启用hdfs的高可用
cm-HDFS:
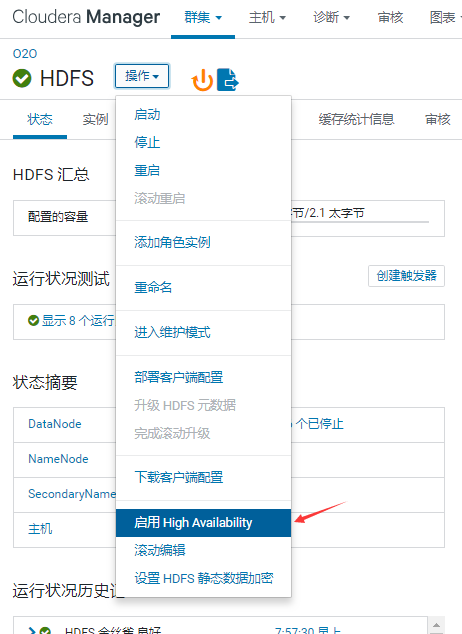
选择另外一个节点的做NN, 生产选node3
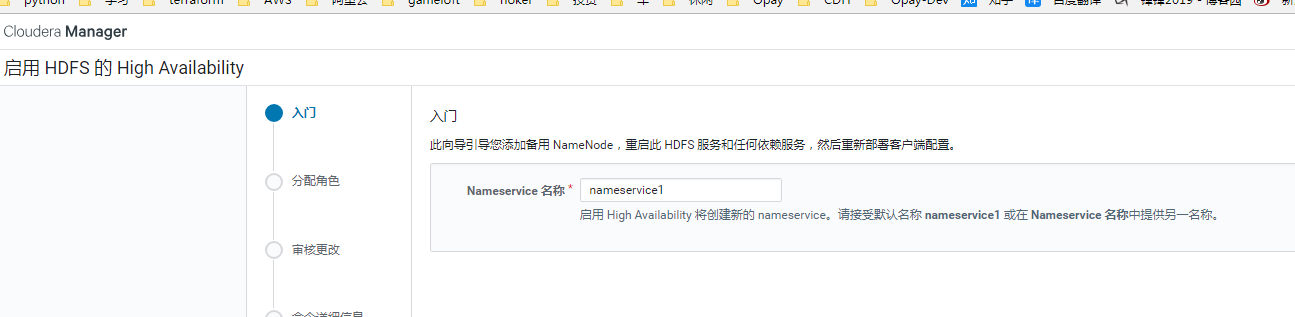
选择三个节点作journalNode, node2,3,4
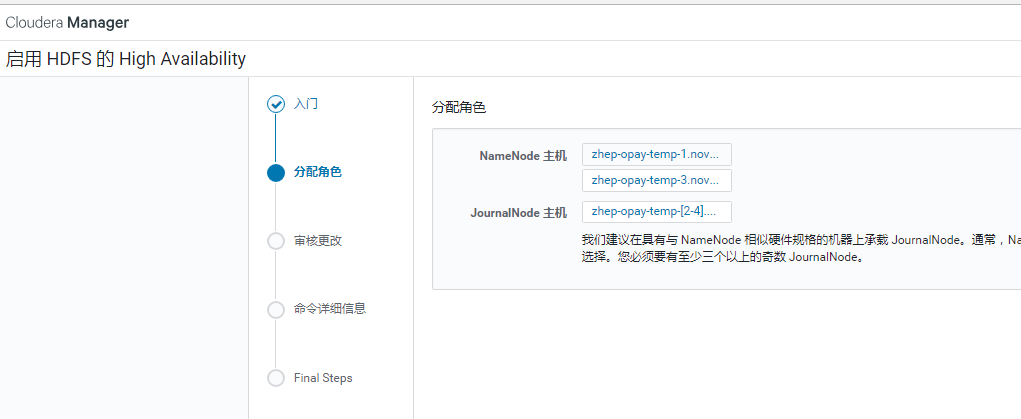
填入journalNode的目录/dfs/jn
经过一系列步骤,如果没报错
点继续:
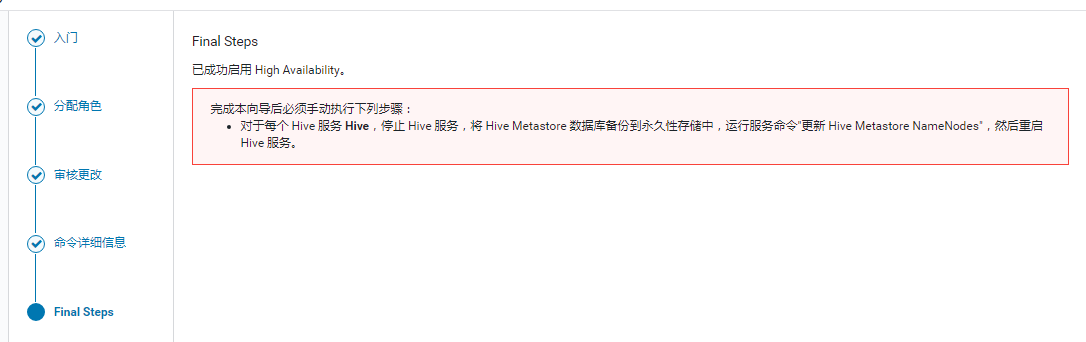
停止所有hive服务:
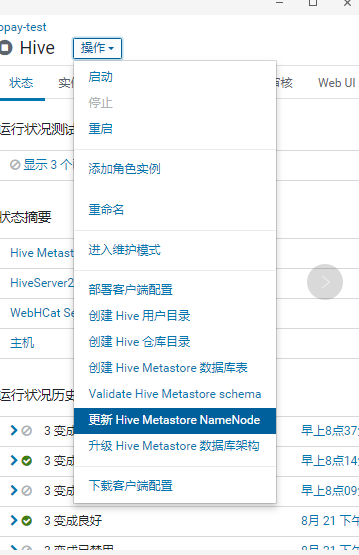
注: 生产的数据量比较大, 更新花费的时间比较长6-8个小时
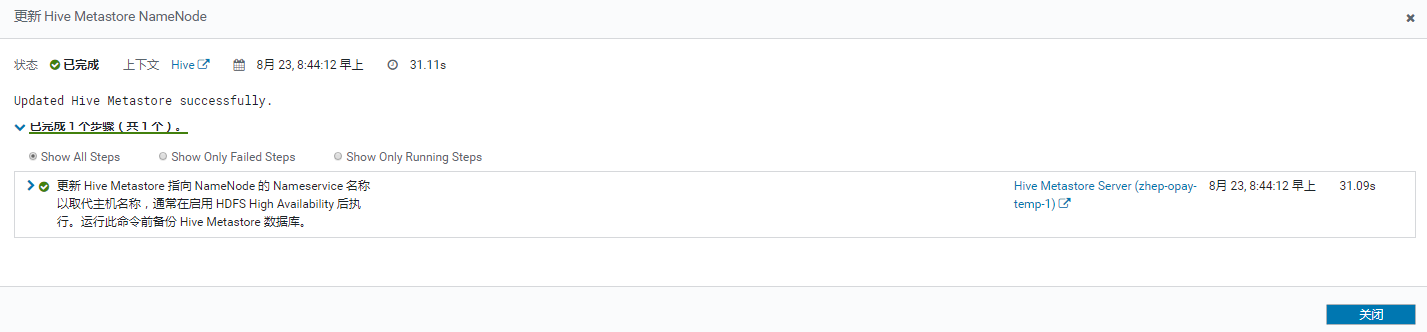
重启hive服务:
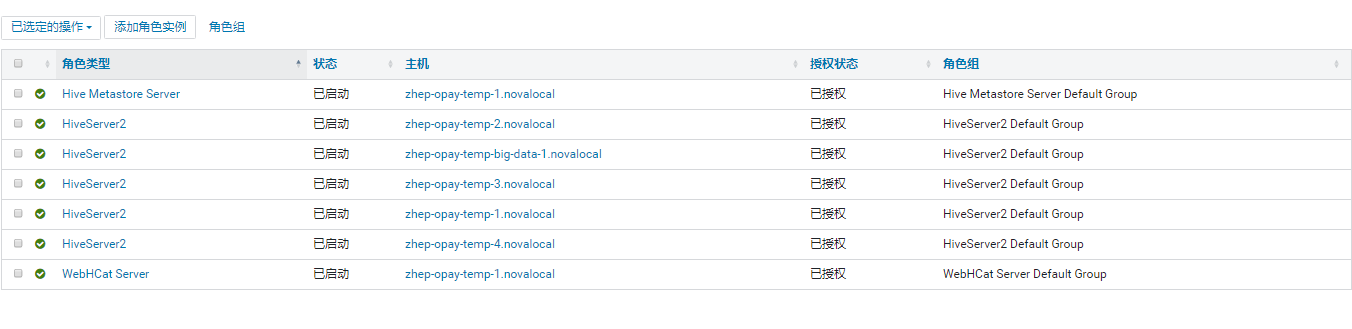
再看hdfs看到新出现的服务:
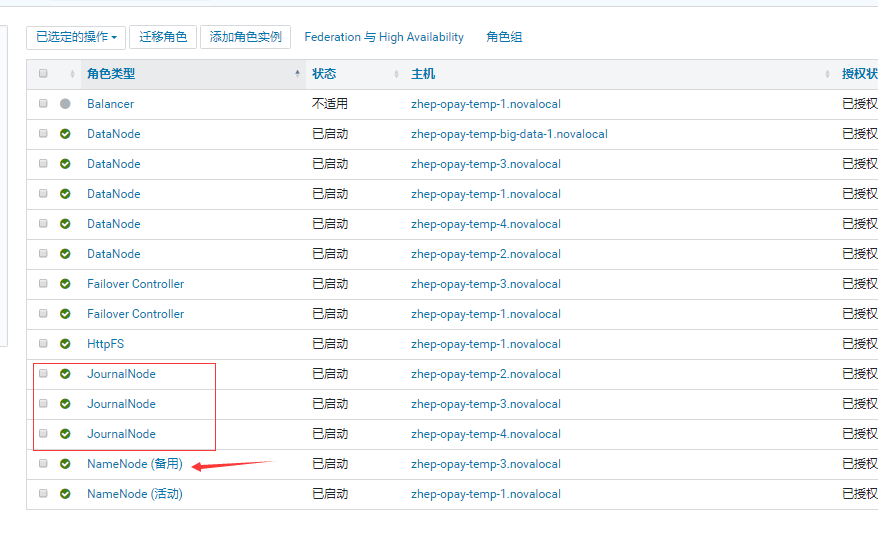
注意:
1/ 高可用启用后,hdfs入口地址发生变化,如代码里有配的,需从node4.datalake.opay.com:8020改为集群地址warehourse:8020或warehourse
即: hdfs://node4.datalake.opay.com:8020 改为hdfs://warehourse
2/ 使用hue, web界面角色要改为活动的NN,用备用NN在hue中使用hdfs会有问题

启用hdfs的高可用的更多相关文章
- 大数据学习(03)——HDFS的高可用
高可用架构图 先上一张搜索来的图. 如上图,HDFS的高可用其实就是NameNode的高可用. 上一篇里,SecondaryNameNode是NameNode单节点部署才会有的角色,它只帮助NameN ...
- Hadoop 2、配置HDFS HA (高可用)
前提条件 先搭建 http://www.cnblogs.com/raphael5200/p/5152004.html 的环境,然后在其基础上进行修改 一.安装Zookeeper 由于环境有限,所以在仅 ...
- 启用yarn的高可用
选择高可用的主机,新的一台: 点运行结束后,会看到实例会多出一个备用的节点:
- HDFS namenode 高可用(HA)搭建指南 QJM方式 ——本质是多个namenode选举master,用paxos实现一致性
一.HDFS的高可用性 1.概述 本指南提供了一个HDFS的高可用性(HA)功能的概述,以及如何配置和管理HDFS高可用性(HA)集群.本文档假定读者具有对HDFS集群的组件和节点类型具有一定理解.有 ...
- 大数据(3) - 高可用 HDFS HA
HDFS HA高可用 1 HA概述 1)所谓HA(high available),即高可用(7*24小时不中断服务). 2)实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件的HA机制 ...
- HDFS高可用实现细节
NameNode 高可用整体架构概述 在 Hadoop 1.0 时代,Hadoop 的两大核心组件 HDFS NameNode 和 JobTracker 都存在着单点问题,这其中以 NameNode ...
- HDFS 09 - HDFS NameNode 的高可用机制
目录 1 - 为什么要高可用 2 - NameNode 的高可用发展史 3 - HDFS 的高可用架构 3.1 Standby 和 Active 的命名空间保持一致 3.2 同一时刻只有一个 Acti ...
- Hadoop高可用集群
1.简介 若HDFS集群中只配置了一个NameNode,那么当该NameNode所在的节点宕机,则整个HDFS就不能进行文件的上传和下载. 若YARN集群中只配置了一个ResourceManager, ...
- spark高可用集群搭建及运行测试
文中的所有操作都是在之前的文章spark集群的搭建基础上建立的,重复操作已经简写: 之前的配置中使用了master01.slave01.slave02.slave03: 本篇文章还要添加master0 ...
随机推荐
- STM32的系统时钟设置SystemClock_Config()探究
一.首先了解几个硬件名词: stm32有多种时钟源,为HSE.HSI.LSE.LSI.PLL,对于L系统的,还有一个专门的MSI 1.HSE是高速外部时钟,一般8M的晶振,精度比较高,比较稳定. 2. ...
- [人物存档]【AI少女】【捏脸数据】气质学生
点击下载(城通网盘): AISChaF_20191119010459547.png
- js new Date() 测试
var t = new Date().toString(); //t = "Thu Oct 31 2019 11:36:57 GMT+0800 (中国标准时间)" var t1 = ...
- .net core 下载文件 其他格式
app.UseStaticFiles(); app.UseStaticFiles(new StaticFileOptions { //FileProvider = new PhysicalFilePr ...
- 用CSS如何实现单行图片与文字垂直居中
图片样式为 以下为引用的内容:.style img{vertical-align:middle;.....} 如果STYLE中有其它如INPUT或其它内联元素可写成 以下为引用的内容:.style i ...
- hdu 1081 dp问题:最大子矩阵和
题目链接 题意:给你一个n*n矩阵,求这个矩阵的最大子矩阵和 #include<iostream> #include<cstdio> #include<string.h& ...
- JAVA静态方法是否可以被继承
结论:java中静态属性和静态方法可以被继承,但是没有被重写(overwrite)而是被隐藏.原因:1). 静态方法和属性是属于类的,调用的时候直接通过类名.方法名完成对,不需要继承机制及可以调用.如 ...
- 「TJOI2019」大中锋的游乐场
题目链接 问题分析 比较明显的最短路模型.需要堆优化的dij.建图的时候注意细节就好. 参考程序 #include <bits/stdc++.h> #define LL long long ...
- 作业要求20191010-3 alpha week 1/2 Scrum立会报告+燃尽图 01
此作业要求参见:https://edu.cnblogs.com/campus/nenu/2019fall/homework/8746 一.小组情况组长:贺敬文组员:彭思雨 王志文 位军营 杨萍队名:胜 ...
- MYSQL中唯一约束和唯一索引的区别
1.唯一约束和唯一索引,都可以实现列数据的唯一,列值可以有null.2.创建唯一约束,会自动创建一个同名的唯一索引,该索引不能单独删除,删除约束会自动删除索引.唯一约束是通过唯一索引来实现数据的唯一. ...