JSONP 爬虫
作者QQ:1095737364 QQ群:123300273 欢迎加入!
1.mavne 依赖:
<!--html 解析 : jsoup HTML parser library @ http://jsoup.org/-->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.2</version>
</dependency>
2.JSONPUtils工具:
package com.hiione.common.util;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements; import java.io.IOException;
import java.util.Iterator; public class JsoupUtils { public static String jsoupElement(String content){
Document doc = Jsoup.parse(content);
Element body = doc.body();
Elements aHref=body.select("a");
Elements jsScript = body.select("script");
Elements form = body.select("form");
Elements link = body.select("link");
Elements ifrom = body.select("iframe ");
Elements http = body.select("http");
if(jsScript.size()!=0 ||aHref.size()!=0||form.size()!=0||link.size()!=0||ifrom.size()!=0||http.size()!=0){
return "0";
}
return "";
}
public static String jsoupElementByURL(String content){
String url = "http://as.meituan.com/meishi/all";
Document doc = null;
try {
doc = Jsoup.connect(url).get();
} catch (IOException e1) {
e1.printStackTrace();
}
Element body = doc.body();
Elements aHref=body.select("a");
Elements es=body.select("a");
for (Iterator it = es.iterator(); it.hasNext();) {
Element e = (Element) it.next();
System.out.println(e.text()+" "+e.attr("href"));
}
Elements jsScript = body.select("script");
Elements form = body.select("form");
Elements link = body.select("link");
Elements ifrom = body.select("iframe ");
Elements http = body.select("http");
if(jsScript.size()!=0 ||aHref.size()!=0||form.size()!=0||link.size()!=0||ifrom.size()!=0||http.size()!=0){
return "0";
}
return "";
}
}
3.jsoup 简介

4.文档输入
// 直接从字符串中输入 HTML 文档
String html = "<html><head><title>JSONP</title></head>" +
"<body><p>这里是 jsoup 项目的相关文章</p></body></html>";
Document doc = Jsoup.parse(html);
// 从URL直接加载 HTML 文档
Document doc = Jsoup.connect("http://www.baidu.net/").get();
String title = doc.title();
Document doc = Jsoup.connect("http://www.baidu.net/")
.data("query", "Java") //请求参数
.userAgent("I’m jsoup") //设置User-Agent
.cookie("auth", "token") //设置cookie
.timeout(3000) //设置连接超时时间
.post(); //使用POST方法访问URL
// 从文件中加载 HTML 文档
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/");
5.解析并提取 HTML 元素
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input, "UTF-8", "http://www.baidu.net/");
Element content = doc.getElementById("content");
Elements links = content.getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
}
File input = new File("D:\test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.baidu.net/");
Elements links = doc.select("a[href]"); // 具有 href 属性的链接
Elements pngs = doc.select("img[src$=.png]");//所有引用png图片的元素
Element masthead = doc.select("div.masthead").first();
// 找出定义了 class="masthead" 的元素
Elements resultLinks = doc.select("h3.r > a"); // direct a after h3
6.修改数据
doc.select("div.comments a").attr("rel", "nofollow");
//为所有链接增加 rel=nofollow 属性
doc.select("div.comments a").addClass("mylinkclass");
//为所有链接增加 class="mylinkclass" 属性
doc.select("img").removeAttr("onclick"); //删除所有图片的onclick属性
doc.select("input[type=text]").val(""); //清空所有文本输入框中的文本
7.HTML 文档清理
String unsafe = "<p><a href='http://www.oschina.net/' onclick='stealCookies()'>JSONP</a></p>";
String safe = Jsoup.clean(unsafe, Whitelist.basic());
// 输出:
// <p><a href="http://www.baidu.net/" rel="nofollow">JSONP</a></p>
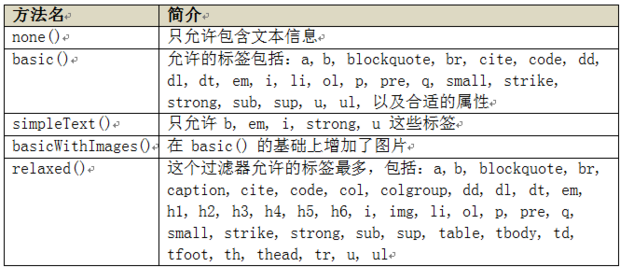
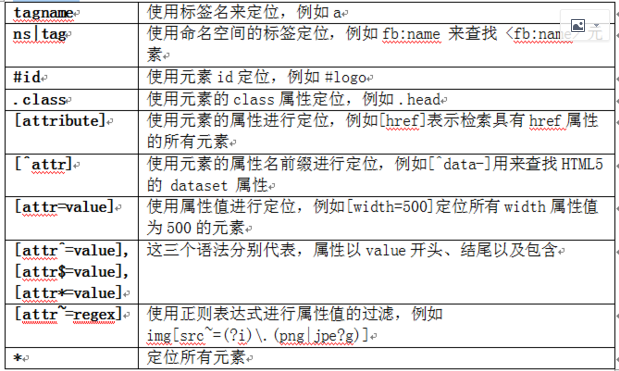
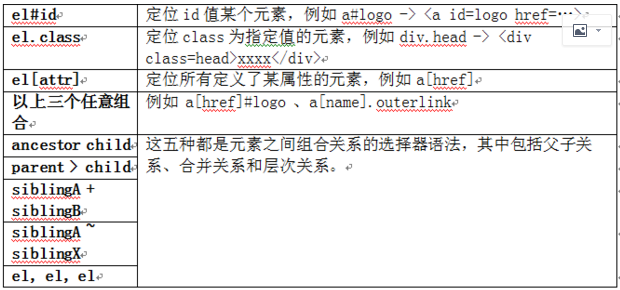
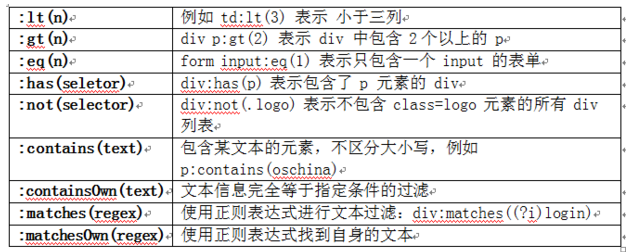
8.jsoup 的过人之处——选择器
JSONP 爬虫的更多相关文章
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇) 淘宝改字段,Bugfix,查看https://github.com/hunterhug/taobaoscrapy.git 由于Gith ...
- NodeJs简单七行爬虫--爬取自己Qzone的说说并存入数据库
没有那么难的,嘿嘿,说起来呢其实挺简单的,或者不能叫爬虫,只需要将自己的数据加载到程序里再进行解析就可以了,如果说你的Qzone是向所有人开放的,那么就有一个JSONP的接口,这么说来就简单了,也就不 ...
- 用 Python 编写网络爬虫 笔记
Chapter I 简介 为什么要写爬虫? 每个网站都应该提供 API,然而这是不可能的 即使提供了 API,往往也会限速,不如自己找接口 注意已知条件(robots.txt 和 sitemap.xm ...
- 跨域问题实践总结! 上(JSONP/document.domain/window.name)
1. JSONP 首先要介绍的跨域方法必然是 JSONP. 现在你想要获取其他网站上的 JavaScript 脚本,你非常高兴的使用 XMLHttpRequest 对象来获取.但是浏览器一点儿也不配合 ...
- 爬虫技术实现空间相册采集器V.0.0.1版本
一. 功能需求分析: 在很多时候我们需要做这样一个事情:我们想把我们QQ空间上的相册高清图像下载下来,怎么做?到网上找软件?答案是否定的,理由之一:网上很多软件不知有没有病毒,第二它有可能捆了很 ...
- python爬虫——与不断变化的页面死磕和更新换代(3)
经过上一次的实战,手感有了,普罗西(雾)池也有了,再战taobao/tmall 试着使用phantomJS爬手机端,结果发现爬来的tmall页面全是乱码,taobao页面xpath识别错误.一顿分析了 ...
- c#代码 天气接口 一分钟搞懂你的博客为什么没人看 看完python这段爬虫代码,java流泪了c#沉默了 图片二进制转换与存入数据库相关 C#7.0--引用返回值和引用局部变量 JS直接调用C#后台方法(ajax调用) Linq To Json SqlServer 递归查询
天气预报的程序.程序并不难. 看到这个需求第一个想法就是只要找到合适天气预报接口一切都是小意思,说干就干,立马跟学生沟通价格. 不过谈报价的过程中,差点没让我一口老血喷键盘上,话说我们程序猿的人 ...
- 深入浅出爬虫之道: Python、Golang与GraphQuery的对比
深入浅出爬虫之道: Python.Golang与GraphQuery的对比 本文将分别使用 Python ,Golang 以及 GraphQuery 来解析某网站的 素材详情页面 ,这个页面的特色是具 ...
- 爬虫扒下 bilibili 视频信息
B站算是对爬虫非常非常友好的网站啦! 修改转载已取得腾讯云授权 在以上两篇文章中我们已经在腾讯云服务器上搭建好了 Python 爬虫环境了,下一步就是在云服务器上爬上我们的爬虫,抓取我们想要的数据: ...
随机推荐
- 基于TFS的.net技术路线的云平台DevOps实践
DevOps是近几年非常流行的系统研发管理模式,很多公司都或多或少在践行DevOps.那么,今天就说说特来电云平台在DevOps方面的实践吧. 说DevOps,不得不说DevOps的具体含义.那么,D ...
- php后台模板html拼接写法
public function get_kefu_reply_list(){ $wid=$this->_post('order_id'); if(!$wid){ echo('工单信息获取失败!' ...
- [leetcode-617-Merge Two Binary Trees]
Given two binary trees and imagine that when you put one of them to cover the other, some nodes of t ...
- 【Android Developers Training】 93. 创建一个空验证器
注:本文翻译自Google官方的Android Developers Training文档,译者技术一般,由于喜爱安卓而产生了翻译的念头,纯属个人兴趣爱好. 原文链接:http://developer ...
- Redis事务原理分析
Redis事务原理分析 基本应用 在Redis的事务里面,采用的是乐观锁,主要是为了提高性能,减少客户端的等待.由几个命令构成:WATCH, UNWATCH, MULTI, EXEC, DISCARD ...
- [Android FrameWork 6.0源码学习] Window窗口类分析
了解这一章节,需要先了解LayoutInflater这个工具类,我以前分析过:http://www.cnblogs.com/kezhuang/p/6978783.html Window是Activit ...
- SSIM(结构相似度算法)不同实现版本的差异
前言 最近用ssim测试图片画质损伤时,发现matlab自带ssim与之前一直使用的ssim计算得分有差异,故和同事开始确定差异所在. 不同的SSIM版本 这里提到不同的ssim版本主要基于matla ...
- .NET 跨平台界面框架和为什么你首先要考虑再三
原文地址 现在用 C# 来开发跨平台应用已经有很成熟的方案,即共用非界面代码,而每个操作系统搭配特定的用户界面代码.这个方案的好处是可以直接使用操作系统原生的控件和第三方控件,还能够和操作系统 ...
- requireJS 源码(二) data-main 的加载实现
(一)requireJs 的整体结构: requireJS 源码 前192行,是一些 变量的声明,工具函数的实现 以及 对 三个全局变量(requirejs,require,define)若被占用后的 ...
- voa 2015 / 4 / 27
As reports of the death toll rise in Nepal, countries and relief organizations around the world are ...