Flink JobManager HA模式部署(基于Standalone)
参考文章:https://ci.apache.org/projects/flink/flink-docs-release-1.3/setup/jobmanager_high_availability.html#bootstrap-zookeeper
Flink典型的任务处理过程如下所示:

很容易发现,JobManager存在单点故障(SPOF:Single Point Of Failure),因此对Flink做HA,主要是对JobManager做HA,根据Flink集群的部署模式不同,分为Standalone、OnYarn,本文主要涉及Standalone模式。
JobManager的HA,是通过Zookeeper实现的,因此需要先搭建好Zookeeper集群,同时HA的信息,还要存储在HDFS中,因此也需要Hadoop集群,最后修改Flink中的配置文件。
一、部署Zookeeper集群
参考博文:http://www.cnblogs.com/liugh/p/6671460.html
二、部署Hadoop集群
参考博文:http://www.cnblogs.com/liugh/p/6624872.html
三、部署Flink集群
参考博文:http://www.cnblogs.com/liugh/p/7446295.html
四、conf/flink-conf.yaml修改
4.1 必选项
high-availability: zookeeper
high-availability.zookeeper.quorum: DEV-SH-MAP-:,DEV-SH-MAP-:,DEV-SH-MAP-:
high-availability.zookeeper.storageDir: hdfs:///flink/ha
4.2 可选项
high-availability.zookeeper.path.root: /flink
high-availability.zookeeper.path.cluster-id: /map_flink
修改完后,使用scp命令将flink-conf.yaml文件同步到其他节点
五、conf/masters修改
设置要启用JobManager的节点及端口:
dev-sh-map-:
dev-sh-map-:
修改完后,使用scp命令将masters文件同步到其他节点
六、conf/zoo.cfg修改
# ZooKeeper quorum peers
server.=DEV-SH-MAP-::
server.=DEV-SH-MAP-::
server.=DEV-SH-MAP-::
修改完后,使用scp命令将masters文件同步到其他节点
七、启动HDFS
[root@DEV-SH-MAP- conf]# start-dfs.sh
Starting namenodes on [DEV-SH-MAP-]
DEV-SH-MAP-: starting namenode, logging to /usr/hadoop-2.7./logs/hadoop-root-namenode-DEV-SH-MAP-.out
DEV-SH-MAP-: starting datanode, logging to /usr/hadoop-2.7./logs/hadoop-root-datanode-DEV-SH-MAP-.out
DEV-SH-MAP-: starting datanode, logging to /usr/hadoop-2.7./logs/hadoop-root-datanode-DEV-SH-MAP-.out
DEV-SH-MAP-: starting datanode, logging to /usr/hadoop-2.7./logs/hadoop-root-datanode-DEV-SH-MAP-.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/hadoop-2.7./logs/hadoop-root-secondarynamenode-DEV-SH-MAP-.out
八、启动Zookeeper集群
[root@DEV-SH-MAP- conf]# start-zookeeper-quorum.sh
Starting zookeeper daemon on host DEV-SH-MAP-.
Starting zookeeper daemon on host DEV-SH-MAP-.
Starting zookeeper daemon on host DEV-SH-MAP-.
【注】这里使用的命令start-zookeeper-quorum.sh是FLINK_HOME/bin中的脚本
九、启动Flink集群
[root@DEV-SH-MAP- conf]# start-cluster.sh
Starting HA cluster with masters.
Starting jobmanager daemon on host DEV-SH-MAP-.
Starting jobmanager daemon on host DEV-SH-MAP-.
Starting taskmanager daemon on host DEV-SH-MAP-.
Starting taskmanager daemon on host DEV-SH-MAP-.
Starting taskmanager daemon on host DEV-SH-MAP-.
可以看到,启动了两个JobManager,一个Leader,一个Standby
十、测试HA
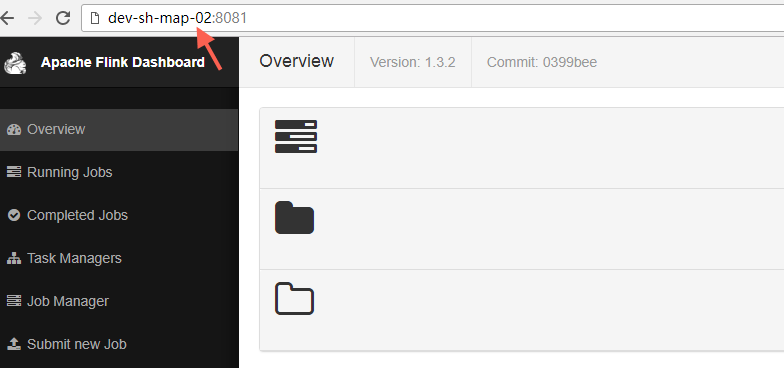
10.1 访问Leader的WebUI:

10.2 访问StandBy的WebUI
这时也会跳转到Leader的WebUI
10.3 Kill掉Leader
[root@DEV-SH-MAP- flink-1.3.]# jps
Jps
TaskManager
DataNode
SecondaryNameNode
JobManager
FlinkZooKeeperQuorumPeer
NameNode
[root@DEV-SH-MAP- flink-1.3.]# kill -9 34562
[root@DEV-SH-MAP- flink-1.3.]# jps
TaskManager
DataNode
SecondaryNameNode
Jps
FlinkZooKeeperQuorumPeer
NameNode
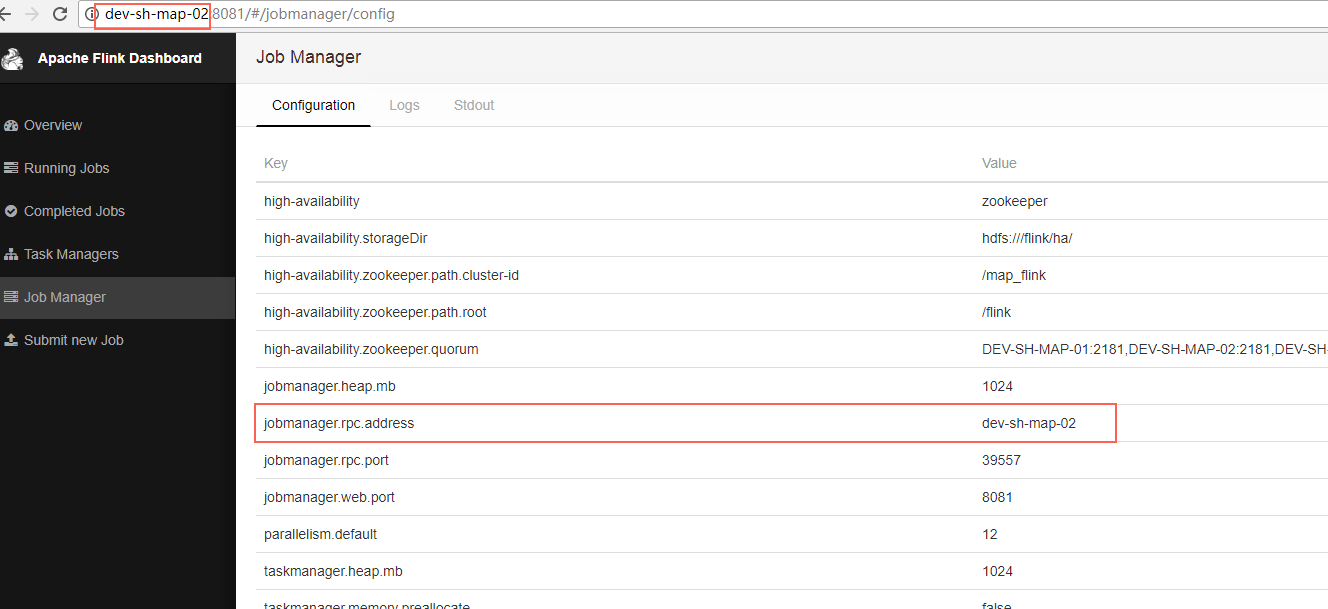
再次访问Flink WebUI,发现Leader已经发生切换
10.4 重启被Kill掉的JobManager
[root@DEV-SH-MAP- bin]# jobmanager.sh start cluster DEV-SH-MAP-01
Starting jobmanager daemon on host DEV-SH-MAP-.
[root@DEV-SH-MAP- bin]# jps
TaskManager
DataNode
SecondaryNameNode
JobManager
Jps
FlinkZooKeeperQuorumPeer
NameNode
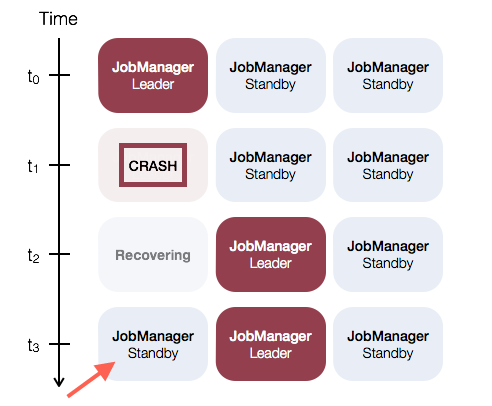
再次查看WebUI,发现虽然以前被Kill掉的Leader起来了,但是现在仍是StandBy,现有的Leader不会发生切换,也就是Flink下面的示意图:
十一、存在的问题
JobManager发生切换时,TaskManager也会跟着发生重启
Flink JobManager HA模式部署(基于Standalone)的更多相关文章
- 一脸懵逼学习Hadoop分布式集群HA模式部署(七台机器跑集群)
1)集群规划:主机名 IP 安装的软件 运行的进程master 192.168.199.130 jdk.hadoop ...
- 分布式集群HA模式部署
一:HDFS系统架构 (一)利用secondary node备份实现数据可靠性 (二)问题:NameNode的可用性不高,当NameNode节点宕机,则服务终止 二:HA架构---提高NameNode ...
- 搭建高可用的flink JobManager HA
JobManager协调每个flink应用的部署,它负责执行定时任务和资源管理. 每一个Flink集群都有一个jobManager, 如果jobManager出现问题之后,将不能提交新的任务和运行新任 ...
- Flink集群模式部署及案例执行
一.软件要求 Flink在所有类UNIX的环境[例如linux,mac os x和cygwin]上运行,并期望集群由一个 主节点和一个或多个工作节点组成.在开始设置系统之前,确保在每个节点上都安装了一 ...
- Spark部署三种方式介绍:YARN模式、Standalone模式、HA模式
参考自:Spark部署三种方式介绍:YARN模式.Standalone模式.HA模式http://www.aboutyun.com/forum.php?mod=viewthread&tid=7 ...
- 第06讲:Flink 集群安装部署和 HA 配置
Flink系列文章 第01讲:Flink 的应用场景和架构模型 第02讲:Flink 入门程序 WordCount 和 SQL 实现 第03讲:Flink 的编程模型与其他框架比较 第04讲:Flin ...
- [hadoop][会装]HBase集群安装--基于hadoop ha模式
可以参考部署HBase系统(分布式部署) 和基于无HA模式的hadoop下部署相比,主要是修改hbase-site .xml文件,修改如下参数即可: <property> <name ...
- Spark运行模式与Standalone模式部署
上节中简单的介绍了Spark的一些概念还有Spark生态圈的一些情况,这里主要是介绍Spark运行模式与Spark Standalone模式的部署: Spark运行模式 在Spark中存在着多种运行模 ...
- Spark集群基于Zookeeper的HA搭建部署笔记(转)
原文链接:Spark集群基于Zookeeper的HA搭建部署笔记 1.环境介绍 (1)操作系统RHEL6.2-64 (2)两个节点:spark1(192.168.232.147),spark2(192 ...
随机推荐
- 【javascript】回调函数
1. 定义 回调函数,即当条件满足时执行的函数.有三种方法实现调用回调函数 call 1)call 用法:call(thisObj, Obj) 主要区别:call 方法会将函数对象上下文修改为this ...
- [NOI2005] 维护数列
[NOI2005] 维护数列 题目 传送门 请写一个程序,要求维护一个数列,支持以下 6 种操作:(请注意,格式栏 中的下划线‘ _ ’表示实际输入文件中的空格) 操作编号 输入文件中的格式 说明 1 ...
- vue指令v-pre示例解析
v-pre会跳过该元素及其子元素的编译过程,显示原始标签. <div id="app"> <span v-pre>{{msg}} 这句不会编译</sp ...
- C互质个数
C互质个数 Time Limit:1000MS Memory Limit:65536K Total Submit:55 Accepted:27 Description 贝贝.妞妞和康康都长大了,如今 ...
- MyBatis-从查询昨天的数据说起
前段时间写了<RabbitMQ入门>系列 RabbitMQ入门-初识RabbitMQ RabbitMQ入门-从HelloWorld开始 RabbitMQ入门-高效的Work模式 Rabbi ...
- 树状数组lowbit()函数原理的解释 x&(x^(x-1)) x&-x
树状数组lowbit()函数所求的就是最低位1的位置所以可以通过位运算来计算 树状数组通过 x&(x^(x-1)) 能够成功求出lowbit的原因: 首先设x=6,即110(2) 于是我们使 ...
- ES6 浅谈let与const 块级作用域之封闭空间(闭包)
ES6新增了 let const 命令,用来声明变量.它的用法类似于 var ,但是所声明的变量,只在 let const 命令所在的代码块内有效. var const 不允许重复声明 用处: 可 ...
- shell脚本报错:"[: =: unary operator expected"
shell脚本报错:"[: =: unary operator expected" 在匹配字符串相等时,我用了类似这样的语句: if [ $STATUS == "OK&q ...
- 关于修改了db2 instance下面文件夹权限导致的不可连接
前一段时间,我修改了db2inst1目录下的所有文件的权限,目的是方便其他用户访问和查看里面的文件信息.可是修改了之后,我用IBM data studio就始终连接不上数据库了. 查看了错误代码,看提 ...
- Qt实现冒泡提示框
通过QLabel创建类似冒泡方式的提示框(提示框显示位置为父类控件居中位置,具体可根据需要自行修改),鼠标停留提示框界面时查看信息,离开时自动淡化消失的效果: 头文件定义 #ifndef _TTipW ...