后缀数组--SA--字符串
SA (Suffix Array) -- 后缀数组
简介
这里明白两个定义:
\(SA_i\) : 按字典序排列后大小为 \(i\) 的后缀的后缀头的下标。
\(Rank_i\) : 后缀头的下标为 \(i\) 按字典序排列后的排名。
一个显而易见却很重要的结论:
\]
如何进行后缀排序?
\(O(n^2 \log n)\)
jb 方式,直接处理出所有后缀,直接 sort , 字符串匹配的时间复杂度为 \(O(n)\) , 乘在一起是 \(O(n^2\log n)\) 德
\(O(n \log^2n)\)
需要神奇的倍增做法。
这时候我们贴一个图图:
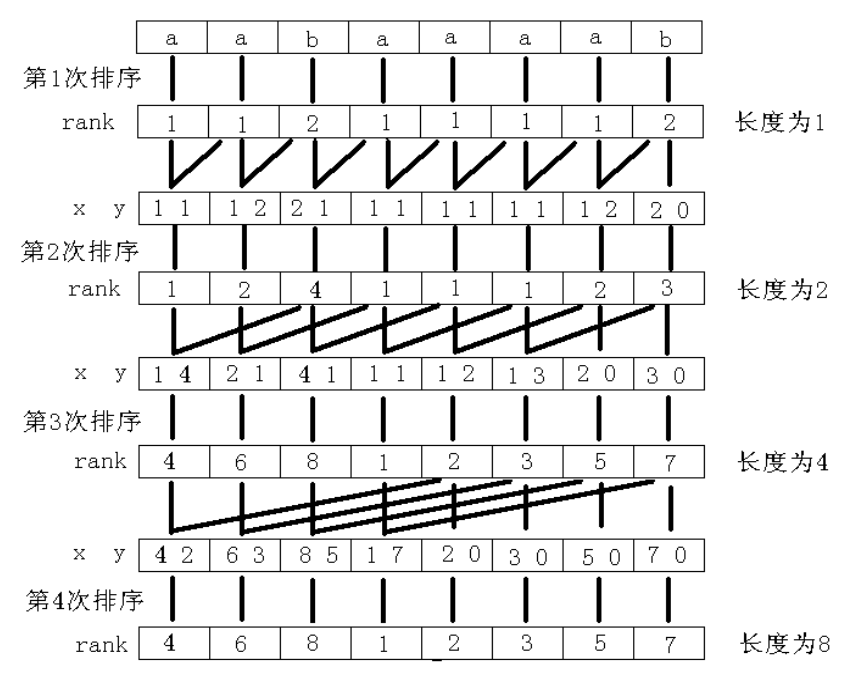
我们先从长度为 \(1\) 开始。 考虑我们更新后的为 \(2\times i\) . 所以只需要将 \(Rank_j\) 和 \(Rank_{\frac{i}{2} + j}\) 作为第一关键字和第二关键字排序即可。
\(O(n\log n)\)
我们发现那个 gb 时间复杂度变为 \(\log^2\) 多乘了一个 \(\log\) 的原因为快速排序。所以考虑 \(O(n)\) 复杂度的排序。
好的通过基数排序就可以进行 \(O(n \log n)\) 了(乐)
但是把这个玩意交到 \(LOJ\) 就发现 \(\color{yellow}T\) .
主要是因为介个玩意常数忒大。
考虑其实我们填一个这个东西本来是第一关键字排好的,其第二关键字在末尾的有可能是 \(0\) , 所以把 \(0\) 的放在最前面,剩下的按原序排好,进行一遍排序即可。
code
CODE
#include <bits/stdc++.h>
#define int long long
using namespace std ;
const int N = 2e6 + 114514 ;
inline int read() {
int x = 0 , f = 1 ;
char c = getchar() ;
while ( c < '0' || c > '9' ) {
f = c == '-' ? -f : f ;
c = getchar() ;
}
while ( c >= '0' && c <= '9' ) {
x = x * 10 + c - '0' ;
c = getchar() ;
}
return x * f ;
}
char s[N] ;
int Rank[N] , Lstrk[N] , SA[N] , n , m = 127 ;
int cnt[N] , key1[N] , id[N] , p ;
signed main() {
#ifndef ONLINE_JUDGE
freopen( "1.in" , "r" , stdin ) ;
freopen( "1.out", "w" ,stdout ) ;
#endif
auto compare = [](int x , int y , int j) {
return Lstrk[x] == Lstrk[y] && Lstrk[x + j] == Lstrk[y + j] ;
} ;
cin >> s + 1 ;
n = strlen( s + 1 ) ;
for ( int i = 1 ; i <= n ; ++ i ) { Rank[i] = s[i] ; ++ cnt[Rank[i]] ; }
for ( int i = 1 ; i <= m ; ++ i ) { cnt[i] += cnt[i - 1] ; }
for ( int i = n ; i >= 1 ; -- i ) { SA[cnt[Rank[i]] --] = i ; }
for ( int j = 1 ; ; j <<= 1 , m = p ) {
p = 0 ;
for ( int i = n ; i > n - j ; -- i ) id[++ p] = i ;
for ( int i = 1 ; i <= n ; ++ i ) {
if ( SA[i] - j > 0 ) id[++ p] = SA[i] - j ;
}
memset( cnt , 0 , sizeof(cnt) ) ;
for ( int i = 1 ; i <= n ; ++ i ) { ++ cnt[key1[i] = Rank[id[i]]] ; }
for ( int i = 1 ; i <= m ; ++ i ) { cnt[i] += cnt[i - 1] ; }
for ( int i = n ; i >= 1 ; -- i ) { SA[cnt[key1[i]] --] = id[i] ; }
memcpy( Lstrk , Rank , sizeof(Rank) ) ;
p = 0 ;
for ( int i = 1 ; i <= n ; ++ i ) {
Rank[SA[i]] = compare( SA[i] , SA[i - 1] , j ) ? p : ++ p ;
}
if ( p == n ) break ;
}
for ( int i = 1 ; i <= n ; ++ i ) {
cout << SA[i] << ' ' ;
}
}
\(height\) 数组
你会后缀排序却不会 \(height\) 数组就像你会求 \(Next\) 数组却不会 \(KMP\) 匹配一样。 —— Wang54321
定义一个东西: \(height_i\) 表示 \(Rank\) 为 \(i\) 的和 \(Rank\) 为 \(i - 1\) 的的 \(LCP\)
即 \(LCP(i , i - 1)\)
证明引理
求的话需要证一个引理:
\[height_{Rank[i]} \ge height_{Rank[i - 1]} - 1
\]
如果 \(height_{Rank[i - 1]} \le 1\) 时,这不显然嘛。
else :
我们将具体的东西表示出来:
\(height_{Rank[i]} = LCP(SA[Rank[i]] , SA[Rank[i] - 1]) = LCP(i , SA[Rank[i] - 1])\)
\(height_{Rank[i - 1]} = LCP(SA[Rank[i - 1]] , SA[Rank[i - 1] - 1]) = LCP(i - 1 , SA[Rank[i - 1] - 1])\)
我们已知 \(height_{Rank[i - 1]}\) 是 \(\ge 1\) 的,设那个 \(1\) 为 \(a\) .
所以 \(i - 1\) 可以设为 \(aAC\) , \(SA[Rank[i - 1] - 1]\) 设为 \(aAD\) .
\(aA\) 为其最长公共前缀。
我们这个 \(C\) 是 \(>\) \(D\) 的。
我们知道 \(i\) 为 \(AC\) 。且 \(SA[Rank[i] - 1]\) 和 \(AC\) 中不含有任何后缀。
所以 \(AD \le SA[Rank[i] - 1] < AC\)
所以一定含有公共前缀 \(A\) .
\(\therefore height_{Rank[i]} \ge height_{Rank[i - 1]} - 1\)
证毕.
求 \(height\)
有了上面的引理就可以求了。代码:
CODE
for ( int i = 1 , k = 0 ; i <= n ; ++ i ) {
if ( Rank[i] == 0 ) continue ;
if ( k ) k -- ;
while ( s[i + k] == s[Rank[i - 1] + k] ) k ++ ;
height[Rank[i]] = k ;
}
\(height\) 的用法
如果你只知道这是个什么玩意却不知道怎么用和不知道显然没什么区别。
一个很明显的东西:
\[LCP(l , r) = \min_{l + 1 \le i \le r}\{height_{i}\}
\]
感性理解一下:
这两段之间,如果前缀有变更,就直接没了吧,其实变更处的 \(LCP\) 就是其 \(LCP\) .
然后就可以把两个字符串的公共长度问题变为了 \(RMQ\) 问题。即 \(ST\) 表维护区间最小值了。
例题(后缀数组配合单调栈): AHOI差异
一个无脑题, \(HASH\) 可过的那种: Sandy 的卡片
结尾撒花 \(\color{pink}✿✿ヽ(°▽°)ノ✿\)
后缀数组--SA--字符串的更多相关文章
- [笔记]后缀数组SA
参考资料这次是真抄的: 1.后缀数组详解 2.后缀数组-学习笔记 3.后缀数组--处理字符串的有力工具 定义 \(SA\)排名为\(i\)的后缀的位置 \(rk\)位置为\(i\)的后缀的排名 \(t ...
- 后缀数组(SA)总结
后缀数组(SA)总结 这个东西鸽了好久了,今天补一下 概念 后缀数组\(SA\)是什么东西? 它是记录一个字符串每个后缀的字典序的数组 \(sa[i]\):表示排名为\(i\)的后缀是哪一个. \(r ...
- 后缀数组SA学习笔记
什么是后缀数组 后缀数组\(sa[i]\)表示字符串中字典序排名为\(i\)的后缀位置 \(rk[i]\)表示字符串中第\(i\)个后缀的字典序排名 举个例子: ababa a b a b a rk: ...
- 后缀数组SA入门(史上最晦涩难懂的讲解)
参考资料:victorique的博客(有一点锅无伤大雅,记得看评论区),$wzz$ 课件(快去$ftp$%%%),$oi-wiki$以及某个人的帮助(万分感谢!) 首先还是要说一句:我不知道为什么我这 ...
- 【字符串】后缀数组SA
后缀数组 概念 实际上就是将一个字符串的所有后缀按照字典序排序 得到了两个数组 \(sa[i]\) 和 \(rk[i]\),其中 \(sa[i]\) 表示排名为 i 的后缀,\(rk[i]\) 表示后 ...
- poj 3518 Corporate Identity 后缀数组->多字符串最长相同连续子串
题目链接 题意:输入N(2 <= N <= 4000)个长度不超过200的字符串,输出字典序最小的最长公共连续子串; 思路:将所有的字符串中间加上分隔符,注:分隔符只需要和输入的字符不同, ...
- bzoj3796(后缀数组)(SA四连)
bzoj3796Mushroom追妹纸 题目描述 Mushroom最近看上了一个漂亮妹纸.他选择一种非常经典的手段来表达自己的心意——写情书.考虑到自己的表达能力,Mushroom决定不手写情书.他从 ...
- poj 3294 后缀数组 多字符串中不小于 k 个字符串中的最长子串
Life Forms Time Limit: 5000MS Memory Limit: 65536K Total Submissions: 16223 Accepted: 4763 Descr ...
- Codeforces VK Cup 2015 A.And Yet Another Bracket Sequence(后缀数组+平衡树+字符串)
这题做得比较复杂..应该有更好的做法 题目大意: 有一个括号序列,可以对其进行两种操作: · 向里面加一个括号,可以在开头,在结尾,在两个括号之间加. · 对当前括号序列进 ...
- POJ2774 Long Long Message —— 后缀数组 两字符串的最长公共子串
题目链接:https://vjudge.net/problem/POJ-2774 Long Long Message Time Limit: 4000MS Memory Limit: 131072 ...
随机推荐
- C# Linq俩个list<Datarow> 取差集,并自定义字段
可以自定义类 ,也可以从参考官网文档:Enumerable.Except 方法 (System.Linq) | Microsoft Learn List<DataRow> list1 = ...
- Python使用Argparse读取命令参数
python编写的脚本需要通过命令参数来做一些参数配置.本文将介绍如何使用argparse来解析命令行参数.这种方法相对于sys.args的方式会简单很多. 通过以下的脚本来构建一个简单的配置解析器, ...
- Elastic-Search 整理(二):高级篇
ES高级篇 集群部署 集群的意思:就是将多个节点归为一体罢了,这个整体就有一个指定的名字了 window中部署集群 - 了解 把下载好的window版的ES中的data文件夹.logs文件夹下的所有的 ...
- Linux 更新网络时间
下载包 yum install -y ntpdate 同步网络时间 ntpdate 0.asia.pool.ntp.org 若上面的时间服务器不可用,也可以改用如下服务器进行同步: time.nist ...
- Oracle 触发器 before insert update
场景,往A表插入数据时,A表和B表是同一类型的状态下,A表中累计的值,不能超过B表中的值(注:往数据库插入时,不能批量执行事务!),利用触发器before insert update,监控状态,若超过 ...
- (五)Redis 缓存异常、应对策略
1.缓存和数据库不一致 只要我们使用 Redis 缓存,就必然会面对缓存和数据库间的一致性保证问题,这里的"一致性"包含了两种情况:缓存中有数据且与数据库中的值相同.缓存中没有数据 ...
- 解决方案 | AutoCAD二次开发的ProgID一览表(AutoCAD2004 ~ AutoCAD2024)
1 图片版本 2 文字版本 AutoCAD产品名 版本号 ProgID AutoCAD 2004 R16 AutoCAD.Application.16 AutoCAD 2005 R16.1 AutoC ...
- TP3.2与TP5.0的区别
1. 控制器输出return $this->fetch(); ----5$this->display(); ----3.2单字母函数去掉了 如:M() D() U() S() C() 3. ...
- [oeasy]python0020换行字符_feed_line_lf_反斜杠n_B语言_安徒生童话
换行字符 回忆上次内容 struct包可以让我们使用封包格式 把数字封包到字节里 pack函数负责封包 unpack函数负责解封 我们通过封到不同的字节状态 遍历了一次ascii码 编辑 还是 ...
- [rCore学习笔记 09]为内核支持函数调用
在[[08 内核第一条指令|上一节]]我们使用了编写entry.asm函数中编写了内核的第一条指令,但是我们使用的汇编.这里注意我们仍然是嵌入了这段asm代码到我们的rust代码之中,然后进行编译.但 ...