Implicit Autoencoder for Point-Cloud Self-Supervised Representation Learning论文阅读
Implicit Autoencoder for Point-Cloud Self-Supervised Representation Learning
2023 ICCV
*Siming Yan, Zhenpei Yang, Haoxiang Li, Chen Song, Li Guan, Hao Kang, Gang Hua, Qixing Huang*; Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 14530-14542
- paper: [2201.00785] Implicit Autoencoder for Point-Cloud Self-Supervised Representation Learning (arxiv.org)
- code: [SimingYan/IAE: ICCV 2023] "Implicit Autoencoder for Point-Cloud Self-Supervised Representation Learning" (github.com)
Abstract
总结 :本文专注于autoencoder框架下的点云表示模型的性能优化,提出了sample-variant issue ,即不同采样(采样是因为网络处理体量限制,需要先对数据集中的数据进行降采样)引入的噪声不同,普通的autoencoder点云表示学习方法,例如Point-MAE拟合输入和重建点云保持完全一致,导致采样中的噪声一定程度上也影响到的了encoder输出的latent code,降低了对同一目标的不同点云的语义表示一致性,换句话说: limiting the model's ability to extract valuable information about the true 3D geometry。作者基于这一点提出了对于decoder的优化,decoder原来是重建点云数据,作者换为重建输入点云的隐式表示 (SDF、UDF、occupancy grid),并且原来的Loss函数(Chamfer Distance Loss,Earth Mover`s Distance)替换为:将重建的隐式表示,和输入点云计算得到的隐式表示之间的L1 distance(for SDF,UDF),或者cross entropy(for occupancy grid)。Loss替换还有一个好处在于大大降低了计算复杂度,使得输入点云的点数能够大大增多,论文中表明点数能从1k左右 -> 40k,在tesla V100的GPU加持下。
Sample Variation Issue
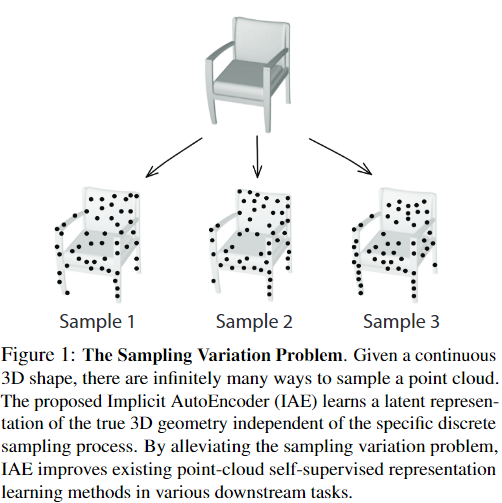
从图中不同的采样在不同位置的点云密度不同,密度大的自然网络容易学习,密度小的网络学习较为困难,但确实原来直接重建点云的方法,使得latent code不得不带有不同sample distinctive的特征描述,本文就意在解决这一问题,促使网络学习到更加generalize的特征)(for one 3D object)。
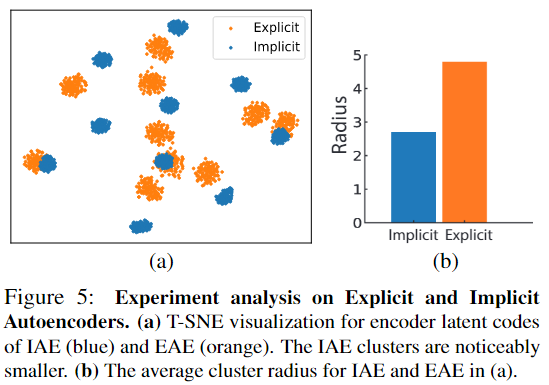
实验中显示了IAE思想的有效性,在分类任务中观察同类样本和非同类样本的特征描述相互之间的距离,可以看到IAE同类样本的聚类半径远小于显示重建点云:
Pipeline
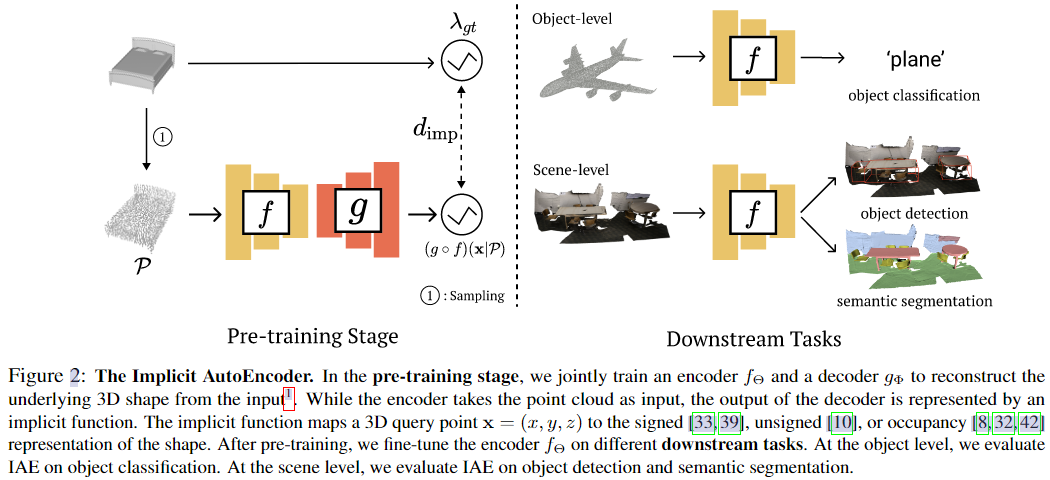
这里主要说的pretrain阶段的decoder的输出,本文主要改进的也是他,这里的 \((g \circ f)(x | \mathcal{P})\) 表示这个autoencoder-decoder架构在 \(\mathcal{P}\) 采样输入样本下的重建出来的隐式表示, \(\lambda_{gt}\) 表示使用ground truth(数据集中的数据)计算出来的隐式表示,例如SDF、UDF、occupancy grid三种:
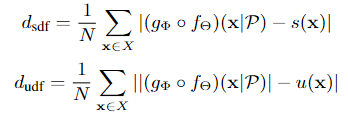
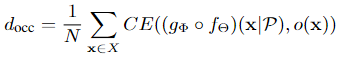
Experiment
看论文就行了,全SOTA,确实有效,并且替换其他encoder,与其他基于其encoder的方法作比较也是SOTA。
在隐式表示是occupancy grid用的decoder:

Implicit Autoencoder for Point-Cloud Self-Supervised Representation Learning论文阅读的更多相关文章
- Chinese word segment based on character representation learning 论文笔记
论文名和编号 摘要/引言 相关背景和工作 论文方法/模型 实验(数据集)及 分析(一些具体数据) 未来工作/不足 是否有源码 问题 原因 解决思路 优势 基于表示学习的中文分词 编号:1001-908 ...
- 论文解读(GRACE)《Deep Graph Contrastive Representation Learning》
Paper Information 论文标题:Deep Graph Contrastive Representation Learning论文作者:Yanqiao Zhu, Yichen Xu, Fe ...
- 论文解读(S^3-CL)《Structural and Semantic Contrastive Learning for Self-supervised Node Representation Learning》
论文信息 论文标题:Structural and Semantic Contrastive Learning for Self-supervised Node Representation Learn ...
- 论文解读(MERIT)《Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning》
论文信息 论文标题:Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning ...
- 论文解读(SUBG-CON)《Sub-graph Contrast for Scalable Self-Supervised Graph Representation Learning》
论文信息 论文标题:Sub-graph Contrast for Scalable Self-Supervised Graph Representation Learning论文作者:Yizhu Ji ...
- 论文解读(USIB)《Towards Explanation for Unsupervised Graph-Level Representation Learning》
论文信息 论文标题:Towards Explanation for Unsupervised Graph-Level Representation Learning论文作者:Qinghua Zheng ...
- 论文解读GALA《Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learning》
论文信息 Title:<Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learn ...
- 翻译 Improved Word Representation Learning with Sememes
翻译 Improved Word Representation Learning with Sememes 题目 Improved Word Representation Learning with ...
- Self-Supervised Representation Learning
Self-Supervised Representation Learning 2019-11-11 21:12:14 This blog is copied from: https://lilia ...
- (转)Predictive learning vs. representation learning 预测学习 与 表示学习
Predictive learning vs. representation learning 预测学习 与 表示学习 When you take a machine learning class, ...
随机推荐
- C语言:if(0)之后的语句真的不会执行吗?
C语言--if(0)之后的语句真的不会执行吗? 原文(有删改):https://www.cnblogs.com/CodeWorkerLiMing/p/14726960.html 前言 学过c语言的都知 ...
- NXP i.MX 8M Plus工业核心板规格书(四核ARM Cortex-A53 + 单核ARM Cortex-M7,主频1.6GHz)
1 核心板简介 创龙科技SOM-TLIMX8MP是一款基于NXP i.MX 8M Plus的四核ARM Cortex-A53 + 单核ARM Cortex-M7异构多核处理器设计的高端工业核心板, ...
- VS图片
- power bi柱形图如何设置高亮自动显示
通过度量值,将需要高亮的数据颜色设置为明显高亮于背景的颜色,将不需要设置为高亮的颜色设置为稍深于背景的颜色, 效果如下:
- AIGC的行业发展
1. AIGC的行业发展 AIGC(Artificial Intelligence Generated Content,人工智能生成内容)是利用人工智能技术来自动生成内容的一种新型内容创作方式.它基于 ...
- LabVIEW图标编辑器中的文本变得模糊
问题详述 在LabVIEW图标编辑器中将文本添加到VI图标时,如果我将字体大小设置为小于10,文本会变得模糊.当字体大小设置为大于11时,文本会正常地显示,但是字体则变得太大而无法放入图标中. 真难看 ...
- [oeasy]python0104_指示灯_显示_LED_辉光管_霓虹灯
编码进化 回忆上次内容 x86.arm.riscv等基础架构 都是二进制的 包括各种数据.指令 但是我们接触到的东西 都是屏幕显示出来的字符 计算机 显示出来的 一个个具体的字型 ...
- [oeasy]python0029_放入系统路径_PATH_chmod_程序路径_执行原理
放入路径 回忆上次内容 上次总算可以把 sleep.py 直接执行了 sleep.py文件头部要声明好打开方式 #!/usr/bin/python3 用的是 python3 解释 sleep.py ...
- ABC354
A link 模拟整个过程即可. 点击查看代码 #include<bits/stdc++.h> #define int long long using namespace std; sig ...
- 开源新纪元:Llama 3.1超大杯405B跑分惊艳,首次超越GPT-4o,下载链接曝光!
开源巨擘Llama 3.1崭露头角,性能卓越引发热议 在科技界的瞩目下,Llama 3.1系列模型以其卓越的性能脱颖而出,尤其是其405B超大杯版本,在微软Azure-ML GitHub平台的多项评测 ...