hbase之RPC详解
Hbase的RPC主要由HBaseRPC、RpcEngine、HBaseClient、HBaseServer、VersionedProtocol 5个概念组成。
1、HBaseRPC是hbase RPC的实现类,核心方法:
1)、RpcEngine getProtocolEngine():返回RpcEngine对象
2)、<T extends VersionedProtocol> T waitForProxy():调用RpcEngine的getProxy()方法,返回一个远程代理对象,比如:第一次访问HRegionServer时需要执行该方法,设置代理后,会缓存该对象到HConnectionImplementation中。
2、RpcEngine接口,其实现类:WritableRpcEngine,核心方法:
1)、VersionedProtocol getProxy():返回代理对象,HRegionServer和HMaster均是VersionedProtocol的实现类,即返回的对象可代理执行HRegionServer和HMaster的方法;
2)、Object[] call():调用程序接口,最终是经过HBaseClient的内部类Connection通过socket方式完成;
3)、RpcServer getServer():返回RpcServer的实现类,有一个抽象实现: HBaseServer和HBaseServer的子类:WritableRpcEngine.Server。
4)、stopProxy()
3、HBaseClient:RPC的client端实现,最核心的方法是call(),通过该方法可执行服务端的方法,该类中有一个重要的内部类:HBaseClient.Connection,该类封装了socket,具体原理就是把要执行的方法通过socket告诉服务端,服务端通过HBaseServer类从socket中读出client端的调用方法,然后执行相关类的相应方法,结果再通过socket传回。
4、HBaseServer:RPC的server端实现,HBaseServer有两个重要的内部类,一个是HBaseServer.Connection,另一个是Handler类,这里的Connection从socket中读出call方法并放入callQueue队列中,Handler类从该队列中取出call方法(比如:scan查询时执行的一次next(),该方法会执行到服务端HRegionServer的next(),这里next就是call方法)并执行,结果通过socket输出给client端,Handler是Thread的子类,在RS启动时就会创建所有的Handle线程,然后一直执行,具体的handler线程数可以通过配置项hbase.regionserver.handler.count配置,默认是10。
5、VersionedProtocol,该接口的类图如下:
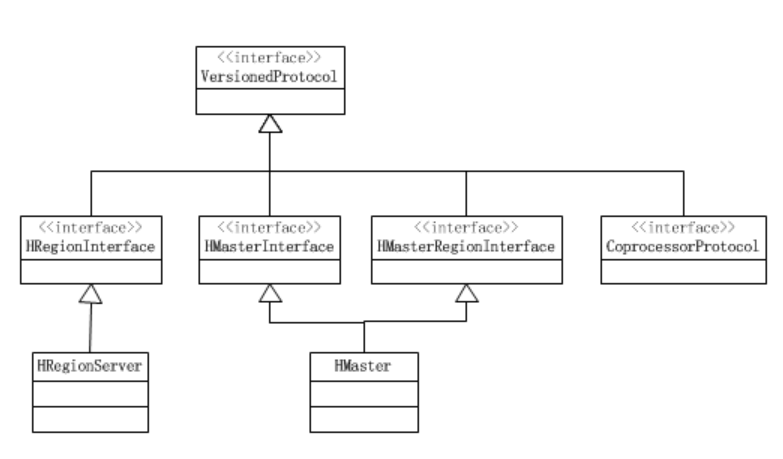
可进行RPC调用的类必须是该接口的实现类,hbase client、 RS、Master相互之间的访问总结为:
HBase Client 通过HMasterInterface接口访问HMasterServer,通过HRegionInterface接口访问HRegionServer;
HRegionServer通过HMasterRegionInterface接口访问HMasterServer;
HMaster通过HRegionInterface接口访问HRegionServer,在访问RS时Master就是HBase Client的角色。
以scan查询为例画时序图,通过时序图详细理解HBase的RPC调用过程
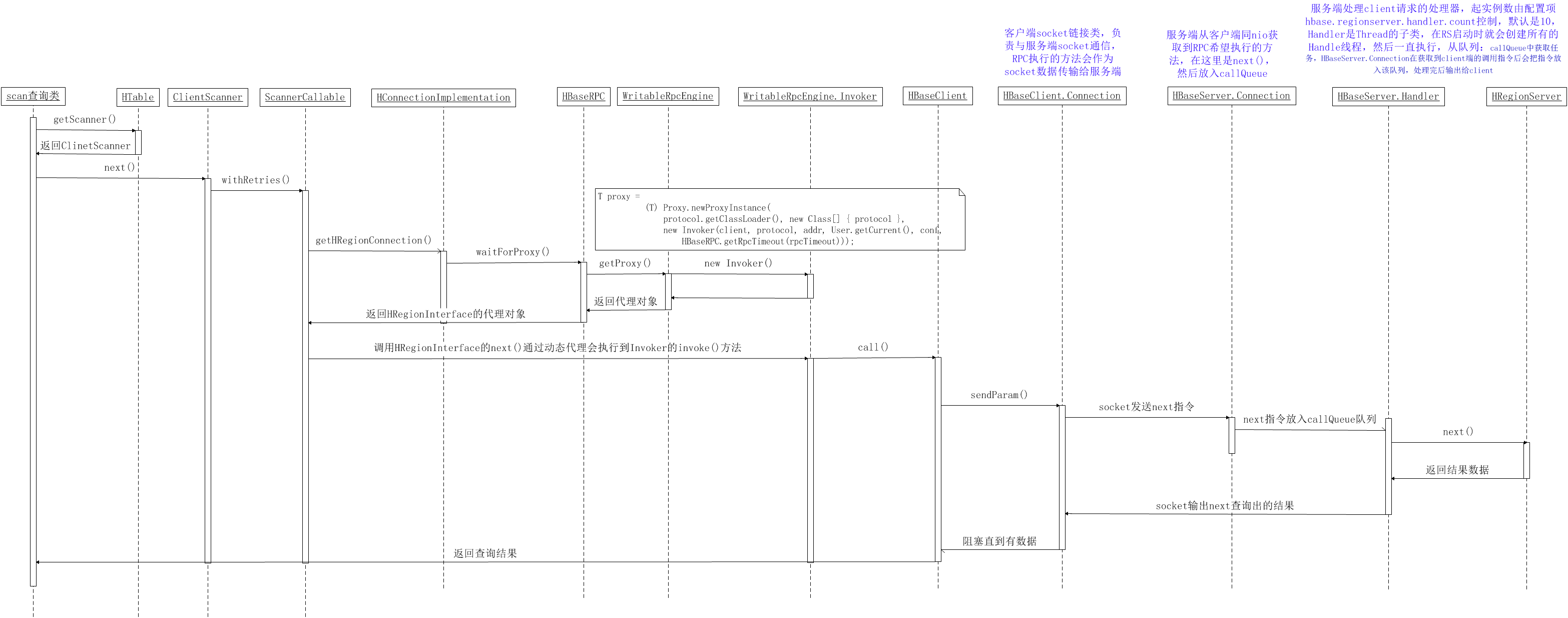
关于HBase的RPC一些知识补充如下:
1、HBaseClient缓存了HBaseClient.Connection,默认一个client应用与每个RS均只有一个socket链接,可以通过以下两个配置项修改:
1)、hbase.client.ipc.pool.type:默认为RoundRobin,共三种,如下:
// PoolMap类的createPool方法,在HBaseClient缓存connection时会调用,从pool中获取connection时,如果缓存的数量没有达到poolMaxSize,
//则会返回null,从而创建新的connection对象
protected Pool<V> createPool() { switch (poolType) { case Reusable: return new ReusablePool<V>(poolMaxSize); //复用的池 case RoundRobin: return new RoundRobinPool<V>(poolMaxSize); //轮询 case ThreadLocal: return new ThreadLocalPool<V>(); //本地线程
}
return null;
}
//PoolMap.RoundRobinPool类的get方法,缓存的数量没有达到poolMaxSize,则会返回null,这时会创建新的connection对象,不同的poolType有不同的实现,
//比如:ReusablePool的get方法是:return poll(); public R get() { if (size() < maxSize) {
return null;
}
nextResource %= size(); R resource = get(nextResource++); return resource; }
2)、hbase.client.ipc.pool.size:socket链接池大小,默认为1
2、详解HBaseClient的getConnection()方法:
//HBaseClient的getConnection方法,默认一个regionserver和一个master均只会建立一个socket链接,
//可以通过修改hbase.client.ipc.pool.size(默认值为1)增加socket链接数,可参看本文档上面几行的内容 protected Connection getConnection(InetSocketAddress addr, Class<? extends VersionedProtocol> protocol, User ticket, int rpcTimeout, Call call) throws IOException, InterruptedException { if (!running.get()) { throw new IOException("The client is stopped"); } Connection connection; //一个regionserver对应一个ConnectionId ConnectionId remoteId = new ConnectionId(addr, protocol, ticket, rpcTimeout); synchronized (connections) { //connections是PoolMap类的实例,如果connections中remoteId对应的链接数量小于hbase.client.ipc.pool.size的配置值则会返回null connection = connections.get(remoteId); if (connection == null) { connection = createConnection(remoteId); //一个regionserver对应一个ConnectionId connections.put(remoteId, connection); } } connection.addCall(call); //如果没有socket链接则建立socket链接 connection.setupIOstreams(); return connection; } //ConnectionId的equals方法 public boolean equals(Object obj) { if (obj instanceof ConnectionId) { ConnectionId id = (ConnectionId) obj; return address.equals(id.address) && protocol == id.protocol && ((ticket != null && ticket.equals(id.ticket)) || (ticket == id.ticket)) && rpcTimeout == id.rpcTimeout; } return false; } //HBaseClient内部类:Connection的setupIOstreams方法,在getConnection()中被调用 protected synchronized void setupIOstreams() throws IOException, InterruptedException { //如果有可用的socket对象则直接返回 if (socket != null || shouldCloseConnection.get()) { return; } if (failedServers.isFailedServer(remoteId.getAddress())) { IOException e = new FailedServerException( "This server is in the failed servers list: " + remoteId.getAddress()); markClosed(e); close(); throw e; } try { setupConnection(); this.in = new DataInputStream(new BufferedInputStream (new PingInputStream(NetUtils.getInputStream(socket)))); this.out = new DataOutputStream (new BufferedOutputStream(NetUtils.getOutputStream(socket))); writeHeader(); // update last activity time touch(); // start the receiver thread after the socket connection has been set up start(); } catch (Throwable t) { failedServers.addToFailedServers(remoteId.address); IOException e; if (t instanceof IOException) { e = (IOException)t; } else { e = new IOException("Could not set up IO Streams", t); } markClosed(e); close(); throw e; } } //HBaseClient内部类:Connection的setupConnection方法,在setupIOstreams ()中被调用 //在这里创建socket对象 protected synchronized void setupConnection() throws IOException { short ioFailures = 0; short timeoutFailures = 0; while (true) { try { this.socket = socketFactory.createSocket(); this.socket.setTcpNoDelay(tcpNoDelay); this.socket.setKeepAlive(tcpKeepAlive); // connection time out is 20s NetUtils.connect(this.socket, remoteId.getAddress(), getSocketTimeout(conf)); if (remoteId.rpcTimeout > 0) { pingInterval = remoteId.rpcTimeout; // overwrite pingInterval } this.socket.setSoTimeout(pingInterval); return; } catch (SocketTimeoutException toe) { /* The max number of retries is 45, * which amounts to 20s*45 = 15 minutes retries. */ handleConnectionFailure(timeoutFailures++, maxRetries, toe); } catch (IOException ie) { handleConnectionFailure(ioFailures++, maxRetries, ie); } } }
3、Hbase有三个链接类:
org.apache.hadoop.hbase.client.HConnection
org.apache.hadoop.hbase.ipc.HBaseClient.Connection
org.apache.hadoop.hbase.ipc.HBaseServer.Connection
l HConnection接口
实现类:HConnectionImplementation,该链接是client与hbase集群这个层面的链接对象,一个集群的一个client就一个该链接对象,在该对象持有
1) RpcEngine对象
2) ZooKeeperWatcher 对象
3) master的RPC代理对象:HMasterInterface
4) regionserver的RPC代理对象:HRegionInterface(一个rs对应一个HRegionInterface代理对象)
5) 缓存的region的location信息
6) 线程池batchPool,batchPool用于HTable的如下方法:

其中批量get查询api:get(List<Get> gets)会调用batch方法,而单条查询get不会,只要是可能涉及多个regionserver的操作均会使用多线程处理,像批量get、批量delete、put,scan一次只能查询一个RS,因此虽然功能上是批量查询数据,但是不需要线程池。
有两个地方均可能创建该批量操作的线程池(注意是线程池不是连接池),分别是HTablePool和HConnectionImplementation,如果通过HTablePool获取HTable对象则采用HTablePool的线程池,如果采用HConnectionImplementation获取HTable对象,则采用HConnectionImplementation的线程池,这个取决于hbase client程序的用法,HTablePool已经是不推荐的方式,0.94.12的版本推荐通过HConnection获取HTable。
// HTable的默认线程池,HTablePool每次创建HTable时均会创建一个直接提交的线程池(采用SynchronousQueue队列),该线程池的特点是不会缓存任务,
//有任务会直接执行,缺点是:如果并发大会导致同时存活大量的线程,优点是不会缓存任务,从而不会存在任务堆积过多导致jvm内存暴涨,不过开启过多的线程也会导致大量的消耗内存 private static ThreadPoolExecutor getDefaultExecutor(Configuration conf) { int maxThreads = conf.getInt("hbase.htable.threads.max", Integer.MAX_VALUE); if (maxThreads == 0) { maxThreads = 1; // is there a better default? } long keepAliveTime = conf.getLong("hbase.htable.threads.keepalivetime", 60); ThreadPoolExecutor pool = new ThreadPoolExecutor(1, maxThreads, keepAliveTime, TimeUnit.SECONDS, new SynchronousQueue<Runnable>(), Threads.newDaemonThreadFactory("hbase-table")); pool.allowCoreThreadTimeOut(true); return pool; } // HConnectionImplementation的默认线程池 private ExecutorService getBatchPool() { if (batchPool == null) { // shared HTable thread executor not yet initialized synchronized (this) { if (batchPool == null) { int maxThreads = conf.getInt("hbase.hconnection.threads.max", Integer.MAX_VALUE); if (maxThreads == 0) { maxThreads = Runtime.getRuntime().availableProcessors(); } long keepAliveTime = conf.getLong("hbase.hconnection.threads.keepalivetime", 60); this.batchPool = new ThreadPoolExecutor(Runtime.getRuntime().availableProcessors(), maxThreads, keepAliveTime, TimeUnit.SECONDS, new SynchronousQueue<Runnable>(), Threads.newDaemonThreadFactory("hbase-connection-shared-executor")); ((ThreadPoolExecutor) this.batchPool).allowCoreThreadTimeOut(true); } this.cleanupPool = true; } } return this.batchPool; }
由源码可以看出:
两个线程池均是采用的直接提交线程池,唯一区别是创建ThreadPoolExecutor对象时指定的corePoolSize不一样,HTablePool是1,HConnection是Runtime.getRuntime().availableProcessors()。
l HBaseClient.Connection和HBaseServer.Connection
这两个Connection链接类是对socket的封装,HBaseClient.Connection类的实例数默认等于1个Master+ RS个数,可以通过hbase.client.ipc.pool.size配置,默认为1,如果是2则client与Master和每个RS均有两个Connection类的实例,也可理解为有2个socket链接,也可配置hbase.client.ipc.pool.type(默认为轮询)修改socket连接池的类型。
总之:HConnection缓存HMasterInterface和HRegionInterface的RPC代理对象,HMasterInterface和HRegionInterface的RPC代理对象最终均是通过Connection类建立的socket与服务端通信, master和每个RS均只对应一个RPC代理对象,每个RPC代理对象默认对应一个Connection对象,一个Connection对象持有一个socket链接。
4、关于参数hbase.regionserver.lease.period:RS的租凭期,RS的租凭设计用于当client端持有RS资源的场景,主要用于scan操作,RS会为client端保留scanner对象,以便多次交互,默认60秒,客户端必须在该时间内向RS发送心跳信息,否则RS认为client是deaded,超过该时间请求RS时,RS会抛出异常,对于scan操作一次next读取相当于一次心跳(参看:Leases类),在client端用该时间作为scan查询时每次next()的超时时间。
5、关于hbase.rpc.timeout配置:每次RPC的超时时间,默认为60000,如果没有超时则等待1s后再重试,直到超时或者重试成功,起三个作用:
1) Socket读数据的超时时间。如果超过超时值,将引发 java.net.SocketTimeoutException具体解释请参考:java.net.Socket.setSoTimeout()的API
2) 控制整个HBaseRPC.waitForProxy()方法的超时时间,在该方法中RPC远程执行HRegionServer的getProtocolVersion()方法,检查client和server端的协议版本,这个过程的总时间不能超过该配置时间,在RPC的过程中涉及建立socket链接和socket通信,因此该时间应该大于或者等于建立链接(ipc.socket.timeout)的时间(socket 通信时间=整体时间),如果小于建立链接的时间,则多导致无用的建立链接等待,就算建立成功但是也会因为整体超时后抛出异常。
3) 在定位root表所在的regionserver地址时,会从zk中获取root表的regionserver信息,该过程的超时时间由该参数控制,当zk不可用等原因时,会返回null,这时就会阻塞直到超时,这个设计应该是有问题,阻塞没有任何意义。
HBaseRPC有setRpcTimeout()方式,在一些场景会通过该方法修改rpc超时时间,通过HBaseRPC的如下方法可以看出,hbase最终采用的时间是编程方式制定的超时时间与hbase.rpc.timeout配置的时间中的最小时间:
//HBaseRPC
public static void setRpcTimeout(int rpcTimeout) {
HBaseRPC.rpcTimeout.set(rpcTimeout);
}
//HBaseRPC
public static int getRpcTimeout(int defaultTimeout) {// defaultTimeout即hbase.rpc.timeout配置的时间
return Math.min(defaultTimeout, HBaseRPC.rpcTimeout.get());
}
//WritableRpcEngine
public <T extends VersionedProtocol> T getProxy(
Class<T> protocol, long clientVersion,
InetSocketAddress addr, Configuration conf, int rpcTimeout)
throws IOException {
T proxy =
(T) Proxy.newProxyInstance(
protocol.getClassLoader(), new Class[] { protocol },
new Invoker(client, protocol, addr, User.getCurrent(), conf,
HBaseRPC.getRpcTimeout(rpcTimeout)));
}
通过编程方式设置rpc超时时间的操作只来自ServerCallable类的beforeCall()方法:
public void beforeCall() {
this.startTime = EnvironmentEdgeManager.currentTimeMillis();
int remaining = (int)(callTimeout - (this.startTime - this.globalStartTime));
if (remaining < MIN_RPC_TIMEOUT) {
remaining = MIN_RPC_TIMEOUT;
}
HBaseRPC.setRpcTimeout(remaining);
}
scan、get、delete等上十个与server交互的操作类均是通过ServerCallable实现。
6、HBase中client与server的socket连接是通过hadoop的org.apache.hadoop.net.NetUtils类实现,在hadoop的1.2.1版本中NetUtils类是基于nio实现socket通信的。
7、关于ipc.socket.timeout:默认20s,该参数控制java.nio.channels.Selector的select(timeout)超时时间,如果20s通道没有就绪则抛出超时异常,也即是socket建立连接的超时时间,读数据的超时时间由hbase.rpc.timeout配置。
8、HBaseClient的call方法
public Writable call(Writable param, InetSocketAddress addr,
Class<? extends VersionedProtocol> protocol,
User ticket, int rpcTimeout) {
Call call = new Call(param);
Connection connection = getConnection(addr, protocol, ticket, rpcTimeout, call);
connection.sendParam(call); // send the parameter
while (!call.done) {
try {
//如果远端调用没有执行完,则会每隔1s钟检查一次,可见是比较低效的。
call.wait(1000);
} catch (InterruptedException ignored) {
interrupted = true;
}
}
hbase之RPC详解的更多相关文章
- HBase 协处理器编程详解,第二部分:客户端代码编写
实现 Client 端代码 HBase 提供了客户端 Java 包 org.apache.hadoop.hbase.client.coprocessor.它提供以下三种方法来调用协处理器提供的服务: ...
- Hadoop生态圈-Hbase的Region详解
Hadoop生态圈-Hbase的Region详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- 全网最详细的hive-site.xml配置文件里如何添加达到Hive与HBase的集成,即Hive通过这些参数去连接HBase(图文详解)
不多说,直接上干货! 一般,普通的情况是 全网最详细的hive-site.xml配置文件里添加<name>hive.cli.print.header</name>和<na ...
- 【甘道夫】HBase基本数据操作详解【完整版,绝对精品】
引言 之前详细写了一篇HBase过滤器的文章,今天把基础的表和数据相关操作补上. 本文档参考最新(截止2014年7月16日)的官方Ref Guide.Developer API编写. 所有代码均基于“ ...
- HBase 协处理器编程详解第一部分:Server 端代码编写
Hbase 协处理器 Coprocessor 简介 HBase 是一款基于 Hadoop 的 key-value 数据库,它提供了对 HDFS 上数据的高效随机读写服务,完美地填补了 Hadoop M ...
- HBase基本数据操作详解【完整版,绝对精品】
欢迎转载,请注明来源: http://blog.csdn.net/u010967382/article/details/37878701 概述 对于建表,和RDBMS类似,HBase也有namespa ...
- 【转载】HBase基本数据操作详解【完整版,绝对精品】
转载自: http://blog.csdn.net/u010967382/article/details/37878701 概述 对于建表,和RDBMS类似,HBase也有namespace的概念,可 ...
- spark RPC详解
前段时间看spark,看着迷迷糊糊的.最近终于有点头绪,先梳理了一下spark rpc相关的东西,先记录下来. 1,概述 个人认为,如果把分布式系统(HDFS, HBASE,SPARK等)比作一个人, ...
- Hbase相关参数详解
转载:http://www.cnblogs.com/nexiyi/p/hbase_config_94.html 版本:0.94-cdh4.2.1 hbase-site.xml配置 hbase.tmp. ...
随机推荐
- .net 学习官网
https://docs.microsoft.com
- 深入理解DiscoveryClient
Spring Cloud Commons 提供的抽象 最早的时候服务发现注册都是通过DiscoveryClient来实现的,随着版本变迁把DiscoveryClient服务注册抽离出来变成了Servi ...
- [Codeforces 316E3]Summer Homework(线段树+斐波那契数列)
[Codeforces 316E3]Summer Homework(线段树+斐波那契数列) 顺便安利一下这个博客,给了我很大启发(https://gaisaiyuno.github.io/) 题面 有 ...
- Numpy Ndarray对象1
标准安装的Python中用列表(list)保存一组值,可以用来当作数组使用,不过由于列表的元素可以是任何对象,因此列表中所保存的是对象的指 针.这样为了保存一个简单的[1,2,3],需要有3个指针和三 ...
- php ecshop采集商品添加规则
ecshop采集商品添加规则 <?phpheader("Content-type:text/html;charset=utf-8"); function get($url) ...
- Zookeeper-技术专区-配置以及学习
zookeeper 一.zookeeper下载 zookeeper下载可以直接去官网进行下载 https://zookeeper.apache.org/releases.html ,可以选择最新版本 ...
- Panabit镜像功能配合wireshark抓包的方法
Panabit镜像功能配合wireshark抓包的方法 Panabit的协议识别都是基于数据包的特征,因此捕获数据包样本是我们进行识别第一步要做的事情.下面就和大家说一下如何捕获网络应用的数据包. 到 ...
- Java加密与解密的艺术 读书心得
现在项目中加密与解密的方式很多,很早就想整理一下Java中加密与解密的方式,读完<<Java加密与解密的艺术>>一书.借此机会梳理一下这方面的知识点 一.基础普及 安全技术目标 ...
- 20180209-xml模块
xml的用法操作如下: xml格式如下: <?xml version="1.0"?> <data> <country name="Liech ...
- JavaScript 中JSON
JSON是JavaScript Object Notation的缩写,它是一种数据交换格式. 在JSON出现之前,大家一直用XML来传递数据.因为XML是一种纯文本格式,所以它适合在网络上交换数据.X ...