浏览器兼容性--IE11以及Edge等下载文件的中文名出现乱码,前后端解决方案
项目中有用到文件下载功能,之前在处理下载时对IE浏览器下文件下载名进行过处理,测试也没有问题,
但是功能上线后,业务反馈IE11文件下载文件名依然乱码。打印User-Agent字符串如下:
IE11 User-Agent字符串:Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko
IE6~IE10版本的User-Agent字符串:Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.0; Trident/6.0)
一、后端修改
IE浏览器在IE11,更改了User-Agent字符串格式内容,所以针对IE11,做一下判断即可:(后端代码更改)
//下载文件,并处理文件名乱码
public void downloadFile(HttpServletRequest request,HttpServletResponse response){
String path = request.getSession().getServletContext().getRealPath("/upload/文档1.doc");
// path是根据日志路径和文件名拼接出来的
File file = new File(path);
//获取日志文件名称
String filename = file.getName();
try {
//判断是否是IE11
Boolean flag= request.getHeader("User-Agent").indexOf("like Gecko")>0; if (request.getHeader("User-Agent").toLowerCase().indexOf("msie") >0||flag){
filename = URLEncoder.encode(filename, "UTF-8");//IE浏览器
}else {
//先去掉文件名称中的空格,然后转换编码格式为utf-8,保证不出现乱码,
//这个文件名称用于浏览器的下载框中自动显示的文件名
filename = new String(filename.replaceAll(" ", "").getBytes("UTF-8"), "ISO8859-1");
//firefox浏览器
//firefox浏览器User-Agent字符串:
//Mozilla/5.0 (Windows NT 6.1; WOW64; rv:36.0) Gecko/20100101 Firefox/36.0
}
InputStream fis = new BufferedInputStream(new FileInputStream(path));
byte[] buffer;
buffer = new byte[fis.available()];
fis.read(buffer);
fis.close();
response.reset();
response.addHeader("Content-Disposition", "attachment;filename=" +filename);
response.addHeader("Content-Length", "" + file.length());
OutputStream os = response.getOutputStream();
response.setContentType("application/octet-stream");
os.write(buffer);// 输出文件
os.flush();
os.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
二、前端修改
同时作为前端也需要有一个兼容IE的心。
只需要在中文前加上encodeURI函数,将其他部分字符串拼接。
encodeURI()是Javascript中真正用来对URL编码的函数。
它着眼于对整个URL进行编码,因此除了常见的符号以外,对其他一些在网址中有特殊含义的符号“; / ? : @ & = + $ , #”,也不进行编码。编码后,它输出符号的utf-8形式,并且在每个字节前加上%。
$scope.commonWord = baseUrl+"/downloadFile.htm?objectId="+encodeURI('欢迎你加入我们手册')+".pdf&fileName="+encodeURI('欢迎你加入我们手册')+".pdf";
本来在测试和预生产上都OK,发线上版本之后上突然发现IE11下的不同

我的这个IE11的版本出现这个问题--中文乱码的问题。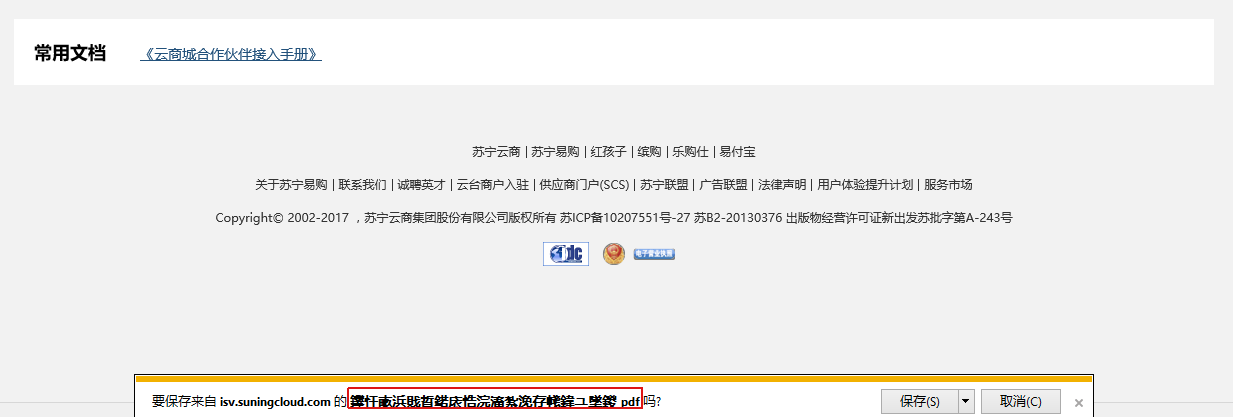
但是在其他版本的IE11居然可以正常下载。
我勒个去
IE居然还在不同的版本之间出现这个问题。你让我怎么兼容。
自己又想了一下,还有可能是不同的win系统下的IE11也会出现不同。
最后后端的修改,完美的解决了这个问题;
之前的是
//2.设置文件头:最后一个参数是设置下载文件名(假如我们叫a.pdf)
response.setHeader("Content-Disposition", "attachment;fileName=" + new String(fileName.getBytes("utf-8"), "ISO8859-1"));
修改之后:
/**
* 构建附件下载回执
*
* @param response - 回执
* @param fullPath - 全路径
* @param fileName - 文件名(含后缀)
* @throws Exception
*/
private void createDownloadFileResponse(HttpServletResponse response, String fullPath, String fileName)
throws IOException {
ServletOutputStream out = null;
FileInputStream in = null;
File file = null;
try {
//1.设置文件ContentType类型,这样设置,会自动判断下载文件类型
response.setContentType("multipart/form-data"); //2.设置文件头:最后一个参数是设置下载文件名(假如我们叫a.pdf)
response.setHeader("Content-Disposition", "attachment;fileName="
+ new String(fileName.getBytes("gb2312"), "ISO8859-1")); // 通过文件路径获得File对象(假如此路径中有一个download.pdf文件)
file = new File(fullPath); in = new FileInputStream(file); // 3.通过response获取ServletOutputStream对象(out)
out = response.getOutputStream(); int len = 0;
byte[] buffer = new byte[1024];
// 循环将输入流中的内容读取到缓冲区当中
while ((len = in.read(buffer)) > 0) {
// 输出缓冲区的内容到浏览器,实现文件下载
out.write(buffer, 0, len);
}
} catch (Exception e) {
logger.error(new StringBuilder("CustomServiceController -> createDownloadFileResponse Error:"
+ "构建附件下载回执出现异常,异常信息为:").append(e).toString());
} finally {
if (in != null) {
in.close();
}
if (out != null) {
out.close();
out.flush();
}
if (file != null && file.exists()) {
file.delete();
}
}
} /*
* 判断是否是ie浏览器如下
*/
public static boolean isMSBrowser(HttpServletRequest request) {
String userAgent = request.getHeader("User-Agent");
for (String signal : IEBrowserSignals) {
if (userAgent.contains(signal))
return true;
}
return false;
}
为什么会出现这种情况:
因为在前端页面已经将中文字符,encodeURI编码转换成utf-8,但是在发送ajax异步请求的时候,IE浏览器总会采用GB2312编码方式(操作系统默认的方式),所以在后端拿到字符串的时候是gb2312编码之后的字符串,所以后端还是需要的是对gb2312编码的字符串进行解码,而不是对utf-8的字符进行解码。
总结一下:
js中url编码&传的值给其他的页面,多参数网址作为整体编码后传值。比如说是http://www.chengxinsong.cn?id=http://chengxinsong.cn/saucxs/?id1=1&id2=2,这个时候参数id所获得的值并不是 http://ilcng.com/xmxy/?id1=1&id2=2而是http://ilcng.com/xmxy/?id1=1,也就是说从&符号的地方截断了,因为&符号是特殊符号不能直接传递,需要经过编码以后才能传递。
一般来说,URL只能使用英文字母、阿拉伯数字和某些标点符号,不能使用其他文字和符号。这是因为网络标准RFC 1738做了硬性规定。
只有字母和数字[0-9a-zA-Z]、一些特殊符号“$-_.+!*'(),”[不包括双引号]、以及某些保留字,才可以不经过编码直接用于URL。
这意味着,如果URL中有汉字,就必须编码后使用。
1、网址路径的编码,用的是utf-8编码;
使用的是chrome浏览器
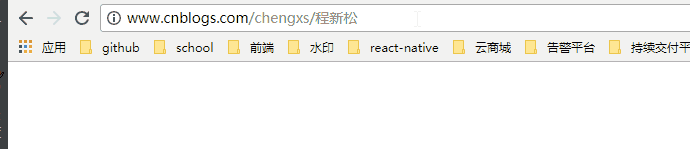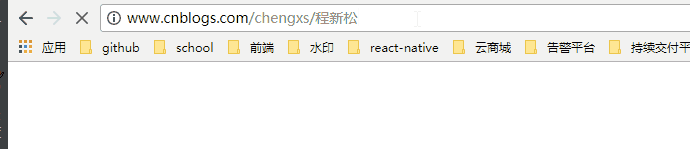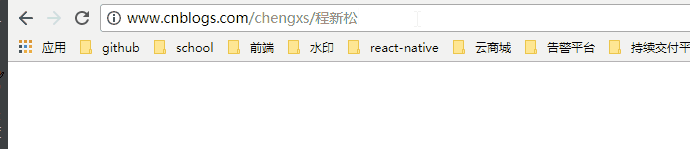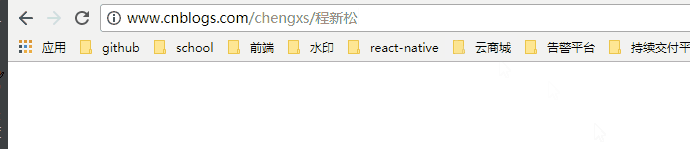
当我使用IE11的浏览器,查看HTTP请求的头信息,会发现IE实际查询的网址是“http://www.cnblogs.com/chengxs/%E7%A8%8B%E6%96%B0%E6%9D%BE”。也就是说,IE自动将“程新松”编码成了“%E7%A8%8B%E6%96%B0%E6%9D%BE”。在每个字节前加上%而得到的。
我把chrome浏览器的url复制到IE上,就出现了如下图所示的:

2、查询字符串的编码,用的是操作系统的默认编码。
3、GET和POST方法的编码,用的是网页的编码。
4、在Ajax调用中,IE总是采用GB2312编码(操作系统的默认编码),而Firefox总是采用utf-8编码。
欢迎访问:
1、云商城isv系统http://isv.suningcloud.com/mpisv-web/index
2、云商城消费者门户http://www.suningcloud.com/promotion/index/experience_center.html
浏览器兼容性--IE11以及Edge等下载文件的中文名出现乱码,前后端解决方案的更多相关文章
- java下载文件时文件名出现乱码的解决办法
转: java下载文件时文件名出现乱码的解决办法 2018年01月12日 15:43:32 橙子橙 阅读数:6249 java下载文件时文件名出现乱码的解决办法: String userAgent ...
- Java 解决IE浏览器下载文件,文件名出现乱码问题
/** * 区分ie 和其他浏览器的下载文件乱码问题 * @param request * @param fileName * @return */ public String getFileName ...
- 解决PHP在IE浏览器下载文件,中文文件名乱码问题
前提:我们网站所有文件全部使用的是UTF-8 NO BOM的编码方式 1.找测试重现.360浏览器下载的呵呵,果然文件名是乱码.再请测试在ie浏览器下测试.IE9,8,7也全部是乱码.查看编码就是UT ...
- 在浏览器端用JS创建和下载文件
前端很多项目中,都有文件下载的需求,特别是JS生成文件内容,然后让浏览器执行下载操作(例如在线图片编辑.在线代码编辑.iPresst等). 但受限于浏览器,很多情况下我们都只能给出个链接,让用户点击打 ...
- Firefox下载文件时中文名乱码问题
为了形象化,先看几张不同浏览器下下载文件时的效果图: 1:Firefox 36.0.1 2:IE8 3:Chrome 40.0.2214.93 m 4:360 7.1.1.322 很明显在Firefo ...
- python3中用django下载文件,中文名乱码怎么办?
前段时间被某个前端小可爱鄙视了一下,说我博客都一年不更新了,我不服,明明还有俩月才到一年呢.不过说是这么说,还是要更新一下的. 以上都是借口,下面开始正文. 我公司的某个内部系统,用djang ...
- window.location.href下载文件,文件名中文乱码处理
下载文件方法: window.location.href='http://www.baidu.com/down/downFile.txt?name=资源文件'; 这种情况下载时:文件名资源文件会中文乱 ...
- Servlet:浏览器下载文件时文件名为乱码问题
1 protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletExcep ...
- 解决用ASP.NET下载文件时,文件名为乱码的问题
关键就一句: string strTemp = System.Web.HttpUtility.UrlEncode(strName, System.Text.Enc ...
随机推荐
- redis特性 存储 API 集群 等
公司组内技术分享,刚好最近工作用redis构建缓存,所以想同事们分享关于redis的一些知识, 这些知识不仅仅是包括一些API层,而是一些关于redis功能功能特性的 目前为什么使用redis构建缓存 ...
- 深度学习的异构加速技术(一):AI 需要一个多大的“心脏”?
欢迎大家前往腾讯云社区,获取更多腾讯海量技术实践干货哦~ 作者:kevinxiaoyu,高级研究员,隶属腾讯TEG-架构平台部,主要研究方向为深度学习异构计算与硬件加速.FPGA云.高速视觉感知等方向 ...
- JMS学习之路(一):整合activeMQ到SpringMVC 转载:http://www.cnblogs.com/xiaochangwei/p/5426639.html
JMS的全称是Java Message Service,即Java消息服务.它主要用于在生产者和消费者之间进行消息传递,生产者负责产生消息,而消费者负责接收消息.把它应用到实际的业务需求中的话我们可以 ...
- 移动端自适应rem 布局篇
相信很多刚开始写移动端页面的同学都要面对页面自适应的问题,当然解决方案很多,比如:百分比布局,弹性布局flex(什么是flex),也都能获得不错的效果,这里主要介绍的是本人在实践中用的最顺手最简单的布 ...
- 基于Vue.js的大型报告页项目实现过程及问题总结(二)
距离上一篇文章过去了二十多天了,期间一直想把第二部分写完,结果在测试过程中遇到了各种坑爹的问题,到今天才算基本完成,也许还有后续,但趁着今天有时间就写出来吧,也算对这个项目的一个总结了 遇到最大问题: ...
- tab面板,html+css
<!doctype html> <html> <head> <meta charset="utf-8"> <title> ...
- LDA算法入门
http://blog.csdn.net/warmyellow/article/details/5454943 LDA算法入门 一. LDA算法概述: 线性判别式分析(Linear Discrimin ...
- Web Mining and Big Data 公开课学习笔记 ---lecture1
1.1 LOOK Finding "stuff" on the web or computer or room or hidden in data Finding documen ...
- HDU2191--多重背包(二进制分解+01背包)
悼念512汶川大地震遇难同胞--珍惜现在,感恩生活 Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Jav ...
- PHP求解一个值是否为质数
/** * 求解一个值是否为质数 * * @param $a * @return int 0是 1不是 */ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 function ...