mmcls/mmdet模型部署至 TorchServe
mmcls/mmdet模型部署至 TorchServe
官方教程:模型部署至 TorchServe — MMClassification 0.23.2 文档
接口说明:
serve/inference_api.md at master · pytorch/serve (github.com)
测试torchserve的分类模型是否健康
curl http://127.0.0.1:8080/ping
# return
{
"status": "Healthy"
}
测试torchserve的检测模型是否健康
curl http://127.0.0.1:8083/ping
# return
{
"status": "Healthy"
}
分类:
请求地址:
http://127.0.0.1:8080/predictions/cls_slice_resnet50 http://127.0.0.1:8080/predictions/cls_thyroid_resnet50 http://127.0.0.1:8080/predictions/cls_componente_resnet50
http://127.0.0.1:8080/predictions/cls_echoes_resnet50
http://127.0.0.1:8080/predictions/cls_edges_resnet50
http://127.0.0.1:8080/predictions/cls_strong_echoes_resnet50
返回结果:
{
"pred_label": 0,
"pred_score": 0.5629526972770691,
"pred_class": "horizontal"
}
python+requests
import requests upload_url = "http://127.0.0.1:8080/predictions/cls_slice_resnet50"
file = {'data': open('F:\\imgs\\nodule2.jpg', 'rb')}
res = requests.post(upload_url, files=file)
print(res.json())curl
curl http://127.0.0.1:8080/predictions/cls_slice_resnet50 -T torchserve/imgs/demo.jpg
检测:
请求地址:
http://127.0.0.1:8083/predictions/det_thyroid_yolox
返回结果:
[
{
"class_name": "motorcycle",
"bbox": [
449.106689453125,
267.3927307128906,
603.3954467773438,
414.5325622558594
],
"score": 0.8570554256439209
}
]
python+requests
import requests upload_url = "http://127.0.0.1:8083/predictions/det_thyroid_yolox"
file = {'data': open('F:\\imgs\\nodule1.jpg', 'rb')}
res = requests.post(upload_url, files=file)
print(res.json())
curl
curl http://127.0.0.1:8083/predictions/det_thyroid_yolox -T torchserve/imgs/demo.jpg
mmcls
1. 转换 MMClassification 模型至 TorchServe
python tools/deployment/mmcls2torchserve.py ${CONFIG_FILE} ${CHECKPOINT_FILE} \
--output-folder ${MODEL_STORE} \
--model-name ${MODEL_NAME}
${MODEL_STORE} 需要是一个文件夹的绝对路径。
示例:
python tools/deployment/mmcls2torchserve.py configs/resnet/resnet50_8xb256-rsb-a1-600e_in1k.py checkpoints/resnet50_8xb256-rsb-a1-600e_in1k.pth --output-folder ./checkpoints/ --model-name resnet50_8xb256-rsb-a1-600e_in1k
2. 构建 mmcls-serve docker 镜像
cd mmclassification
docker build -t mmcls-serve docker/serve/
修改mmcls/docker/serve/Dockerfile,为下面内容。主要是在 apt-get update 前面添加了下面几句:
RUN sed -i s@/archive.ubuntu.com/@/mirrors.aliyun.com/@g /etc/apt/sources.list
RUN apt-get clean
RUN rm /etc/apt/sources.list.d/cuda.list
第一行是添加国内源,第二行是修复nvidia更新密钥问题。更新 CUDA Linux GPG 存储库密钥 - NVIDIA 技术博客
RUN sed -i s@/archive.ubuntu.com/@/mirrors.aliyun.com/@g /etc/apt/sources.list
RUN apt-get clean
RUN rm /etc/apt/sources.list.d/cuda.list
️ 不加上边几行会报错:
W: GPG error: https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ InRelease: The following signatures couldn't be verified because the public key is not available: NO_PUBKEY A4B469963BF863CC
E: The repository 'https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64 InRelease' is no longer signed.
新的Dockerfile内容:
ARG PYTORCH="1.8.1"
ARG CUDA="10.2"
ARG CUDNN="7"
FROM pytorch/pytorch:${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel
ARG MMCV="1.4.2"
ARG MMCLS="0.23.2"
ENV PYTHONUNBUFFERED TRUE
RUN sed -i s@/archive.ubuntu.com/@/mirrors.aliyun.com/@g /etc/apt/sources.list
RUN apt-get clean
RUN rm /etc/apt/sources.list.d/cuda.list
RUN apt-get update && \
DEBIAN_FRONTEND=noninteractive apt-get install --no-install-recommends -y \
ca-certificates \
g++ \
openjdk-11-jre-headless \
# MMDet Requirements
ffmpeg libsm6 libxext6 git ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 \
&& rm -rf /var/lib/apt/lists/*
ENV PATH="/opt/conda/bin:$PATH"
RUN export FORCE_CUDA=1
# TORCHSEVER
RUN pip install torchserve torch-model-archiver
# MMLAB
ARG PYTORCH
ARG CUDA
RUN ["/bin/bash", "-c", "pip install mmcv-full==${MMCV} -f https://download.openmmlab.com/mmcv/dist/cu${CUDA//./}/torch${PYTORCH}/index.html"]
RUN pip install mmcls==${MMCLS}
RUN useradd -m model-server \
&& mkdir -p /home/model-server/tmp
COPY entrypoint.sh /usr/local/bin/entrypoint.sh
RUN chmod +x /usr/local/bin/entrypoint.sh \
&& chown -R model-server /home/model-server
COPY config.properties /home/model-server/config.properties
RUN mkdir /home/model-server/model-store && chown -R model-server /home/model-server/model-store
EXPOSE 8080 8081 8082
USER model-server
WORKDIR /home/model-server
ENV TEMP=/home/model-server/tmp
ENTRYPOINT ["/usr/local/bin/entrypoint.sh"]
CMD ["serve"]
3. 运行 mmcls-serve 镜像
请参考官方文档 基于 docker 运行 TorchServe.
为了使镜像能够使用 GPU 资源,需要安装 nvidia-docker。之后可以传递 --gpus 参数以在 GPU 上运。
示例:
docker run --rm \
--cpus 8 \
--gpus device=0 \ # 单GPU
-p8080:8080 -p8081:8081 -p8082:8082 \ # HTTP
-p7070:7070 -p7071:7071 # gRPC
--mount type=bind,source=`realpath ./checkpoints`,target=/home/model-server/model-store \
mmcls-serve:latest
实例(启动服务)
docker run --rm --gpus 2 -p8080:8080 -p8081:8081 -p8082:8082 -p7072:7070 -p7073:7071 --mount type=bind,source=/home/xbsj/gy77/torchserve/torchserve_models/mmcls,target=/home/model-server/model-store mmcls-serve
备注
realpath ./checkpoints 是 “./checkpoints” 的绝对路径,你可以将其替换为你保存 TorchServe 模型的目录的绝对路径。
参考 该文档 了解关于推理 (8080),管理 (8081) 和指标 (8082) 等 API 的信息。
4. 测试部署
curl http://127.0.0.1:8080/predictions/${MODEL_NAME} -T demo/demo.JPEG
示例:
curl http://127.0.0.1:8080/predictions/cls_thyroid_resnet50 -T torchserve/imgs/demo.jpg
# 或者
curl http://${IP地址}:8080/predictions/resnet50_8xb256-rsb-a1-600e_in1k -T demo/demo.JPEG
您应该获得类似于以下内容的响应:
{
"pred_label": 65,
"pred_score": 0.9548004269599915,
"pred_class": "sea snake"
}
另外,你也可以使用 test_torchserver.py 来比较 TorchServe 和 PyTorch 的结果,并进行可视化。
python tools/deployment/test_torchserver.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} ${MODEL_NAME}
[--inference-addr ${INFERENCE_ADDR}] [--device ${DEVICE}]
示例:
python tools/deployment/test_torchserver.py demo/demo.JPEG configs/resnet/resnet50_8xb256-rsb-a1-600e_in1k.py checkpoints/resnet50_8xb256-rsb-a1-600e_in1k.pth resnet50_8xb256-rsb-a1-600e_in1k
可视化结果展示:
 |
 |
|---|
docker终止运行的服务:
docker container ps # 查看正在运行的容器
docker container stop ${container id} # 根据容器id终止运行的容器
mmdet
1. 转换 MMDetection 模型至 TorchServe
python tools/deployment/mmdet2torchserve.py ${CONFIG_FILE} ${CHECKPOINT_FILE} \
--output-folder ${MODEL_STORE} \
--model-name ${MODEL_NAME}
${MODEL_STORE} 需要是一个文件夹的绝对路径。
示例:
python tools/deployment/mmdet2torchserve.py configs/yolox/yolox_s_8x8_300e_coco.py checkpoints/yolox_s_8x8_300e_coco.pth --output-folder ./checkpoints --model-name yolox_s_8x8_300e_coco
python tools/deployment/mmcls2torchserve.py ../torchserve/pytorch_models/cls_thyroid_resnet50.py ../torchserve/pytorch_models/cls_thyroid_resnet50.pth --output-folder ../torchserve/torchserve_models --model-name cls_thyroid_resnet50
2. 构建 mmdet-serve docker 镜像
cd mmdet
docker build -t mmdet-serve docker/serve/
修改mmdet/docker/serve/Dockerfile,为下面内容。主要是在 apt-get update 前面添加了下面几句:
第一行是添加国内源,第二行是修复nvidia更新密钥问题。更新 CUDA Linux GPG 存储库密钥 - NVIDIA 技术博客
RUN sed -i s@/archive.ubuntu.com/@/mirrors.aliyun.com/@g /etc/apt/sources.list
RUN apt-get clean
RUN rm /etc/apt/sources.list.d/cuda.list
️ 不加上边几行会报错:
W: GPG error: https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ InRelease: The following signatures couldn't be verified because the public key is not available: NO_PUBKEY A4B469963BF863CC
E: The repository 'https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64 InRelease' is no longer signed.
新的Dockerfile内容:
ARG PYTORCH="1.6.0"
ARG CUDA="10.1"
ARG CUDNN="7"
FROM pytorch/pytorch:${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel
ARG MMCV="1.3.17"
ARG MMDET="2.23.0"
ENV PYTHONUNBUFFERED TRUE
RUN sed -i s@/archive.ubuntu.com/@/mirrors.aliyun.com/@g /etc/apt/sources.list
RUN apt-get clean
RUN rm /etc/apt/sources.list.d/cuda.list
RUN apt-get update && \
DEBIAN_FRONTEND=noninteractive apt-get install --no-install-recommends -y \
ca-certificates \
g++ \
openjdk-11-jre-headless \
# MMDet Requirements
ffmpeg libsm6 libxext6 git ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 \
&& rm -rf /var/lib/apt/lists/*
ENV PATH="/opt/conda/bin:$PATH"
RUN export FORCE_CUDA=1
# TORCHSEVER
RUN pip install torchserve torch-model-archiver nvgpu -i https://pypi.tuna.tsinghua.edu.cn/simple/
# MMLAB
ARG PYTORCH
ARG CUDA
RUN ["/bin/bash", "-c", "pip install mmcv-full==${MMCV} -f https://download.openmmlab.com/mmcv/dist/cu${CUDA//./}/torch${PYTORCH}/index.html -i https://pypi.tuna.tsinghua.edu.cn/simple/"]
RUN pip install mmdet==${MMDET} -i https://pypi.tuna.tsinghua.edu.cn/simple/
RUN useradd -m model-server \
&& mkdir -p /home/model-server/tmp
COPY entrypoint.sh /usr/local/bin/entrypoint.sh
RUN chmod +x /usr/local/bin/entrypoint.sh \
&& chown -R model-server /home/model-server
COPY config.properties /home/model-server/config.properties
RUN mkdir /home/model-server/model-store && chown -R model-server /home/model-server/model-store
EXPOSE 8080 8081 8082
USER model-server
WORKDIR /home/model-server
ENV TEMP=/home/model-server/tmp
ENTRYPOINT ["/usr/local/bin/entrypoint.sh"]
CMD ["serve"]
3. 运行 mmdet-serve 镜像
请参考官方文档 基于 docker 运行 TorchServe.
为了使镜像能够使用 GPU 资源,需要安装 nvidia-docker。之后可以传递 --gpus 参数以在 GPU 上运。
示例:
docker run --rm \
--cpus 8 \
--gpus device=0 \ # 单GPU
-p8080:8080 -p8081:8081 -p8082:8082 \ # HTTP
-p7070:7070 -p7071:7071 # gRPC
--mount type=bind,source=`realpath ./checkpoints`,target=/home/model-server/model-store \
mmcls-serve:latest
实例,为了不跟 mmcls-serve 冲突,使用8083,8084,8085, 7072,7073端口。
docker run --rm --gpus 2 -p8083:8080 -p8084:8081 -p8085:8082 -p7072:7070 -p7073:7071 --mount type=bind,source=/home/xbsj/gy77/torchserve/torchserve_models/mmdet,target=/home/model-server/model-store mmdet-serve
4. 测试部署
curl http://127.0.0.1:8083/predictions/det_thyroid_yolox -T torchserve/imgs/demo.jpg
您应该获得类似于以下内容的响应:
[
{
"class_name": "car",
"bbox": [
481.5609130859375,
110.4412612915039,
522.7328491210938,
130.5723876953125
],
"score": 0.8954943418502808
},
{
"class_name": "car",
"bbox": [
431.3537902832031,
105.25204467773438,
484.0513610839844,
132.73513793945312
],
"score": 0.8776198029518127
},
{
"class_name": "car",
"bbox": [
294.16278076171875,
117.66851806640625,
379.8677978515625,
149.80923461914062
],
"score": 0.8764416575431824
},
{
"class_name": "car",
"bbox": [
191.56170654296875,
108.98323059082031,
299.0423278808594,
155.1902313232422
],
"score": 0.8606226444244385
},
{
"class_name": "car",
"bbox": [
398.29461669921875,
110.82112884521484,
433.4544677734375,
133.10105895996094
],
"score": 0.8603343963623047
},
{
"class_name": "car",
"bbox": [
608.4430541992188,
111.58413696289062,
637.6807250976562,
137.55311584472656
],
"score": 0.8566091060638428
},
{
"class_name": "car",
"bbox": [
589.808349609375,
110.58977508544922,
619.0382080078125,
126.56522369384766
],
"score": 0.7685313820838928
},
{
"class_name": "car",
"bbox": [
167.66847229003906,
110.8987045288086,
211.2526092529297,
140.1393585205078
],
"score": 0.764432430267334
},
{
"class_name": "car",
"bbox": [
0.3290290832519531,
112.89485931396484,
62.417659759521484,
145.11058044433594
],
"score": 0.7574507594108582
},
{
"class_name": "car",
"bbox": [
268.7782287597656,
105.21003723144531,
328.5860290527344,
127.79859924316406
],
"score": 0.7260770201683044
},
{
"class_name": "car",
"bbox": [
96.76626586914062,
89.0433349609375,
118.81390380859375,
102.16648864746094
],
"score": 0.6803644299507141
},
{
"class_name": "car",
"bbox": [
571.3563232421875,
110.22184753417969,
592.4779052734375,
126.81962585449219
],
"score": 0.6668680906295776
},
{
"class_name": "car",
"bbox": [
61.34038162231445,
93.14757537841797,
84.83381652832031,
106.10137176513672
],
"score": 0.6323376893997192
},
{
"class_name": "bench",
"bbox": [
221.9741668701172,
176.775146484375,
456.5819091796875,
382.6751708984375
],
"score": 0.9417163729667664
},
{
"class_name": "bench",
"bbox": [
372.16351318359375,
134.79196166992188,
433.37713623046875,
189.78695678710938
],
"score": 0.5323100686073303
}
另外,你也可以使用 test_torchserver.py 来比较 TorchServe 和 PyTorch 的结果,并进行可视化。
python tools/deployment/test_torchserver.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} ${MODEL_NAME}
[--inference-addr ${INFERENCE_ADDR}] [--device ${DEVICE}]
示例:
python tools/deployment/test_torchserver.py demo/demo.jpg configs/yolox/yolox_s_8x8_300e_coco.py checkpoints/yolox_s_8x8_300e_coco.pth yolox_s_8x8_300e_coco
可视化展示:
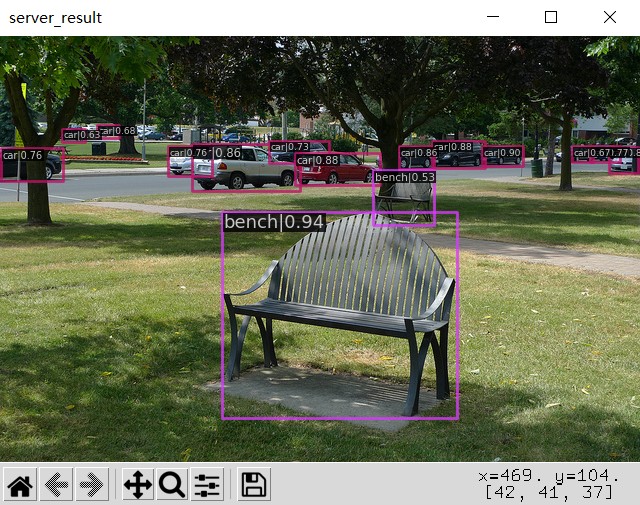 |
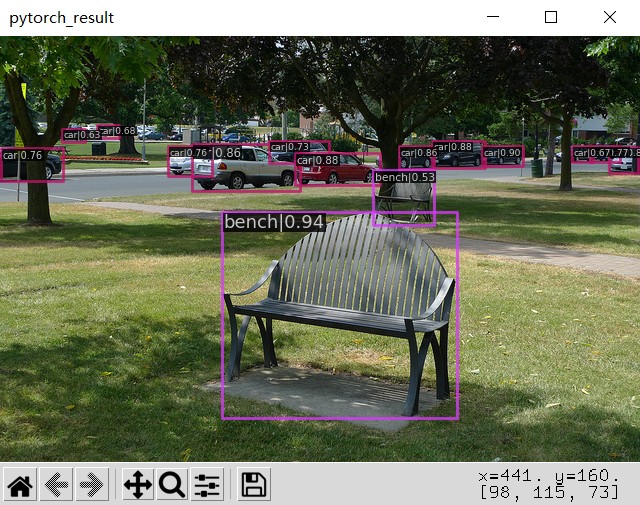 |
|---|
docker终止运行的服务:
docker container ps # 查看正在运行的容器
docker container stop ${container id} # 根据容器id终止运行的容器
mmcls 多标签模型部署在torch serve
GitHub仓库:gy-7/mmcls_multi_label_torchserve (github.com)
各个文件说明:
cls_requests_demo:分类模型请求api服务的demo
det_requests_demo:检测模型请求api服务的demo
inference:要修改的inference代码
mmcls_handler:要修改的mmcls_handler代码
torchserve_log:过程中遇到的报错集合
1️⃣ 修改 mmcls_handler.py
我们首先要搞清楚,mmcls_handler.py 是转换 pytorch 模型为 torch serve 模型的时候用到的。转换过程中把里边的内容嵌入到转换完的 torch serve 模型里了。
我们主要修改的是 mmcls_handler 中 postprocess 的操作。将仓库中 mmcls_handler.py 文件内容覆盖掉mmclassification/tools/deployment/mmcls_handler.py。
2️⃣ 重新转换所有的模型:
python tools/deployment/mmcls2torchserve.py ../torchserve/pytorch_models/cls_componente_resnet50.py ../torchserve/pytorch_models/cls_componente_resnet50.pth --output-folder ../torchserve/torchserve_models/mmcls/ --model-name cls_componente_resnet50
python tools/deployment/mmcls2torchserve.py ../torchserve/pytorch_models/cls_echoes_resnet50.py ../torchserve/pytorch_models/cls_echoes_resnet50.pth --output-folder ../torchserve/torchserve_models/mmcls/ --model-name cls_echoes_resnet50
python tools/deployment/mmcls2torchserve.py ../torchserve/pytorch_models/cls_edges_resnet50.py ../torchserve/pytorch_models/cls_edges_resnet50.pth --output-folder ../torchserve/torchserve_models/mmcls/ --model-name cls_edges_resnet50
python tools/deployment/mmcls2torchserve.py ../torchserve/pytorch_models/cls_slice_resnet50.py ../torchserve/pytorch_models/cls_slice_resnet50.pth --output-folder ../torchserve/torchserve_models/mmcls/ --model-name cls_slice_resnet50
python tools/deployment/mmcls2torchserve.py ../torchserve/pytorch_models/cls_thyroid_resnet50.py ../torchserve/pytorch_models/cls_thyroid_resnet50.pth --output-folder ../torchserve/torchserve_models/mmcls/ --model-name cls_thyroid_resnet50
python tools/deployment/mmcls2torchserve.py ../torchserve/pytorch_models/cls_strong_echoes_resnet50.py ../torchserve/pytorch_models/cls_strong_echoes_resnet50.pth --output-folder ../torchserve/torchserve_models/mmcls/ --model-name cls_strong_echoes_resnet50
3️⃣ 修改inference.py
inference.py 是调用api服务的时候,调用的接口。我们用docker 装的 torch serve服务,所以我们要修改容器里边的 源码。
启动原先的服务,进入容器。
docker exec -it --user root 7f0f1ea9e3e8 /bin/bash
# 修改inference.py
vim /opt/conda/lib/python3.7/site-packages/mmcls/apis/inference.py
# 保存镜像
docker commit -m "fix inference.py" 7f0f1ea9e3e8 mmcls-serve_multi_label:latest
4️⃣ 可以愉快的出来结果了
前五个是单标签,最后一个是多标签。
{'pred_label': 2, 'pred_score': 0.9856280088424683, 'pred_class': 'vertical'}
{'pred_label': 0, 'pred_score': 0.9774421453475952, 'pred_class': 'benign'}
{'pred_label': 4, 'pred_score': 0.6918501853942871, 'pred_class': 'componentes_4'}
{'pred_label': 2, 'pred_score': 0.5446202158927917, 'pred_class': 'echoes_2'}
{'pred_label': 1, 'pred_score': 0.4259072542190552, 'pred_class': 'edges_1'}
{'pred_label': [0, 0, 0, 0, 0], 'pred_score': [0.46634966135025024, 0.07801822572946548, 0.2685200273990631, 0.016055332496762276, 0.13444863259792328], 'pred_class': []}
mmcls/mmdet模型部署至 TorchServe的更多相关文章
- 学习笔记TF022:产品环境模型部署、Docker镜像、Bazel工作区、导出模型、服务器、客户端
产品环境模型部署,创建简单Web APP,用户上传图像,运行Inception模型,实现图像自动分类. 搭建TensorFlow服务开发环境.安装Docker,https://docs.docker. ...
- Tensorflow Serving 模型部署和服务
http://blog.csdn.net/wangjian1204/article/details/68928656 本文转载自:https://zhuanlan.zhihu.com/p/233614 ...
- 【tensorflow-转载】tensorflow模型部署系列
参考 1. tensorflow模型部署系列: 完
- Slim模型部署多GPU
1 多GPU原理 单GPU时,思路很简单,前向.后向都在一个GPU上进行,模型参数更新时只涉及一个GPU. 多GPU时,有模型并行和数据并行两种情况. 模型并行指模型的不同部分在不同GPU上运行. 数 ...
- TensorFlow Serving实现多模型部署以及不同版本模型的调用
前提:要实现多模型部署,首先要了解并且熟练实现单模型部署,可以借助官网文档,使用Docker实现部署. 1. 首先准备两个你需要部署的模型,统一的放在multiModel/文件夹下(文件夹名字可以任意 ...
- PyTorch专栏(六): 混合前端的seq2seq模型部署
欢迎关注磐创博客资源汇总站: http://docs.panchuang.net/ 欢迎关注PyTorch官方中文教程站: http://pytorch.panchuang.net/ 专栏目录: 第一 ...
- 如何使用flask将模型部署为服务
在某些场景下,我们需要将机器学习或者深度学习模型部署为服务给其它地方调用,本文接下来就讲解使用python的flask部署服务的基本过程. 1. 加载保存好的模型 为了方便起见,这里我们就使用简单的分 ...
- 混合前端seq2seq模型部署
混合前端seq2seq模型部署 本文介绍,如何将seq2seq模型转换为PyTorch可用的前端混合Torch脚本.要转换的模型来自于聊天机器人教程Chatbot tutorial. 1.混合前端 在 ...
- 基于FastAPI和Docker的机器学习模型部署快速上手
针对前文所述 机器学习模型部署摘要 中docker+fastapi部署机器学习的一个完整示例 outline fastapi简单示例 基于文件内容检测的机器学习&fastapi 在docker ...
- Nanodet模型部署(ncnn,openvino)/YOLOX部署(TensorRT)
Nanodet模型部署(ncnn,openvino) nanodet官方代码库nanodet 1. nanodet模型部署在openvino上 step1: 参考链接 nanodet官方demo op ...
随机推荐
- vue和xml复习
复习 JS知识梳理 JS定义的位置 行内js(事件名="javascript:js代码"),内部js(
- [MAUI] 混合开发概念
混合开发的概念是相对与原生开发来说的:App不直接运行原生程序,而是在原生程序中运行一个Web程序,原生程序中包含Web运行时,用于承载Web页面.暂且将原生应用称之为Web容器,Web容器应该能 ...
- inner join on 1=1 在查询中的高级用法
最近在项目中看到一个查询语句,让我有兴趣去研究.研究.查询语句如下: 重点分析第二个INNER JOIN ON 1 = 1 这个语句:内连接表示查询两个表的交集,而且ON的条件为 1=1 就表示连接 ...
- JS(DOM事件高级)
一 注册事件(绑定事件) 1.1 注册事件概述 给元素添加事件,称为注册事件或者绑定事件.注册事件有两种方式:传统方式和方法监听注册方式 1.2 addEventListener 事件监听方式 eve ...
- JS(入门)
一. 编程语言 1.1 编程 编程:就是让计算机为解决某个问题而使用某种程序设计语言编写程序代码,并最终得到结果的过程.计算机程序:就是计算机所执行的一系列的指令集合,而程序全部都是用我们所掌握的语言 ...
- 用免费GPU部署自己的stable-diffusion项目(AI生成图片)
2021年时出现了 openAI 的 DALL,但是不开源.2022年一开年,DALL-E 2发布,依然不开源.同年7月,Google 公布其 Text-to-Image 模型 Imagen,并且几乎 ...
- Apache服务器打开网页是乱码解决方案
当 Apache 服务器显示乱码时,可以使用两种方法解决: 1. 服务器端 可以在 Apache 的配置文件中添加以下内容来设置默认编码为UTF-8: AddDefaultCharset utf-8 ...
- Python表格处理模块xlrd在Anaconda中的安装
本文介绍在Anaconda环境下,安装Python读取.xls格式表格文件的库xlrd的方法. xlrd是一个用于读取Excel文件的Python库,下面是xlrd库的一些主要特点和功能: 读 ...
- 7 JavaScript循环语句
7 循环语句 在js中有三种循环语句. 首先是while循环. 它的逻辑和咱们python中的while几乎一模一样, 就是符号上有些许的区别. // 语法 while(条件){ 循环体 -> ...
- 玩转OpenHarmony智能家居:如何实现树莓派“碰一碰”设备控制
一.简介 "碰一碰"设备控制,依托NFC短距通信协议,通过碰一碰的交互方式,将OpenAtom OpenHarmony(简称"OpenHarmony")标准系统 ...