线上Storm的worker,executor,task参数调优篇
问题引入:
线上最近的数据量越来越大,出现了数据处理延迟的现象,观察storm ui的各项数据,发现有大量的spout失败的情况,如下:
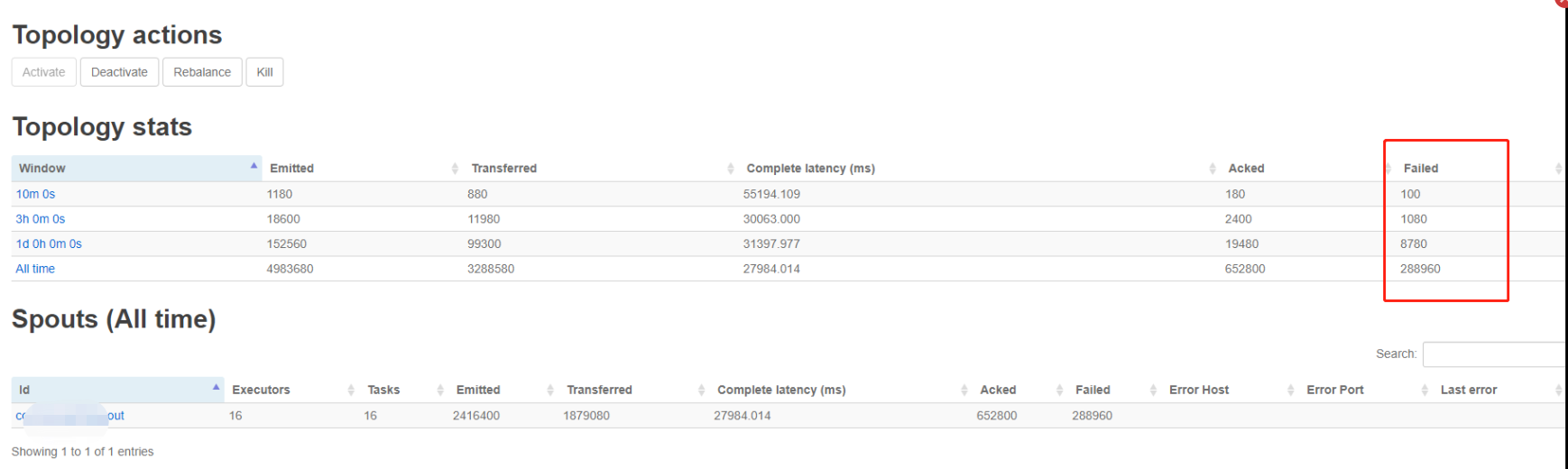
----------------------------------------------------------------------------------------------------------------------------------------------------------------
然后根据storm并发度的一些理论,进行一些参数的配置调整:
Storm的并行度是非常重要的,通过提高并行度可以提高storm程序的计算能力。
那strom是如何提高并行度的呢?
Strom程序的执行是由多个supervisor共同执行的。
supervisor运行的是topology中的spout/bolt task
task 是storm中进行计算的最小的运行单位,表示是spout或者bolt的运行实例。
程序执行的最大粒度的运行单位是进程,刚才说的task也是需要有进程来运行它的,在supervisor中,运行task的进程称为worker,
Supervisor节点上可以运行非常多的worker进程,一般在一个进程中是可以启动多个线程的,所以我们可以在worker中运行多个线程,这些线程称为executor,在executor中运行task。
这样的话就可以提高strom的计算能力。
总结一下:worker>executor>task
要想提高storm的并行度可以从三个方面来改造
worker(进程)>executor(线程)>task(实例)
增加work进程,增加executor线程,增加task实例
worker的设置:
这表示是一个work进程,其实就是一个jvm虚拟机进程,在这个work进程里面有多个executor线程,每个executor线程会运行一个或多个task实例。一个task是最终完成数据处理的实体单元。(默认情况下一个executor运行一个task)
worker,executor,task解释:
1个worker进程执行的是1个topology的子集(注:不会出现1个worker为多个topology服务)。
1个worker进程会启动1个或多个executor线程来执行1个topology的component(spout或bolt)。因此,1个运行中的topology就是由集群中多台物理机上的多个worker进程组成的。
executor是1个被worker进程启动的单独线程。每个executor只会运行1个topology的1个component(spout或bolt)的task(注:task可以是1个或多个,storm默认是1个component只生成1个task,executor线程里会在每次循环里顺序调用所有task实例)。
task是最终运行spout或bolt中代码的单元(注:1个task即为spout或bolt的1个实例,executor线程在执行期间会调用该task的nextTuple或execute方法)。topology启动后,1个component(spout或bolt)的task数目是固定不变的,但该component使用的executor线程数可以动态调整(例如:1个executor线程可以执行该component的1个或多个task实例)。这意味着,对于1个component存在这样的条件:#threads<=#tasks(即:线程数小于等于task数目)。默认情况下task的数目等于executor线程数目,即1个executor线程只运行1个task。
刚才从理论说明了如何提高集群的并行度,在这里我们就来看一下这些东西worker(进程)>executor(线程)>task(实例) 是如何设置的:
l worker(进程):这个worker进程数量是在集群启动之前配置好的,在哪配置的呢?是在storm/conf/storm.yaml文件中,参数是supervisor.slots.port,如果我们不在这进行配置的话,这个参数也是有默认值的,在strom-0.9.3的压缩包中的lib目录下,有一个strom-core.jar,打开这个jar文件,在里面有一个defaults.yaml文件中是有一些默认配置的。
默认情况下一个storm项目只使用一个work进程,也可以通过代码进行修改,通过config.setNumWorkers(workers)设置。
注意:如果worker使用完的话再提交topology就不会执行,因为没有可用的worker,只能处于等待状态,把之前运行的topology停止一个之后这个就会继续执行了,
这里项目中存在3个脱坡,两个worker设置为20;另外一个数据量大的设置worker数为40;相当于等于线上机器的CPU核数;(注意:我的storm ui上的slots总数为160,但是我没有把worker数设置的更大,我的考虑是如果设置大于CPU核数,有可能反而会影响其性能,所以最终设置每个拓扑中的worker数最大不超过40,此处不一定设置大于40要不好,有了解的可以留言讨论一下);

下面以worker数为20的这个拓扑来进行分析:

将超时时间由原来的30扩大到600;最大的spout缓存设置为1000*spout数=20000;ack的数设置为20(ack的个数要保持与worker一样,因为每个worker会创建一个executor来处理ack,)
executor(线程):
executor(线程):默认情况下一个executor运行一个task,可以通过在代码中设置builder.setSpout(id,spout, parallelism_hint);或者builder.setBolt(id,bolt,parallelism_hint);来提高线程数的。
task(实例):通过boltDeclarer.setNumTasks(num);来设置实例的个数
默认情况下,一个supervisor节点会启动4个worker进程。每个worker进程会启动1个executor,每个executor启动1个task。
Ok,这几个参数都可以使用一些方法进行增加。

这里设置spout的executor个数为20个,task个数为20个,然后bolt的executor个数设置为120,task设置为120,因为bolt进行数据处理,需要连接redis存储,设置多个线程执行,充分发挥多核CPU性能;
下面来看一下对这些配置修改之后的效果

从ui的显示来看,发现不在有failed出现,没有failed的原因是

这三个参数起了效果,complete latency 的时间是45s,小于我们设置的600,在设置时间可以得到处理,不会有超时failed问题;
但是 发现Complete latency的时间比优化之前降低了,原因应该是我把executor和tasks的数值增大了,由原来的16增大到20,处理的吞度量增大,吞吐量和这个参数成反比;所以增大吞吐量可以增大executor和tasks的值;
下面看另一个问题:

在代码中设置使用20个worker,查看ui界面,发现workers是20个,executors设置了130个,为什么显示executor为150呢?
因为每一个worker默认都会占用一个executor(这个executor会启动一个acker任务),这样就会占用20个,一共 10 + 120 + 20 = 150。
Acker任务默认是每个worker进程启动一个executor线程来执行,,可以在topology中取消acker任务,这样的话就不会多出来一个executor和任务了。
同样task也是这个道理;
注意:除去worker占用外,只有设置足够多的线程和实例才可以真正的提高并行度。
在这设置多个实例主要是为了下面执行rebalance的时候用到,因为rebalance不需要修改代码,就可以动态修改topology的并行度,这样的话就必须提前配置好多个实例,在rebalance的时候主要是对之前设置多余的任务实例分配线程去执行。
在命令行动态修改并行度
除了使用代码进行调整,还可以在shell命令行下对并行度进行调整。
storm rebalance mytopology -w 10 -n 2 -e spout=2 -e bolt=2
表示 10秒之后对mytopology进行并行度调整。把spout调整为2个executor,把bolt调整为2个executor
注意:并行度主要就是调整executor的数量,但是调整之后的executor的数量必须小于等于task的数量,如果分配的executor的线程数比task数量多的话也只能分配和task数量相等的executor。
经过多次试验总结,得出如下结论:
1)Topology的worker数通过config设置,即执行该topology的worker(java)进程数。它可以通过storm rebalance 命令任意调整。
2) Topology中某个bolt的executor数,即parallelismNum,即执行该bolt的线程数,在setBolt时由第三个参数指定。它可以通过storm rebalance 命令调整,但最大不能超过该bolt的task数;
3) bolt的task数,通过setNumTasks()设置。(也可不设置,默认取bolt的executor数),无法在运行时调整。
4)Bolt实例数,这个比较特别,它和task数相等。有多少个task就会new 多少个Bolt对象。而这些Bolt对象在运行时由Bolt的thread进行调度。也即是说
线上Storm的worker,executor,task参数调优篇的更多相关文章
- Storm中-Worker Executor Task的关系
Storm在集群上运行一个Topology时,主要通过以下3个实体来完成Topology的执行工作:1. Worker(进程)2. Executor(线程)3. Task 下图简要描述了这3者之间的关 ...
- Linux上TCP的几个内核参数调优
Linux作为一个强大的操作系统,提供了一系列内核参数供我们进行调优.光TCP的调优参数就有50多个.在和线上问题斗智斗勇的过程中,笔者积累了一些在内网环境应该进行调优的参数.在此分享出来,希望对大家 ...
- 【Spark调优】提交job资源参数调优
[场景] Spark提交作业job的时候要指定该job可以使用的CPU.内存等资源参数,生产环境中,任务资源分配不足会导致该job执行中断.失败等问题,所以对Spark的job资源参数分配调优非常重要 ...
- Spark Shuffle原理、Shuffle操作问题解决和参数调优
摘要: 1 shuffle原理 1.1 mapreduce的shuffle原理 1.1.1 map task端操作 1.1.2 reduce task端操作 1.2 spark现在的SortShuff ...
- spark参数调优
摘要 1.num-executors 2.executor-memory 3.executor-cores 4.driver-memory 5.spark.default.parallelism 6. ...
- 【Spark篇】---Spark中内存管理和Shuffle参数调优
一.前述 Spark内存管理 Spark执行应用程序时,Spark集群会启动Driver和Executor两种JVM进程,Driver负责创建SparkContext上下文,提交任务,task的分发等 ...
- spark submit参数调优
在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都可以在spark-submit命令中作为参数设置.很多Spark初学者,通常不知道该设置哪些必要的参数,以及如何设置 ...
- 【Spark调优】Shuffle原理理解与参数调优
[生产实践经验] 生产实践中的切身体会是:影响Spark性能的大BOSS就是shuffle,抓住并解决shuffle这个主要原因,事半功倍. [Shuffle原理学习笔记] 1.未经优化的HashSh ...
- spark 资源参数调优
资源参数调优 了解完了Spark作业运行的基本原理之后,对资源相关的参数就容易理解了.所谓的Spark资源参数调优,其实主要就是对Spark运行过程中各个使用资源的地方,通过调节各种参数,来优化资源使 ...
随机推荐
- GET 和 POST is so different
.原理区别 一般我们在浏览器输入一个网址访问网站都是GET请求;再FORM表单中,可以通过设置Method指定提交方式为GET或者POST提交方式,默认为GET提交方式. HTTP定义了与服务器交互的 ...
- Educational Codeforces Round 74 (Rated for Div. 2)【A,B,C【贪心】,D【正难则反的思想】】
A. Prime Subtractiontime limit per test2 secondsmemory limit per test256 megabytesinputstandard inpu ...
- JAVA类的无参方法
Java注释: //:单行注释 /**/:多行注释 /** */:JavaDoc注释 方法: ...
- Oracle 审计 部署监控 user DML操作
1.移动audit表及索引到dbadmin表空间 alter table aud$ move tablespace DBADMIN;alter table AUDIT$ move tablespace ...
- 032_备份 MySQL 的 shell 脚本(mysqldump 版本)
#!/bin/bash#定义变量 user(数据库用户名),passwd(数据库密码),date(备份的时间标签)#dbname(需要备份的数据库名称,根据实际需求需要修改该变量的值,默认备份 mys ...
- 025_自动为其他脚本添加解释器信息#!/bin/bash
#!/bin/bash#先使用 grep 判断对象脚本是否已经有解释器信息,如果没有则使用 sed 添加解释器以及描述信息if ! grep -q "^#!" $1; then # ...
- app微信支付的集成步骤
1.引用地址 //微信支付 compile 'com.tencent.mm.opensdk:wechat-sdk-android-with-mta:+' 2.注册 private IWXAPI api ...
- Flask中current_app和g对象
Flask零基础到项目实战(七)请求方法.g对象和钩子函数 一.get方法 二.post方法 post请求在模板中要注意几点: input标签中,要写name来标识这个value的key,方便后台 ...
- Swiper轮播插件使用
前文 Swiper是纯javascript打造的滑动特效插件,面向手机.平板电脑等移动终端,能实现触屏焦点图.触屏Tab切换.触屏多图切换等常用效果. 归根到此,Swi ...
- Qt编写自定义控件33-图片切换动画
一.前言 在很多看图软件中,切换图片的时候可以带上动画过渡或者切换效果,显得更人性化,其实主要还是炫一些,比如百叶窗.透明度变化.左下角飞入等,无论多少种效果,核心都是围绕QPainter来进行,将各 ...