数据结构之链表(LinkedList)(二)
数据结构之链表(LinkedList)(一)
双链表
上一篇讲述了单链表是通过next 指向下一个节点,那么双链表就是指不止可以顺序指向下一个节点,还可以通过prior域逆序指向上一个节点
示意图:
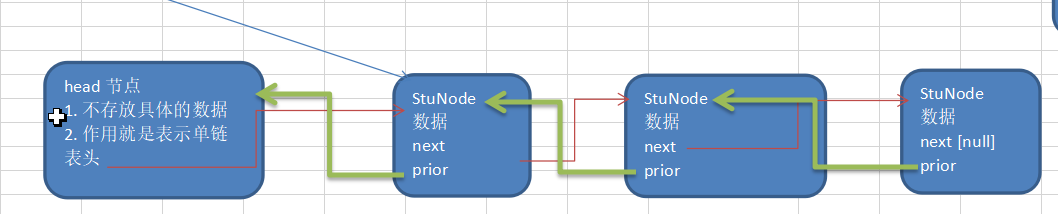
那么怎么来实现双链表的增删改查操作呢。
分析:
1) 遍历 方和 单链表一样,只是可以向前,也可以向后查找
2) 添加 (默认添加到双向链表的最后)
① 先找到双向链表的最后这个节点
② temp.next = newStuNode
③ newStuNode.prior = temp;
3) 修改 思路和 原来的单向链表一样.
4) 删除
①因为是双向链表,因此,我们可以实现自我删除某个节点
② 直接找到要删除的这个节点,比如temp
③ temp.prior.next = temp.next
④ temp.next.prior= temp.prior;
实现代码:
添加&遍历:
默认添加在链表最后一个。
// 添加一个节点到双向链表的最后.
public void add(StuNode2 stuNode2){ // 因为head节点不能动,因此我们需要一个辅助遍历 temp
StuNode2 temp = head;
// 遍历链表,找到最后
while (true) {
// 找到链表的最后
if (temp.next == null) {//
break;
}
// 如果没有找到最后, 将将temp后移
temp = temp.next;
}
// 当退出while循环时,temp就指向了链表的最后
// 形成一个双向链表
temp.next = stuNode2;
stuNode2.prior = temp;
}
添加代码
//遍历双向列表的方法 和单项列表一致
//显示链表[遍历]
public void list() {
//判断链表是否为空
if(head.next == null) {
System.out.println("链表为空");
return;
}
//因为头节点,不能动,因此我们需要一个辅助变量来遍历
StuNode2 temp = head.next;
while(true) {
//判断是否到链表最后
if(temp == null) {
break;
}
//输出节点的信息
System.out.println(temp);
//将temp后移, 一定小心
temp = temp.next;
}
}
遍历代码
public static void main(String[] args) {
//进行测试
//先创建节点
StuNode2 stu1 = new StuNode2(1, "张三", "85");
StuNode2 stu2 = new StuNode2(2, "李四", "87");
StuNode2 stu3 = new StuNode2(3, "小明", "70");
StuNode2 stu4 = new StuNode2(4, "小红", "90");
//创建要给链表
DoubleLinkedList doubleLinkedList = new DoubleLinkedList();
//加入
doubleLinkedList.add(stu1);
doubleLinkedList.add(stu2);
doubleLinkedList.add(stu3);
doubleLinkedList.add(stu4);
System.out.println("原始双链表数据 " );
doubleLinkedList.list();;
}
main
原始双链表数据
StuNode [stuNo=1, name=张三, mark=85]
StuNode [stuNo=2, name=李四, mark=87]
StuNode [stuNo=3, name=小明, mark=70]
StuNode [stuNo=4, name=小红, mark=90]
输出
根据序号排序添加
上面添加是默认添加到最后一个节点,那么要求根据序号默认排序添加呢,其实和单链表是一样思路
public void addByOrder(StuNode2 stuNode2){
StuNode2 temp = head;
boolean flag = false;
while (true){
if (temp.next == null){
break;
}
if (temp.next.stuNo>stuNode2.stuNo){//位置找到
break;
}else if (temp.stuNo == stuNode2.stuNo){
flag=true;
break;
}
temp =temp.next;
}
if (flag){
System.out.printf("准备插入的学生 %d 已经存在了, 不能加入\n", stuNode2.stuNo);
}else{
stuNode2.next=temp.next;
temp.next=stuNode2;
stuNode2.prior=temp;
if(temp.next != null){
temp.next.prior=stuNode2;
}
}
}
代码
修改:
// 修改一个节点的内容, 可以看到双向链表的节点内容修改和单向链表一样
// 只是 节点类型改成 StuNode2
public void update(StuNode2 newStuNode) {
// 判断是否空
if (head.next == null) {
System.out.println("链表为空~");
return;
}
// 找到需要修改的节点, 根据stuNo编号
// 定义一个辅助变量
StuNode2 temp = head.next;
boolean flag = false; // 表示是否找到该节点
while (true) {
if (temp == null) {
break; // 已经遍历完链表
}
if (temp.stuNo == newStuNode.stuNo) {
// 找到
flag = true;
break;
}
temp = temp.next;
}
// 根据flag 判断是否找到要修改的节点
if (flag) {
temp.name = newStuNode.name;
temp.mark = newStuNode.mark;
} else { // 没有找到
System.out.printf("没有找到 学号 %d 的节点,不能修改\n", newStuNode.stuNo);
}
}
修改代码
public static void main(String[] args) {
//进行测试
//先创建节点
StuNode2 stu1 = new StuNode2(1, "张三", "85");
StuNode2 stu2 = new StuNode2(2, "李四", "87");
StuNode2 stu3 = new StuNode2(3, "小明", "70");
StuNode2 stu4 = new StuNode2(4, "小红", "90");
//创建要给链表
DoubleLinkedList doubleLinkedList = new DoubleLinkedList();
//加入
doubleLinkedList.add(stu1);
doubleLinkedList.add(stu2);
doubleLinkedList.add(stu3);
doubleLinkedList.add(stu4);
System.out.println("原始双链表数据 " );
doubleLinkedList.list();;
//修改3号的分数
StuNode2 stu = new StuNode2(3,"小明","99");
doubleLinkedList.update(stu);
System.out.println("修改后的链表");
doubleLinkedList.list();;
}
main
原始双链表数据
StuNode [stuNo=1, name=张三, mark=85]
StuNode [stuNo=2, name=李四, mark=87]
StuNode [stuNo=3, name=小明, mark=70]
StuNode [stuNo=4, name=小红, mark=90]
修改后的链表
StuNode [stuNo=1, name=张三, mark=85]
StuNode [stuNo=2, name=李四, mark=87]
StuNode [stuNo=3, name=小明, mark=99]
StuNode [stuNo=4, name=小红, mark=90]
输出
删除:
上篇单链表的思路是找到要删除节点的前一个节点,然后待删除节点的前一个节点直接指向待删除节点的后一个节点,隐藏待删除的节点,从而达到删除目的。
那么双链表可以直接找到待删除节点temp,通过逆指向 temp.prior 找到待删除节点的上一个节点,然后顺指向temp.prior.next 指向待删除节点的下一个节点temp.next
也就是 temp.prior.next = temp.next。同时要修改 待删除节点的下一个节点的逆指向 指向待删除节点的上一个节点,也就是temp.next.prior= temp.prior;
示意图:
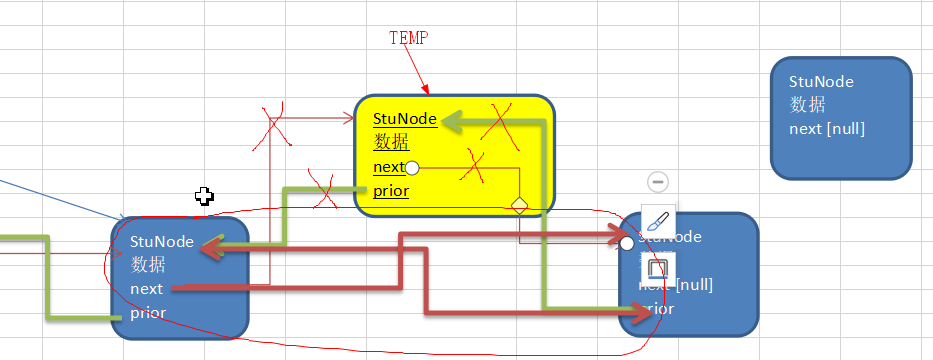
// 从双向链表中删除一个节点,
// 说明
// 1 对于双向链表,我们可以直接找到要删除的这个节点
// 2 找到后,自我删除即可
public void del(int stuNo) { // 判断当前链表是否为空
if (head.next == null) {// 空链表
System.out.println("链表为空,无法删除");
return;
} StuNode2 temp = head.next; // 辅助变量(指针)
boolean flag = false; // 标志是否找到待删除节点的
while (true) {
if (temp == null) { // 已经到链表的最后
break;
}
if (temp.stuNo == stuNo) {
// 找到的待删除节点的前一个节点temp
flag = true;
break;
}
temp = temp.next; // temp后移,遍历
}
// 判断flag
if (flag) { // 找到
// 可以删除
// temp.next = temp.next.next;[单向链表]
temp.prior.next = temp.next;
// 如果是最后一个节点,就不需要执行下面这句话,否则出现空指针
if (temp.next != null) {
temp.next.prior = temp.prior;
}
} else {
System.out.printf("要删除的 %d 节点不存在\n", stuNo);
}
}
删除代码
public static void main(String[] args) {
//进行测试
//先创建节点
StuNode2 stu1 = new StuNode2(1, "张三", "85");
StuNode2 stu2 = new StuNode2(2, "李四", "87");
StuNode2 stu3 = new StuNode2(3, "小明", "70");
StuNode2 stu4 = new StuNode2(4, "小红", "90");
//创建要给链表
DoubleLinkedList doubleLinkedList = new DoubleLinkedList();
//加入
doubleLinkedList.add(stu1);
doubleLinkedList.add(stu2);
doubleLinkedList.add(stu3);
doubleLinkedList.add(stu4);
System.out.println("原始双链表数据 " );
doubleLinkedList.list();
//删除3号数据
doubleLinkedList.del(3);
System.out.println("删除后的链表 " );
doubleLinkedList.list();
}
main
原始双链表数据
StuNode [stuNo=1, name=张三, mark=85]
StuNode [stuNo=2, name=李四, mark=87]
StuNode [stuNo=3, name=小明, mark=70]
StuNode [stuNo=4, name=小红, mark=90]
删除后的链表
StuNode [stuNo=1, name=张三, mark=85]
StuNode [stuNo=2, name=李四, mark=87]
StuNode [stuNo=4, name=小红, mark=90]
输出
数据结构之链表(LinkedList)(二)的更多相关文章
- 数据结构之链表(LinkedList)(三)
数据结构之链表(LinkedList)(二) 环形链表 顾名思义 环形列表是一个首尾相连的环形链表 示意图 循环链表的特点是无须增加存储量,仅对表的链接方式稍作改变,即可使得表处理更加方便灵活. 看一 ...
- Python与数据结构[0] -> 链表/LinkedList[0] -> 单链表与带表头单链表的 Python 实现
单链表 / Linked List 目录 单链表 带表头单链表 链表是一种基本的线性数据结构,在C语言中,这种数据结构通过指针实现,由于存储空间不要求连续性,因此插入和删除操作将变得十分快速.下面将利 ...
- 数据结构之链表(LinkedList)(一)
链表(Linked List)介绍 链表是有序的列表,但是它在内存中是存储如下 1)链表是以节点方式存储的,是链式存储 2)每个节点包含data域(value),next域,指向下一个节点 3)各个节 ...
- Python与数据结构[0] -> 链表/LinkedList[1] -> 双链表与循环双链表的 Python 实现
双链表 / Doubly Linked List 目录 双链表 循环双链表 1 双链表 双链表和单链表的不同之处在于,双链表需要多增加一个域(C语言),即在Python中需要多增加一个属性,用于存储指 ...
- Python与数据结构[0] -> 链表/LinkedList[2] -> 链表有环与链表相交判断的 Python 实现
链表有环与链表相交判断的 Python 实现 目录 有环链表 相交链表 1 有环链表 判断链表是否有环可以参考链接, 有环链表主要包括以下几个问题(C语言描述): 判断环是否存在: 可以使用追赶方法, ...
- 《数据结构与算法分析——C语言描述》ADT实现(NO.00) : 链表(Linked-List)
开始学习数据结构,使用的教材是机械工业出版社的<数据结构与算法分析——C语言描述>,计划将书中的ADT用C语言实现一遍,记录于此.下面是第一个最简单的结构——链表. 链表(Linked-L ...
- 数据结构-List接口-LinkedList类-Set接口-HashSet类-Collection总结
一.数据结构:4种--<需补充> 1.堆栈结构: 特点:LIFO(后进先出);栈的入口/出口都在顶端位置;压栈就是存元素/弹栈就是取元素; 代表类:Stack; 其 ...
- 基本数据结构:链表(list)
copy from:http://www.cppblog.com/cxiaojia/archive/2012/07/31/185760.html 基本数据结构:链表(list) 谈到链表之前,先说一下 ...
- SDUT 2142 数据结构实验之图论二:基于邻接表的广度优先搜索遍历
数据结构实验之图论二:基于邻接表的广度优先搜索遍历 Time Limit: 1000MS Memory Limit: 65536KB Submit Statistic Problem Descript ...
随机推荐
- YII2 输出 执行的 SQL 语句,直接用程序输出
$query = User::find() ->,,,]) ->select(['username']) // 输出SQL语句 $commandQuery = clone $query; ...
- mvn创建flink项目
使用如下项目骨架创建flink项目,结果被官方的下面这个创建方式坑了.. mvn archetype:generate \ -DarchetypeGroupId=org.apache.flink \ ...
- Typescript中的类 Es5中的类和静态方法和继承(原型链继承、对象冒充继承、原型链+对象冒充组合继承)
<!doctype html> <html> <head> <meta charset="utf-8"> <meta name ...
- Docker容器(二)——镜像制作
制作Docker镜像有两种方式:第一种.docker commit,保存容器(Container)的当前状态到镜像后,然后生成对应的image:第二种.docker build,使用Dockerfil ...
- 了解美杜莎(Medusa)
(1).美杜莎介绍 Medusa(美杜莎)是一个速度快,支持大规模并行,模块化的暴力破解工具.可以同时对多个主机,用户或密码执行强力测试.Medusa和hydra一样,同样属于在线密码破解工具.Med ...
- (二十三)IDEA 构建一个springboot工程,以及可能遇到的问题
一.下载安装intellij IEDA 需要破解 二.创建springboot工程 其他步骤省略,创建好的工程结构如下图: 三.配置springoboot工程 3.1 如上图src/main目录下只有 ...
- Android Butterknife使用方法总结 IOC框架
前言: ButterKnife是一个专注于Android系统的View注入框架,以前总是要写很多findViewById来找到View对象,有了ButterKnife可以很轻松的省去这些步骤.是大神J ...
- mssql的update :from语法
一条Update更新语句是不能更新多张表的,除非使用触发器隐含更新.而表的更新操作中,在很多情况下需要在表达式中引用要更新的表以外的数据.我们先来讨论根据其他表数据更新你要更新的表 一.MS S ...
- js实现深度优先遍历和广度优先遍历
深度优先遍历和广度优先遍历 什么是深度优先和广度优先 其实简单来说 深度优先就是自上而下的遍历搜索 广度优先则是逐层遍历, 如下图所示 1.深度优先 2.广度优先 两者的区别 对于算法来说 无非就是时 ...
- Kubernetes环境部署
简介 Kubernetes 是一个开源系统,用于容器化应用的自动部署.扩缩和管理.它将构成应用的容器按逻辑单位进行分组以便于管理和发现. 配置镜像源 Debian / Ubuntu apt-get ...