python:网络爬虫的学习笔记
如果要爬取的内容嵌在网页源代码中的话,直接下载网页源代码再利用正则表达式来寻找就ok了。下面是个简单的例子:
import urllib.request
html = urllib.request.urlopen('http://www.massey.ac.nz/massey/learning/programme-course/programme.cfm?prog_id=93536')
html = html.read().decode('utf-8')
注意,decode方法有时候可能会报错,例如
html = urllib.request.urlopen('http://china.nba.com/')
html = html.read().decode('utf-8')
Traceback (most recent call last):
File "<ipython-input-6-fc582e316612>", line 1, in <module>
html = html.read().decode('utf-8')
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd6 in position 85: invalid continuation byte
具体原因不知道,可以用decode的一个参数,如下
html = html.read().decode('utf-8','replace')
html = urllib.request.urlopen('http://china.nba.com/')
html = html.read().decode('utf-8','replace')
html
Out[9]: '<!DOCTYPE html>\r\n<html>\r\n<head lang="en">\r\n <meta charset="UTF-8">\r\n <title>NBA�й��ٷ���վ</title>\r\n <meta http-equiv="X-UA-Compatible" content="IE=Edge,chrome=1">\r\n <meta name="description" content="NBA�й��ٷ���վ">\r\n <meta name="keywords"
replace表示遇到不能转码的字符就将其替换成问号还是什么的。。。这也算是一个折中的方法吧。我们继续回到正题。假如说我们想爬取上面提到的网页的课程名称
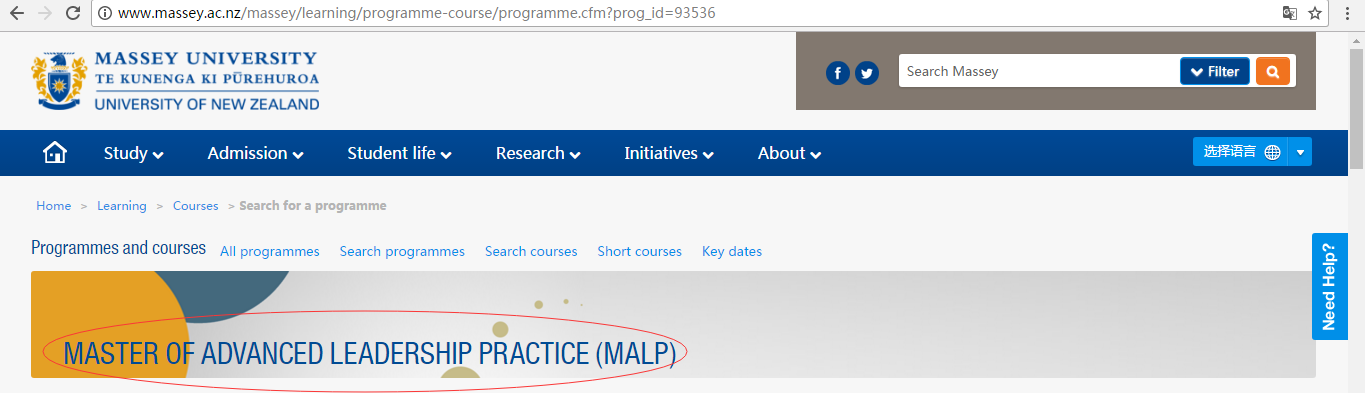
查看网页源代码。我用的谷歌浏览器,右键单击页面,再选择‘查看网页源代码’

再在这个页面上ctrl+F,查找你要爬取的字符:
这个就刚才截图所对应的代码(想看懂源代码还得学习一下html语言啊 http://www.w3school.com.cn/html/index.asp 这个网址挺不错的)
接下来就是用正则表达式把这个字符串扣下来了:
re.findall('<h1>.*?</h1>',html)
Out[35]: ['<h1>Master of Advanced Leadership Practice (<span>MALP</span>)</h1>']
剩下的就是对字符串的切割了:
course = re.findall('<h1>.*?</h1>',html)
course = str(course[0])
course = course.replace('<h1>','')
course = course.replace('(<span>MALP</span>)</h1>','')
结果:
course = re.findall('<h1>.*?</h1>',html)
course = str(course[0])
course = course.replace('<h1>','')
course = course.replace(' (<span>MALP</span>)</h1>','')
course
Out[40]: 'Master of Advanced Leadership Practice'
把它写成一个函数:
def get_course(url):
html = urllib.request.urlopen(url)
html = html.read().decode('utf-8')
course = re.findall('<h1>.*?</h1>',html)
course = str(course[0])
course = course.replace('<h1>','')
course = course.replace(' (<span>MALP</span>)</h1>','')
return course
这样输入该学校的其他课程的网址,同样也能把那个课程的名称扣下来(语文不好,请见谅)
get_course('http://www.massey.ac.nz/massey/learning/programme-course/programme.cfm?prog_id=93059')
Out[48]: 'Master of Counselling Studies (<span>MCounsStuds</span>)</h1>'
这就很尴尬了,原因是第二个replace函数,pattern是错误的,看来还得用正则改一下
def get_course(url):
html = urllib.request.urlopen(url)
html = html.read().decode('utf-8')
course = re.findall('<h1>.*?</h1>',html)
course = str(course[0])
course = course.replace('<h1>','')
repl = str(re.findall(' \(<span>.*?</span>\)</h1>',course)[0])
course = course.replace(repl,'')
return course
再试试
get_course('http://www.massey.ac.nz/massey/learning/programme-course/programme.cfm?prog_id=93059')
Out[69]: 'Master of Counselling Studies'
搞定!
其实可以用BeautifulSoup直接解析源代码,使得查找定位更快。下一篇在说吧
这其实是我在广州第一份工作要干的活,核对网址是否存在,是否还是原来的课程。那个主管要人工核对。。。1000多个网址,他说他就是自己人工核对的,哈哈,我可不愿意干这活。当时也尝试用R语言去爬取课程名,试了很久。。。比较麻烦吧,后来学了python。现在要核对的话估计十分钟就能搞定1000多个网址了吧。就想装个b,大家可以无视
python:网络爬虫的学习笔记的更多相关文章
- Python网络爬虫与信息提取笔记
直接复制粘贴笔记发现有问题 文档下载地址//download.csdn.net/download/hide_on_rush/12266493 掌握定向网络数据爬取和网页解析的基本能力常用的 Pytho ...
- 《用Python写爬虫》学习笔记(一)
注:纯文本内容,代码独立另写,属于本人学习总结,无任何商业用途,在此分享,如有错误,还望指教. 1.为什么需要爬虫? 答:目前网络API未完全放开,所以需要网络爬虫知识. 2.爬虫的合法性? 答:爬虫 ...
- 《Python网络编程》学习笔记--使用谷歌地理编码API获取一个JSON文档
Foundations of Python Network Programing,Third Edition <python网络编程>,本书中的代码可在Github上搜索fopnp下载 本 ...
- 《用Python写爬虫》学习笔记(二)编写第一个网络爬虫
1.首先,下载网页使用Python的urllib2模块,或者Python HTTP模块request来实现 urllib2会出现问题,解决方法1.重试下载(设置下载次数) 2.设置用户代理 2.其次, ...
- 《Python网络编程》学习笔记--从例子中收获的计算机网络相关知识
从之前笔记的四个程序中(http://www.cnblogs.com/take-fetter/p/8278864.html),我们可以看出分别使用了谷歌地理编码API(对URL表示地理信息查询和如何获 ...
- 《Python网络编程》学习笔记--UDP协议
第二章中主要介绍了UDP协议 UDP协议的定义(转自百度百科) UDP是OSI参考模型中一种无连接的传输层协议,它主要用于不要求分组顺序到达的传输中,分组传输顺序的检查与排序由应用层完成,提供面向事务 ...
- 关于Python网络爬虫实战笔记①
python网络爬虫项目实战笔记①如何下载韩寒的博客文章 python网络爬虫项目实战笔记①如何下载韩寒的博客文章 1. 打开韩寒博客列表页面 http://blog.sina.com.cn/s/ar ...
- 【python网络爬虫】之requests相关模块
python网络爬虫的学习第一步 [python网络爬虫]之0 爬虫与反扒 [python网络爬虫]之一 简单介绍 [python网络爬虫]之二 python uillib库 [python网络爬虫] ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
随机推荐
- array数据处理
之前写过map,forEach,现在用到every和some,记录一下当作学习笔记,方便以后翻阅. forEach是没有返回值的,对原数组进行修改: // forEach没有返回值,只针对每个元素调用 ...
- jeesite 跳开登录页面直接访问
把控制层的${adminPath}改为${frontPath} 访问时吧/a改为/f 也可以在jeesite配置文件内配置两个的值 http://localhost:8181/cxfvp/a?logi ...
- Java学习笔记【九、集合框架】
集合框架设计的目标: 高性能. 允许不同类型的集合,以类似的方式工作,有互操作性. 对一个集合的扩展和适应必须简单. 集合框架包含: 接口:代表集合的抽象数据类型. 实现(类):具体实现(ArrayL ...
- mac下MySQL出现乱码的解决方法
之前写过一篇Linux下MySQL出现乱码的解决方法,本文说下mac下的处理,其实处理方式是一样的,我电脑的mysql版本是5.7.26-log 网上很多帖子都说去/usr/local/mysql/s ...
- 《python解释器源码剖析》第5章--python中的tuple对象
5.0 序 我们知道对于tuple,就相当于不支持元素添加.修改.删除等操作的list 5.1 PyTupleObject对象 tuple的实现机制非常简单,可以看做是在list的基础上删除了增删改等 ...
- Python3.8新特性-- 海象操作符
“理论联系实惠,密切联系领导,表扬和自我表扬”——我就是老司机,曾经写文章教各位怎么打拼职场的老司机. 不记得没关系,只需要知道:有这么一位老司机, 穿上西装带大家打拼职场! 操起键盘带大家打磨技术! ...
- gluOrtho2D与glViewport
https://blog.csdn.net/HouraisanF/article/details/83444183 窗口与显示主要与三个量有关:世界坐标,窗口大小和视口大小.围绕这些量共有4个函数: ...
- luogu4366 [Code+#4]最短路[优化建边最短路]
显然这里的$n^2$级别的边数不能全建出来,于是盯住xor这个关键点去 瞎猜 探究有没有什么特殊性质可以使得一些边没有必要建出来. 发现一个点经过一次xor $x$,花费$x$这么多代价(先不看$C$ ...
- Web应用界面好帮手!DevExtreme React和Vue组件全新功能上线
行业领先的.NET界面控件DevExpress 正式发布了v19.1版本,本文将主要介绍DevExtremev19.1中React组件响应式应用程序布局模板及CLI工具.本地React图表,和Vue组 ...
- static和assets的区别
assets和static两个都是用于存放静态资源文件. 放在static中的文件不会进行构建编译处理,也就不会压缩体积,在打包时效率会更高,但体积更大在服务器中就会占据更大的空间 放在assets中 ...