成分分析(PCA)算法原理.这里打算再写一篇笔记,总结一下如何使用scikit-learn工具来进行PCA降维. 在数据处理中,经常会遇到特征维度比样本数量多得多 ...
- 简单易学的机器学习算法—SVD奇异值分解
简单易学的机器学习算法-SVD奇异值分解 一.SVD奇异值分解的定义 假设M是一个的矩阵,如果存在一个分解: 其中的酉矩阵,的半正定对角矩阵,的共轭转置矩阵,且为的酉矩阵.这样的分解称为M的奇 ...
- PCA算法 | 数据集特征数量太多怎么办?用这个算法对它降维打击!
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第27文章,我们一起来聊聊数据处理领域的降维(dimensionality reduction)算法. 我们都知道,图片 ...
- 机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理)
前言: 找工作时(IT行业),除了常见的软件开发以外,机器学习岗位也可以当作是一个选择,不少计算机方向的研究生都会接触这个,如果你的研究方向是机器学习/数据挖掘之类,且又对其非常感兴趣的话,可以考虑考 ...
- 建模分析之机器学习算法(附python&R代码)
0序 随着移动互联和大数据的拓展越发觉得算法以及模型在设计和开发中的重要性.不管是现在接触比较多的安全产品还是大互联网公司经常提到的人工智能产品(甚至人类2045的的智能拐点时代).都基于算法及建模来 ...
- 机器学习实战 - 读书笔记(13) - 利用PCA来简化数据
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第13章 - 利用PCA来简化数据. 这里介绍,机器学习中的降维技术,可简化样品数据. ...
- paper 19 :机器学习算法(简介)
本来看了一天的分类器方面的代码,乱乱的,索性再把最基础的概念拿过来,现总结一下机器学习的算法吧! 1.机器学习算法简述 按照不同的分类标准,可以把机器学习的算法做不同的分类. 1.1 从机器学习问题角 ...
随机推荐
- python文件
目录 1. 文件的概念 1.1 文件的概念和作用 1.2 文件的存储方式 2. 文件的基本操作 2.1 操作文件的套路 2.2 操作文件的函数/方法 2.3 read 方法 -- 读取文件 2.4 打 ...
- Android Lifecycle使用
引言 Lifecycle 是官方提供的架构组件之一,目前已经是稳定版本,Lifecycle 组件包括LifecycleOwner.LifecycleObserver.Lifecycle 组件是执行操作 ...
- BZOJ2434: [Noi2011]阿狸的打字机(AC自动机 树状数组)
Time Limit: 10 Sec Memory Limit: 256 MBSubmit: 4140 Solved: 2276[Submit][Status][Discuss] Descript ...
- Android为TV端助力 转载:Android绘图Canvas十八般武器之Shader详解及实战篇(上)
前言 Android中绘图离不开的就是Canvas了,Canvas是一个庞大的知识体系,有Java层的,也有jni层深入到Framework.Canvas有许多的知识内容,构建了一个武器库一般,所谓十 ...
- Android 消息异步处理之AsyncTask
Android提供了异步处理消息的方式大致有两种,第一种是handler+Thread,之前已经对于这种方式做过分析,第二种就是AsyncTask,这是Android1.5提供的一种轻量级的工具类,其 ...
- vue.runtime.esm.js:593 [Vue warn]: Invalid prop: custom validator check failed for prop "value".报错解决
在uni中使用 picker组件,一直报错 vue.runtime.esm.js:593 [Vue warn]: Invalid prop: custom validator check failed ...
- Pycharm配置anaconda环境
概述 在上节介绍了anaconda管理python环境,而Pycharm作为主流python IDE,两者配合使用才算完美. 配置 File - Setting - Project Interpret ...
- (办公)Mysql入门
数据库的操作:1.用 SHOW 显示已有的数据库show databases 2.创建数据库:create database 创建数据库create database db_name3.删除数据库:d ...
- (python)数据结构---字典
一.描述 由键值key-value组成的数据的集合 可变.无序的,key不可以重复 字典的键key要可hash(列表.字典.集合不可哈希),不可变的数据结构是可哈希的(字符串.元组.对象.bytes) ...
- MySQL线程处于Waiting for table flush的分析
最近遇到一个案例,很多查询被阻塞没有返回结果,使用show processlist查看,发现不少MySQL线程处于Waiting for table flush状态,查询语句一直被阻塞,只能通过K ...