全网呕血整理:关于YOLO v3原理分析
摘要:YOLO系列的目标检测算法可以说是目标检测史上的宏篇巨作,接下来我们来详细介绍一下YOLO v3算法内容。
算法基本思想
首先通过特征提取网络对输入特征提取特征,得到特定大小的特征图输出。输入图像分成13×13的grid cell,接着如果真实框中某个object的中心坐标落在某个grid cell中,那么就由该grid cell来预测该object。每个object有固定数量的bounding box,YOLO v3中有三个bounding box,使用逻辑回归确定用来预测的回归框。
网络结构
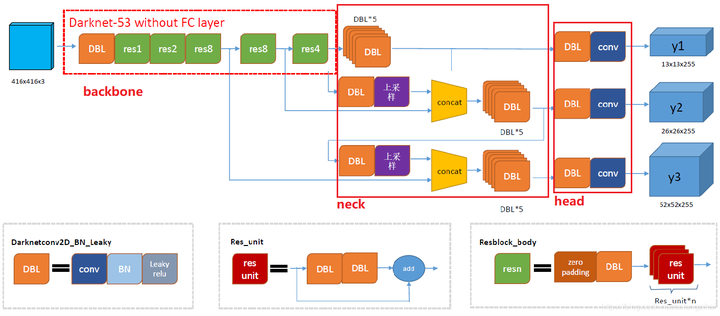
上图DBL是Yolo v3的基本组件。Darknet的卷积层后接BatchNormalization(BN)和LeakyReLU。除最后一层卷积层外,在yolo v3中BN和LeakyReLU已经是卷积层不可分离的部分了,共同构成了最小组件。
主干网络中使用了5个resn结构。n代表数字,有res1,res2, … ,res8等等,表示这个res_block里含有n个res_unit,这是Yolo v3的大组件。从Yolo v3开始借鉴了ResNet的残差结构,使用这种结构可以让网络结构更深。对于res_block的解释,可以在上图网络结果的右下角直观看到,其基本组件也是DBL。
在预测支路上有张量拼接(concat)操作。其实现方法是将darknet中间层和中间层后某一层的上采样进行拼接。值得注意的是,张量拼接和Res_unit结构的add的操作是不一样的,张量拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
Yolo_body一共有252层。23个Res_unit对应23个add层。BN层和LeakyReLU层数量都是72层,在网络结构中的表现为:每一层BN后面都会接一层LeakyReLU。上采样和张量拼接操作各2个,5个零填充对应5个res_block。卷积层一共有75层,其中有72层后面都会接BatchNormalization和LeakyReLU构成的DBL。三个不同尺度的输出对应三个卷积层,最后的卷积层的卷积核个数是255,针对COCO数据集的80类:3×(80+4+1)=255,3表示一个grid cell包含3个bounding box,4表示框的4个坐标信息,1表示置信度。
下图为具体网络结果图。
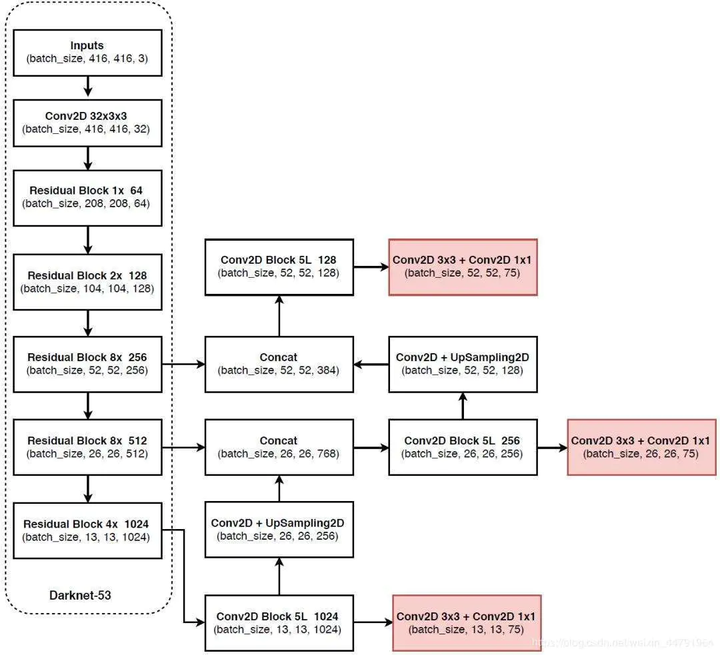
输入映射到输出
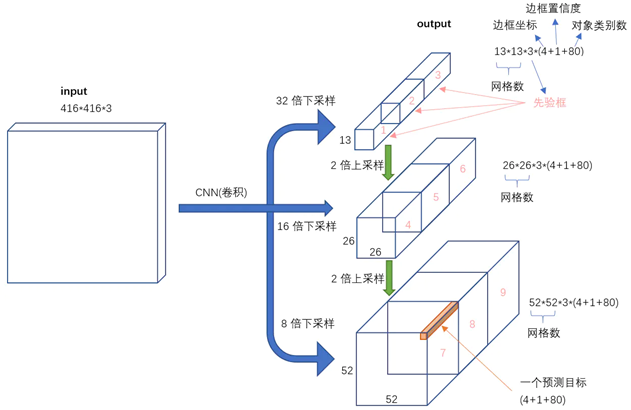
不考虑神经网络结构细节的话,总的来说,对于一个输入图像,YOLO3将其映射到3个尺度的输出张量,代表图像各个位置存在各种对象的概率。
我们看一下YOLO3共进行了多少个预测。对于一个416*416的输入图像,在每个尺度的特征图的每个网格设置3个先验框,总共有 13*13*3 + 26*26*3 + 52*52*3 = 10647 个预测。每一个预测是一个(4+1+80)=85维向量,这个85维向量包含边框坐标(4个数值),边框置信度(1个数值),对象类别的概率(对于COCO数据集,有80种对象)。
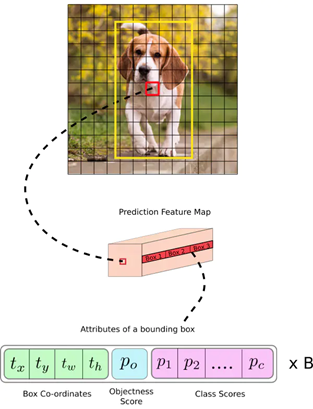
边界框预测(Bounding Box Prediction)
Yolo v3关于bounding box的初始尺寸还是采用Yolo v2中的k-means聚类的方式来做,这种先验知识对于bounding box的初始化帮助还是很大的,毕竟过多的bounding box虽然对于效果来说有保障,但是对于算法速度影响还是比较大的。
在COCO数据集上,9个聚类如下表所示,注这里需要说明:特征图越大,感受野越小。对小目标越敏感,所以选用小的anchor box。特征图越小,感受野越大。对大目标越敏感,所以选用大的anchor box。

Yolo v3采用直接预测相对位置的方法。预测出b-box中心点相对于网格单元左上角的相对坐标。直接预测出(tx,ty,tw,th,t0),然后通过以下坐标偏移公式计算得到b-box的位置大小和confidence。
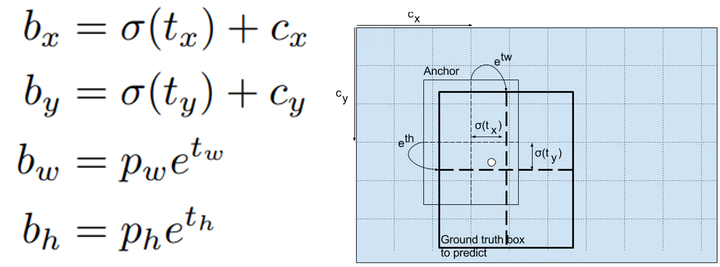
tx、ty、tw、th就是模型的预测输出。cx和cy表示grid cell的坐标,比如某层的feature map大小是13×13,那么grid cell就有13×13个,第0行第1列的grid cell的坐标cx就是0,cy就是1。pw和ph表示预测前bounding box的size。bx、by、bw和bh就是预测得到的bounding box的中心的坐标和size。在训练这几个坐标值的时候采用了sum of squared error loss(平方和距离误差损失),因为这种方式的误差可以很快的计算出来。
注:这里confidence = Pr(Object)*IoU 表示框中含有object的置信度和这个box预测的有多准。也就是说,如果这个框对应的是背景,那么这个值应该是 0,如果这个框对应的是前景,那么这个值应该是与对应前景 GT的IoU。
Yolo v3使用逻辑回归预测每个边界框的分数。如果边界框与真实框的重叠度比之前的任何其他边界框都要好,则该值应该为1。如果边界框不是最好的,但确实与真实对象的重叠超过某个阈值(Yolo v3中这里设定的阈值是0.5),那么就忽略这次预测。Yolo v3只为每个真实对象分配一个边界框,如果边界框与真实对象不吻合,则不会产生坐标或类别预测损失,只会产生物体预测损失。
多尺度预测
在上面网络结构图中可以看出,Yolo v3设定的是每个网格单元预测3个box,所以每个box需要有(x, y, w, h, confidence)五个基本参数。Yolo v3输出了3个不同尺度的feature map,如上图所示的y1, y2, y3。y1,y2和y3的深度都是255,边长的规律是13:26:52。
每个预测任务得到的特征大小都为N ×N ×[3∗(4+1+80)] ,N为格子大小,3为每个格子得到的边界框数量, 4是边界框坐标数量,1是目标预测值,80是类别数量。对于COCO类别而言,有80个类别的概率,所以每个box应该对每个种类都输出一个概率。所以3×(5 + 80) = 255。这个255就是这么来的。
Yolo v3用上采样的方法来实现这种多尺度的feature map。在Darknet-53得到的特征图的基础上,经过六个DBL结构和最后一层卷积层得到第一个特征图谱,在这个特征图谱上做第一次预测。Y1支路上,从后向前的倒数第3个卷积层的输出,经过一个DBL结构和一次(2,2)上采样,将上采样特征与第2个Res8结构输出的卷积特征张量连接,经过六个DBL结构和最后一层卷积层得到第二个特征图谱,在这个特征图谱上做第二次预测。Y2支路上,从后向前倒数第3个卷积层的输出,经过一个DBL结构和一次(2,2)上采样,将上采样特征与第1个Res8结构输出的卷积特征张量连接,经过六个DBL结构和最后一层卷积层得到第三个特征图谱,在这个特征图谱上做第三次预测。
就整个网络而言,Yolo v3多尺度预测输出的feature map尺寸为y1:(13×13),y2:(26×26),y3:(52×52)。网络接收一张(416×416)的图,经过5个步长为2的卷积来进行降采样(416 / 2ˆ5 = 13,y1输出(13×13)。从y1的倒数第二层的卷积层上采样(x2,up sampling)再与最后一个26×26大小的特征图张量连接,y2输出(26×26)。从y2的倒数第二层的卷积层上采样(x2,up sampling)再与最后一个52×52大小的特征图张量连接,y3输出(52×52)
感受一下9种先验框的尺寸,下图中蓝色框为聚类得到的先验框。黄色框式ground truth,红框是对象中心点所在的网格。

预测框的3种情况
预测框一共分为三种情况:正例(positive)、负例(negative)、忽略样例(ignore)。
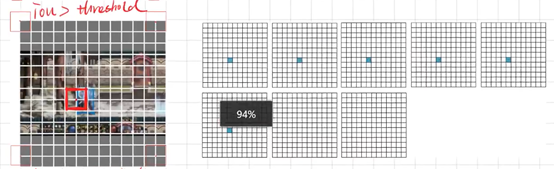
(1)正例:任取一个ground truth, 与上面计算的10647个框全部计算IOU, IOU最大的预测框, 即为正例。并且一个预测框, 只能分配给一个ground truth。 例如第一个ground truth已经匹配了一个正例检测框, 那么下一个ground truth, 就在余下的10646个检测框中, 寻找IOU最大的检测框作为正例。ground truth的先后顺序可忽略。正例产生置信度loss、检测框loss、类别loss。预测框为对应的ground truth box标签(使用真实的x、y、w、h计算出); 类别标签对应类别为1, 其余为0; 置信度标签为1。
(2)忽略样例:正例除外, 与任意一个ground truth的IOU大于阈值(论文中使用5), 则为忽略样例。忽略样例不产生任何loss。
为什么会有忽略样例?
由于Yolov3采用了多尺度检测, 那么再检测时会有重复检测现象. 比如有一个真实物体,在训练时被分配到的检测框是特征图1的第三个box,IOU达0.98,此时恰好特征图2的第一个box与该ground truth的IOU达0.95,也检测到了该ground truth,如果此时给其置信度强行打0的标签,网络学习效果会不理想。
(3)负例:正例除外(与ground truth计算后IOU最大的检测框,但是IOU小于阈值,仍为正例), 与全部ground truth的IOU都小于阈值(0.5), 则为负例。负例只有置信度产生loss, 置信度标签为0。
如下图所示:
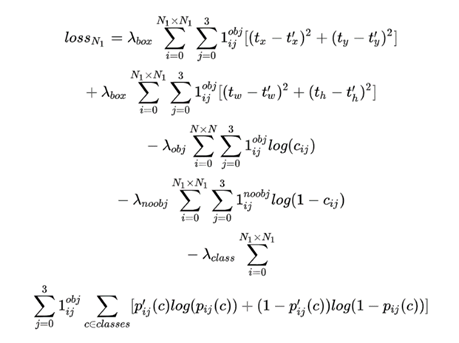
- λ为权重参数, 用于控制检测框loss, obj与noobj的置信度loss, 以及类别
- 对于正类而言, 1ijobj输出为1; 对于负例而言, 1ijnoobj输出为1; 对于忽略样例而言, 全部为0;
- 类别采用交叉熵作为损失函数。
类别预测
类别预测方面Yolo v2网络中的Softmax分类器,认为一个目标只属于一个类别,通过输出Score大小,使得每个框分配到Score最大的一个类别。但在一些复杂场景下,一个目标可能属于多个类(有重叠的类别标签),因此Yolo v3用多个独立的Logistic分类器替代Softmax层解决多标签分类问题,且准确率不会下降。
举例说明,原来分类网络中的softmax层都是假设一张图像或一个object只属于一个类别,但是在一些复杂场景下,一个object可能属于多个类,比如你的类别中有woman和person这两个类,那么如果一张图像中有一个woman,那么你检测的结果中类别标签就要同时有woman和person两个类,这就是多标签分类,需要用Logistic分类器来对每个类别做二分类。Logistic分类器主要用到sigmoid函数,该函数可以将输入约束在0到1的范围内,因此当一张图像经过特征提取后的某一类输出经过sigmoid函数约束后如果大于0.5,就表示该边界框负责的目标属于该类。
物体分数和类置信度
物体分数:表示一个边界框包含一个物体的概率,对于红色框和其周围的框几乎都为1,但边角的框可能几乎都为0。物体分数也通过一个sigmoid函数,表示概率值。
类置信度:表示检测到的物体属于一个具体类的概率值,以前的YOLO版本使用softmax将类分数转化为类概率。在YOLOv3中作者决定使用sigmoid函数取代,原因是softmax假设类之间都是互斥的,例如属于“Person”就不能表示属于“Woman”,然而很多情况是这个物体既是“Person”也是“Woman”。
输出处理
我们的网络生成10647个锚框,而图像中只有一个狗,怎么将10647个框减少为1个呢?首先,我们通过物体分数过滤一些锚框,例如低于阈值(假设0.5)的锚框直接舍去;然后,使用NMS(非极大值抑制)解决多个锚框检测一个物体的问题(例如红色框的3个锚框检测一个框或者连续的cell检测相同的物体,产生冗余),NMS用于去除多个检测框。
具体使用以下步骤:抛弃分数低的框(意味着框对于检测一个类信心不大);当多个框重合度高且都检测同一个物体时只选择一个框(NMS)。
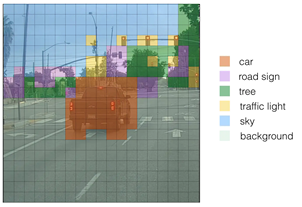
为了更方便理解,我们选用上面的汽车图像。首先,我们使用阈值进行过滤一部分锚框。模型有19*19*3*85个数,每个盒子由85个数字描述。将(19,19,3,85)分割为下面的形状:
box_confidence:(19,19,3,1)表示19*19个cell,每个cell的 3个框,每个框有物体的置信度概率;
boxes:(19,19,3,4)表示每个cell 的3个框,每个框的表示;
box_class_probs:(19,19,3,80)表示每个cell的3个框,每个框80个类检测概率。
每个锚框我们计算下面的元素级乘法并且得到锚框包含一个物体类的概率,如下图:

即使通过类分数阈值过滤一部分锚框,还剩下很多重合的框。第二个过程叫NMS,里面有个IoU,如下图所示。
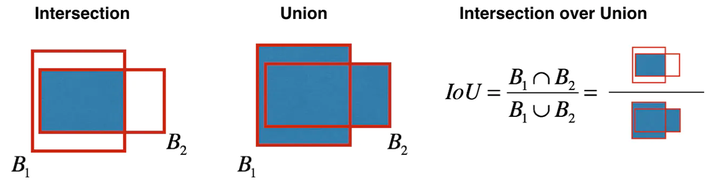
实现非极大值抑制,关键在于:选择一个最高分数的框;计算它和其他框的重合度,去除重合度超过IoU阈值的框;回到步骤1迭代直到没有比当前所选框低的框。

Loss Function
在Yolo v3的论文里没有明确提出所用的损失函数,确切地说,Yolo系列论文里面只有Yolo v1明确提了损失函数的公式。在Yolo v1中使用了一种叫sum-square error的损失计算方法,只是简单的差方相加。我们知道,在目标检测任务里,有几个关键信息是需要确定的:(x,y),(w,h),class,confidence 。根据关键信息的特点可以分为上述四类,损失函数应该由各自特点确定。最后加到一起就可以组成最终的loss function了,也就是一个loss function搞定端到端的训练。

yolov3网络硬核讲解(视频)
视频地址:https://www.bilibili.com/video/BV12y4y1v7L6?from=search&seid=442233808730191461
真实值是如何编码
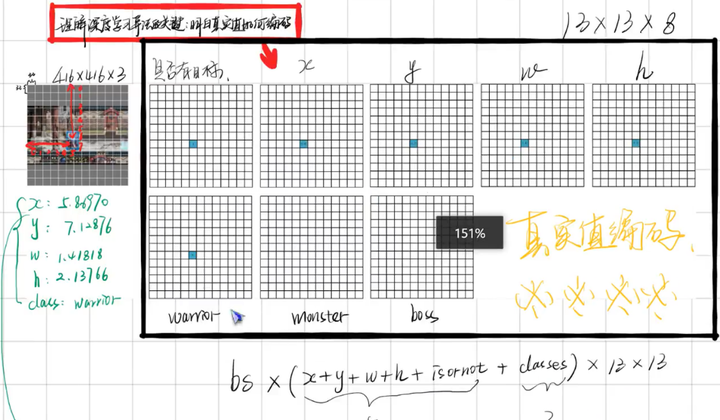
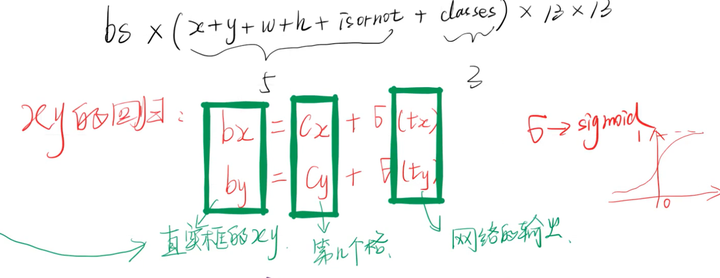
预测锚框的设计

锚框与目标框做iou


本文分享自华为云社区《YOLOV3 原理分析(全网资料整理)》,原文作者:lutianfei 。
全网呕血整理:关于YOLO v3原理分析的更多相关文章
- YOLO V3 原理
基本思想V1: 将输入图像分成S*S个格子,每隔格子负责预测中心在此格子中的物体. 每个格子预测B个bounding box及其置信度(confidence score),以及C个类别概率. bbox ...
- (转)Android 系统 root 破解原理分析
现在Android系统的root破解基本上成为大家的必备技能!网上也有很多中一键破解的软件,使root破解越来越容易.但是你思考过root破解的 原理吗?root破解的本质是什么呢?难道是利用了Lin ...
- seo伪原创技术原理分析,php实现伪原创示例
seo伪原创技术原理分析,php实现伪原创示例 现在seo伪原创一般采用分词引擎以及动态同义词库,模拟百度(baidu),谷歌(google)等中文切词进行伪原创,生成后的伪原创文章更准确更贴近百度和 ...
- YOLO系列:YOLO v3解析
本文好多内容转载自 https://blog.csdn.net/leviopku/article/details/82660381 yolo_v3 提供替换backbone.要想性能牛叉,backbo ...
- RSA公钥文件解密密文的原理分析
前言 最近在学习RSA加解密过程中遇到一个这样的难题:假设已知publickey公钥文件和加密后的密文flag,如何对其密文进行解密,转换成明文~~ 分析 对于rsa算法的公钥与私钥的产生,我们可以了 ...
- Hadoop生态圈-Zookeeper的工作原理分析
Hadoop生态圈-Zookeeper的工作原理分析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 无论是是Kafka集群,还是producer和consumer都依赖于Zoo ...
- Tomcat源码分析——请求原理分析(下)
前言 本文继续讲解TOMCAT的请求原理分析,建议朋友们阅读本文时首先阅读过<TOMCAT源码分析——请求原理分析(上)>和<TOMCAT源码分析——请求原理分析(中)>.在& ...
- Tomcat源码分析——请求原理分析(上)
前言 谈起Tomcat的诞生,最早可以追溯到1995年.近20年来,Tomcat始终是使用最广泛的Web服务器,由于其使用Java语言开发,所以广为Java程序员所熟悉.很多人早期的J2EE项目,由程 ...
- ZT自老罗的博客 Android系统的智能指针(轻量级指针、强指针和弱指针)的实现原理分析
Android系统的智能指针(轻量级指针.强指针和弱指针)的实现原理分析 分类: Android 2011-09-23 00:59 31568人阅读 评论(42) 收藏 举报 androidclass ...
- ssm框架搭建流程及原理分析
这几天自己想搭建个ssm框架玩一下,有些东西长时间不玩都给忘了,所以自己把整个流程整理了一下,只要跟着步骤,就能顺利完成ssm框架的搭建. 一.搭建步骤: 1.整理jar包 2.对于一个web ...
随机推荐
- webwork学习
学习了H5中的webworker 主机 > 程序 > 进程 > 线程 > 纤程 多进程(重) 多线程(轻) 开销 创建.销毁开销大 创建.销毁开销小 安全性 进程之间是隔离 线 ...
- 在VM虚拟机中安装FTP服务
自用的话,建议先关掉防火墙 systemctl stop firewalld #关闭防火墙 systemctl disable firewalld.service #设置开机禁用防火墙 systemc ...
- super学习
2022-10-02 16:27:38 super super代表的是"当前对象(this)"的父类型特征 概念 1.super是一个关键字,全部小写. 2.super和this对 ...
- K8s 多租户方案的挑战与价值
在当今企业环境中,随着业务的快速增长和多样化,服务器和云资源的管理会越来越让人头疼.K8s 虽然很强大,但在处理多个部门或团队的业务部署需求时,如果缺乏有效的多租户支持,在效率和资源管理方面都会不尽如 ...
- jmeter完成文件上传接口
前提:测试项目中有一个上传本地文件(excel)测被测接口. 测试工具:jmeter 协议:http 测试项目如下图: 第一步:点击模板上传,选择本地excel文件 第二步:上传成功,系统识别exce ...
- serdes级联时钟
级联时钟在其他的IP领域下很少见到,在serdes中时个基本的功能. 因为高密场景下需要时钟数几十个IP,一般摆放在芯片边缘位置. 而SOC的管脚资源非常有限.因此就需要多个IP之间的ref clk进 ...
- macOS 苹果电脑双面打印单面打印PDF设置
苹果的打印服务分为两个部分,一个是应用层另一个是系统层. 其中双面打印或单面打印统一在系统层面设置,下面我分别截图示意wps pdf和福昕pdf两款软件设置双面打印. 1.WPS PDF 在完成方式中 ...
- Python:单元测试框架unittest
1.什么是单元测试 测试函数/方法或者一段代码,用于检验被测代码的一个很小的.很明确的功能是否正确,通常是开发做. 在Python中的单元测试框架有Unittest和Pytest,现在总结Unitte ...
- C#设计模式之享元模式(Flyweight)
using System; using System.Collections; public class Client { public static void Main(string[] args) ...
- 安装Office
安装Office 第一步 访问: https://otp.landian.vip/zh-cn/ 点击立即下载 选择: 第二步 打开下载好的zip,解压,启动程序 第三步 选择部署(在这里可以看到电脑已 ...