MySQL分页优化中的“INNER JOIN方式优化分页算法”到底在什么情况下会生效?
本文出处:http://www.cnblogs.com/wy123/p/7003157.html
最近无意间看到一个MySQL分页优化的测试案例,并没有非常具体地说明测试场景的情况下,给出了一种经典的方案,
因为现实中很多情况都不是固定不变的,能总结出来通用性的做法或者说是规律,是要考虑非常多的场景的,
同时,面对能够达到优化的方式要追究其原因,同样的做法,换了个场景,达不到优化效果的,还要追究其原因。
个人对此场景在不用情况表示怀疑,然后自己测试了一把,果然发现一些问题,同时也证实了一些预期的想法。
本文就MySQL分页优化,从最最简单的情况出发,来做一个简单的分析。
另:本文测试环境是最最低配置的云服务器,相对来说服务器硬件环境有限,不过对于不同的语句(写法)应该是“平等的”
20170916补充:
想想用脚趾头就能明白,
1,如果分页排序字段是聚集索引,完全没必要对索引分页再查询数据,因为索引就是数据本身。
2,如果是非聚集索引,先对索引分页,然后再利用索引去查询数据,先分页索引确实可以减少扫描的范围
3,如果经常按照2中的方式查询,也就是按照非聚集索引排序查询,那么为什么不在该列上建立聚集索引呢。
MySQL经典的分页“优化”做法
MySQL分页优化中,有一种经典的问题,在查询越“靠后”的数据越慢(取决于表上的索引类型,对于B树结构的索引,SQL Server中也一样)
select * from t order by id limit m,n。
也即随着M的增大,查询同样多的数据,会越来越慢
面对这一问题,于是就产生了一种经典的做法,类似于(或者变种)如下的写法
就是先把分页范围内的id单独找出来,然后再跟基表做关联,最后查询出来所需要的数据
select * from t
inner join (select id from t order by id limit m,n)t1 on t1.id = t.id
这种做法是不是总是生效的,或者说是在什么情况下后者才能到达到优化的目的?有没有做了改写之后无效甚至变慢的情况?
与此同时,绝大多数查询都是有筛选条件的,
如果有筛选条件的情况,
sql语句就变成了select * from t where *** order by id limit m,n
如果如法炮制,改写成类似
select * from t
inner join (select id from t where *** order by id limit m,n )t1 on t1.id = t.id
在这种情况下,改写后的sql语句还能达到优化的目的吗?
测试环境搭建
测试数据比较简单,通过存储过程循环写入测试数据,测试表的InnoDB引擎表。
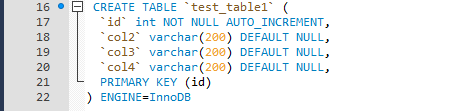
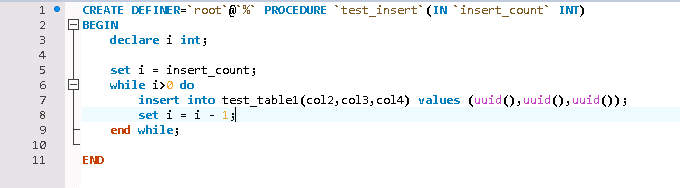
这里要注意的是日志写入模式一定要修改成innodb_flush_log_at_trx_commit = 2,否则默认情况下,500w数据,估计一天都写不完,这个与日志写入模式有关,就不多说了,

分页查询优化的缘由
首先还是先看一下这个经典的问题,分页的时候,越“靠后”查询相应越慢的情况
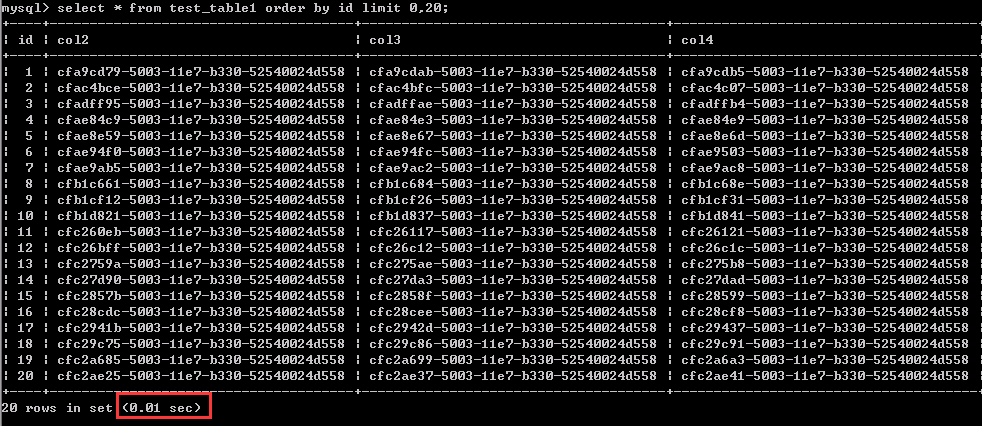
测试一:查询第1-20行的数据,0.01秒
同样是查询20行数据,查询相对“靠后”的数据,比如这里的从4900001-4900020行数据的情况,用时1.97秒。
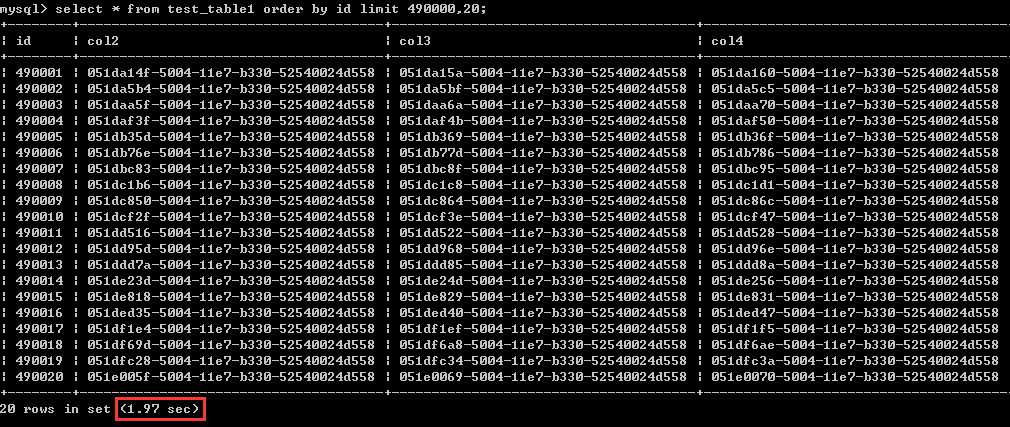
从中可以看到,查询条件不变的情况下,越往后查询,查询效率越低,可以简单理解成:同样搜索20行数据,越是靠后的数据,查询代价越大。
至于为什么后一种效率较低,后面会慢慢分析。
测试环境是centos 7 ,mysql 5.7,测试表的数据是500W
重现经典分页“优化”,当没有筛选条件,排序列为聚集索引的时候,并不会有所改善
这里来对比以下两种写法在聚集索引列作为排序条件时候的性能
select * from t order by id limit m,n。
select * from t
inner join (select id from t order by id limit m,n)t1 on t1.id = t.id
第一种写法:
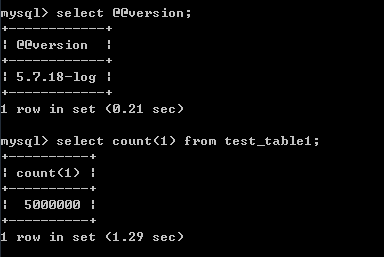
select * from test_table1 order by id asc limit 4900000,20;测试结果见截图,执行时间为8.31秒
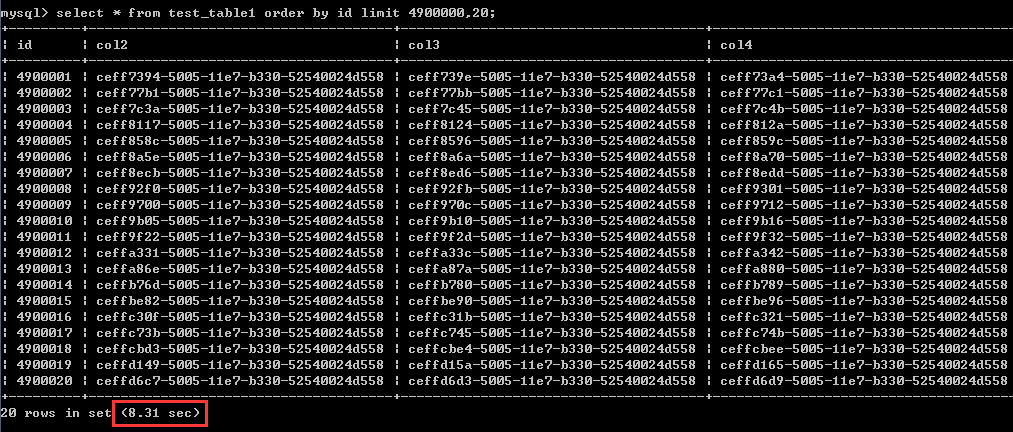
第二种改写后的写法:
select t1.* from test_table1 t1
inner join (select id from test_table1 order by id limit 4900000,20)t2 on t1.id = t2.id;执行时间为8.43秒

这里很清楚,通过经典的改写方法改写之后,性能能毫无提升,甚至还有一点点变慢了,
实际测试上表现为两者在性能上并没有明显的线性差异,这两者楼主是做了多次测试的。
我个人看到类似结论非要测一下不可的,这个东西不能靠蒙,或者靠运气什么的,能提高效率是为什么,不能提高又是为什么。
那么为什么改写之后的写法没有像传说中的那种提升性能?
是什么导致当前这个改写没有到达提升性能的目的?
后者能够提升性能的原理是什么?
首先看一下测试表的表结构,排序列上是有索引,这一点是没有问题的,关键是这个排序列上的索引是主键(聚集索引)。
为什么排序列上是聚集索引的时候,相对“优化”改写之后的sql并不能达到“优化”的目的?
在排序列为聚集索引列的情况下,两者都是顺序扫描表来实现查询符合条件的数据的
后者虽然是先驱动一个子查询,然后再用子查询的结果驱动主表,
但是子查询并没有改变“顺序扫描表来实现查询符合条件的数据的”做法,当前情况下,甚至改写后的做法显得画蛇添足
参考如下两者执行计划,第一个截图的执行计划的一行,与改写后的sql的执行计划的第三行(id =2 的那一行),基本上一样。


当没有筛选条件,排序列为聚集索引时候的分页查询,所谓的分页查询优化只不过是画蛇添足
目前来看,查询上述数据,两种方式都非常慢,那如果要查询上述的数据,该如何做?
还是要看为什么慢,首先要理解B数的平衡性结构,在我自己粗略的理解来看,如下图,
当查询的数据“靠后”的时候,实际上是偏离在B树索引的一个方向,如下两个截图所示的目标数据
其实平衡树上的数据,没有所谓的“靠前”与“靠后”,“靠前”与“靠后”都是相对于对方来说的,或者说是从扫描的方向上来看的
从一个方向上看“靠后的”数据,从一个方向看就是“靠前的”,前后不是绝对的。
如下两个截图是B树索引结构的粗略表现形式,假如目标数据的位置固定的情况下,所谓的“靠后”是相对与从左向右来说的;
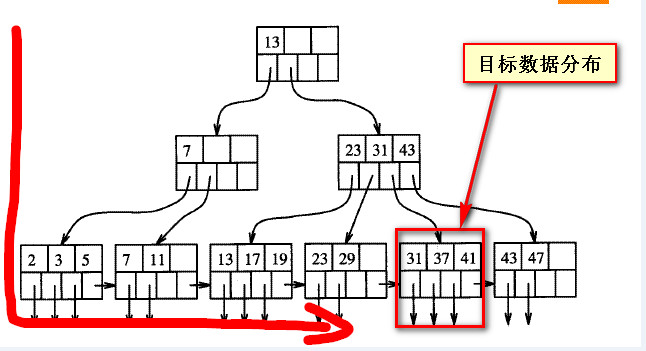
如果从右向左看,之前所谓靠后的数据实际上是“靠前”的。
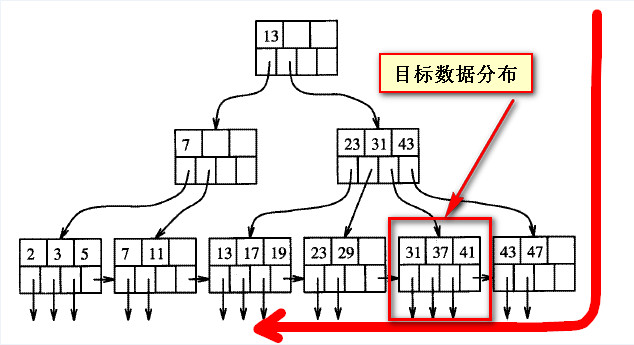
只要数据是靠前的,要高效低找到这部分数据,还是可以的。mysql中应该也有类似于sqlserver中的正向(forwarded)和反向扫描(backward)的做法。
如果对于靠后的数据,采用反向扫描,应该就可以很快找到这个部分数据,然后对找到的数据在再次排序(asc),结果应该是一样的,
首先来看效果:结果跟上面的查询一模一样,这里仅耗时0.07秒,之前的两种写法均超过了8秒,效率有上百倍的差距。
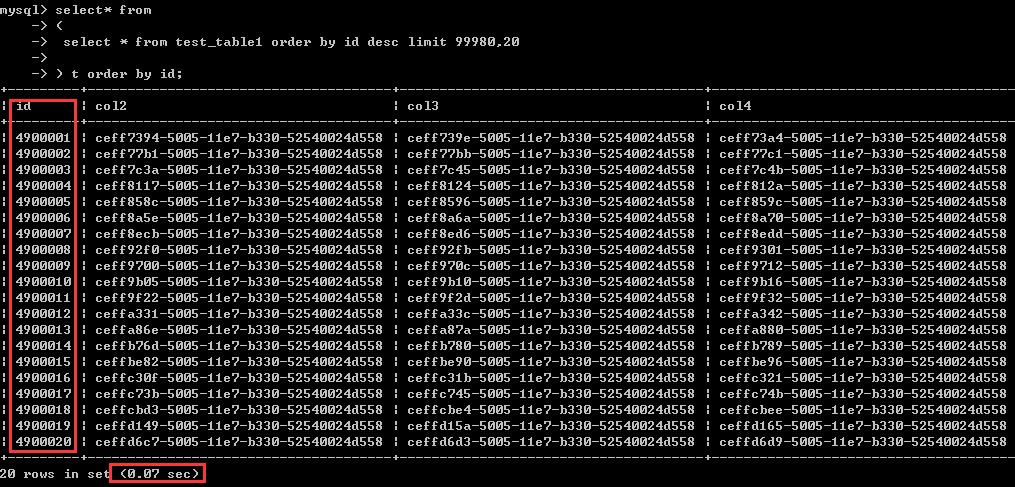
至于这个是为什么,我想根据上面的阐述,自己应该能够体会的到,这里附上这个sql。
如果经常查询所谓的靠后的数据,比如说Id较大的数据,或者说是时间维度上较新的数据,可以采用倒叙扫描索引的方式来实现高效分页查询
(这里请计算好数据所在的分页,同样的数据,正序和倒序其起始“页码”是不同的)
select* from
(
select * from test_table1 order by id desc limit 99980,20 ) t order by id;
当没有筛选条件,排序列为非聚集索引的时候,会有所改善
这里对测试表test_table1做出如下改变
1,增加一个id_2列,
2,该字段上创建一个唯一索引,
3,该字段用对应的主键Id填充
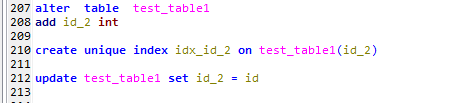
上面的测试是按照主键索引(聚集索引)来排序的,现在来按照非聚集索引排序,也即新增的这个列id_2来排序,测试一开始提到的两种分页方法。
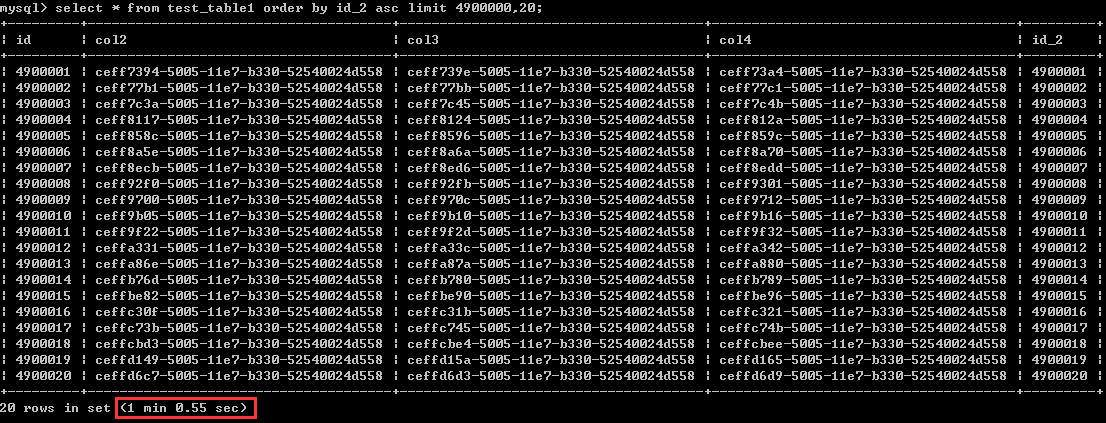
首先来看第一种写法
select * from test_table1 order by id_2 asc limit 4900000,20;执行时间为1分钟多一点,暂且认其为60秒
第二种写法
select t1.* from test_table1 t1
inner join (select id from test_table1 order by id_2 limit 4900000,20)t2 on t1.id = t2.id;执行时间1.67秒
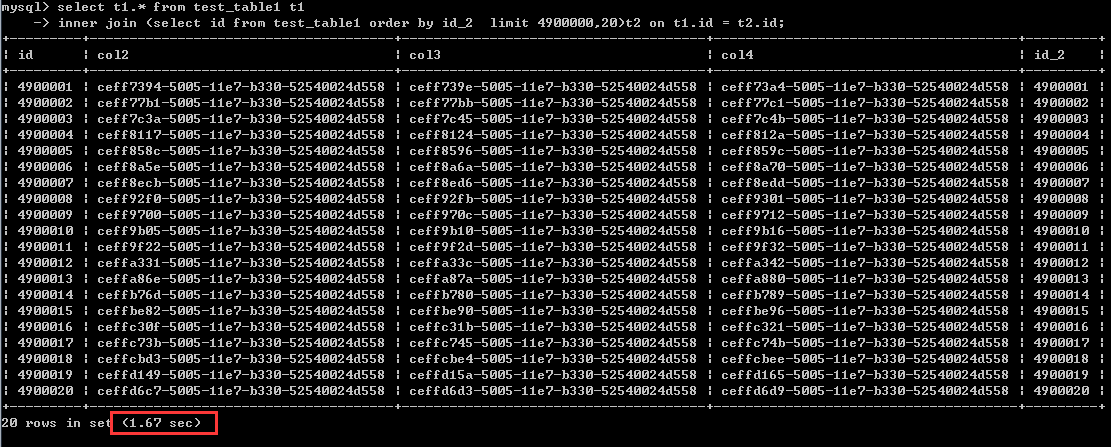
从这种情况来看,也就是说排序列为非聚集索引列的时候,后一种写法确实能大幅度地提升效率。差不多有40倍的提升。
那么原因在何呢?
首先来看第一种写法的执行计划,可以简单理解为这个sql的执行时做全表扫描之后,然后重新按照id_2排序,最后取最前20条数据。
首先全表扫描就是一个非常耗时的过程,排序也是一个非常大的代价,因此表现为性能非常的低下。

再来看后者的执行计划,他是首先子子查询中,按照id_2上的索引顺序扫描,然后用符合条件的主键Id去表中查询数据
这样的话,避免了查询出来大量的数据然后重新排序(Using filesort)
如果了解sqlserver执行计划的情况下,后者与前者相比,应该还有避免了频繁的回表(sqlserver中叫做key lookup或者书签查找的过程
可以认为是子查询驱动外层表查询符合条件的20条的数据的过程是一个批量的,一次性的。

其实,只有在当前情况下,也就是说排序列为非聚集索引列的时候,改写后的sql才能提升分页查询的效率。
即便如此,此方式“优化”过的分页语句,还是与如下写法的分页效率有比较大的差别的
上面也看到了,返回同样的数据,如下的查询是0.07秒,比这里的1.67秒还是高2个数量级的
select* from
(
select * from test_table1 order by id desc limit 99980,20 ) t order by id;
另外一个,想提到的问题就是,如果经常性分页查询,还要按照某种顺序,那么为什么不在这个列上建立一个聚集索引。
比如语句自增Id的,或者时间+其他字段确保唯一性的,mysql会在主键上自动创建聚集索引。
然后有了聚集索引,“靠前”与“靠后”仅仅是一个相对的逻辑上的概念了,如果多数时候是想得到“靠后”或者较新的数据,就可以采用上述写法,
当存在筛选条件的情况下,分页查询的优化
这一部分想了想,情况太复杂了,很难概括出来一种非常具有代表性的案例,因此就不过多地做测试了。
select * from t where *** order by id limit m,n
1,比如刷选条件本身就很高效,一过滤出来仅剩下很少一部分数据,那么改不改写sql意义也不大,因为筛选条件本身就可以做到很高效的筛选
2,比如刷选条件本身作用不大(过滤后数据量依然巨大),这种情况其实又回到了不存在筛选条件的情况,还有取决于如何排序,正序还是倒序等等
3,比如筛选条件本身作用不大(过滤后数据量依然巨大),要考虑的一个很实际的问题是数据分布,
数据的分布也会影响的sql的执行效率(sqlserver中的经历,mysql应该差别不大)
4,本身查询比较复杂的情况下,很难说用某种方式就可以达到高效的目的
情况越复杂,越是难以总结出来一种通用性的规律或者说是方法,一切都要以具体情况来看待,很难下一个定论。
这里对于查询加上筛选条件的情况,就不做一一分析了,不过可以肯定的是,脱离了实际场景,肯定没有一个固化的方案。
另外,对于查询当前页数据时候,利用上一页查询的最大值做筛选条件,也可以很快滴找到当前页的数据,这样当然没有问题,但这属于另外一个做法,不在本文讨论之列。
补充一个在SQL Server下的测试结果,如果是非聚集索引,如果查询排序的列是一个单列索引,分页方式并不能提升效率。
create table TestPaging
(
id int identity(1,1),
name varchar(50),
other varchar(100)
)
declare @i int = 0
while @i<100000
begin
insert into TestPaging values (NEWID(),NEWID())
set @i = @i + 1
end create index idx on TestPaging(name)
从执行计划可以看出,查询Id的子查询是一个全表扫描
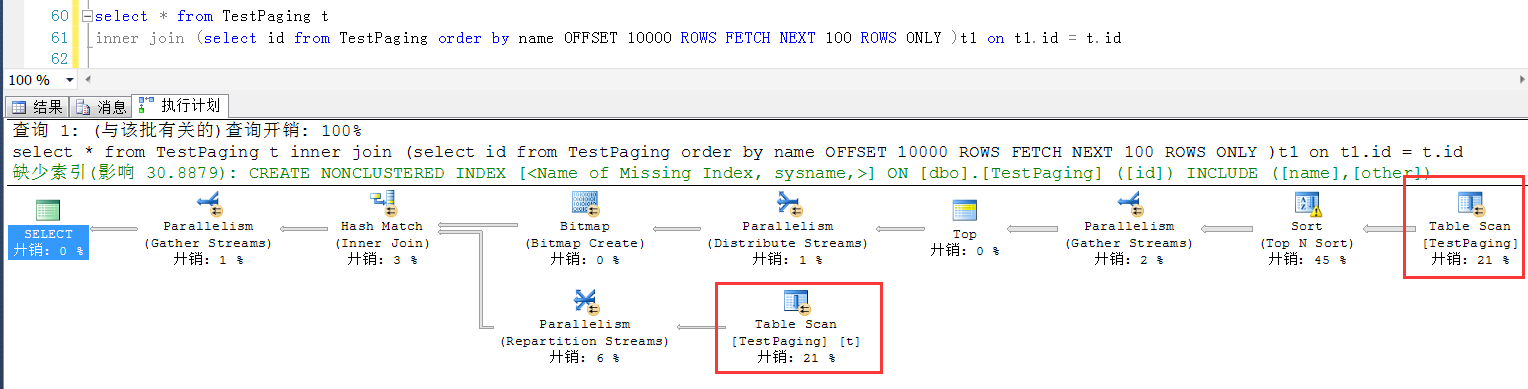
除非是一个符合索引,在表中数据比较大的情况下,才能提高效率(子查询进行索引扫描的代价要小于全表扫描的代价),不过话说回来,如果经常按照某个列排序分页,为什么该列上不建立成聚集索引呢?

总结
分页查询,越靠后越慢的情况,实则对于B树索引来说,靠前与靠后是一个逻辑上相对的概念,性能上的差异,是基于B树索引结构以及扫描方式有关的.
如果加上筛选条件,情况将变得更加复杂,这个问题在SQL Server中的原理也是一样的,本来也在SQL Server中做了测试的,这里就不重复了。
当前这种情况,排序列不一定,查询条件不一定,数据分布不一定,就很难用一种特定的方法来实现“优化”,弄不好还起到画蛇添足的副作用。
因此在做分页优化的时候,一定要根据具体的场景来做分析,方法也不一定只有一种,脱离实际场景的结论,都是扯犊子。
唯有弄清楚这个问题的来龙去脉,才能游刃有余。
因此个人对于数据“优化”的结论,一定是具体问题具体分析,是很忌讳总结出来一套规则(规则1,2,3,4,5)给人“套用”,鉴于本人也很菜,就更不敢总结出来一些教条了。
MySQL分页优化中的“INNER JOIN方式优化分页算法”到底在什么情况下会生效?的更多相关文章
- InnoDB缓冲池预加载在MySQL 5.7中的正确打开方式
InnoDB缓冲池预加载在MySQL 5.7中的正确打开方式 https://mp.weixin.qq.com/s/HGa_90XvC22anabiBF8AbQ 在这篇文章里,我将讨论在MySQL 5 ...
- a标签在编辑器中可以整体删除并且a标签为不可编辑的情况下 标签依然存在(棒棒哒)
a标签在编辑器中可以整体删除并且a标签为不可编辑的情况下 标签依然存在 因为给a标签的后面 添加了一个空元素,如<i></i>(棒棒哒)<div contentEdita ...
- 详解分页组件中查count总记录优化
1 背景 研究mybatis-plus(以下简称MBP),使用其分页功能时.发现了一个JsqlParserCountOptimize的分页优化处理类,官方对其未做详细介绍,网上也未找到分析该类逻辑的只 ...
- NAND Flash中常用的纠错方式(ECC算法)
Hanming,RS,BCH —— NAND Flash中常用的纠错方式 因为闪存中会有出错的可能,如果没有使用ECC模块,读出的数据和写入的数据会有不匹配的可能,也许一个文件中只有一两个bit不匹配 ...
- (转)在.NET程序运行过程中,什么是堆,什么是栈?什么情况下会在堆(栈)上分配数据?它们有性能上的区别吗?“结构”对象可能分配在堆上吗?什么情况下会发生,有什么需要注意的吗?
转自:http://www.cnblogs.com/xiaoyao2011/archive/2011/09/09/2172427.html 在.NET程序运行过程中,什么是堆,什么是栈? 堆也就是托管 ...
- Java中只有按值传递,没有按引用传递!(两种参数情况下都是值传递)
今天,我在一本面试书上看到了关于java的一个参数传递的问题: 写道 java中对象作为参数传递给一个方法,到底是值传递,还是引用传递? 我毫无疑问的回答:“引用传递!”,并且还觉得自己对java的这 ...
- java项目中VO和DTO以及Entity,各自是在什么情况下应用
1.entity里的每一个字段,与数据库相对应, 2.dto里的每一个字段,是和你前台页面相对应, 3.VO,这是用来转换从entity到dto,或者从dto到entity的中间的东西. 举个例子 ...
- java项目中VO和DTO以及Entity,各自是在什么情况下应用的
j2ee中,经常提到几种对象(object),理解他们的含义有助于我们更好的理解面向对象的设计思维. POJO(plain old java object):普通的java对象,有别于特殊的j ...
- java项目中VO、DTO以及Entity,各自是在什么情况下应用的
按照标准来说: entity里的每一个字段,与数据库相对应 vo里的每一个字段,是和你前台页面相对应 dto,这是用来转换从entity到dto,或者从dto到entity的中间的东西 举个例子: h ...
随机推荐
- Maven的pom.xml配置文件详解
Maven简述 Maven项目对象模型(POM),可以通过一小段描述信息来管理项目的构建,报告和文档的软件项目管理工具. Maven 除了以程序构建能力为特色之外,还提供高级项目管理工具.由于 Mav ...
- 微信小程序之购物车功能
前言 以往的购物车,基本都是通过大量的 DOM 操作来实现.微信小程序其实跟 vue.js 的用法非常像,接下来就看看小程序可以怎样实现购物车功能. 需求 先来弄清楚购物车的需求. 单选.全选和取消, ...
- Nuget常用命令操作
Nuget是一个.NET平台下的开源的项目,它是Visual Studio的扩展.在使用Visual Studio开发基于.NET Framework的应用时,Nuget能把在项目中添加.移除和更新引 ...
- JAVA 基础之Integer
jdk1.5后增加了自动拆箱和自动装箱特性.java的八种 byte,short,int,long,float,double,char,boolean基本类型和各自对应的包装类型的相互转化. 装箱指的 ...
- [大数据]-Elasticsearch5.3.1 IK分词,同义词/联想搜索设置
--题外话:最近发现了一些问题,一些高搜索量的东西相当一部分没有价值.发现大部分是一些问题的错误日志.而我是个比较爱贴图的.搜索引擎的检索会将我们的博文文本分词.所以图片内容一般是检索不到的,也就是说 ...
- jqPaginator 项目中做分页的应用技巧
最近做后台管理系统,分页用到的不少,项目中其实已经有分页功能的组件但是不够高度自定义,于是就找到了 jqPaginator 高度自定义的Html结构 初始化引用如下: $("#paginat ...
- GD库知识点
GD库:PHP的一个扩展库,主要用于绘制动态图,根据数据动态响应的图片 如统计图 验证码 其他的用途如:处理已有图像 图片的缩放 裁剪 图片水印 文字水印 1.安装GD库 2.画图步骤:创建背景图像( ...
- java关键字transient与volatile小结
本文转自:http://heaven-arch.iteye.com/blog/1160693 transient和volatile两个关键字一个用于对象序列化,一个用于线程同步,都是Java中比较高阶 ...
- Java UDP Socket
本文转载地址: Java学习路上的收获:http://blog.csdn.net/qinpeng100423/article/details/8980423 一. UDP协议定义 U ...
- Linux parent process and child process when 'sudo'
如果在一般用户下如user,执行sudo命令,会产生两个进程. ps -ef | grep Container root 4305 643 0 16:37 pts/39 00:00:00 sudo . ...