【Spark机器学习速成宝典】基础篇04数据类型(Python版)
目录
Vector
LabeledPoint
Matrix
使用C4.5算法生成决策树
使用CART算法生成决策树
预剪枝和后剪枝
应用:遇到连续与缺失值怎么办?
多变量决策树
Python代码(sklearn库)
|
Vector |
一个数学向量。MLlib 既支持稠密向量也支持稀疏向量,前者表示向量的每一位都存储下来,后者则只存储非零位以节约空间。后面会简单讨论不同种类的向量。向量可以通过mllib.linalg.Vectors 类创建出来
# -*-coding=utf-8 -*-
from pyspark import SparkConf, SparkContext
sc = SparkContext('local') import numpy as np
import scipy.sparse as sps
from pyspark.mllib.linalg import Vectors # Use a NumPy array as a dense vector.使用NumPy数组作为稠密向量
dv1 = np.array([1.0, 0.0, 3.0])
# Use a Python list as a dense vector.使用Python list作为稠密向量
dv2 = [1.0, 0.0, 3.0]
# Create a SparseVector.创建一个稀疏向量<1.0 0.0 2.0 3.0>的两种方式
sv1 = Vectors.sparse(4, {0: 1.0, 2: 2.0})
sv2 = Vectors.sparse(4, [0, 2], [1.0, 2.0])
# Use a single-column SciPy csc_matrix as a sparse vector.使用单列的csc_matrix作为稀疏向量
sv2 = sps.csc_matrix((np.array([10.0, 30.0]), np.array([0, 2]), np.array([0, 2])), shape=(3, 1))
|
LabledPoint |
在诸如分类和回归这样的监督式学习(supervised learning)算法中,LabeledPoint 用来表示带标签的数据点。它包含一个特征向量与一个标签(由一个浮点数表示),位置在mllib.regression 包中。
# -*-coding=utf-8 -*-
from pyspark import SparkConf, SparkContext
sc = SparkContext('local') from pyspark.mllib.linalg import SparseVector
from pyspark.mllib.regression import LabeledPoint # Create a labeled point with a positive label and a dense feature vector.使用稠密向量创建一个带有正标记LabeledPoint
pos = LabeledPoint(1.0, [1.0, 0.0, 3.0]) # Create a labeled point with a negative label and a sparse feature vector.使用稀疏向量创建一个带有负标记LabeledPoint
neg = LabeledPoint(0.0, SparseVector(3, [0, 2], [1.0, 3.0]))
|
Matrix |
矩阵的基类是Matrix,我们提供了两种实现方法:稠密矩阵和稀疏矩阵。建议使用矩阵实现的工厂方法来创建矩阵。
# -*-coding=utf-8 -*-
from pyspark import SparkConf, SparkContext
sc = SparkContext('local') from pyspark.mllib.linalg import Matrix, Matrices # Create a dense matrix ((1.0, 2.0), (3.0, 4.0), (5.0, 6.0))
dm2 = Matrices.dense(3, 2, [1, 2, 3, 4, 5, 6]) # Create a sparse matrix ((9.0, 0.0), (0.0, 8.0), (0.0, 6.0))
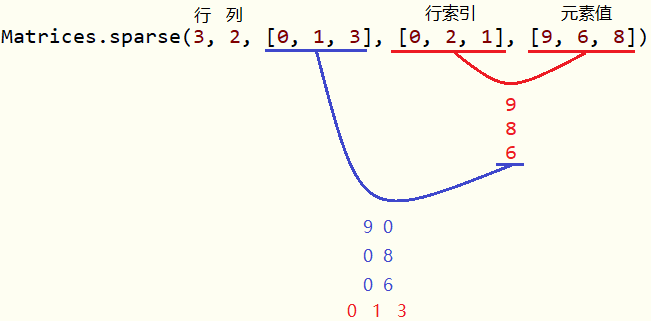
sm = Matrices.sparse(3, 2, [0, 1, 3], [0, 2, 1], [9, 6, 8])
|
什么是决策树(Decision Tree)4 |
引例
现有训练集如下,请训练一个决策树模型,对未来的西瓜的优劣做预测。
|
什么是决策树(Decision Tree)5 |
引例
现有训练集如下,请训练一个决策树模型,对未来的西瓜的优劣做预测。
|
什么是决策树(Decision Tree)6 |
引例
现有训练集如下,请训练一个决策树模型,对未来的西瓜的优劣做预测。
|
什么是决策树(Decision Tree)7 |
引例
现有训练集如下,请训练一个决策树模型,对未来的西瓜的优劣做预测。
|
什么是决策树(Decision Tree)8 |
引例
现有训练集如下,请训练一个决策树模型,对未来的西瓜的优劣做预测。
【Spark机器学习速成宝典】基础篇04数据类型(Python版)的更多相关文章
- 【Spark机器学习速成宝典】基础篇01Windows下spark开发环境搭建+sbt+idea(Scala版)
注意: spark用2.1.1 scala用2.11.11 材料准备 spark安装包 JDK 8 IDEA开发工具 scala 2.11.8 (注:spark2.1.0环境于scala2.11环境开 ...
- 【Spark机器学习速成宝典】模型篇04朴素贝叶斯【Naive Bayes】(Python版)
目录 朴素贝叶斯原理 朴素贝叶斯代码(Spark Python) 朴素贝叶斯原理 详见博文:http://www.cnblogs.com/itmorn/p/7905975.html 返回目录 朴素贝叶 ...
- 【Spark机器学习速成宝典】基础篇02RDD常见的操作(Python版)
目录 引例入门:textFile.collect.filter.first.persist.count 创建RDD的方式:parallelize.textFile 转化操作:map.filter.fl ...
- 【Spark机器学习速成宝典】基础篇03数据读取与保存(Python版)
目录 保存为文本文件:saveAsTextFile 保存为json:saveAsTextFile 保存为SequenceFile:saveAsSequenceFile 读取hive 保存为文本文件:s ...
- 【Spark机器学习速成宝典】模型篇08保序回归【Isotonic Regression】(Python版)
目录 保序回归原理 保序回归代码(Spark Python) 保序回归原理 待续... 返回目录 保序回归代码(Spark Python) 代码里数据:https://pan.baidu.com/s/ ...
- 【Spark机器学习速成宝典】模型篇07梯度提升树【Gradient-Boosted Trees】(Python版)
目录 梯度提升树原理 梯度提升树代码(Spark Python) 梯度提升树原理 待续... 返回目录 梯度提升树代码(Spark Python) 代码里数据:https://pan.baidu.co ...
- 【Spark机器学习速成宝典】模型篇06随机森林【Random Forests】(Python版)
目录 随机森林原理 随机森林代码(Spark Python) 随机森林原理 参考:http://www.cnblogs.com/itmorn/p/8269334.html 返回目录 随机森林代码(Sp ...
- 【Spark机器学习速成宝典】模型篇05决策树【Decision Tree】(Python版)
目录 决策树原理 决策树代码(Spark Python) 决策树原理 详见博文:http://www.cnblogs.com/itmorn/p/7918797.html 返回目录 决策树代码(Spar ...
- 【Spark机器学习速成宝典】模型篇03线性回归【LR】(Python版)
目录 线性回归原理 线性回归代码(Spark Python) 线性回归原理 详见博文:http://www.cnblogs.com/itmorn/p/7873083.html 返回目录 线性回归代码( ...
随机推荐
- centos搭建LAMP
实验环境: [root@nmserver-7 html]# cat /etc/redhat-release CentOS release 7.3.1611 (AltArch) [root@nmserv ...
- Python 第一个程序
第一个程序 打开pycharm,新建一个工程,新建一个文件(后缀为.py) 书写最简单的代码:print(人生苦短,我用python!) 执行python代码 使用pycharm的运行按钮 终端下输入 ...
- PL/SQL Developer13安装教程
参考: https://blog.csdn.net/qs17809259715/article/details/88855617
- WIndows cmd command 指令总结
1. 文件操作 显示当前文件夹内所有文件 dir dir /s 仅显示特定后缀的文件 # 查找当前目录下所有mp3文件dir /s *.mp3
- crt执行cat命令后乱码
cat查看二进制文件后所有命令都乱码执行reset即可恢复
- 如何在python中使用chromedriver
下载对应版本的chromedriver,不知道版本的请参考:https://stackoverflow.com/a/55266105/11128312 接下来将下载的chromedriver.exe放 ...
- 问题-CHM文件不显示
原问题:http://bbs.csdn.net/topics/370230310 问题描述: http://download.csdn.net/download/wybneu/3582721 我从这个 ...
- k8sService资源
一.service资源及其实现模型 通过规则定义出由多个pod对象组合而成的逻辑集合,以及访问这组pod的策略.service关联pod资源的规则要借助于标签选择器来完成 1.service资源概述 ...
- std::this_thread::sleep_until
头文件:<thread> (C++11) template<class Clock, class Duration> void sleep_u ...
- wx小程序知识点(四)
四.页面间数据传递 和 参数传值 (1)页面间数据传递 ① 全局变量 ② 页面跳转或重定向时使用url携带参数(wx.navigateTo(urlStr)) ③ 使用组件模板 template < ...