MySql数据库优化-汇总
各位,不喜勿喷,和气生财~
数据库优化,是一种综合性的技术,不是通过某一种方式让数据库效率提高很多,而是通过各个方面的优化,来是数据库效率明显的稳步的提高。
主要包括以下:
1、库表的设计优化(三种范式)
2、库表添加合适的索引(普通索引+主键索引+唯一索引+全文索引)
3、分表技术-水平分割与垂直分割
4、读写分离(add/delete/update与select分开)
5、多用存储过程和触发器(模块化编程)
6、优化MqSql配置(配置最大并发数,调整缓存大小,my.ini)
7、SQL优化与慢查询
8、定时清楚垃圾数据,定时进行碎片整理(MyISAM)
除此之外,还有 MqSql服务器硬件升级
以下进行详细描述
题外话:
存储引擎:
MyISAM: 查询速度快,插入速度快,但不支持事务,碎片多;
InnoDB :5.5版本后Mysql的默认数据库,支持事务,支持ACID事务,支持行级锁定;
Memory :所有数据置于内存中,拥有极高的插入,适合频繁的数据更新,更新和查询效率。但是会占用和数据量成正比的内存空间。并且其内容会在Mysql重新启动时丢失,不需要保存滴;
数据库三种模式结构/三级模式
外模式(用户):用户所能看到的数据视图,可通过数据库操纵语言对数据进行操作;
模式(概念):用户视图的最小并集,所有数据的逻辑结构和概念的描述;
内模式(物理):实际存储组合,内部视图,是实际物理存储的抽象;
一、库表设计
良好的数据库设计,能够节省数据库空间,保持数据完整性,方便应用程序的开发;(相反:数据冗余,空间浪费,插入更新繁杂或者异常)
设计数据库
1、充分了解需求:标识实体(具体存在的对象、东西,名词),标识实体属性,标识实体关系
以BBS论坛为例
实体:
用户(属性:昵称,密码,邮箱,生日,性别,登记,备注,积分,注册时间)
主贴(属性:标题,正文,发帖时间,状态,发帖人,回复数量,点击数)
回帖(属性:帖子编号,回帖人,回帖标题,回帖正文,回帖时间,点击数)
板块(属性:板块名称,版主,板块格言,点击数,发帖数)
2、实体关系
一对一,两个表的主键是公共字段
一对多,主键与非主键之间的关系
多对一,非主键与主键之间 的关系
多对多,非主键与非主键之间的关系
3、E-R图,实体-联系图(Entity Relationship Diagram),提供了表示实体类型、属性和联系的方法,用来描述现实世界的概念模型;
*1、创建表时,将实体转化为表,将属性转化为列,唯一标识一行数据的列可为主键,无合适字段做主键就用自动增加列, 将关系转化为主外键展示实体之间的关系;
*2、表结构规范化-三范式(
1、列的原子性。列不可分解,确保每列都不能再分解成更基本的数据单位;
2、记录的唯一标识。给记录增加一个主键,非主键字段依赖主键字段,即表的列中若有重复数据且与主键无关,则可拆分表;
3、字段不存在冗余。不存在传递依赖,即若表的除主键外各个列间有直接关联,即非主键字段一个字段可以推导出另一个字段,则可拆分表
)
范式举例:
山东理工,山东淄博;山大,山东济南;其中山东济南就可以拆分(第一范式)山东理工,山东,淄博;山大,山东,济南;
学号-主,姓名;ID,科目,成绩,学号,姓名;满足第二范式;但不满足第三范式;如果学号非主键,则满足第三范式;
*但注意,也有第五第六等范式,范式越高表越多,查询效率一般就会降低,一般第三范式效率最高列。。
反三范式:学号,语文,数学,英语,总成绩;总成绩字段就是违反第三范式,适当的数据冗余允许,不然就查询效率低了:select sum(yw+sx+yy) from t_score或单独建表 学号,总成绩;
由此可见,数据库的性能效率比规范化更重要;
主键索引,唯一索引见上述链接;
1、主键索引,主键查询时默认使用;
2、组合索引,左边用,右边不用;
3、模糊查询,%或者_写在左边不会用索引,右边会用;
4、条件语句中如果有or,or的两侧均为索引才能使用,否则不会使用;
普通索引与组合索引区别:多个普通索引MySQL只用到认为似乎是最有效率的一个单列索引;组合索引为最左前缀,name-age-city建索引,相当于name,age,age-name,city-name;
主键索引与唯一索引区别:主键执行计划优于唯一,主键索引不能为空,仅一个主键索引列,主键索引更适合自生成不改变的列,主键可被其他列引为外键;
唯一索引,检索到一个直接返回;普通索引,检查是否是全部才返回;
创建索引语法:
create index 索引名称 on 表明 (字段名)
创建全文索引语法:
CREATE fulltext INDEX 索引名称 ON 表明 (字段名)
例子:
- SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('database'); 两个字段的索引:FULLTEXT (title,body)
- SELECT * FROM articles WHERE MATCH (tags) AGAINST ('旅游' IN BOOLEAN MODE);IN BOOLEAN MODE是只有含有关键字就行,不用在乎位置,是不是起启位置.
*仅存储引擎为MyISAM支持全文索引,InnoDB不支持不支持全文索引;
*mysql默认的阀值是50%,当某字段出现次数只有低于50%(停止词)的才会出现在结果集中;(意思是,全文索引用在海量数据中,不存在高于50%的情况)
*fulltext不支持中文,用Sphinx是一个基于SQL的全文检索引擎,结合MySQL,PostgreSQL做全文搜索,他可以提供比数据库本身更专业的搜索功能,使得应用程序更容易实现专业化的全文检索;
三、分表
水平分表:字段不多但是记录行数超级多,达到千万级别,经常检索速度会很慢;按照合理的逻辑去拆分成一个个较小的表,比如按照月份或者类型等待,利于程序简单实现,同时必须考虑到避免union,否则不如不拆分;
垂直分表:记录不多但是字段较多或者较长,占用的空间也比较大,检索需要大量IO,降低性能;拆分时可将较大字段拆分出来,组成一对一的对应关系表;
四、读写分离
数据库服务器压力大时,可以利用主从数据库,对仅仅需要查询,且不特别关注失效性的功能,使用从数据库进行数据的查询;
五、存储过程与触发器
存储过程:可编程的函数,由sql语句和控制结构组成;
sql:需要先编译后执行;存储过程:跨平台和应用使用;速度快,减少网络流量,组件式编程,统一接口参数安全,灵活性差;
#语法
CREATE PROCEDURE 过程名([[IN|OUT|INOUT] 参数名 数据类型[,[IN|OUT|INOUT] 参数名 数据类型…]]) [特性 ...] 过程体
#小示例
CREATE PROCEDURE proc3(IN parameter int)
BEGIN
DECLARE var int;
SET var=parameter+1;
IF var=0 THEN
INSERT INTO t VALUES (17);
END IF ;
IF parameter=0 THEN
UPDATE t SET s1=s1+1;
ELSE
UPDATE t SET s1=s1+2;
END IF ;
END ;
存储过程内的普通变量
#语法:DECLARE 变量名1[,变量名2...] 数据类型 [默认值];
DECLARE x1 VARCHAR(5) DEFAULT 'outer';
变量赋值
#语法:SET 变量名 = 变量值 [,变量名= 变量值 ...]
SET x1=x1+1;
存储过程中的用户变量
#用户变量一般以@开头
SET @y='Goodbye Cruel World';
参与select/update/where语句
SELECT data1,data2 INTO x1,@y FROM test.table1 LIMIT 1;
update test.table1 set data1=@y;
insert into test.table1 (data1,data2)values(x1,@y);
判断语句
#IF分支:
IF 条件1 THEN 语句;
ELSEIF 条件2 THEN 语句;
......
ELSE 语句;
END IF; #CASE分支:
CASE [条件]
WHEN 条件1 THEN 语句1
WHEN 条件2 THEN 语句2
......
ELSE 语句n
END CASE
循环语句
LOOP循环:
LOOP
语句群
END LOOP WHILE语句:
WHILE 条件 DO
语句群
END WHILE REPEAT UNTIL语句:
REPEAT
语句群
UNTIL 条件
END REPEAT
跳转或者终止符
ITERATE 语句: ITERATE只可以出现在LOOP, REPEAT, 和WHILE语句内。ITERATE意思为:“再次循环” 会再次回到label开始位置;
BEGIN
DECLARE v INT;
SET v=0;
LOOP_LABLE:LOOP
IF v=3 THEN
SET v=v+1;
ITERATE LOOP_LABLE;
END IF;
INSERT INTO t VALUES(v);
SET v=v+1;
IF v>=5 THEN
LEAVE LOOP_LABLE;
END IF;
END LOOP;
END; LEAVE语句:这个语句被用来退出任何被标注的流程控制构造。它和BEGIN ... END或循环一起被使用,像其他语言中的break。
开始结束符
[begin_label:] BEGIN
语句群
END [end_label]
七、SQL优化与慢查询
切入点:一个较大的项目,我们想了解当前mysql的运行状态、是否有耗时较长的sql执行等待
1、数据库的增删改查
一般情况下,增删改总计占数据库的10%,而90%是查询操作;
2、show status的相关常用命令
#查看数据库的一些状态
show status;
#显示执行了多少条/次的增删改查
show stauts like 'com_select';
show stauts like 'com_insert';
show stauts like 'com_delete';
show stauts like 'com_update';
#[session|global] 默认是session会话级-只取出当前窗口的执行;global-从mysql启动到现在
show global stauts like 'com_select'; #查询当前MySQL本次启动后的运行统计时间(单位:秒)-另外,存储引擎为MyISAM,且运行时间过长,则注意碎片整理
show status like 'uptime';
#查看试图连接到MySQL(不管是否连接成功)的连接数
show status like 'connections';
#查看线程缓存内的线程的数量。
show status like 'threads_cached'; #慢查询
#查看查询时间超过long_query_time秒的查询的个数-即慢查询
show status like 'slow_queries';
#可以显示当前慢查询时间(单位:秒)(默认10秒)
show variables like 'long_query_time';
#可以修改慢查询时间(单位:秒)
set long_query_time=1;
3、启动MqSql使用记录慢查询日志(2种)
#第一种:中括号[]内的部分是可选的,file_name表示日志文件路径
#在5.5及以上版本的MySQL中,使用如下命令启动:
mysqld --safe-mode --show-query-log[=1] [--show-query-log-file=file_name]
#在5.0、5.1等低版本的MySQL中,使用如下命令启动:
mysqld --log-slow-queries[=file_name] #第二种:启动命令配置到my.ini中的[mysqld]节点
[mysqld]
#设置慢查询界定时间为1秒
long_query_time=1
#5.0、5.1等版本配置如下选项
log-slow-queries="mysql_slow_query.log"
#5.5及以上版本配置如下选项
slow-query-log=On
slow_query_log_file="mysql_slow_query.log"
重启mysql
停止net stop mysql 启动 net start mysql
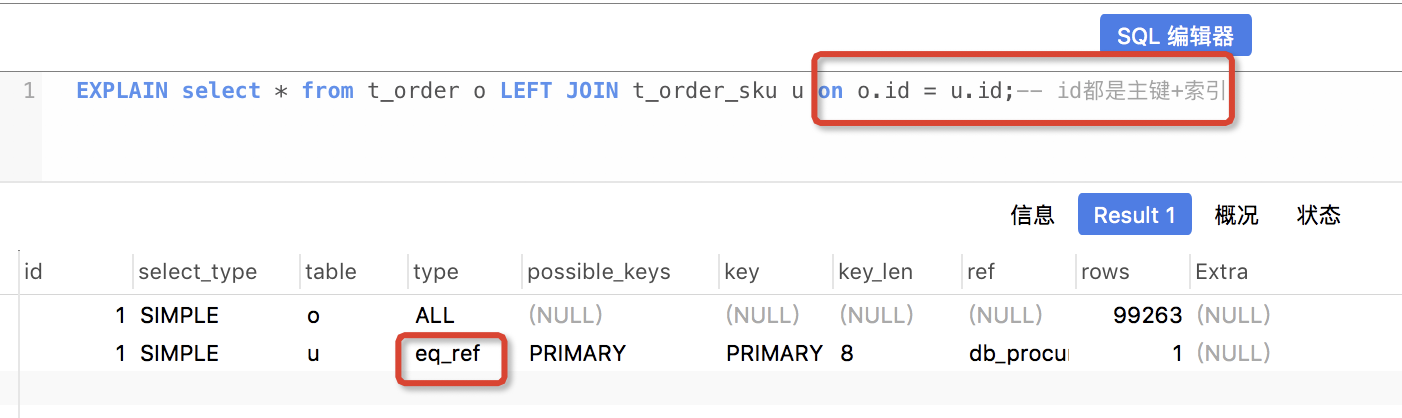
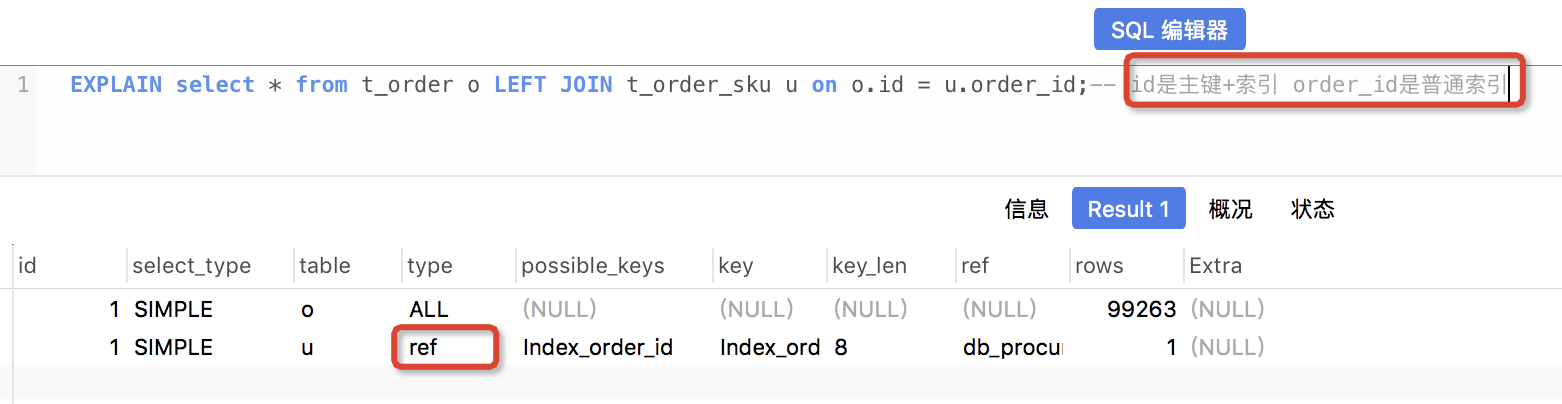
4、explain
explain命令,可以用显示mysql如何使用索引来处理select语句以及连接表;

上述图片中的字段再次描述:
id:查询序号,即执行顺序号,不重要;
select_type:simple 它表示简单的select,没有union和子查询;primary 最外面的select,在有子查询的语句中,最外面的select查询就是primary;union union语句的第二个或者说是后面那一个;
table:显示这一行的数据是关于哪张表的;
possible_keys:可能会使用的索引;
key:实际使用的索引;优化where语句,选择合适的字段或者表字段;
key_len:索引长度,越短越好;
ref:使用某个库表字段 去 匹配表中数据
rows:查询的行数,越小越好;
extra:关于mysql如何解析查询的额外信息
关注当内容显示using temporary,即需要优化sql,因为用到了缓存;--尽力用小表驱动大表
举例:联表排序:驱动表字段排序直接是驱动表排序/非驱动表排序则先合并结果集后排序(指定联接条件时满足查询条件较少数据表为驱动表,不指定联接条件时表数据较少的为驱动表)
type:重要,连接类型:
const 表示:表中最多有一个匹配行,且用到了primary key 或者unique索引;

eq_ref 表示:和前边表查询匹配的值,后边表中最多仅有一个匹配行,且都用到了primary key 或者unique索引,且是最好的表之间的联接类型
ref 表示:和前边表匹配的值,后边表均会取出,且基于的关键字段是索引字段,但不是后边表的primary key 或者unique索引,则为ref,且是较好的表之间的联接类型
八、碎片整理
存储引擎为MyISAM
数据insert会使用其占用空间增加,但delete数据不会是其占用的空间减少,原因:删除数据时,mysql并不会回收被已删除数据的占据的存储空间以及索引位;而是等待新的数据来弥补这个空缺;
语法命令(定期optimize):
#删除数据后的优化 - 碎片整理
optimize table 表名
MySql数据库优化-汇总的更多相关文章
- 关于MySQL数据库优化的部分整理
在之前我写过一篇关于这个方面的文章 <[原创]为什么使用数据索引能提高效率?(本文针对mysql进行概述)(更新)> 这次,主要侧重点讲下两种常用存储引擎. 我们一般从两个方面进行MySQ ...
- 【MySQL】花10分钟阅读下MySQL数据库优化总结
1.花10分钟阅读下MySQL数据库优化总结http://www.kuqin.com2.扩展阅读:数据库三范式http://www.cnblogs.com3.my.ini--->C:\Progr ...
- 30多条mysql数据库优化方法,千万级数据库记录查询轻松解决(转载)
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- 50多条mysql数据库优化建议
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 缺省情况下建立的索引是非群集索引,但有时它并不是最佳的.在非群集索引下,数据在物理上随机存 ...
- 解开发者之痛:中国移动MySQL数据库优化最佳实践(转)
开源数据库MySQL比较容易碰到性能瓶颈,为此经常需要对MySQL数据库进行优化,而MySQL数据库优化需要运维DBA与相关开发共同参与,其中MySQL参数及服务器配置优化主要由运维DBA完成,开发则 ...
- 30多条mysql数据库优化方法【转】
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- 百万行mysql数据库优化和10G大文件上传方案
百万行mysql数据库优化和10G大文件上传方案 最近这几天正在忙这个优化的方案,一直没时间耍,忙碌了一段时间终于还是拿下了这个项目?项目中不要每次都把程序上的问题,让mysql数据库来承担,它只是个 ...
- 从运维角度来分析mysql数据库优化的一些关键点【转】
概述 一个成熟的数据库架构并不是一开始设计就具备高可用.高伸缩等特性的,它是随着用户量的增加,基础架构才逐渐完善. 1.数据库表设计 项目立项后,开发部根据产品部需求开发项目,开发工程师工作其中一部分 ...
- 关于mysql数据库优化
关于mysql数据库优化 以我之愚见,数据库的优化在于优化存储和查询速度 目前主要的优化我认为是优化查询速度,查询速度快了,提高了用户的体验 我认为优化主要从两方面进行考虑, 优化数据库对象, 优化s ...
随机推荐
- 32.把数组排成最小的数(python)
题目描述 输入一个正整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个.例如输入数组{3,32,321},则打印出这三个数字能排成的最小数字为321323. # -*- ...
- python-文件校验
使用hashlib的md5方法对文件进行加密,目的是为了保证文件在传输的过程中是否发生变化. #!/usr/bin/python3 # coding:utf-8 # Auther:AlphaPanda ...
- Spring实例化相关问题
1.当Controller或者Service使用new来实例化时,能不能正常调用使用Resource声明的变量 不能,使用new来实例化时,所有使用Resource声明的变量均为null
- 大哥带的XSS练习LEVE2
0X01输出在html标签中的XSS 这里相当于我们把XSS代码插入到了 html中的<td>标签中 其他好看的 但是不是同源访问 <script> var body= doc ...
- sqli-labs(40)
0X01同样是构造闭合 这里的闭合条件是') 构造语句 ?id=');insert into users values(100,'tx','tx')%23 在客户端mysql里面看看 嘿嘿 成功执行 ...
- DVWA--File Inclusion(不能远程包含的问题解决)
然后别以为这样就完了 我被这样坑了一下午 找到你对应版本的php 进去Ctrl+f 搜索url_allow——fopen 和include
- Zookeeper入门(五)之Linux环境下Zookeeper安装
本文参考地址为:http://www.mamicode.com/info-detail-2243059.html1.安装wget http://archive.apache.org/dist/zook ...
- Springboot 使用 webSocket
介绍 WebSocket是HTML5开始提供的一种在单个 TCP 连接上进行全双工通讯的协议.在WebSocket API中,浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接,并进 ...
- MySQL学习笔记(cmd模式下的操作)
1.登入MySQL 1.1 登入MySQL 1.1.1命令如下: C:\Users\zjw>mysql -hlocalhost -uroot -p Enter password: ****** ...
- js函数收集
常见js函数收集: 转自:http://www.qdfuns.com/notes/36030/2eb2d45cccd4e62020b0a6f0586390af.html //运动框架 function ...