mysql-高性能索引策略
原文转自:http://www.cnblogs.com/happyflyingpig/p/7655762.html
独立索引:
独立索引是指索引列不能是表达式的一部分,也不能是函数的参数
例1:
SELECT actor_id FROM actor WHERE actor_id+1=5 --这种写法,就算在actor_id上建立了索引,也不起效
例2:
SELECT .... WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(date_col) <= 10 --这也是一种错误的写法
多列索引(联合索引)&选择合适的索引列顺序:
多列索引(Multiple-Column Indexes)也称为复合索引(composite index),也即同时对多个列建立索引。
什么时候用多列索引?
- 当出现服务器对多个索引做相交操作时(通常有多个AND条件),通常意味着需要一个包含所有相关列的多列索引,而不是多个独立的单列索引。
- 当服务器需要对多个索引做联合操作时(通常有多个OR条件),通常需要耗费大量CPU和内存资源在算法的缓存、排序和合并操作上。特别是当其中有些索引的选择性不高,需要合并扫描返回大量数据的时候。
多列索引的生效规则:
比如(a,b,c),abc都是拍好序的,在任意一段a的下面b都是排好序的,任何一段b下面c都是拍好序的。多列索引的生效原则是从前往后依次使用生效,如果中间某个索引没有使用,那么断点前面的索引部分起作用,断点后面的索引没有起作用;
还需注意:(a,b,c)多列索引和 (a,c,b)是不一样的,看上面的图也看得出来关系顺序是不一样的;
分析几个实际例子来加强理解

(0)select * from mytable where a=3 and b=5 and c=4; --abc三个索引都在where条件里面用到了,而且都发挥了作用
(1)select * from mytable where c=4 and b=6 and a=3; --这条语句列出来只想说明 mysql没有那么笨,where里面的条件顺序在查询之前会被mysql自动优化,效果跟上一句一样
(2)select * from mytable where a=3 and c=7; --a用到索引,b没有用,所以c是没有用到索引效果的
(3)select * from mytable where a=3 and b>7 and c=3; --a用到了,b也用到了,c没有用到,这个地方b是范围值,也算断点,只不过自身用到了索引
(4)select * from mytable where b=3 and c=4; --因为a索引没有使用,所以这里 bc都没有用上索引效果
(5)select * from mytable where a>4 and b=7 and c=9; --a用到了 b没有使用,c没有使用
(6)select * from mytable where a=3 order by b; --a用到了索引,b在结果排序中也用到了索引的效果,前面说了,a下面任意一段的b是排好序的
(7)select * from mytable where a=3 order by c; --a用到了索引,但是这个地方c没有发挥排序效果,因为中间断点了,使用 explain 可以看到 filesort
(8)select * from mytable where b=3 order by a; --b没有用到索引,排序中a也没有发挥索引效果
对于如何选择索引的列顺序有一个经验法则:将选择性最高的列放到索引最前列。(参考①)
当不需要考虑排序和分组时,将选择性最高的列放到前面通常是很好的。这时候索引的作用只是用于优化WHERE条件的查找
前缀索引和索引的选择性:
前缀索引能有效减小索引文件的大小,提高索引的速度。但是前缀索引也有它的坏处:
1.不能再OORDER BY 或 GROUP BY 中使用前缀索引;
2.也不能把他们用作覆盖索引(Covering index)。
建立前缀索引的语法:
ALTER TABLE table_name ADD KEY(column_name(prefix_length));
示例:
ALTER TABLE city ADD KEY(cityname(7));
什么叫做索引的选择性呢?①
所谓索引的选择性(Selectivity),是指不重复索引值(也叫作基数,Cardinality)与表记录数(#T)的比值
Selectivity = Cardinality / #T
显然选择性的取值范围为(0,1],选择性越高的索引值价值越大
SELECT count(DISTINCT(title))/count(*) AS Selectivity FROM employees.titles;
- +-------------+
- | Selectivity |
- +-------------+
- | 0.0379 |
- +-------------+
比如employees表只有一个索引<emp_no>,那么如果我们想按名字搜索一个人,就只能全表扫描了:
EXPLAIN SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido';
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
| 1 | SIMPLE | employees | ALL | NULL | NULL | NULL | NULL | 300024 | Using where |
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
这样全表扫描效率很低,所以我们考虑到把名字建立索引,有两种选择,建<first_name>或<first_name,last_name>,看下两个索引的选择性:
SELECT count(DISTINCT(first_name))/count(*) AS Selectivity FROM employees;
+-------------+
| Selectivity |
+-------------+
| 0.0042 |
+-------------+
SELECT count(DISTINCT(concat(first_name, last_name)))/count(*) AS Selectivity FROM employees;
+-------------+
| Selectivity |
+-------------+
| 0.9313 |
+-------------+
从结果看显然<first_name>选择性太低,<first_name,last_name>选择性好。但是first_name和last_name加起来长度为30,有没有兼顾长度和选择性的办法?可以考虑用first_name和last_name的前几个字符建立索引,例如<first_name, left(last_name, 3)>,看看其选择性:
SELECT count(DISTINCT(concat(first_name, left(last_name, 3))))/count(*) AS Selectivity FROM employees;
+-------------+
| Selectivity |
+-------------+
| 0.7879 |
+-------------+
选择性还不错,但离0.9313还是有点距离,那么把last_name前缀加到4:
SELECT count(DISTINCT(concat(first_name, left(last_name, 4))))/count(*) AS Selectivity FROM employees;
+-------------+
| Selectivity |
+-------------+
| 0.9007 |
+-------------+
这时选择性已经很理想了,而这个索引的长度只有18,比<first_name, last_name>短了接近一半,我们把这个前缀索引 建上:
ALTER TABLE employees
ADD INDEX `first_name_last_name4` (first_name, last_name(4));
此时再执行一遍按名字查询,比较分析一下与建索引前的结果:
SHOW PROFILES;
+----------+------------+---------------------------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+---------------------------------------------------------------------------------+
| 87 | 0.11941700 | SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido' |
| 90 | 0.00092400 | SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido' |
+----------+------------+---------------------------------------------------------------------------------+
性能的提升是显著的,查询速度提高了120多倍。
聚簇索引
覆盖索引
冗余索引和覆盖索引
未使用的索引
应该删除未被使用的索引。有两个工具可以帮助定位未使用的索引。
1.在Percona Server或者MariaDB中先打开userstates服务器变量(默认是关闭的),然后让服务器正常运行一段时间,再通过查询INFORMATION_SCHEMA.INDEX_STATISTICS就能查到每个索引的使用频率。
2.在Percona Toolkit中的pt-index-usage,该工具可以读取查询日志,并对日志中的每条查询进行EXPLAIN操作,然后打印出关于索引和查询的报告
索引和锁
InnoDB只有在访问行的时候才会对其枷锁,而索引能够减少InnoDB访问的行数,从而减少锁的数量
InnoDB在二级索引上使用共享(读)锁,但访问主键索引需要排他(写)锁。这消除了覆盖索引的可能性,并且使得SELECT FOR UPDATE比LOCK IN SHARE MODE 或非锁定查询要慢很多
InnoDB的主键选择与插入优化
在使用InnoDB存储引擎时,如果没有特别的需要,请永远使用一个与业务无关的自增字段作为主键。为什么呢?
因为InnoDB使用聚集索引,数据记录本身被存于主索引(一颗B+Tree)的叶子节点上。这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)。
如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。如下图所示:
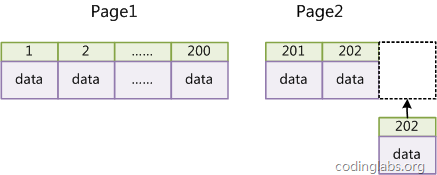
这样就会形成一个紧凑的索引结构,近似顺序填满。由于每次插入时也不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上。
如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置:
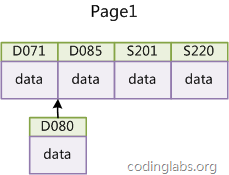
此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
因此,只要可以,请尽量在InnoDB上采用自增字段做主键。
参考文献:
[1] Baron Schwartz等 著,宁海元等 译 ;《高性能MySQL》(第3版); 电子工业出版社 ,2013
[2] 张洋blog, http://blog.codinglabs.org/articles/theory-of-mysql-index.html
[3]匿名blog, http://www.cnblogs.com/codeAB/p/6387148.html
mysql-高性能索引策略的更多相关文章
- mysql高性能索引策略
转载说明:http://www.nyankosama.com/2014/12/19/high-performance-index/ 1. 引言 随着互联网时代地到来,各种各样的基于互联网的应用和服务进 ...
- 高性能mysql——高性能索引策略
<高性能MySQL>读书笔记 一. 索引的优点 1. 索引可以让服务器快速定位到表的指定位置,大大减少了服务器需要扫描的数量: 2. 最常见的B-Tree索引按照顺序存储数据,可以用来做o ...
- MySQL建立高性能索引策略
索引永远是最好的查询解决方案嘛? 索引并不总是最好的工具.总的来说,只有当索引帮助存储引擎快速查找到记录带来的好处大于其带来的额外工作(比如插入操作后索引的维护)时,索引才是高效的. 对于非常小的表: ...
- MySQL索引背后的之使用策略及优化(高性能索引策略)
为了讨论索引策略,需要一个数据量不算小的数据库作为示例.本文选用MySQL官方文档中提供的示例数据库之一:employees.这个数据库关系复杂度适中,且数据量较大.下图是这个数据库的E-R关系图(引 ...
- mysql高性能索引
独立索引: 独立索引是指索引列不能是表达式的一部分,也不能是函数的参数 例1: SELECT actor_id FROM actor WHERE actor_id+1=5 --这种写法,就算在acto ...
- MySQL全面瓦解24:构建高性能索引(策略篇)
学习如果构建高性能的索引之前,我们先来了解下之前的知识,以下两篇是基础原理,了解之后,对面后续索引构建的原则和优化方法会有更清晰的理解: MySQL全面瓦解22:索引的介绍和原理分析 MySQL全面瓦 ...
- MySQL创建高性能索引
参考<高性能MySQL>第3版 1 索引基础 1.1 索引作用 在MySQL中,查找数据时先在索引中找到对应的值,然后根据匹配的索引记录找到对应的数据行,假如要运行下面查询语句: 如果在u ...
- MySQL(3)-索引
一.索引类型 在MySQL中,存储引擎使用索引,首先在索引中找到对应值,然后根据匹配的索引记录中找到对应的行. 无论是多么复杂的ORM工具,在精妙和复杂的索引面前都是"浮云".这里 ...
- [MySQL-笔记]创建高性能索引
索引,MySQL中也叫“键”,是存储引擎中用于快速找到记录的一种数据结构,具体的工作方式就像书本中的索引一样,但是具体的实现方式会有差别. 一.索引分类 B-Tree索引: 优点: MyISAM中,索 ...
- 五、MYSQL的索引
对于建立的索引(姓,名字,data) 5.1.索引对一下的查询类型有效 1.全值匹配:能查找姓+名为ALLEN.出生日期为1990-11-05的人: 2.最左前缀匹配:可以查找姓为ALLEN的人:即只 ...
随机推荐
- 微信小程序跳一跳辅助程序(手动版)
最近,微信官方推出了demo小程序游戏<跳一跳>,这个游戏操作简单,容易上手,却又不容易获得高分,受到很多人的喜爱(emm...这游戏有毒).自己也尝试了玩了几次,作为一个手残+脑残的资深 ...
- 汇编debug与masm命令
汇编语言这块是我之前写在网易博客上的,不过那个账号基本已经作废了,所以现在抽个时间把当时的博客搬到CSDN上. 汇编命令(编译器masm命令):找到masm所在的文件夹,我的在d:\MASM中,用cm ...
- Java--比较方便的特性归纳,持续更新...
1.import 关键字不仅可以导入包,还可以静态变量和方法. 2.内部类对象会依赖于外部类对象,除非已经存在一个外部类对象,否则类中不会出现内部类对象.也就是说实例化内部类对象时,必须使用外部类对象 ...
- Redis Sentinel配置小记
Sentinel是一个管理多个redis实例的工具,它可以实现对redis的监控.通知.自动故障转移.sentinel不断的检测redis实例是否可以正常工作,通过API向其他程序报告redis的状态 ...
- slave延迟很大优化方法
一般而言,slave相对master延迟较大,其根本原因就是slave上的复制线程没办法真正做到并发.简单说,在master上是并发模式(以InnoDB引擎为主)完成事务提交的,而在slave上,复制 ...
- 开启 TLS 1.3 加密协议,极速 HTTPS 体验
随着互联网的发展,用户对网络速度的要求也越来越高,尤其是目前在大力发展 HTTPS 的情况下,TLS 加密协议变得至关重要.又拍云在 HTTPS 的普及和性能优化上,始终做着自己的努力和贡献.2018 ...
- vb代码之------画一个半透明矩形
入吾QQ群183435019 (学习 交流+唠嗑). 废话不说,咱们来看代码吧 程序结果运行如下 需要如下API 1:GdipCreateFromHDC 功能:创建设备场景相对应的绘图区域(相当于给设 ...
- main函数是主线程吗
1.线程的概念: 线程是程序最基本的运行单位,而进程不能运行,所以能运行的,是进程中的线程. 2.线程是如何创建起来的: 进程仅仅是一个容器,包含了线程运行中所需要的数据结构等信息.一个进程创建时,操 ...
- Centos7安装ES 和 Docker搭建ES
本文版权归博客园和作者吴双本人共同所有 转载和爬虫请注明原文地址 www.cnblogs.com/tdws 一.linux centos7.x安装ES 1.下载java sudo yum instal ...
- 仿腾讯课堂固定滚动列表ReactNative组件
前言 由于业务需要做成类似腾讯课堂课程详情滚动的效果,考虑到后面有可能有新的呈现方式,RN提供的组件没有这种滚动控件,不如自己封装,其实去年已经写了一篇但是写的比较乱,周末花了点时间重写梳理下做的东西 ...