logstash日志采集工具的安装部署
1.从官网下载安装包,并通过Xftp5上传到机器集群上
下载logstash-6.2.3.tar.gz版本,并通过Xftp5上传到hadoop机器集群的第一个节点node1上的/opt/uploads/目录:

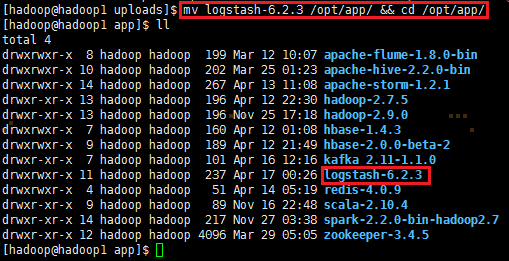
2、解压logstash-6.2.3.tar.gz,并把解压的安装包移动到/opt/app/目录上
tar zxvf logstash-6.2.3.tar.gz

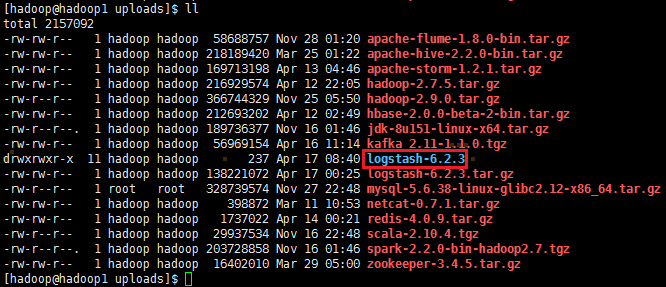
mv logstash-6.2.3 /opt/app/ && cd /opt/app/
3、修改环境变量,编辑/etc/profile,并生效环境变量,输入如下命令:
sudo vi /etc/profile
添加如下内容:
export LOGSTASH_HOME=/opt/app/logstash-6.2.3
export PATH=:$PATH:$LOGSTASH_HOME/bin
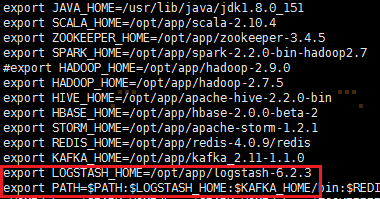
使环境变量生效:source /etc/profile
4、配置文件类型
4.1 log-kafka配置文件
输入源为nginx的日志文件,输出源为kafka
input {
file {
path => "/var/logs/nginx/*.log"
discover_interval => 5
start_position => "beginning"
}
}
output {
kafka {
topic_id => "accesslog"
codec => plain {
format => "%{message}"
charset => "UTF-8"
}
bootstrap_servers => "hadoop1:9092,hadoop2:9092,hadoop3:9092"
}
}
4.2 file-kafka配置文件
输入源为txt文件,输出源为kafka
input {
file {
codec => plain {
charset => "GB2312"
}
path => "D:/GameLog/BaseDir/*/*.txt"
discover_interval => 30
start_position => "beginning"
}
}
output {
kafka {
topic_id => "gamelog"
codec => plain {
format => "%{message}"
charset => "GB2312"
}
bootstrap_servers => "hadoop1:9092,hadoop2:9092,hadoop3:9092"
}
}
4.3 log-elasticsearch配置文件
输入源为nginx的日志文件,输出源为elasticsearch
input {
file {
type => "flow"
path => "var/logs/nginx/*.log"
discover_interval => 5
start_position => "beginning"
}
}
output {
if [type] == "flow" {
elasticsearch {
index => "flow-%{+YYYY.MM.dd}"
hosts => ["hadoop1:9200", "hadoop2:9200", "hadoop3:9200"]
}
}
}
4.4 kafka-elasticsearch配置文件
输入源为kafka的accesslog和gamelog主题,并在中间分别针对accesslog和gamelog进行过滤,输出源为elasticsearch。当input里面有多个kafka输入源时,client_id => "es*"必须添加且需要不同,否则会报错javax.management.InstanceAlreadyExistsException: kafka.consumer:type=app-info,id=logstash-0。
input {
kafka {
type => "accesslog"
codec => "plain"
auto_offset_reset => "earliest"
client_id => "es1"
group_id => "es1"
topics => ["accesslog"]
bootstrap_servers => "hadoop1:9092,hadoop2:9092,hadoop3:9092"
}
kafka {
type => "gamelog"
codec => "plain"
auto_offset_reset => "earliest"
client_id => "es2"
group_id => "es2"
topics => ["gamelog"]
bootstrap_servers => "hadoop1:9092,hadoop2:9092,hadoop3:9092"
}
}
filter {
if [type] == "accesslog" {
json {
source => "message"
remove_field => ["message"]
target => "access"
}
}
if [type] == "gamelog" {
mutate {
split => { "message" => " " }
add_field => {
"event_type" => "%{message[3]}"
"current_map" => "%{message[4]}"
"current_x" => "%{message[5]}"
"current_y" => "%{message[6]}"
"user" => "%{message[7]}"
"item" => "%{message[8]}"
"item_id" => "%{message[9]}"
"current_time" => "%{message[12]}"
}
remove_field => ["message"]
}
}
}
output {
if [type] == "accesslog" {
elasticsearch {
index => "accesslog"
codec => "json"
hosts => ["hadoop1:9200","hadoop2:9200","hadoop3:9200"]
}
}
if [type] == "gamelog" {
elasticsearch {
index => "gamelog"
codec => plain {
charset => "UTF-16BE"
}
hosts => ["hadoop1:9200","hadoop2:9200","hadoop3:9200"]
}
}
}
注:UTF-16BE为解决中文乱码,而不是UTF-8
5、logstash启动
logstash -f /opt/app/logstash-6.2.3/conf/flow-kafka.conf

6、logstash遇到的问题
1) 在使用logstash采集日志时,如果我们采用file为input类型,采用不能反复对一份文件进行测试!第一次会成功,之后就会失败!
参考资料:
https://blog.csdn.net/lvyuan1234/article/details/78653324
logstash日志采集工具的安装部署的更多相关文章
- 日志采集客户端 filebeat 安装部署
linux----------------1. 下载wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.5.1- ...
- filebeat + logstash 日志采集链路配置
1. 概述 一个完整的采集链路的流程如下: 所以要进行采集链路的部署需要以下几个步聚: nginx的配置 filebeat部署 logstash部署 kafka部署 kudu部署 下面将详细说明各个部 ...
- Hadoop生态圈-flume日志收集工具完全分布式部署
Hadoop生态圈-flume日志收集工具完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 目前为止,Hadoop的一个主流应用就是对于大规模web日志的分析和处理 ...
- docker可视化集中管理工具shipyard安装部署
docker可视化集中管理工具shipyard安装部署 Shipyard是在Docker Swarm实现对容器.镜像.docker集群.仓库.节点进行管理的web系统. 1.Shipyard功能 Sh ...
- 大数据应用日志采集之Scribe 安装配置指南
大数据应用日志采集之Scribe 安装配置指南 大数据应用日志采集之Scribe 安装配置指南 1.概述 Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量的应用.它 ...
- flume 日志采集工具
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并 ...
- 运维工具Ansible安装部署
http://blog.51cto.com/liqingbiao/1875921 centos7安装部署ansible https://www.cnblogs.com/bky185392793/p/7 ...
- 日志采集工具Flume的安装与使用方法
安装Flume,参考厦门大学林子雨教程:http://dblab.xmu.edu.cn/blog/1102/ 并完成案例1 1.案例1:Avro source Avro可以发送一个给定的文件给Flum ...
- Filebeat轻量级日志采集工具
Beats 平台集合了多种单一用途数据采集器.这些采集器安装后可用作轻量型代理,从成百上千或成千上万台机器向 Logstash 或 Elasticsearch 发送数据. 一.架构图 此次试验基于前几 ...
随机推荐
- IDEA 新建 module
maven项目可以创建多个module,在IDEA中具体操作 1.在已经建好的maven项目上右键 2.新建: 效果如下: 这时在子pom.xml中 <parent> <artifa ...
- 自定义chromium浏览器
自定义chromium浏览器 来源 https://chaopeng.me/blog/2018/08/17/how-to-develop-full-homebrew-browser.html 最近有 ...
- 关于thinkphp5URL重写
可以通过URL重写隐藏应用的入口文件index.php,下面是相关服务器的配置参考: [ Apache ] httpd.conf配置文件中加载了mod_rewrite.so模块 AllowOverri ...
- 自学Aruba之添加黑名单Blacklists方法
点击返回:自学Aruba之路点击返回:自学Aruba集锦 07 自学Aruba之添加黑名单Blacklists方法 方法一:页面添加方式,临时添加黑名单(禁止入网60min)方法二:命令行添加方式,临 ...
- 【BZOJ5315】[JSOI2018]防御网络(动态规划,仙人掌)
[BZOJ5315][JSOI2018]防御网络(动态规划,仙人掌) 题面 BZOJ 洛谷 题解 显然图是仙人掌. 题目给了斯坦纳树就肯定不是斯坦纳树了,,,, 总不可能真让你\(2^n\)枚举点集再 ...
- 解决忘记mysql中的root用户密码问题
如果忘了数据库中的root密码,无法登陆mysql. 解决步骤: 1. 使用“--skip-grant-tables”启动数据库 ~]#systemctl stop mysql ~]#mysqld_s ...
- A1137. Final Grading
For a student taking the online course "Data Structures" on China University MOOC (http:// ...
- Apache Ant 项目构建
项目构建:通过构建工具对多个项目进行统一批量的编译和运行,比如,对多个Jmeter脚本批量运行 1.Ant是什么? Ant是 构建工具,Apache Ant是一个将软件编译.测试.部署等步骤联系在一起 ...
- tensorflow不同版本安装与升级/降级
https://blog.csdn.net/junmuzi/article/details/78357371 首先,可以安装一个anaconda. 然后使用python的pip可以安装特定版本的ten ...
- spring 的 transactionManager 事务管理器 配置
转: 事务的传播特<tx:advice id="txadvice" transaction-manager="transactionManager"> ...