AI相关 TensorFlow -卷积神经网络 踩坑日记之一
上次写完粗浅的BP算法 介绍
本来应该继续把 卷积神经网络算法写一下的
但是最近一直在踩 TensorFlow的坑。所以就先跳过算法介绍直接来应用场景,原谅我吧。
TensorFlow 介绍
TF是google开源出来的人工智能库,由python语言写的
官网地址:http://www.tensorflow.org/ 请用科学上网访问
中文地址:http://www.tensorfly.cn/
当然还有其他AI库,不过大多数都是由python 写的
.net 的AI库叫 Accord.net (因为我本职是.net的,so……)有兴趣的同学可以去看看,有很多机器学习的工具类,不过可惜当时我在研究的时候只有BP算法,还没有卷积算法的相关。
写这篇博文的时候,听说微软又开放了一个AI库,但是tensorflow比较早。所以还是继续搞tensorFlow
TensorFlow 在支持GPU 并行运算上做的挺多。这个库的入手程度相对其他AI库稍容易点。而且有很多教程代码,包括卷积,对抗网络,循环网络算法。
声明一下踩坑日志系列主要是针对卷积。
阿尔法狗的核心部分就是用的TensorFlow,真佩服google说开源就开源。
好了,废话不说,开始
安装方法推荐
因为我用的是windows机
所以我推荐的安装环境是 python 3.5.2 +PyCharm
这篇博文写时,最新的python是3.6
尝试过安装3.6跟tensorFlow有不兼容问题,后来换了3.5.2 就可以了。
我安装的版本是tensorFlow1.1
不排除之后的版本已经修复这个问题。
tensorFlow1.2已经修复此问题

我推荐的安装方法超简单,但是网上有很多非常复杂的安装,在此踩一下。
十几个字搞定:
安装好python 之后设置好环境变量,然后安装PyCharm 打开=》setting =》project Interpreter 选择刚才安装好的3.5.2
点下面的绿色+ 号 搜索 tensorFolw ,install package! 完成。

教程代码介绍
关于教程部分我建议先看一下极客学院的翻译教程文档。
传送门在此http://wiki.jikexueyuan.com/project/tensorflow-zh/tutorials/overview.html
另外下载一下 github上的源码
https://github.com/tensorflow/tensorflow
最简单的教程是
MNIST
这个教程相关内容在上面的极客学院的文档有详细的介绍,这里我摘取一点

官网例子上有一个坑,因为训练数据会从外网链接上下载,我刚入门那个时候这个链接是404。所以只能另外找这个包,现在这个问题虽然已经修复了,但是我担心那个网站也不是很靠谱。有需要的可以留下邮箱,不多人的话我直接发给你们。
这里我讲一下tensorFlow几个比较晦涩的概念,请结合那个教程一起看
张量 tensor :张量是TF最基本的元素,基本上所有的接口都是需要张量作为输入。
张量其实是对基本类型的一层包装,就是说tensor可以包装是int string array 各种类型。最重要的用途是用来描述多维数组
比如 这个方法生成的tensor
tf.zeros([100,100]) 就是代表正式运行的时候会生成一个二维数组,第一维有100个索引,每个里面有100个0
tf.random_normal([784, 200], stddev=0.35) 代表随机生成一个二维数组 ,784是一维,每个里面有200个元素。总共就是784*100个随机数。 sttddev是这个正态分布的偏差值,我觉得可以理解为平均的差值。用来调整数值分布的密度。
生成一个tensor的方式有很多,也可以用tf.constant() 直接输入常量
这里大家肯定已经很奇怪了,数组就数组,string 就string,干嘛还要包装起来成了tensor
其实这个tensor除了常量tensor之外,其他比方说随机数组,在调用的时候里面都没有值的,只是声明说要生成这么一堆数据,但是实际上要等到 session.run 的时候数据才会生成。
所以其实tensorFlow 编程就是用这些方法声明要构建一个怎么样的算法,这个过程叫做构建图。然后再N次的session.run 这个算法来训练。所以调试的时候很麻烦的地方是,常常是构建图的时候没问题,但是这个算法图正式跑的时候各种出错,但是很难定位是由于哪个数据进行到什么地方出错的。幸好有 tfdbg的模块可以调试,我下面会讲一下在tfdbg上踩的坑。
checkpoint :相当于保存点,就是用来训练到一半的时候保存当时所有张量的值,然后下次可以通过一个saver的鬼东西读取checkpoint的所有环境,继续训练。
这个非常有用,因为数据量特大的时候可能要跑好几天,这样就可以分段进行的,也不怕中途死机。(别问我为啥会死机,说多了都是泪)
MNSIT 这个教程代码是比较简易的卷积算法,训练集很小。
稍大一点的教程是:cifar10

cifar10 的算法比较全面一点
这是这个算法过程的简要描述

由2层 (卷积层+最大池化+归一层)+2层全连接层。不知道全连接层是什么东西的,请参考我上一篇关于BP算法,全连接层就是BP算法的典型结构。
卷积层我这里简单说一下,就是由一个k*k 的数据矩阵(卷积核),去跟图像做卷积运算。卷积过程参考下图
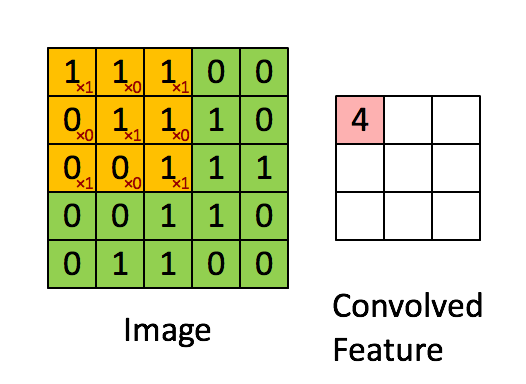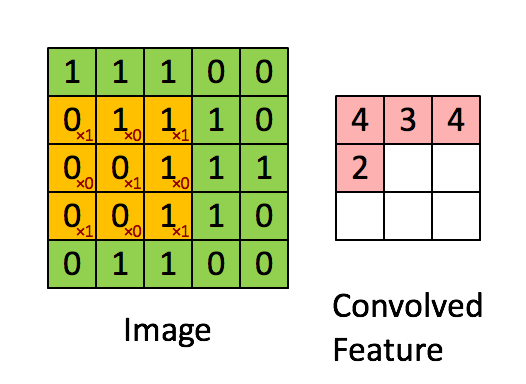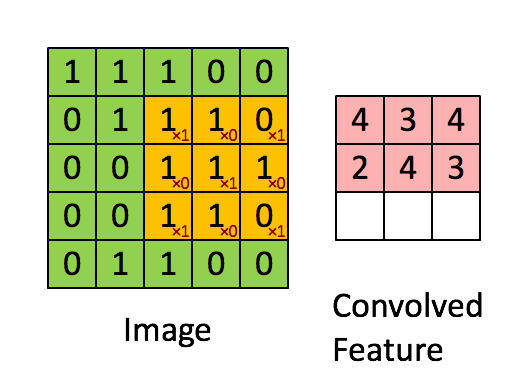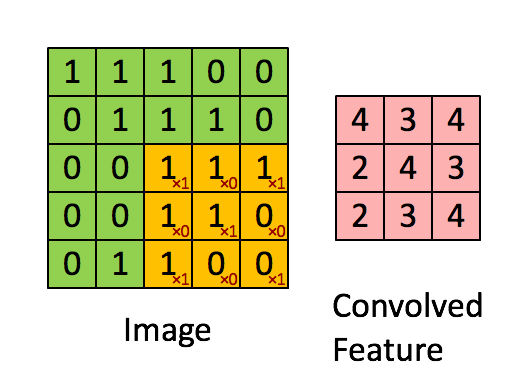
这个过程的作用主要是提取图像特征,不同的卷积核对图像的处理效果是不同的。
比如模糊效果,锐化效果,黑白效果,轮廓效果。都是可以直接设定不同卷积核来达到。
卷积这个词是指这个过程中执行的实际数学过程,不过这个过程在图像领域可以称之为“提取特征”或者叫“滤镜”大家更能明白一点,就是因为不同值的卷积核代表不同的特征提取器。
上面还提到一个名词叫“池化”就是降维,提取特征出来的图片数据量非常大,池化效果比如3*3范围内取一个最大值。那么原本90*90的图片就变成 30*30了。
这就是最大池化。Maxpool
归一化的算法也挺多,但是通俗一点讲,比方说做完卷积之后数据可能是这样 [255,244,266,7777,433] 太大了不好计算,也增加计算压力。归一化一种最简单的办法就是 取个最大值,对每个数做一次 除法
[255/7777,244/7777,266/7777,7777/7777,433/7777]
这样得出来的值就都在 0-1 之间了。这就是传说中归“一”化。
卷积层+最大池化+归一层最终得出一张图片的各种特征数组,然后传给全链接层,根据误差值调整网络里的所有参数,最终达到跟真实值一致。然后跑一下测试集评估结果。
卷积我这里就不细说了。
(我后来写的算法综述中有介绍CNN卷积神经网络的一些内容,补充性的看一下吧 传送门:点我点我)
cifar10+imagenet 改代码
当然cifar10 还是不能拿来用的。毕竟是教程代码
那么现在如果要投入实用,其实有2个问题要解决
1,扩大训练集
2,因为评估代码用的一打图片打包成一个.bin 文件 所以得改成接收1张jpg图片然后输出结果。
第一个问题
先下载imagenet 训练集 ILSVRC2012
这个朋友有地址 http://www.cnblogs.com/zjutzz/p/6083201.html
1000种分类,每一种分类有1000张图片 就是一百万张图片 压缩包140G。下载大半天,解压又是大半天。推荐用7z解压。神速。
但是没有中文分类的名字
所以还得看这里 中文对照表 http://blog.csdn.net/u010165147/article/details/72848497
下载好之后再说一个坑。里面有部分图片是出错格式的。大概有几百张吧。其实量也很小。如果你们找到没问题数据包的就不要我这个了。
不过因为代码读取的时候会出错,所以可能训练到几十万步的时候突然来那么一下,前功尽弃,还很难锁定是哪张出错了。
后来我疯了,因为可以看到出错图片的字节数,所以根据字节数查看文件,然后删了它,然后再跑几十万步之后,又出错,又删了它。
但是几百张图可能出错。- -!哈哈哈哈哈(此处苦笑)。。让我死吧。
然后我就用tfdbg 或者 tensorbroad 来查出那些出错的图片路径。但是……我把图片路径装到一个tf队列里,tfdbg不能显示队列内容。F!
tensorbroad 开启后一直显示没找到监控数据,然而数据文件一直存在的。F!(这个问题在下文有找到原因)
找了很多办法,花了很多时间之后宣告放弃。另觅良方。
干了一阵子傻事之后,我突然受到上天的启发,感觉真神上身。“为啥我不用try catch呢!”
因为这个方法在第一天的时候被我否定了,因为读图的方法

decode_jpeg 一直是这里报错,但是我直接try catch 这一段代码是无效的。因为正如我上面说的,这里只是构建图,构建了想要解码图片的算法而已,并没有真正解码,所以图片格式错误不会被catch到。
但是。。。。。。
我可以在session.run 的时候try catch啊!!!!
我可以在session.run 的时候try catch啊!!!!
我可以在session.run 的时候try catch啊!!!!
结果绕了一大圈,还是最开始的办法最靠谱。“师傅,把那块砖头往我这里砸,对,就是这里,脑门上,用力”。
(结果是try catch也不太行,还是会有一些错误导致session报错,然后程序停止。
最后的办法是用一个图片批量处理工具,把所有图过一遍,去掉那些不可读的图片。)
OK,前戏完结。
cifar10 的详细源码解析这里就不讲了,大家自行搜索。
大致讲一下我对cifar10的修改,用来装载这100万张图片
首先
cifar10_input.py 代码里
distorted_inputs 方法主要是用来加载

这六个bin文件

每个文件里是一堆图片跟标签的打包。
再看
read_cifar10()方法里

FixedLength 读取器会根据固定长度的一段段的读取文件。所以这个bin文件里面一张图的长度就是 32*32*3(RGB3个通道的意思)+label的长度。
现在imagenet解压出来的格式是

这里明显不同了,怎么办?
不干了!删代码!卸载系统!
说笑了,默默的打开IDE。
还是
cifar10_input.py文件
主要改这个方法

这个方法主要是从bin文件里读取了固定长度的,然后把label切出来放到 result.label 把原本图片数据转换成3维数组tersor(reshape)。然后稍微把数组的维度转换一下。就是最后 transpone 改为了[1,2,0] 就是原本depth*height*width 改为 height*width*depth*depth这里是指颜色通道,红绿蓝3种。

这里我换成
WholeFileReader 读取整个文件。然后
resize_images 成32*32
因为label 是分类名称,也是图片所在文件夹的名称,所以我在外面把图片文件夹名称都丢到一个label的string队列里,然后里面做出队 depuqeue。 核心部分就完了。
剩下一个问题就是读取单张图片然后跑一下评估代码
cifar10_eval.py
得出结果。然后就可以投入实用了。
cifar10_eval.py代码还需要改一下

新增这个方法,图片必须改成32*32大小的,这个可以用其他自己熟悉的代码处理,把图片读取成数组,然后按照bin文件的格式打包成一个。剩下就是按照eval原有的代码,只改一下读取bin文件的路径就可以。

最后run之后把
predictions输出就可以了
这里就能拿到label了,然后根据上面的中文对照表得出分类名称。大功告成。
然而。。。。。。
这篇文章叫做踩坑日志,所以最大的坑在最后。
不知道为啥,训练了100W步之后每次去测试跑结果,都是

有毒啊!!!
未完待续。
国际惯例 原文地址http://www.cnblogs.com/7rhythm/p/7091624.html
转载请注明出处。PS:文中代码都是用图片,因为只是摘取部分核心代码,并不能直接运行,所以诸君不用复制去调试了,理解要紧。
传送门:踩坑日记之二
AI相关 TensorFlow -卷积神经网络 踩坑日记之一的更多相关文章
- 人工智能(AI)库TensorFlow 踩坑日记之一
上次写完粗浅的BP算法 介绍 本来应该继续把 卷积神经网络算法写一下的 但是最近一直在踩 TensorFlow的坑.所以就先跳过算法介绍直接来应用场景,原谅我吧. TensorFlow 介绍 TF是g ...
- Hexo搭建静态博客踩坑日记(二)
前言 Hexo搭建静态博客踩坑日记(一), 我们说到利用Hexo快速搭建静态博客. 这节我们就来说一下主题的问题与主题的基本修改操作. 起步 chrome github hexo git node.j ...
- Tensorflow卷积神经网络[转]
Tensorflow卷积神经网络 卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络, 在计算机视觉等领域被广泛应用. 本文将简单介绍其原理并分析Te ...
- 深度学习原理与框架-Tensorflow卷积神经网络-cifar10图片分类(代码) 1.tf.nn.lrn(局部响应归一化操作) 2.random.sample(在列表中随机选值) 3.tf.one_hot(对标签进行one_hot编码)
1.tf.nn.lrn(pool_h1, 4, bias=1.0, alpha=0.001/9.0, beta=0.75) # 局部响应归一化,使用相同位置的前后的filter进行响应归一化操作 参数 ...
- hexo博客谷歌百度收录踩坑日记
title: hexo博客谷歌百度收录踩坑日记 toc: false date: 2018-04-17 00:09:38 百度收录文件验证 无论怎么把渲染关掉或者render_skip都说我的格式错误 ...
- Hexo搭建静态博客踩坑日记(一)
前言 博客折腾一次就好, 找一个适合自己的博客平台, 专注于内容进行提升. 方式一: 自己买服务器, 域名, 写前端, 后端(前后分离最折腾, 不分离还好一点)... 方式二: 利用Hexo, Hug ...
- TensorFlow 卷积神经网络实用指南 | iBooker·ApacheCN
原文:Hands-On Convolutional Neural Networks with TensorFlow 协议:CC BY-NC-SA 4.0 自豪地采用谷歌翻译 不要担心自己的形象,只关心 ...
- 人工智能(AI)库TensorFlow 踩坑日记之二
上次 踩坑日志之一 遗留的问题终于解决了,所以作者(也就是我)终于有脸出来写第二篇了. 首先还是贴上 卷积算法的示例代码地址 :https://github.com/tensorflow/models ...
- tensorflow卷积神经网络-【老鱼学tensorflow】
前面我们曾有篇文章中提到过关于用tensorflow训练手写2828像素点的数字的识别,在那篇文章中我们把手写数字图像直接碾压成了一个784列的数据进行识别,但实际上,这个图像是2828长宽结构的,我 ...
随机推荐
- window 远程在Linux(centOS7.0)上安装JDK以及配置环境变量
本人是在windows 7 上安装了虚拟机,虚拟机安装的是linux(centOS7.0)系统现在在Windows 上安装SecureCRT 远程虚拟机的linux系统,安装JDK以及配置环境变量. ...
- web 直播&即时聊天------阿里云、融云
随着直播越来越火,所在公司也打算制作自己的直播,所以去了解了这方面,使用后发现还是有些问题需要记录的. 经过分析,制作直播应该是分为两块来做,即直播与实时评论.这里先去制作实时评论,等直播ok后,也会 ...
- 编写自己的一个简单的web容器(二)
昨天我们已经能够确定浏览器的请求能够被我们自己编写的服务类所接收并且我们服务类响应的数据也能够正常发送到浏览器客户端,那么我们今天要解决的问题就是让我们的数据能够被浏览器识别并解析. Http(Htt ...
- Linux Set Command
1. set -e "Exit immediately if a simple command exits with a non-zero status." When this o ...
- Servlet起步
什么是Servlet Servlet是sun公司制定的用来扩展web服务器功能的组件规范,通俗理解为遵循Servlet规范开发的实现了某个功能的Java组件.该组件没有 main 方法,不能独立地运行 ...
- Word Ladder II 2015年6月4日
Given two words (start and end), and a dictionary, find all shortest transformation sequence(s) from ...
- SVN如何迁移到Git?
最近在使用华为软件开发云进行开发项目管理,目前华为软件开发云支持500M的免费项目空间,而且还可以在线编译和构建,不用担心开发环境和生产环境的不同,很好的体现了DevOps的开发理念. 之前一直是用s ...
- input输入框控制字数
HTML: <input class = "remark" type = "text" maxlength = "500"> J ...
- Git详细教程(3)---结合gitHub使用
1.GitHub的基本使用 GitHub就是一个网站,本身是基于Git,可以完成版本控制,可以托管代码. 英文版的. 在使用GitHub之前,首先需要注册一个账号. 登录,就可以完成相关的一些操作. ...
- springboot 获取hibernate 的 SessionFactory
注入bean package cn.xiaojf; import cn.xiaojf.today.data.rdb.repository.RdbCommonRepositoryImpl; import ...