Dataphin帮助企业构建数据中台系列之--萃取数据中心
Dataphin作为阿里巴巴数据中台OneData (OneModel、OneID、OneService)方法论的产品载体,帮助企业构建三大数据中心:基于数据集成形成的垂直数据中心、基于数据开发沉淀的公共数据中心和基于标签工厂构建的萃取数据中心。今天我们就一起来看看,Dataphin是如何基于OneID思想构建数据萃取中心,连接上下游应用为企业创造更多价值的吧~
为什么要建立萃取数据中心:提升数据价值密度
首先,我们来看看Dataphin为什么要帮助企业构建自己的萃取数据中心?
大数据时代,任何微小的数据都可能产生不可思议的价值。作为智能数据构建与管理平台,Dataphin的规范建模、数据处理等核心功能帮助企业高效整合来自不同业务数据库的海量数据,沉淀数据资产,构建自己的数据中台,应对大数据时代Volume(大量)、Variety(多样)、Velocity(高速)方面的挑战。然而,相比于传统的小数据,大数据更大的价值在于从海量不相关的各类数据中,挖掘出对预测分析有参考意义的数据,提升数据价值密度并应用于指导生产,从而帮助企业实现提效降本的目的。Dataphin的数据萃取功能正提供了这样的能力。
从业务视角来看,日常生产和营销活动中,不管是人群圈选、选址还是个性化投放,都离不开标签的指导。标签是对一个实体的立体刻画(不局限于人,任何可被描述和分析的存在都可以是实体,如商品、公司等)。不同维度的标签从不同角度对实体进行描述,例如以零售视角为切入点,我们可以从自然属性(如性别、年龄)、社会属性(如经济状况、婚姻状态)、兴趣偏好(如喜欢整洁的环境、希望有漂亮的牙齿)和行业消费偏好(如美妆偏好、母婴偏好)来对消费者进行描述。高质量、全面的标签能够有效地抽象出一个实体的信息全貌,为精准营销奠定了基础。
数据只有融通才能产生更大的价值,我们不仅希望可以分析和应用大数据,更希望得到通过跨业务单元连接起来的数据和精细化萃取的数据。这种情况下,Dataphin数据萃取模块基于业务数据库的原始数据和建模研发等沉淀的数据资产,将全系统中主数据——即贯穿各个隔离业务的核心对象,进行识别与关联连接,打通业务数据孤岛,进一步提炼可直接应用的高价值标签数据,从而帮助企业构建自己的萃取数据中心,并对接上游应用(QuickAudience等)进一步指导生产营销活动。
如何高效建立萃取数据中心:可视化配置,自动化生产
Dataphin研发模块下的数据萃取为我们提供了连接行为数据并实现标签萃取的功能,现阶段优先支持以消费者为对象的数据体系,功能模块主要包括3 大部分:ID中心、行为中心和标签中心(目前ID中心暂未上线)。此外,运维模块下还提供单独的萃取运维子模块,支持从业务视角查看萃取相关的调度任务。下面,我们将从几个功能模块的视角给大家介绍Dataphin如何帮助企业构建自己的萃取数据中心。
1)ID中心:相关ID自动化识别与连接
Dataphin基于OneID的思想,以唯一标识打通来自不同平台、系统、渠道的数据,支持通过可视化界面参数配置的方式,从所有数据中提炼并基于算法自动识别各类型ID 之间的映射关系(购物会员ID、视频观看者ID、购物设备mac、观看设备IP 等),并将属于同一实体的不同类型ID通过唯一的One ID进行连接,使得基于ID生产的标签可以聚合到同一实体,从而对实体进行更精准、全面的刻画。
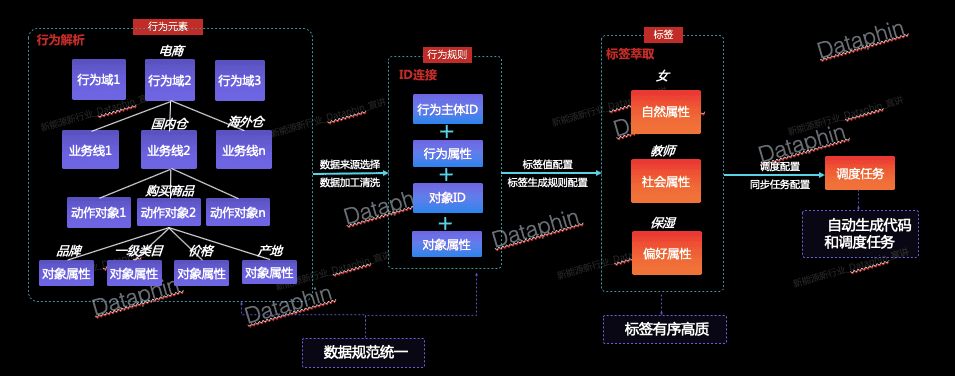
2)行为中心:沉淀行为元素,构建行为规则
Dataphin目前支持以人的相关ID 为中心,通过可视化界面表单配置的方式,从来源行为数据中提炼进而聚拢不同业务域下的行为数据(如电商购物、视频观看)。
首先,我们需要从业务视角对行为数据进行梳理,从中提炼出可复用的行为元素(行为域、业务线、动作、对象、对象属性),并通过对行为元素进行组合定义不同的行为(行为域-业务线-动作-对象)。行为域聚合业务含义一致的行为数据,如电商域、文娱域;业务线基于行为域将行为数据进一步细分,各业务线之间相对独立,如淘宝业务线、天猫业务线;动作指行为主体发出的操作,如购买、浏览;对象指行为主体操作的具体事物,如商品、电影;对象属性是对象的描述性信息,如名称、品牌、年份。通过抽取沉淀行为元素,我们可以将来源数据更好地进行划分组合以得到具有明确业务含义的行为,如电商域-淘宝-购买-商品、文娱域-优酷-浏览-电影。通过沉淀行为元素,我们可以更好地规范来源数据,并减少重复建设和人力投入。

给同一行为选择不同的来源表并添加配置,即生成不同的行为规则(由行为+来源表唯一确定),后续标签生产将依赖已经构建的行为和行为规则。规则配置主要包括行为主体ID、对象、对象属性和行为发生次数,从来源表选择相应的字段,再通过行为规则的周期调度任务,我们就能得到持续更新的行为数据作为标签生产的来源。

3)标签中心:高效标签生产
构建完成行为和行为规则后,进一步地,我们将基于算法模型,通过简单的界面配置定义标签的生成规则。
标签的配置分为两大步骤:第一步首先基于定义的行为圈选出某标签需要依赖的行为数据,接着对预期得到的标签值和打标方式进行配置;第二步需要对已选的行为数据设置时间衰减模式,并基于业务含义给不同的行为分配不同的权重。例如,我们认为“购买母婴用品”和“观看亲子视频”的用户都可以被打上“母婴人群”的标签,那么第一步,我们将这两种行为相关的数据都勾选出来,设置预期标签值为“母婴人群”;第二步,我们认为近期的行为比之前发生的行为更有参考性,因此选择线性衰减模式,给近期行为赋予更大的时间权重;同时,基于业务经验,我们认为“购买母婴用品”比“观看亲子视频”更能精确定位到目标用户,所以给“购买母婴用品”行为分配更大的权重。这样,我们就完成了“母婴人群”这样一个购物偏好标签的生产。

不同于传统标签生产,Dataphin数据萃取的用户只需要关心标签的具体业务含义和规则,而不用关心底层算法的实现,通过简单的界面操作即可完成标签的配置,并自动生成代码和周期调度任务,极大程度上降低了标签生产的难度和门槛。
4)萃取运维
最后,我们在萃取模块配置的行为规则和标签都会生成自动化调度的周期任务。在“运维”界面的“萃取运维”子模块下,我们可以从业务视角更清晰明了地查看相应任务和对应生成的实例,并针对异常调度通过补数据等操作回复生产。如此一来,业务人员也可以配置并查看萃取任务,大大降低了对技术人员的依赖。

总结
Dataphin数据萃取功能上线后,批量生产十几个同类型的标签的时间从两周缩短到两天左右,而且可以监控标签生产任务,不管是速度还是正确性上都得到了很大的提升;参与的人员也从原本的数据产品经理、数据研发工程师、数据科学家为主导转变为更多的业务角色可以参与甚至主导。
Dataphin萃取数据中心的建立,帮助企业更好的实现了目标对象相关ID 的识别与连接、目标对象所有行为的规范化结构化聚集和目标对象相关标签属性的快速创建,从而快速构建企业自己用户数据资产,以便对接数据应用类产品,实现营销投放等。
看了这些介绍,是不是对Dataphin的数据萃取功能充满了期待和信心?那就快来体验一下吧~更多Dataphin的惊喜等你来挖掘!
结语:
阿里巴巴数据中台团队,致力于输出阿里云数据智能的最佳实践,助力每个企业建设自己的数据中台,进而共同实现新时代下的智能商业!
阿里巴巴数据中台解决方案,核心产品:
Dataphin,以阿里巴巴大数据核心方法论OneData为内核驱动,提供一站式数据构建与管理能力;
Quick BI,集阿里巴巴数据分析经验沉淀,提供一站式数据分析与展现能力;
Quick Audience,集阿里巴巴消费者洞察及营销经验,提供一站式人群圈选、洞察及营销投放能力,连接阿里巴巴商业,实现用户增长。
本文作者:陈梦婷
本文为云栖社区原创内容,未经允许不得转载。
Dataphin帮助企业构建数据中台系列之--萃取数据中心的更多相关文章
- 阿里大数据产品Dataphin上线公共云,将助力更多企业构建数据中台
日前,由阿里数据打造的智能数据构建与管理Dataphin,重磅上线阿里云-公共云,开启智能研发版本的公共云公测!在此之前,Dataphin以独立部署方式输出并服务线下客户,已助力多家大型客户高效自动化 ...
- 如何通过Dataphin构建数据中台新增100万用户?
欢迎来到数据中台小讲堂!这一期我们来看看,作为阿里巴巴数据中台(OneData - OneModel.OneID.OneService)方法论的产品载体,Dataphin如何帮助传统零售企业实现数字化 ...
- CTO与CIO选型数据中台的几大建议
企业数字化转型离不开企业数字化技术的配备.但企业在选择数字化技术时也面临着一个问题,就是如何在大胆采用先进的数字化技术和对技术进行投资之间找到平衡,将投资风险降到最低,毕竟错误的技术选型会给企业带来不 ...
- 阿里云智能数据构建与管理 Dataphin公测,助力企业数据中台建设
阿里云智能数据构建与管理 Dataphin (下简称“Dataphin”)近日重磅上线公共云,开启智能研发版本的公共云公测!在此之前,Dataphin以独立部署方式输出并服务线下客户,已助力多家大型客 ...
- Dataphin数据服务系列之--API 配置、管理和消费
研发小哥哥还在为公司里大量 API 只上不下,不可查不可用, 想找的 API 找不到而苦恼吗?业务方小姐姐还在为 API 开发时间长,业务相应不及时而抱怨吐槽吗? 铛铛铛,Dataphin 数据服务 ...
- 奇点云数据中台技术汇(三)| DataSimba系列之计算引擎篇
随着移动互联网.云计算.物联网和大数据技术的广泛应用,现代社会已经迈入全新的大数据时代.数据的爆炸式增长以及价值的扩大化,将对企业未来的发展产生深远的影响,数据将成为企业的核心资产.如何处理大数据,挖 ...
- OPPO数据中台之基石:基于Flink SQL构建实数据仓库
小结: 1. OPPO数据中台之基石:基于Flink SQL构建实数据仓库 https://mp.weixin.qq.com/s/JsoMgIW6bKEFDGvq_KI6hg 作者 | 张俊编辑 | ...
- 数据中台技术汇(二)| DataSimba系列之数据采集平台
继上期数据中台技术汇栏目发布DataSimba——企业级一站式大数据智能服务平台,本期介绍DataSimba的数据采集平台. DataSimba采集平台属于DataSimba的数据计算及服务平台的一部 ...
- 奇点云数据中台技术汇(四)| DataSimba系列之流式计算
你是否有过这样的念头:如果能立刻马上看到我想要的数据,我就能更好地决策? 市场变化越来越快,企业对于数据及时性的需求,也越来越大,另一方面,当下数据容量呈几何倍暴增,数据的价值在其产生之后,也将随 ...
随机推荐
- leetcode 155. 最小栈(c++)
设计一个支持 push,pop,top 操作,并能在常数时间内检索到最小元素的栈. push(x) -- 将元素 x 推入栈中.pop() -- 删除栈顶的元素.top() -- 获取栈顶元素.get ...
- python数据类
前言 之前有写过一篇python元类的笔记,元类主要作用就是在要创建的类中使用参数metaclass=YourMetaclass调用自定义的元类,这样就可以为所有调用了这个元类的类添加相同的属性了. ...
- Invoke和BeginInvoke的区别(转载)
转自http://www.cnblogs.com/c2303191/articles/826571.html Control.Invoke 方法 (Delegate) :在拥有此控件的基础窗口句柄的线 ...
- 题解1235. 洪水 (Standard IO)
Description 一天, 一个画家在森林里写生,突然爆发了山洪,他需要尽快返回住所中,那里是安全的.森林的地图由R行C列组成,空白区域用点“.”表示,洪水的区域用“*”表示,而岩石用“X”表示, ...
- SpringMVC请求处理流程源码
我们首先引用<Spring in Action>上的一张图来了解Spring MVC 的核心组件和大致处理流程: 从上图中看到①.DispatcherServlet 是SpringMVC ...
- knn原理及借助电影分类实现knn算法
KNN最近邻算法原理 KNN英文全称K-nearst neighbor,中文名称为K近邻算法,它是由Cover和Hart在1968年提出来的 KNN算法原理: 1. 计算已知类别数据集中的点与当前点之 ...
- IDEA永久破解方法
链接: https://pan.baidu.com/s/1a1pMOP6rMrh-wJdUFSCqAw 提取码: 46cx 复制这段内容后打开百度网盘手机App,操作更方便哦
- 2019牛客暑期多校训练营(第一场) - B - Integration - 数学
https://ac.nowcoder.com/acm/contest/881/B https://www.cnblogs.com/zaq19970105/p/11210030.html 试图改写多项 ...
- 如何写一个简单的基于 Qt 框架的 HttpServer ?
httpserver.h #ifndef HTTPSERVER_H #define HTTPSERVER_H #include <QObject> #include <QtCore& ...
- 自定义InputFormat
回顾: 在上一篇https://www.cnblogs.com/superlsj/p/11857691.html详细介绍了InputFormat的原理和常见的实现类.总结来说,一个InputForma ...