独立成分分析(ICA)的模拟实验(R语言)
本文永久链接: https://esl.hohoweiya.xyz/notes/ICA/index.html
本笔记是ESL14.7节图14.42的模拟过程。第一部分将以ProDenICA法为例试图介绍ICA的整个计算过程;第二部分将比较ProDenICA、FastICA以及KernelICA这种方法,试图重现图14.42。
ICA的模拟过程
生成数据
首先我们得有一组独立(ICA的前提条件)分布的数据\(S\)(未知),然后经过矩阵\(A_0\)混合之后得到实际的观测值\(X\),即
\]
也可以写成
\]
用鸡尾酒酒会的例子来说就是,来自不同个体的说话声经过麦克风混合之后得到我们实际接收到的信号。假设有两组独立同分布的数据,分布都为n(对应图14.42中的编号),每组数据个数均为\(N=1024\),混合矩阵为A0,用R代码描述这一过程如下
library(ProDenICA)
p = 2
dist = "n"
N = 1024
A0 = mixmat(p)
s = scale(cbind(rjordan(dist,N),rjordan(dist,N)))
x = s %*% A0
最终我们得到观测值x。
白化
在进行ICA时,也就是恢复\(X=S\mathbf A\)中的混合矩阵\(\mathbf A\),都会假设\(X\)已经白化得到\(\mathrm{Cov}(X)=\mathbf I\),而这个处理过程可以用SVD实现。对于中心化的\(X\),根据
\]
得到满足\(Cov(X^*)=\mathbf I\)的\(X^*\),则
\]
于是经过这个变换之后,混合矩阵变为
\]
则
\]
用R语言表示如下
x <- scale(x, TRUE, FALSE) # central
sx <- svd(x)
x <- sqrt(N) * sx$u # satisfy cov(x) = I
target <- solve(A0)
target <- diag(sx$d) %*% t(sx$v) %*% target/sqrt(N) # new mixing maxtrix
ProDenICA法
细节不再展开,直接利用ProDenICA中的包进行计算
W0 <- matrix(rnorm(2*2), 2, 2)
W0 <- ICAorthW(W0)
W1 <- ProDenICA(x, W0=W0,trace=TRUE,Gfunc=GPois)$W
得到\(A\)的估计值W1
计算Amari距离
amari(W1, target)
比较两种算法
这一部分试图重现Fig. 14.42。
N = 1024
genData <- function(dist, N = 1024, p = 2){
# original sources
s = scale(cbind(rjordan(dist, N), rjordan(dist, N)))
# mixing matrix
mix.mat = mixmat(2)
# original observation
x = s %*% mix.mat
# central x
x = scale(x, TRUE, FALSE)
# whiten x
xs = svd(x)
x = sqrt(N) * xs$u # new observations
mix.mat2 = diag(xs$d) %*% t(xs$v) %*% solve(mix.mat) / sqrt(N) # new mixing matrix
return(list(x = x, A = mix.mat2))
}
res = array(NA, c(2, 18, 30))
for (i in c(1:18)){
for (j in c(1:30)){
data = genData(letters[i])
x = data$x
A = data$A
W0 <- matrix(rnorm(2*2), 2, 2)
W0 <- ICAorthW(W0)
# ProDenICA
W1 <- ProDenICA(x, W0=W0,trace=FALSE,Gfunc=GPois, restarts = 5)$W
# FastICA
W2 <- ProDenICA(x, W0=W0,trace=FALSE,Gfunc=G1, restarts = 5)$W
res[1, i, j] = amari(W1, A)
res[2, i, j] = amari(W2, A)
}
}
res.mean = apply(res, c(1,2), mean)
#offset = apply(res, c(1,2), sd)
#offset = 0
#res.max = res.mean + offset/4
#res.min = res.mean - offset/4
res.max = apply(res, c(1,2), max)
res.min = apply(res, c(1,2), min)
# plot
plot(1:18, res.mean[1, ], xlab = "Distribution", ylab = "Amari Distance from True A", xaxt = 'n', type = "o", col = "orange", pch = 19, lwd = 2, ylim = c(0, 0.5))
axis(1, at = 1:18, labels = letters[1:18])
lines(1:18, res.mean[2, ], type = "o", col = 'blue', pch = 19, lwd=2)
legend("topright", c("ProDenICA", "FastICA"), lwd = 2, pch = 19, col = c("orange", "blue"))
#for(i in 1:18)
#{
# for (j in 1:2)
# {
# color = c("orange", "blue")
# lines(c(i, i), c(res.min[j, i], res.max[j, i]), col = color[j], pch = 3)
# lines(c(i-0.2, i+0.2), c(res.min[j, i], res.min[j, i]), col = color[j], pch = 3)
# lines(c(i-0.2, i+0.2), c(res.max[j, i], res.max[j, i]), col = color[j], pch = 3)
# }
#}
得到下图

与图14.42的右图中的FastICA和ProDenICA的图象一致。
试图绘制出图中的变化范围,但由于书中并未指出变换范围是什么,尝试了标准差及最大最小值,但效果不是很好,这是可以继续优化的一个方面。下图是用四分之一的标准差作为其波动范围得到的
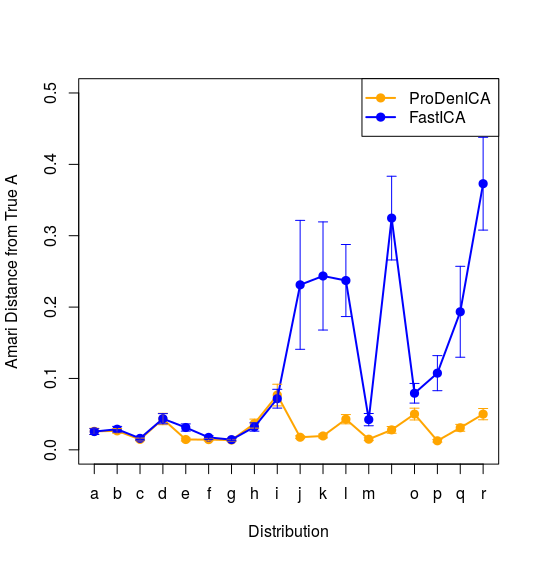
待完善
加入kernelICA
独立成分分析(ICA)的模拟实验(R语言)的更多相关文章
- 机器学习 —— 基础整理(四)特征提取之线性方法:主成分分析PCA、独立成分分析ICA、线性判别分析LDA
本文简单整理了以下内容: (一)维数灾难 (二)特征提取--线性方法 1. 主成分分析PCA 2. 独立成分分析ICA 3. 线性判别分析LDA (一)维数灾难(Curse of dimensiona ...
- 独立成分分析 ICA 原理及公式推导 示例
独立成分分析(Independent component analysis) 前言 独立成分分析ICA是一个在多领域被应用的基础算法.ICA是一个不定问题,没有确定解,所以存在各种不同先验假定下的求解 ...
- ICA (独立成分分析)
介绍 独立成分分析(ICA,Independent Component Correlation Algorithm)简介 X=AS X为n维观测信号矢量,S为独立的m(m<=n)维未知源信号矢量 ...
- Topographic ICA as a Model of Natural Image Statistics(作为自然图像统计模型的拓扑独立成分分析)
其实topographic independent component analysis 早在1999年由ICA的发明人等人就提出了,所以不算是个新技术,ICA是在1982年首先在一个神经生理学的背景 ...
- PCA主成分分析 ICA独立成分分析 LDA线性判别分析 SVD性质
机器学习(8) -- 降维 核心思想:将数据沿方差最大方向投影,数据更易于区分 简而言之:PCA算法其表现形式是降维,同时也是一种特征融合算法. 对于正交属性空间(对2维空间即为直角坐标系)中的样本点 ...
- 斯坦福ML公开课笔记15—隐含语义索引、神秘值分解、独立成分分析
斯坦福ML公开课笔记15 我们在上一篇笔记中讲到了PCA(主成分分析). PCA是一种直接的降维方法.通过求解特征值与特征向量,并选取特征值较大的一些特征向量来达到降维的效果. 本文继续PCA的话题, ...
- 独立成分分析(Independent Component Analysis)
ICA是一种用于在统计数据中寻找隐藏的因素或者成分的方法.ICA是一种广泛用于盲缘分离的(BBS)方法,用于揭示随机变量或者信号中隐藏的信息.ICA被用于从混合信号中提取独立的信号信息.ICA在20世 ...
- Independent Components Analysis:独立成分分析
一.引言 ICA主要用于解决盲源分离问题.需要假设源信号之间是统计独立的.而在实际问题中,独立性假设基本是合理的. 二.随机变量独立性的概念 对于任意两个随机变量X和Y,如果从Y中得不到任何关于X的信 ...
- ICA(独立成分分析)笔记
ICA又称盲源分离(Blind source separation, BSS) 它假设观察到的随机信号x服从模型,其中s为未知源信号,其分量相互独立,A为一未知混合矩阵. ICA的目的是通过且仅通过观 ...
随机推荐
- Spring之AOP二
在Spring之AOP一中使用动态代理将日志打印功能注入到目标对象中,其实这就是AOP实现的原理,不过上面只是Java的实现方式.AOP不管什么语言它的几个主要概念还是有必要了解一下的. 一.AOP概 ...
- MySQL在字段中使用select子查询
前几天看别人的代码中看到在字段中使用select子查询的方法,第一次见这种写法,然后研究了一下,记录下来 大概的形式是这样的: select a .*,(select b.another_field ...
- Docker(四):Docker基本网络配置
1.Libnetwork Libnetwork提出了新的容器网络模型简称为CNM,定义了标准的API用于为容器配置网络. CNM三个重要概念: 沙盒:一个隔离的网络运行环境,保存了容器网络栈的配置,包 ...
- Raspberry Pi中可用的Go IDE:liteide
p { margin-bottom: 0.25cm; line-height: 120% } a:link { } Raspberry Pi中可用的Go IDE:liteide p { margin- ...
- Codebase Refactoring (with help from Go)
Codebase Refactoring (with help from Go) 代码库重构(借助于Go) 1.摘要 Go应该添加为类型创建替代等效名称的能力,以便在代码库重构期间渐进代码修复.本文解 ...
- 不解释,分享这个base.css
@charset "utf-8"; /*! * @名称:base.css * @功能:1.重设浏览器默认样式 * 2.设置通用原子类 */ /* 防止用户自定义背景颜色对网页的影响 ...
- 第一本的java 的小总结
1.Java常见的注释有哪些,语法是怎样的? 1)单行注释用//表示,编译器看到//会忽略该行//后的所文本 2)多行注释/* */表示,编译器看到/*时会搜索接下来的*/,忽略掉/* */之间的文 ...
- Git添加远程库和从远程库中获取
一. Git添加远程库 1. 在本地新建一个文件夹,在该文件夹使用Git工具,运行$ git init,将该文件夹变为本地Git仓库,同时会生成一个隐藏的.git文件夹. 2. 在该文件夹中用Note ...
- ES6 modules 详解
概述 历史上,JavaScript 一直没有模块(module)体系,无法将一个大程序拆分成互相依赖的小文件,再用简单的方法拼装起来.其他语言都有这项功能,比如 Ruby 的require.Pytho ...
- [js高手之路]html5 canvas动画教程 - 跟着鼠标移动消失的一堆炫彩小球
综合利用前面所学,实现一个绚丽的小球动画,这个实例用到的知识点,在我的博客全部都有,可以去这里查看所有的canvas教程 <head> <meta charset='utf-8' / ...