docker高级篇2-分布式存储之三种算法
面试题:
1~2亿条数据需要缓存,请问如何设计这个缓存案例?
答:单机单台100%是不可能的。肯定是分布式缓存的。那么用Redis如何落地?
一般有三种方案:
哈希取余分区;一致性哈希算法分区;哈希槽分区。如下图:

大家好,我是凯哥Java(kaigejava),乐于分享,每日更新技术文章,欢迎大家关注“凯哥Java”,及时了解更多。让我们一起学Java。也欢迎大家有事没事就来和凯哥聊聊~~~
哈希取余分区:
对redis的key进行hash后和机器总数取余。公式:has(key)%N
这种分区算法的优点:
简单粗暴,直接有效。只需要预估好数据规划好节点。就能保证一段时间的数据支撑。使用HASH算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求,起到负载均衡+分而治之的作用。
缺点:
原来规划后的节点,进行扩容或者缩容就比较麻烦了。不管是扩容还是缩容,每次数据变更导致几点有变动,映射关系需要重新进行计算。在服务器个数固定不变的时候没问题。如果需要弹性扩容或者故障停机的情况下,原来的取模公式就会发生变化。此时地址经过某个redis机器宕机了。由于机器总数量发生了变化,会导致hash取余全部数据重新洗牌啊!!
一致性哈希算法分区:
一致性hash算法是什么?
一致性hash算法在1997年麻省理工学院提出的,设计目标是为了解决:
分布式缓存数据变动和映射问题。某个机器宕机了,分母数量改变了,自然取余就出问题了。
一致性hash算法能干嘛?
提出一致性hash解决方案。目的是当服务器个数发生变动的时候,尽量减少影响客户端到服务器的映射关系。
都有哪些步骤?
3大步骤。
1:算法构建一致性哈希环;
一致性哈希算法必然有个hash函数并安装算法产生hash值,这个算法的所有可能哈希值会构成一个全量集,这个集合可以成为hash空间,范围是[0,2^32-1],这是一个线性空间,但是在算法中,通过适当的逻辑控制将其首尾相连(0=2^32),这样在逻辑上,就形成了一个环形的空间。
一致性哈希环也是使用的取模的方方,是对2^32取模。一致性hash算法将这个哈希值空间组织成一个虚拟的圆环,整个哈希环是按照顺时针方法组织的。如下图:
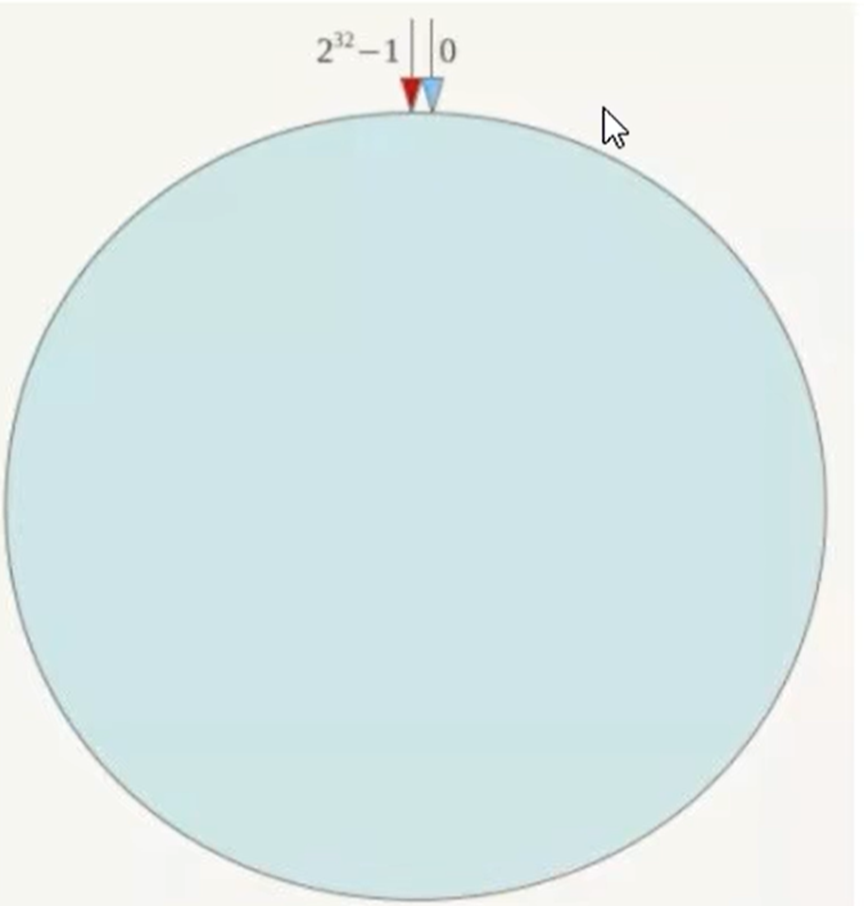
2:服务器IP节点映射
将集群中的各个IP节点映射到环上的某一个位置。将各个服务器使用hash进行一个hash.(具体可以选择服务器的IP或者主机名称作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置)。例如4个节点NodeA、B、C、D,经过IP地址的哈希环上计算(hash(ip)),使用IP地址哈希后环空间位置如下图:
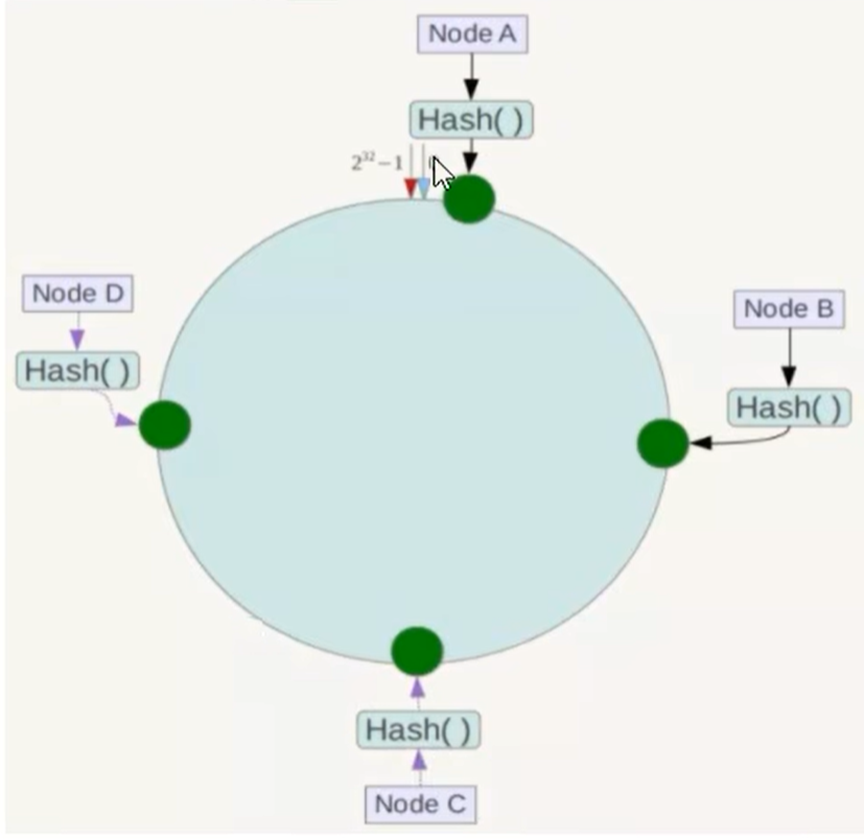
3:key落到服务器的落键规则
hash环构建了、服务器IP节点也映射了,那么当我们需要存储一个KV键值对的时候,先要计算的是key对应的hash值(hash(key)),将这个key使用相同的函数hash计算出哈希值并确定此数据在环上的位置,从此位置沿着环顺时针"行走",第一遇到的服务器就是其应该定位到的服务器。并将该键值对存储在这个节点上。
例如:我们有ObjA、ObjB、ObjC、ObjD四个数据对象,在经过hash计算之后,在环上分布的空间位置如下图。
根据一致性hash算法,ObjA的数据将会被定位到NodeA上。其他的类推,B将会在NodeB上,C将会在NodeC上,D将会在NodeD上.
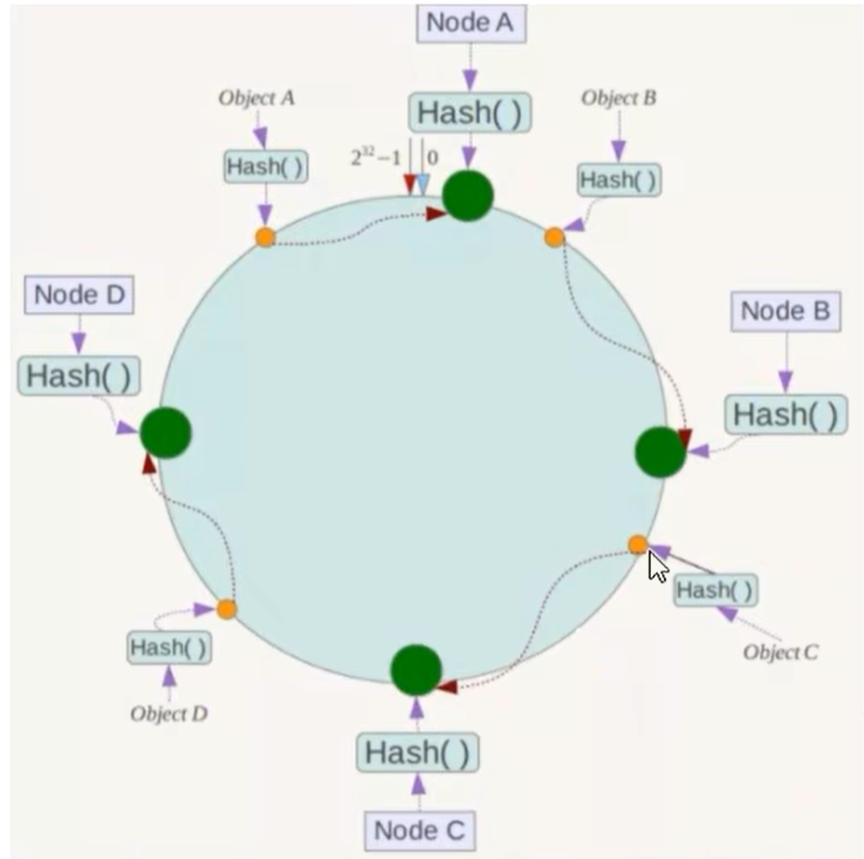
一致性hash算法的优点是什么?
1:一致性哈希算法的容错性
假设上图中的NodeC所在的服务器宕机了,可以看到次数对象ABD不会受到影响,只有C队形会被重定位到NodeD的机器上。一般地,在一致性Hash算法中,如果一台服务器不可用了,则受到影响的数据仅仅是对应服务器到其环空间中前一台服务器(也就是沿着逆时针方向行走遇到的第一台服务器)之间的数据而已,其他的数据不会受到影响,简单的来说,就是C服务器挂了,受影响的只是B、C之间的数据,并且这些数据会迁移到D上进行存储。
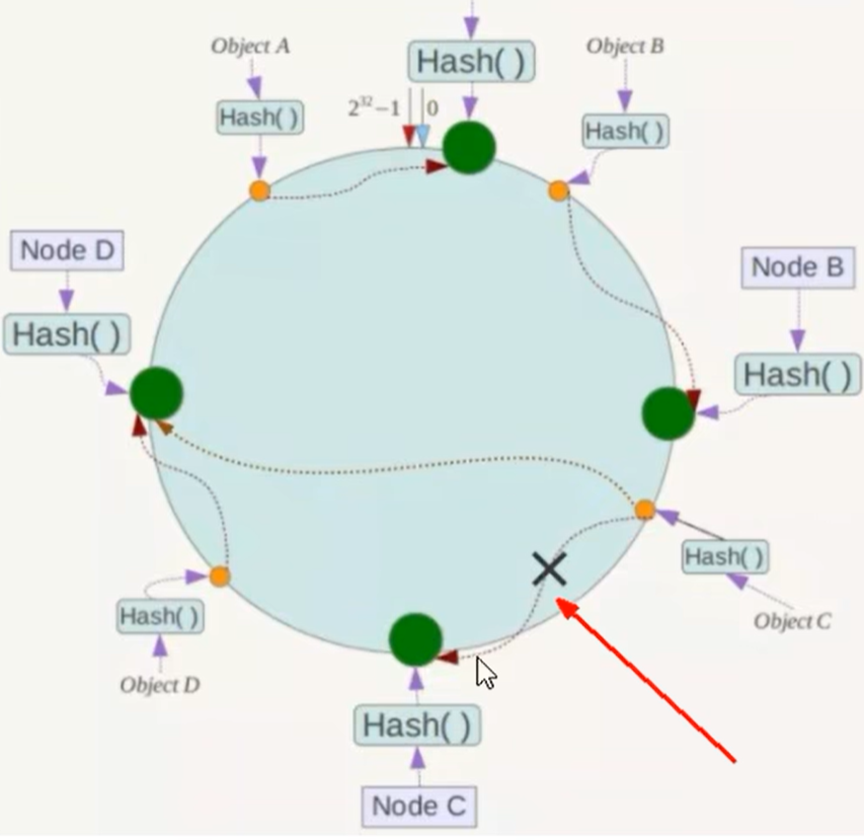
2:一致性哈希算法的扩展性
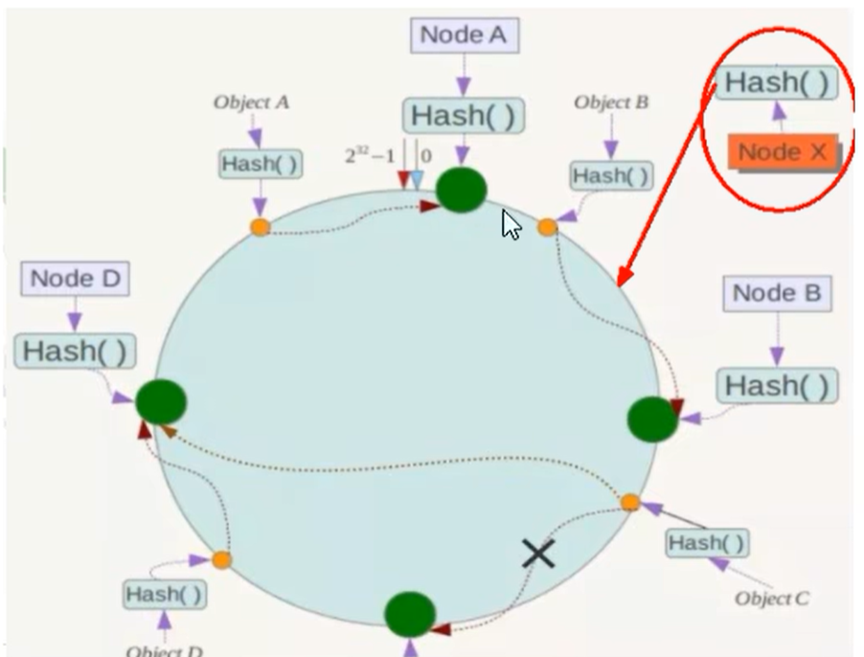
所谓的扩展性,就是数据量增加了,则需要增加一台节点NodeX,X的位置在A和B之间,那受到影响的也就是A到X之间的数据,重新把A到X的数据录入到X上即可,不会导致hash重新取余,全部数据重新洗牌.如下图:
一致性hash算法的缺点是什么?
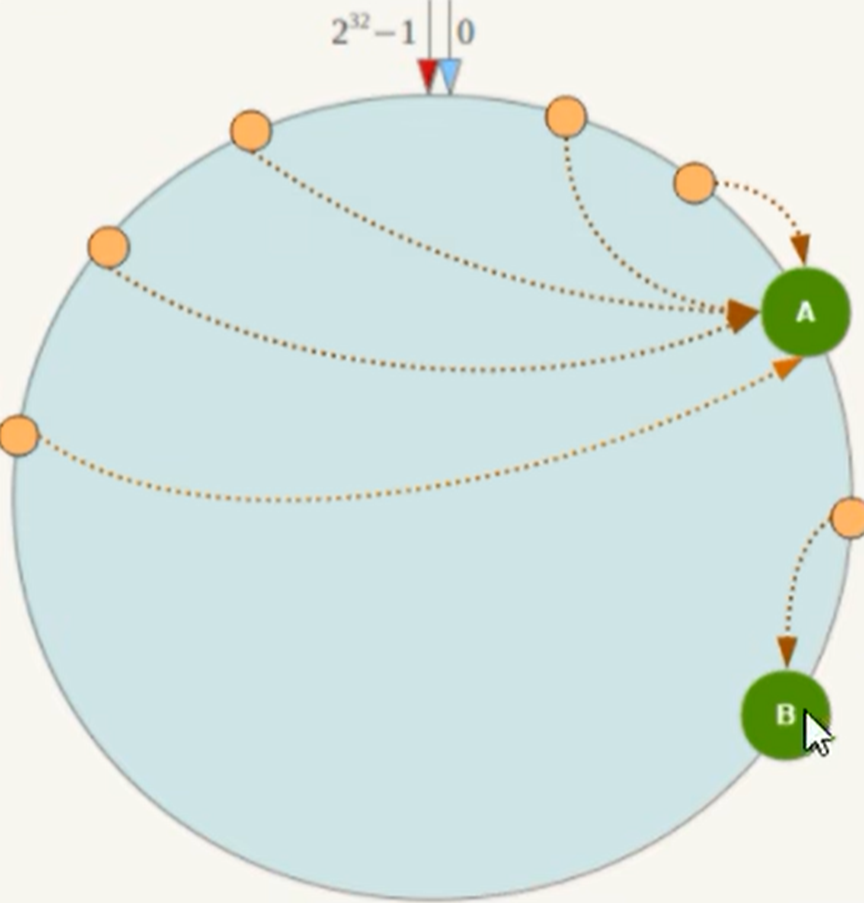
一致性哈希算法的数据倾斜问题
在服务器节点太少的情况下,容易因为节点数据分布不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)的问题。假设系统中只有两台服务器。那么出现数据倾斜就如下图:
总结一致性hash算法:
目的:为了在节点数目发生改变时尽可能少迁移数据。将所有的存储节点排列在相接的hash环上,每个key在计算hash之后,会按照顺时针找到的存储节点存放。而当有节点加入或者退出时候,仅影响该节点在hash环上的顺时针相邻的后续节点。
优点:加入和删除节点只会影响哈希环中顺时针方向相邻的节点,对其他节点无影响。
缺点:数据的分布和节点的位置有关,因为这些节点不是均匀地分布在哈希环上的,所以数据进行存储时候达不到均匀分布效果。可能就出现了数据倾斜问题。
针对上面问题,于是,又有了新的方案。就是接下来要讲的,哈希槽分区。
哈希槽分区
哈希槽是什么?
为什么会出现哈希槽算法?
因为一致性哈希算法的数据倾斜问题,为了解决这个问题。
哈希槽实质上就是一个数组,数组[0,2^14-1]形成hash slot空间。
能干什么?
解决均匀分配的问题,在数据和节点之间又加入了一层,把这一层称为哈希槽(slot),用于管理数据和节点之间的关系。现在就相当于节点上放的是槽,槽里面上的是数据。
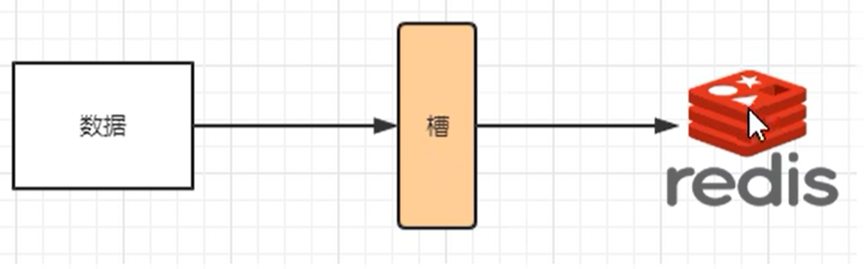
槽解决的是粒度问题,相当于是把粒度变大了。这样便于数据移动。
哈希解决的是映射问题,使用key的哈希值来计算所对应槽,便于数据分配。
多少个hash槽:
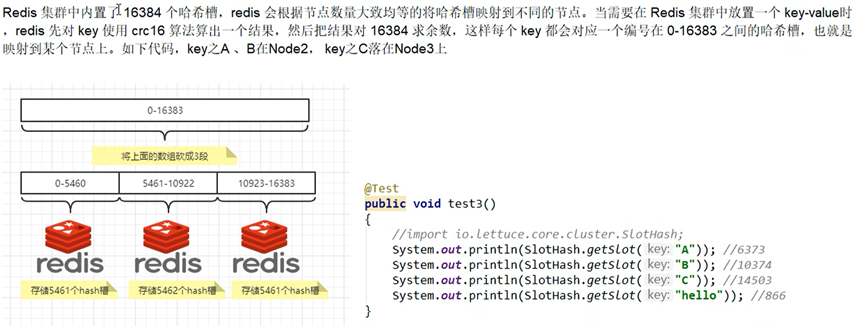
一个集群中只能有16384个槽。编号为0--16383(0-2^14-1),这些槽会分配给集群中所有的主节点,分配策略没有要求。可以指定哪个编号的槽分配给哪个主节点。集群会记录节点和槽对应的关系。解决了节点和槽的关系后,接下来就需要对key进行hash值计算,然后对16384取余。余数是几,那么key就落入到对应的槽中。slot=CRC16(key)%16384.以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容器,这样数据迁移问题就解决了.
哈希槽计算
Redis集群中内置了16384个哈希槽,Redis会根据节点数量大致均等地将hash槽映射到不同的节点。当需要在集群中放置一个k-v时,Redis先对key使用crc16算法算出一个结果,然后把结果对16834求余数。这样每个key都会对应一个编号,也就会映射到某个节点上。如下图:
结束语
如操作有问题欢迎去 我的 个人博客(www.kaigejava.com)留言或者 微信公众号(凯哥Java)留言交流哦。
{kind=link}
直通车,本系列教程已发布文章,快速到达,《Docker学习系列》教程已经发布的内容如下:
【图文教程】Windows11下安装Docker Desktop
【填坑】在windows系统下安装Docker Desktop后迁移镜像位置
【Docker学习系列】Docker学习1-docker安装
【Docker学习系列】Docker学习2-docker设置镜像加速器
【Docker学习系列】Docker学习3-docker的run命令干了什么?docker为什么比虚拟机快?
【Docker学习系列】Docker学习2-常用命令之启动命令和镜像命令
【Docker学习系列】Docker学习系列3:常用命令之容器命令
【Docker学习系列】Docker学习4-常用命令之重要的容器命令
【Docker教程系列】Docker学习5-Docker镜像理解
【Docker教程系列】Docker学习6-Docker镜像commit操作案例
【Docker学习教程系列】7-如何将本地的Docker镜像发布到阿里云
【Docker学习教程系列】8-如何将本地的Docker镜像发布到私服?
「Docker学习系列教程」10-Docker容器数据卷案例
docker高级篇1-dockeran安装mysql主从复制
docker高级篇2-分布式存储之三种算法的更多相关文章
- 02: docker高级篇
1.1 Docker Compose 1.Docker Compose 介绍 1. Compose是一个定义和管理多容器的工具,使用Python语言编写. 2. 使用Compose配置文件描述多个容器 ...
- Devops 开发运维高级篇之Jenkins+Docker+SpringCloud微服务持续集成(上)
Devops 开发运维高级篇之Jenkins+Docker+SpringCloud微服务持续集成(上) Jenkins+Docker+SpringCloud持续集成流程说明 大致流程说明: 1) 开发 ...
- Devops 开发运维高级篇之Jenkins+Docker+SpringCloud微服务持续集成——部署方案优化
Devops 开发运维高级篇之Jenkins+Docker+SpringCloud微服务持续集成--部署方案优化 之前我们做的方案部署都是只能选择一个微服务部署并只有一台生产服务器,每个微服务只有一个 ...
- 【转载】Spark性能优化指南——高级篇
前言 数据倾斜调优 调优概述 数据倾斜发生时的现象 数据倾斜发生的原理 如何定位导致数据倾斜的代码 查看导致数据倾斜的key的数据分布情况 数据倾斜的解决方案 解决方案一:使用Hive ETL预处理数 ...
- 【转】【技术博客】Spark性能优化指南——高级篇
http://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651745207&idx=1&sn=3d70d59cede236e ...
- Spark性能优化指南——高级篇(转载)
前言 继基础篇讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为<Spark性能优化指南>的高级篇,将深入分析数据倾斜调优与shuffle调优,以解决更加棘手的性能问 ...
- Spark性能优化指南-高级篇
转自https://tech.meituan.com/spark-tuning-pro.html,感谢原作者的贡献 前言 继基础篇讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作 ...
- Spark性能优化指南——高级篇
本文转载自:https://tech.meituan.com/spark-tuning-pro.html 美团技术点评团队) Spark性能优化指南——高级篇 李雪蕤 ·2016-05-12 14:4 ...
- Spring Cloud Alibaba | Sentinel: 服务限流高级篇
目录 Spring Cloud Alibaba | Sentinel: 服务限流高级篇 1. 熔断降级 1.1 降级策略 2. 热点参数限流 2.1 项目依赖 2.2 热点参数规则 3. 系统自适应限 ...
- 数据库MySQL学习笔记高级篇
数据库MySQL学习笔记高级篇 写在前面 学习链接:数据库 MySQL 视频教程全集 1. mysql的架构介绍 mysql简介 概述 高级Mysql 完整的mysql优化需要很深的功底,大公司甚至有 ...
随机推荐
- Golang channel底层是如何实现的?(深度好文)
Hi 你好,我是k哥.大厂搬砖6年的后端程序员. 我们知道,Go语言为了方便使用者,提供了简单.安全的协程数据同步和通信机制,channel.那我们知道channel底层是如何实现的吗?今天k哥就来聊 ...
- Apifox 6月更新|定时任务、内网自部署服务器运行接口定时导入、数据库 SSH 隧道连接
Apifox 新版本上线啦!!! 看看本次版本更新主要涵盖的重点内容,有没有你所关注的功能特性: 自动化测试支持设置「定时任务」 支持内网自部署服务器运行「定时导入」 数据库均支持通过 SSH 隧道 ...
- yb 课堂实战之视频列表接口开发+API权限路径规划 《三》
开发JsonData工具类 package net.ybclass.online_ybclass.utils; public class JsonData { /** * 状态码,0表示成功过,1表示 ...
- 高程读后感(四)— 关于BOM本人容易忽略的知识点总结
目录 window对象 window对象上属性及方法 超时调用setTimeout和间歇调用setInterval BOM location对象及其位置操作 history对象 window对象 wi ...
- [oeasy]python0074[专业选修]字节序_byte_order_struct_pack_大端序_小端序
进制转化 回忆上次内容 上次 总结了 计算字符串值的函数 eval 四种进制的转化函数 bin oct int hex 函数名 前缀 目标字符串所用进制 bin 0b 二进制 oct 0o ...
- 第四节 JMeter基础-初级登录【固定用户登录】
声明:本文所记录的仅本次操作学习到的知识点,其中商城IP错误,请自行更改. 1.认识JMeter (1)测试计划:测试的起点,所有组件的容器.相当于一个测试项目,对测试计划展开一系列的操作. (2)线 ...
- 玄机-第二章日志分析-mysql应急响应
目录 前言 简介 应急开始 准备工作 日志分析 步骤 1 步骤 2 步骤 3 步骤 4 总结 补充mysql中的/var/log/mysql/erro.log 记录上传文件信息的原因 前言 这里应急需 ...
- Android studio报错:Failed to allocate a 3213123 byte allocation with 31231 free bytes and 189MB ontil 0OM
这个问题是运行内存超了 在AndroidManifest中加入 android:hardwareAccelerated="false"android:largeHeap= &quo ...
- SptingBoot同时接收文件和对象数据(接收表单数据)
emmm...虽然很简单,而且网上全是教程,但是自己做个笔记映像才会更深刻,还请各位前辈多多指教: @RequestMapping(value = "/eventPush", me ...
- 【OracleDB】 07 分组查询 & 分组函数
分组函数 分组函数作用于一组数据,并对一组数据返回一个值. Oracle中分组函数的种类: - 求平均值 AVG - 计数记录数 COUNT - 求最大值 MAX - 求最小值 MIN - 求和 SU ...