数据仓库Hive(一)——hive简介,产生,安装
1.Hive简介
- 数据仓库
- 解释器、编译器、优化器等
- 运行时,元数据存储在关系型数据库里面
1.1数据库和数据仓库的区别
- 数据库需要立即返回结果,数据仓库不需要
- 数据仓库能收纳各种数据源,而数据库只能保持产品线
- 数据库可修改,数据仓库不可修改
1.2Hive的产生
- 非java编程者对hdfs的数据做mapreduce操作
2.Hive架构
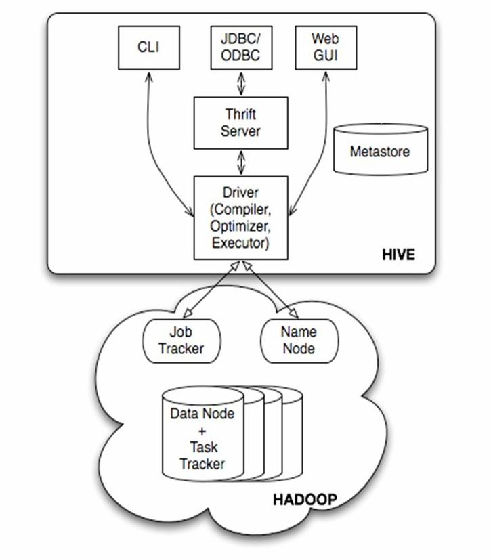
图2.1 架构图
(1)用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是CLI,Cli启动的时候,会同时启动一个Hive副本。Client是Hive的客户端,用户连接至Hive Server。在启动 Client模式的时候,需要指出Hive Server所在节点,并且在该节点启动Hive Server。 WUI是通过浏览器访问Hive。
(2)Hive将元数据存储在数据库中,如mysql、derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
(3)解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
(4)Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会生成MapRedcue任务)。
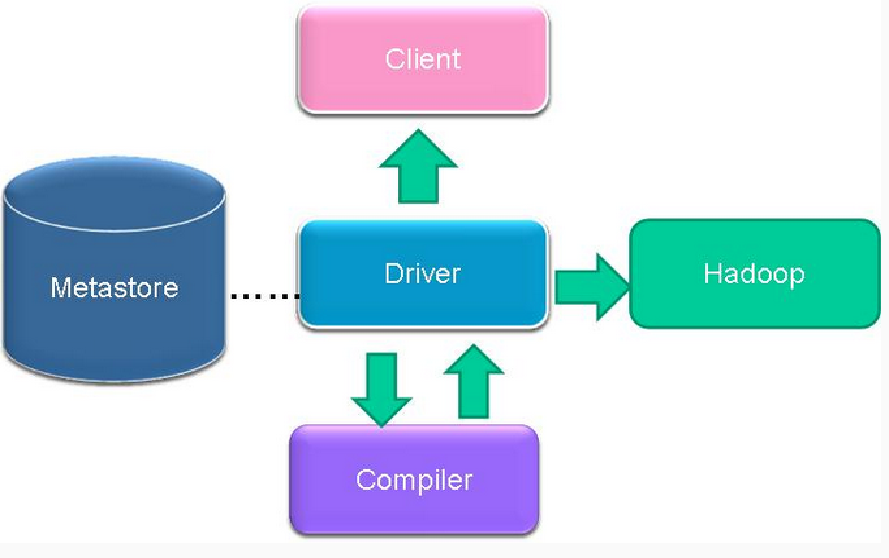
图2.2 描述传递过程
3.安装hive的步骤:
3.1.下载解压
wget http://mirror.bit.edu.cn/apache/hive/hive-2.3.4/apache-hive-2.3.4-bin.tar.gz
3.2.修改环境变量
vi /etc/profile
export HIVE_HOME=/opt/bigdata/hive-2.3.
将bin目录添加到PATH路径中
3、修改配置文件,进入到/opt/bigdata/hive-2.3.4/conf
mv hive-default.xml.template hive-site.xml
增加配置:
进入到文件之后,将文件原有的配置删除,但是保留最后一行,从<configuration></configuration>
:.,$-1d
增加如下配置信息:
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node01:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value></value>
</property>
4、添加MySQL的驱动包拷贝到lib目录
5、执行初始化元数据数据库的步骤
schematool -dbType mysql -initSchema
6、执行hive启动对应的服务
7、执行相应的hive SQL的基本操作
远程访问模式的服务端一样,客户端配置:
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node03:9083</value>
</property>
</configuration>
服务端 hive --service metastore
客户端 hive
4.架构方式
4-1 hive数据架构图
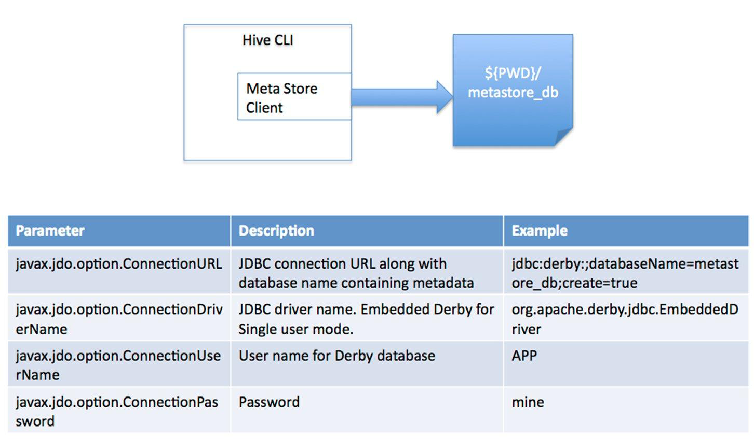
4-2搭建模式(一)单hive形式->自带metastore_db模式{In-memory DB}
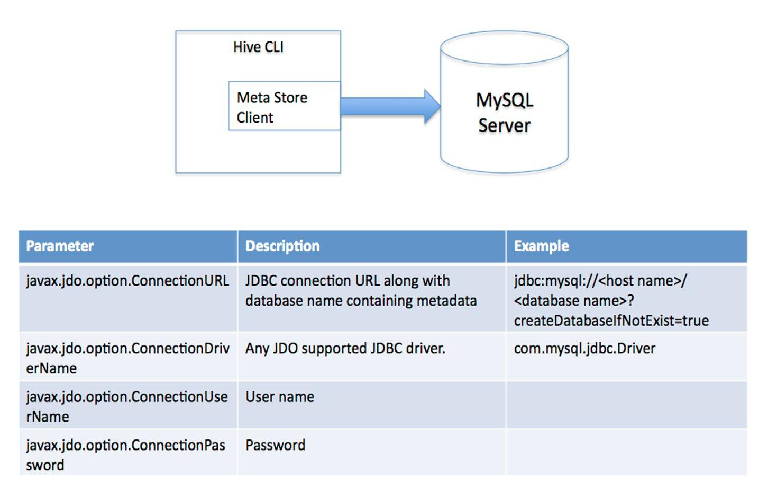
4-3搭建模式(二)一个hive 一个数据库模式{三中的模式}
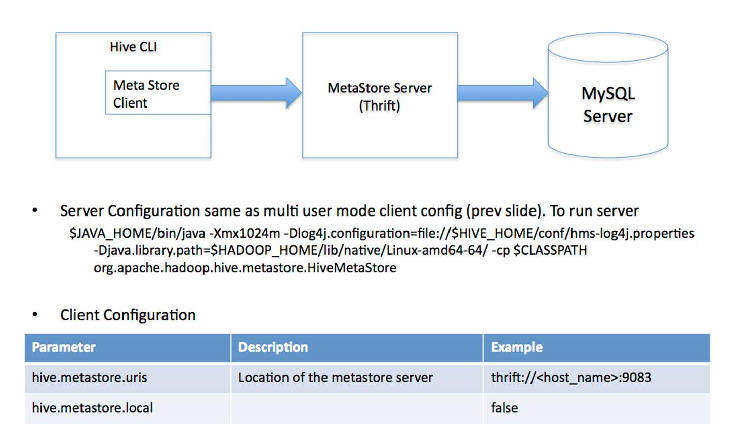
4-3搭建模式(三)远程访问模式
远程访问模式:远程服务器模式 用于非Java客户端访问元数据库,在服务器端启动MetaStoreServer,客户端利用Thrift协议通过MetaStoreServer访问元数据库
数据仓库Hive(一)——hive简介,产生,安装的更多相关文章
- Apache Hive 简介及安装
简介 Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件 映射为一张数据库表,并提供类 SQL 查询功能. 本质是将 SQL 转换为 MapReduce 程序. 主要用途:用来 ...
- 【转】 hive简介,安装 配置常见问题和例子
原文来自: http://blog.csdn.net/zhumin726/article/details/8027802 1 HIVE概述 Hive是基于Hadoop的一个数据仓库工具,可以将结构化 ...
- MySQL、Hive以及MySQL Connector/J安装过程
MySQL安装 ①官网下载mysql-server(yum安装) wget http://dev.mysql.com/get/mysql-community-release-el7-5.noarch. ...
- hive第一篇----简介和使用客户端
摘要by crazyhacking:•Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能.•本质是将SQL转换为MapReduce程序的映射 ...
- Hive 系列(一)安装部署
Hive 系列(一)安装部署 Hive 官网:http://hive.apache.org.参考手册 一.环境准备 JDK 1.8 :从 Oracle 官网下载,设置环境变量(JAVA_HOME.PA ...
- 一个数据仓库时代开始--Hive
一.什么是 Apache Hive? Apache Hive 是一个基于 Hadoop Haused 构建的开源数据仓库系统,我们使用它来查询和分析存储在 Hadoop 文件中的大型数据集.此外,通过 ...
- 1 复习ha相关 + weekend110的hive的元数据库mysql方式安装配置(完全正确配法)(CentOS版本)(包含卸载系统自带的MySQL)
本博文的主要内容是: .复习HA相关 .MySQL数据库 .先在MySQL数据库中建立hive数据库 .hive的配置 以下是Apache Hadoop HA的总结.分为hdfs HA和yarn HA ...
- java大数据最全课程学习笔记(1)--Hadoop简介和安装及伪分布式
Hadoop简介和安装及伪分布式 大数据概念 大数据概论 大数据(Big Data): 指无法在一定时间范围内用常规软件工具进行捕捉,管理和处理的数据集合,是需要新处理模式才能具有更强的决策力,洞察发 ...
- 【原创】大数据基础之Impala(1)简介、安装、使用
impala2.12 官方:http://impala.apache.org/ 一 简介 Apache Impala is the open source, native analytic datab ...
- Ambari配置Hive,Hive的使用
mysql安装,hive环境的搭建 ambari部署hadoop 博客大牛:董的博客 ambari使用 ambari官方文档 hadoop 2.0 详细配置教程 使用Ambari快速部署Hadoop大 ...
随机推荐
- NLP大赛冠军总结:300万知乎多标签文本分类任务(附深度学习源码)
NLP大赛冠军总结:300万知乎多标签文本分类任务(附深度学习源码) 七月,酷暑难耐,认识的几位同学参加知乎看山杯,均取得不错的排名.当时天池AI医疗大赛初赛结束,官方正在为复赛进行平台调 ...
- Design a stack that supports getMin() in O(1) time and O(1) extra space
Question: Design a Data Structure SpecialStack that supports all the stack operations like push(), p ...
- JRE、JDK、JVM 及 JIT 之间有什么不同
java虚拟机(JVM) 使用java编程语言的主要优势就是平台的独立性.你曾经想知道过java怎么实现平台的独立性吗?对,就是虚拟机,它抽象化了硬件设备,开发者和他们的程序的得以操作系统.虚 ...
- leetcode-easy-array-31 three sum
mycode 69.20% class Solution(object): def removeDuplicates(self, nums): """ :type nu ...
- 数据结构和算法(Java版)快速学习(线性表)
线性表的基本特征: 第一个数据元素没有前驱元素: 最后一个数据元素没有后继元素: 其余每个数据元素只有一个前驱元素和一个后继元素. 线性表按物理存储结构的不同可分为顺序表(顺序存储)和链表(链式存储) ...
- oracle 普通数据文件备份与恢复
普通数据文件指:非system表空间.undo_tablespace表空间.临时表空间和只读表空间的数据文件.它们损坏导致用户数据不能访问,不会导致db自身异常.实例崩溃.数据库不恢复就无法启动的情况 ...
- 前端使用Git 切换分支 查看线上远程,本地切换
想要使用Git切换线上分支时先 得先查看线上分支 git branch -a //查看线上分支 git branch //查看本地分支 这是线上的分支图(当前是master) 知道有那些分支就可以进行 ...
- 如何用katalon录制回放一个web UI测试—— katalon学习笔记(四)
,首先打开katanlon,进入到katalon主界面,选择点击file->new->project ,在创建新项目弹出框中Name输入项输入项目的名称:Type选择web,也就是你要测试 ...
- VBA文件操作
做这些东西主要是为了,实现,我们的最终目标. 查到 两个大表里面的变化数据. 所以 这次 ①实现了 文件操作的一部分内容. 包括,excel的打开.分四个步骤. 1.路径 2.打开工作博 3.操作 4 ...
- input函数以及while处理列表和字典
一.函数input()的工作原理 .input()函数:获取输入的字符串 示例: message = input('请输入信息,方便电脑显示') print(message) print('您输入的信 ...