高性能无锁队列 Disruptor 核心原理分析及其在i主题业务中的应用
作者:来自 vivo 互联网服务器团队- Li Wanghong
本文首先介绍了 Disruptor 高性能内存队列的基本概念、使用 Demo、高性能原理及源码分析,最后通过两个例子介绍了 Disruptor 在i主题业务中的应用。
一、i主题及 Disruptor 简介
i主题是 vivo 旗下的一款主题商店 app,用户可以通过下载主题、壁纸、字体等,实现对手机界面风格的一键更换和自定义。
Disruptor 是英国外汇交易公司 LMAX 开发的一个高性能的内存队列(用于系统内部线程间传递消息,不同于 RocketMQ、Kafka 这种分布式消息队列),基于 Disruptor 开发的系统单线程能支撑每秒600万订单。目前,包括 Apache Storm、Camel、Log4j 2在内的很多知名项目都应用了 Disruptor 以获取高性能。在 vivo 内部它也有不少应用,比如自定义监控中使用 Disruptor 队列来暂存通过监控 SDK 上报的监控数据,i主题中也使用它来统计本地内存指标数据。
接下来从 Disruptor 和 JDK 内置队列的对比、Disruptor 核心概念、Disruptor 使用Demo、Disruptor 核心源码、Disruptor 高性能原理、Disruptor 在 i主题业务中的应用几个角度来介绍 Disruptor。
二、和 JDK 中内置的队列对比
下面来看下 JDK 中内置的队列和 Disruptor 的对比。队列的底层实现一般分为三种:数组、链表和堆,其中堆一般是为了实现带有优先级特性的队列,暂不考虑。另外,像 ConcurrentLinkedQueue 、LinkedTransferQueue 属于无界队列,在稳定性要求特别高的系统中,为了防止生产者速度过快,导致内存溢出,只能选择有界队列。这样 JDK 中剩下可选的线程安全的队列还有ArrayBlockingQueue 和 LinkedBlockingQueue。
由于 LinkedBlockingQueue 是基于链表实现的,由于链表存储的数据在内存里不连续,对于高速缓存并不友好,而且 LinkedBlockingQueue 是加锁的,性能较差。ArrayBlockingQueue 有同样的问题,它也需要加锁,另外,ArrayBlockingQueue 存在伪共享问题,也会导致性能变差。而今天要介绍的 Disruptor 是基于数组的有界无锁队列,符合空间局部性原理,可以很好的利用 CPU 的高速缓存,同时它避免了伪共享,大大提升了性能。
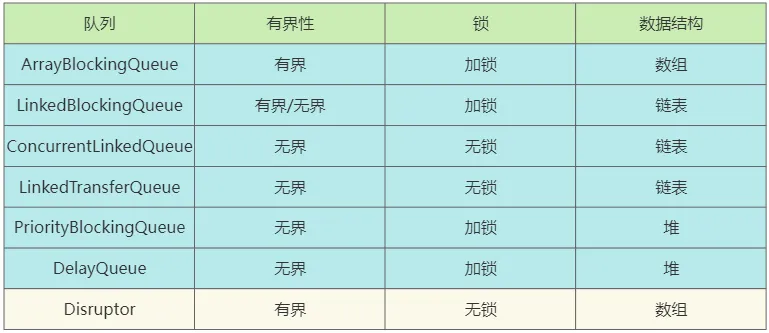
三、Disruptor 核心概念
如下图,从数据流转的角度先对 Disruptor 有一个直观的概念。Disruptor 支持单(多)生产者、单(多)消费者模式。消费时支持广播消费(HandlerA 会消费处理所有消息,HandlerB 也会消费处理所有消息)、集群消费(HandlerA 和 HandlerB 各消费部分消息),HandlerA 和HandlerB 消费完成后会把消息交给 HandlerC 继续处理。
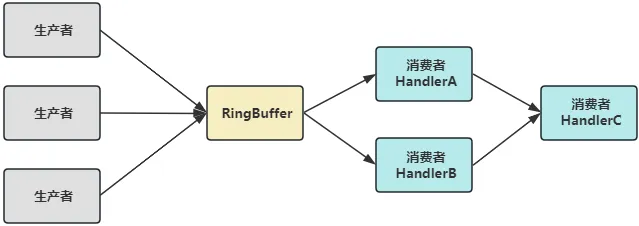
下面结合 Disruptor 官方的架构图介绍下 Disruptor 的核心概念:
RingBuffer:前文说 Disruptor 是一个高性能内存内存队列,而 RingBuffer 就是该内存队列的数据结构,它是一个环形数组,是承载数据的载体。
Producer:Disruptor 是典型的生产者消费者模型。因此生产者是 Disruptor 编程模型中的核心组成,可以是单生产者,也可以多生产者。
Event:具体的数据实体,生产者生产 Event ,存入 RingBuffer,消费者从 RingBuffer 中消费它进行逻辑处理。
Event Handler:开发者需要实现 EventHandler 接口定义消费者处理逻辑。
Wait Strategy:等待策略,定义了当消费者无法从 RingBuffer 获取数据时,如何等待。
Event Processor:事件循环处理器,EventProcessor 继承了 Runnable 接口,它的子类实现了 run 方法,内部有一个 while 循环,不断尝试从 RingBuffer 中获取数据,交给 EventHandler 去处理。
Sequence:RingBuffer 是一个数组,Sequence (序号)就是用来标记生产者数据生产到哪了,消费者数据消费到哪了。
Sequencer:分为单生产者和多生产者两种实现,生产者发布数据时需要先申请下可用序号,Sequencer 就是用来协调申请序号的。
Sequence Barrier:见下文分析。
四、Disruptor 使用 Demo
4.1 定义 Event
Event 是具体的数据实体,生产者生产 Event ,存入 RingBuffer,消费者从 RingBuffer 中消费它进行逻辑处理。Event 就是一个普通的 Java 对象,无需实现 Disruptor 内定义的接口。
public class OrderEvent {
private long value;
public long getValue() {
return value;
}
public void setValue(long value) {
this.value = value;
}
}4.2 定义 EventFactory
用于创建 Event 对象。
public class OrderEventFactory implements EventFactory<OrderEvent> {
public OrderEvent newInstance() {
return new OrderEvent();
}
}4.3 定义生产者
可以看到,生成者主要是持有 RingBuffer 对象进行数据的发布。这里有几个点需要注意:
RingBuffer 内部维护了一个 Object 数组(也就是真正存储数据的容器),在 RingBuffer 初始化时该 Object 数组就已经使用 EventFactory 初始化了一些空 Event,后续就不需要在运行时来创建了,提高性能。因此这里通过 RingBuffer 获取指定序号得到的是一个空对象,需要对它进行赋值后,才能进行发布。
这里通过 RingBuffer 的 next 方法获取可用序号,如果 RingBuffer 空间不足会阻塞。
通过 next 方法获取序号后,需要确保接下来使用 publish 方法发布数据。
public class OrderEventProducer {
private RingBuffer<OrderEvent> ringBuffer;
public OrderEventProducer(RingBuffer<OrderEvent> ringBuffer) {
this.ringBuffer = ringBuffer;
}
public void sendData(ByteBuffer data) {
// 1、在生产者发送消息的时候, 首先需要从我们的ringBuffer里面获取一个可用的序号
long sequence = ringBuffer.next();
try {
//2、注意此时获取的OrderEvent对象是一个没有被赋值的空对象
OrderEvent event = ringBuffer.get(sequence);
//3、进行实际的赋值处理
event.setValue(data.getLong(0));
} finally {
//4、 提交发布操作
ringBuffer.publish(sequence);
}
}
}4.4 定义消费者
消费者可以实现 EventHandler 接口,定义自己的处理逻辑。
public class OrderEventHandler implements EventHandler<OrderEvent> {
public void onEvent(OrderEvent event,
long sequence,
boolean endOfBatch) throws Exception {
System.out.println("消费者: " + event.getValue());
}
}4.5 主流程
首先初始化一个 Disruptor 对象,Disruptor 有多个重载的构造函数。支持传入 EventFactory 、ringBufferSize (需要是2的幂次方)、executor(用于执行EventHandler 的事件处理逻辑,一个 EventHandler 对应一个线程,一个线程只服务于一个 EventHandler )、生产者模式(支持单生产者、多生产者)、阻塞等待策略。在创建 Disruptor 对象时,内部会创建好指定 size 的 RingBuffer 对象。
定义 Disruptor 对象之后,可以通过该对象添加消费者 EventHandler。
启动 Disruptor,会将第2步添加的 EventHandler 消费者封装成 EventProcessor(实现了 Runnable 接口),提交到构建 Disruptor 时指定的 executor 对象中。由于 EventProcessor 的 run 方法是一个 while 循环,不断尝试从RingBuffer 中获取数据。因此可以说一个 EventHandler 对应一个线程,一个线程只服务于一个EventHandler。
拿到 Disruptor 持有的 RingBuffer,然后就可以创建生产者,通过该RingBuffer就可以发布生产数据了,然后 EventProcessor 中启动的任务就可以消费到数据,交给 EventHandler 去处理了。
public static void main(String[] args) {
OrderEventFactory orderEventFactory = new OrderEventFactory();
int ringBufferSize = 4;
ExecutorService executor = Executors.newFixedThreadPool(1);
/**
* 1. 实例化disruptor对象
1) eventFactory: 消息(event)工厂对象
2) ringBufferSize: 容器的长度
3) executor:
4) ProducerType: 单生产者还是多生产者
5) waitStrategy: 等待策略
*/
Disruptor<OrderEvent> disruptor = new Disruptor<OrderEvent>(orderEventFactory,
ringBufferSize,
executor,
ProducerType.SINGLE,
new BlockingWaitStrategy());
// 2. 添加消费者的监听
disruptor.handleEventsWith(new OrderEventHandler());
// 3. 启动disruptor
disruptor.start();
// 4. 获取实际存储数据的容器: RingBuffer
RingBuffer<OrderEvent> ringBuffer = disruptor.getRingBuffer();
OrderEventProducer producer = new OrderEventProducer(ringBuffer);
ByteBuffer bb = ByteBuffer.allocate(8);
for (long i = 0; i < 5; i++) {
bb.putLong(0, i);
producer.sendData(bb);
}
disruptor.shutdown();
executor.shutdown();
}五、Disruptor 源码分析
本文分析时以单(多)生产者、单消费者为例进行分析。
5.1 创建 Disruptor
首先是通过传入的参数创建 RingBuffer,将创建好的 RingBuffer 与传入的 executor 交给 Disruptor 对象持有。
public Disruptor(
final EventFactory<T> eventFactory,
final int ringBufferSize,
final Executor executor,
final ProducerType producerType,
final WaitStrategy waitStrategy){
this(RingBuffer.create(producerType, eventFactory, ringBufferSize, waitStrategy),
executor);
}接下来分析 RingBuffer 的创建过程,分为单生产者与多生产者。
public static <E> RingBuffer<E> create(
ProducerType producerType,
EventFactory<E> factory,
int bufferSize,
WaitStrategy waitStrategy){
switch (producerType){
case SINGLE:
// 单生产者
return createSingleProducer(factory, bufferSize, waitStrategy);
case MULTI:
// 多生产者
return createMultiProducer(factory, bufferSize, waitStrategy);
default:
throw new IllegalStateException(producerType.toString());
}
}不论是单生产者还是多生产者,最终都会创建一个 RingBuffer 对象,只是传给 RingBuffer 的 Sequencer 对象不同。可以看到,RingBuffer 内部最终创建了一个Object 数组来存储 Event 数据。这里有几点需要注意:
RingBuffer 是用数组实现的,在创建该数组后紧接着调用 fill 方法调用 EventFactory 工厂方法为数组中的元素进行初始化,后续在使用这些元素时,直接通过下标获取并给对应的属性赋值,这样就避免了 Event 对象的反复创建,避免频繁 GC。
RingBuffe 的数组中的元素是在初始化时一次性全部创建的,所以这些元素的内存地址大概率是连续的。消费者在消费时,是遵循空间局部性原理的。消费完第一个Event 时,很快就会消费第二个 Event,而在消费第一个 Event 时,CPU 会把内存中的第一个 Event 的后面的 Event 也加载进 Cache 中,这样当消费第二个 Event时,它已经在 CPU Cache 中了,所以就不需要从内存中加载了,这样可以大大提升性能。
public static <E> RingBuffer<E> createSingleProducer(
EventFactory<E> factory, int bufferSize, WaitStrategy waitStrategy){
SingleProducerSequencer sequencer = new SingleProducerSequencer(bufferSize,
waitStrategy);
return new RingBuffer<E>(factory, sequencer);
}RingBufferFields(
EventFactory<E> eventFactory,
Sequencer sequencer){
// 省略部分代码...
// 额外创建2个填充空间的大小, 首尾填充, 避免数组的有效载荷和其它成员加载到同一缓存行
this.entries = new Object[sequencer.getBufferSize() + 2 * BUFFER_PAD];
fill(eventFactory);
}
private void fill(EventFactory<E> eventFactory){
for (int i = 0; i < bufferSize; i++){
// BUFFER_PAD + i为真正的数组索引
entries[BUFFER_PAD + i] = eventFactory.newInstance();
}
}5.2 添加消费者
添加消费者的核心代码如下所示,核心就是为将一个 EventHandler 封装成 BatchEventProcessor,
然后添加到 consumerRepository 中,后续启动 Disruptor 时,会遍历 consumerRepository 中的所有 BatchEventProcessor(实现了 Runnable 接口),将 BatchEventProcessor 任务提交到线程池中。
public final EventHandlerGroup<T> handleEventsWith(
final EventHandler<? super T>... handlers){
// 通过disruptor对象直接调用handleEventsWith方法时传的是空的Sequence数组
return createEventProcessors(new Sequence[0], handlers);
}EventHandlerGroup<T> createEventProcessors(
final Sequence[] barrierSequences,
final EventHandler<? super T>[] eventHandlers) {
// 收集添加的消费者的序号
final Sequence[] processorSequences = new Sequence[eventHandlers.length];
// 本批次消费由于添加在同一个节点之后, 因此共享该屏障
final SequenceBarrier barrier = ringBuffer.newBarrier(barrierSequences);
// 为每个EventHandler创建一个BatchEventProcessor
for (int i = 0, eventHandlersLength = eventHandlers.length;
i < eventHandlersLength; i++) {
final EventHandler<? super T> eventHandler = eventHandlers[i];
final BatchEventProcessor<T> batchEventProcessor =
new BatchEventProcessor<>(ringBuffer, barrier, eventHandler);
if (exceptionHandler != null){
batchEventProcessor.setExceptionHandler(exceptionHandler);
}
// 添加到消费者信息仓库中
consumerRepository.add(batchEventProcessor, eventHandler, barrier);
processorSequences[i] = batchEventProcessor.getSequence();
}
// 更新网关序列(生产者只需要关注所有的末端消费者节点的序列)
updateGatingSequencesForNextInChain(barrierSequences, processorSequences);
return new EventHandlerGroup<>(this, consumerRepository, processorSequences);
}创建完 Disruptor 对象之后,可以通过 Disruptor 对象添加 EventHandler,这里有一需要注意:通过 Disruptor 对象直接调用 handleEventsWith 方法时传的是空的 Sequence 数组,这是什么意思?可以看到 createEventProcessors 方法接收该空 Sequence 数组的字段名是 barrierSequences,翻译成中文就是栅栏序号。怎么理解这个字段?
比如通过如下代码给 Disruptor 添加了两个handler,记为 handlerA 和 handlerB,这种是串行消费,对于一个 Event,handlerA 消费完后才能轮到 handlerB 去消费。对于 handlerA 来说,它没有前置消费者(生成者生产到哪里,消费者就可以消费到哪里),因此它的 barrierSequences 是一个空数组。而对于 handlerB 来说,它的前置消费者是 handlerA,因此它的 barrierSequences 就是A的消费进度,也就是说 handlerB 的消费进度是要小于 handlerA 的消费进度的。

disruptor.handleEventsWith(handlerA).handleEventsWith(handlerB);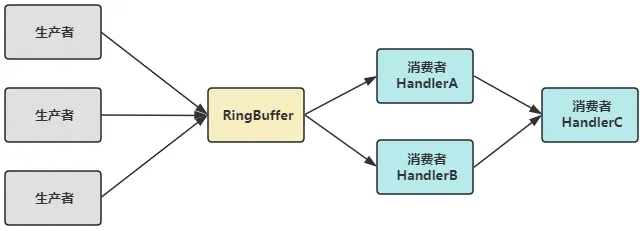
5.3 启动 Disruptor
Disruptor的启动逻辑比较简洁,就是遍历consumerRepository 中收集的 EventProcessor(实现了Runnable接口),将它提交到创建 Disruptor 时指定的executor 中,EventProcessor 的 run 方法会启动一个while 循环,不断尝试从 RingBuffer 中获取数据进行消费。
disruptor.start();public RingBuffer<T> start() {
checkOnlyStartedOnce();
for (final ConsumerInfo consumerInfo : consumerRepository) {
consumerInfo.start(executor);
}
return ringBuffer;
}
public void start(final Executor executor) {
executor.execute(eventprocessor);
}5.4 发布数据
在分析 Disruptor 的发布数据的源码前,先来回顾下发布数据的整体流程。
调用 next 方法获取可用序号,该方法可能会阻塞。
通过上一步获得的序号从 RingBuffer 中获取对应的 Event,因为 RingBuffer 中所有的 Event 在初始化时已经创建好了,这里获取的只是空对象。
因此接下来需要对该空对象进行业务赋值。
调用 next 方法需要在 finally 方法中进行最终的发布,标记该序号数据已实际生产完成。
public void sendData(ByteBuffer data) {
long sequence = ringBuffer.next();
try {
OrderEvent event = ringBuffer.get(sequence);
event.setValue(data.getLong(0));
} finally {
ringBuffer.publish(sequence);
}
}5.4.1 获取序号
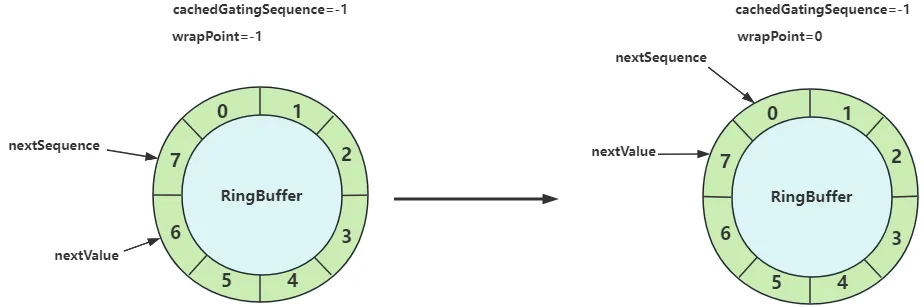
next 方法默认申请一个序号。nextValue 表示已分配的序号,nextSequence 表示在此基础上再申请n个序号(此处n为1),cachedValue 表示缓存的消费者的最小消费进度。
假设有一个 size 为8的 RingBuffer,当前下标为6的数据已经发布好(nextValue为6),消费者一直未开启消费(cachedValue 和 cachedGatingSequence 为-1),此时生产者想继续发布数据,调用 next() 方法申请获取序号为7的位置(nextSequence为7),计算得到的 wrapPoint 为7-8=-1,此时 wrapPoint 等于 cachedGatingSequence,可以继续发布数据,如左图。最后将 nextValue 赋值为7,表示序号7的位置已经被生产者占用了。
接着生产者继续调用 next() 方法申请序号为0的数据,此时 nextValue为7,nextSequence 为8,wrapPoint 等于0,由于消费者迟迟未消费(cachedGatingSequence为-1),此时 wrapPoint 大于了 cachedGatingSequence,因此 next 方法的if判断成立,会调用 LockSupport.parkNanos 阻塞等待消费者进行消费。其中 getMinimumSequence 方法是获取多个消费者的最小消费进度。
public long next() {
return next(1);
}public long next(int n) {
/**
* 已分配的序号的缓存(已分配到这里), 初始-1. 可以看该方法的返回值nextSequence,
* 接下来生产者就会该往该位置写数据, 它赋值给了nextValue, 所以下一次调用next方
* 法时, nextValue位置就是表示已经生产好了数据, 接下来要申请nextSequece的数据
*/
long nextValue = this.nextValue;
// 本次申请分配的序号
long nextSequence = nextValue + n;
// 构成环路的点:环形缓冲区可能追尾的点 = 等于本次申请的序号-环形缓冲区大小
// 如果该序号大于最慢消费者的进度, 那么表示追尾了, 需要等待
long wrapPoint = nextSequence - bufferSize;
// 上次缓存的最小网关序号(消费最慢的消费者的进度)
long cachedGatingSequence = this.cachedValue;
// wrapPoint > cachedGatingSequence 表示生产者追上消费者产生环路(追尾), 即缓冲区已满,
// 此时需要获取消费者们最新的进度, 以确定是否队列满
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > nextValue) {
// 插入StoreLoad内存屏障/栅栏, 保证可见性。
// 因为publish使用的是set()/putOrderedLong, 并不保证其他消费者能及时看见发布的数据
// 当我再次申请更多的空间时, 必须保证消费者能消费发布的数据
cursor.setVolatile(nextValue);
long minSequence;
// minSequence是多个消费者的最小序号, 要等所有消费者消费完了才能继续生产
while (wrapPoint > (minSequence = Util.getMinimumSequence(gatingSequences,
nextValue))) {
LockSupport.parkNanos(1L);
}
// 缓存生产者们最新的消费进度
this.cachedValue = minSequence;
}
// 这里只写了缓存, 并未写volatile变量, 因为只是预分配了空间但是并未被发布数据,
// 不需要让其他消费者感知到。消费者只会感知到真正被发布的序号
this.nextValue = nextSequence;
return nextSequence;
}5.4.2 根据序号获取 Event
直接通过 Unsafe 工具类获取指定序号的 Event 对象,此时获取的是空对象,因此接下来需要对该 Event 对象进行业务赋值,赋值完成后调用 publish 方法进行最终的数据发布。
OrderEvent event = ringBuffer.get(sequence);public E get(long sequence) {
return elementAt(sequence);
}protected final E elementAt(long sequence) {
return (E) UNSAFE.getObject(entries,
REF_ARRAY_BASE +
((sequence & indexMask) << REF_ELEMENT_SHIFT));
}5.4.3 发布数据
生产者获取到可用序号后,首先对该序号处的空 Event 对象进行业务赋值,接着调用 RingBuffer 的 publish 方法发布数据,RingBuffer 会委托给其持有的 sequencer(单生产者和多生产者对应不同的 sequencer)对象进行真正发布。单生产者的发布逻辑比较简单,更新下 cursor 进度(cursor 表示生产者的生产进度,该位置已实际发布数据,而 next 方法中的 nextSequence 表示生产者申请的最大序号,可能还未实际发布数据),接着唤醒等待的消费者。
waitStrategy 有不同的实现,因此唤醒逻辑也不尽相同,如采用 BusySpinWaitStrategy 策略时,消费者获取不到数据时自旋等待,然后继续判断是否有新数据可以消费了,因此 BusySpinWaitStrategy 策略的 signalAllWhenBlocking 就是一个空实现,啥也不做。
ringBuffer.publish(sequence);public void publish(long sequence) {
sequencer.publish(sequence);
}public void publish(long sequence) {
// 更新生产者进度
cursor.set(sequence);
// 唤醒等待的消费者
waitStrategy.signalAllWhenBlocking();
}5.4.4 消费数据
前面提到,Disruptor 启动时,会将封装 EventHandler 的EventProcessor(此处以 BatchEventProcessor 为例)提交到线程池中运行,BatchEventProcessor 的 run 方法会调用 processEvents 方法不断尝试从 RingBuffer 中获取数据进行消费,下面分析下 processEvents 的逻辑(代码做了精简)。它会开启一个 while 循环,调用 sequenceBarrier.waitFor 方法获取最大可用的序号,比如获取序号一节所提的,生产者持续生产,消费者一直未消费,此时生产者已经将整个 RingBuffer 数据都生产满了,生产者无法再继续生产,生产者此时会阻塞。假设这时候消费者开始消费,因此 nextSequence 为0,而 availableSequence 为7,此时消费者可以批量消费,将这8条已生产者的数据全部消费完,消费完成后更新下消费进度。更新消费进度后,生产者通过 Util.getMinimumSequence 方法就可以感知到最新的消费进度,从而不再阻塞,继续发布数据了。
private void processEvents() {
T event = null;
// sequence记录消费者的消费进度, 初始为-1
long nextSequence = sequence.get() + 1L;
// 死循环,因此不会让出线程,需要独立的线程(每一个EventProcessor都需要独立的线程)
while (true) {
// 通过屏障获取到的最大可用序号
final long availableSequence = sequenceBarrier.waitFor(nextSequence);
// 批量消费
while (nextSequence <= availableSequence) {
event = dataProvider.get(nextSequence);
eventHandler.onEvent(event, nextSequence, nextSequence == availableSequence);
nextSequence++;
}
// 更新消费进度(批量消费, 每次消费只更新一次Sequence, 减少性能消耗)
sequence.set(availableSequence);
}
}下面分析下 SequenceBarrier 的 waitFor 方法。首先它会调用 waitStrategy 的 waitFor 方法获取最大可用序号,以 BusySpinWaitStrategy 策略为例,它的 waitFor 方法的三个参数的含义分别是:
sequence:消费者期望获得的序号,也就是当前消费者已消费的进度+1
cursor:当前生产者的生成进度
dependentSequence:消费者依赖的前置消费者的消费进度。该字段是在添加 EventHandler,创建BatchEventProcessor 时创建的。如果当前消费者没有前置依赖的消费者,那么它只需要关心生产者的进度,生产者生产到哪里,它就可以消费到哪里,因此 dependentSequence 就是 cursor。而如果当前消费者有前置依赖的消费者,那么dependentSequence就是FixedSequenceGroup(dependentSequences)。
因为 dependentSequence 分为两种情况,所以 waitFor 的逻辑也可以分为两种情况讨论:
当前消费者无前置消费者:假设 cursor 为6,也就是序号为6的数据已经发布了数据,此时传入的sequence为6,则waitFor方法可以直接返回availableSequence(6),可以正常消费。序号为6的数据消费完成后,消费者继续调用 waitFor 获取数据,传入的 sequence为7,而此时 availableSequence 还是未6,因此消费者需要自旋等待。当生产者继续发布数据后,因为 dependentSequence 持有的就是生产者的生成进度,因此消费者可以感知到,继续消费。
当前消费者有前置消费者:假设 cursor 为6,当前消费者C有两个前置依赖的消费者A(消费进度为5)、B(消费进度为4),那么此时 availableSequence(FixedSequenceGroup实例,它的 get 方法是获取A、B的最小值,也就是4)为4。如果当前消费者C期望消费下标为4的数据,则可以正常消费,但是消费下标为5的数据就不行了,它需要等待它的前置消费者B消费完进度为5的数据后才能继续消费。
在 waitStrategy 的 waitFor 方法返回,得到最大可用的序号 availableSequence 后,最后需要再调用下 sequencer 的 getHighestPublishedSequence 获取真正可用的最大序号,这和生产者模型有关系,如果是单生产者,因为数据是连续发布的,直接返回传入的 availableSequence。而如果是多生产者,因为多生产者是有多个线程在生产数据,发布的数据是不连续的,因此需要通过 过getHighestPublishedSequence 方法获取已发布的且连续的最大序号,因为获取序号进行消费时需要是顺序的,不能跳跃。
public long waitFor(final long sequence)
throws AlertException, InterruptedException, TimeoutException {
/**
* sequence: 消费者期望获取的序号
* cursorSequence: 生产者的序号
* dependentSequence: 消费者需要依赖的序号
*/
long availableSequence = waitStrategy.waitFor(sequence,
cursorSequence,
dependentSequence, this);
if (availableSequence < sequence) {
return availableSequence;
}
// 目标sequence已经发布了, 这里获取真正的最大序号(和生产者模型有关)
return sequencer.getHighestPublishedSequence(sequence, availableSequence);
}public long waitFor(
final long sequence, Sequence cursor, final Sequence dependentSequence,
final SequenceBarrier barrier) throws AlertException, InterruptedException {
long availableSequence;
// 确保该序号已经被我前面的消费者消费(协调与其他消费者的关系)
while ((availableSequence = dependentSequence.get()) < sequence) {
barrier.checkAlert();
// 自旋等待
ThreadHints.onSpinWait();
}
return availableSequence;
}六、Disruptor 高性能原理分析
6.1 空间预分配
前文分析源码时介绍到,RingBuffer 内部维护了一个 Object 数组(也就是真正存储数据的容器),在 RingBuffer 初始化时该 Object 数组就已经使用EventFactory 初始化了一些空 Event,后续就不需要在运行时来创建了,避免频繁GC。
另外,RingBuffe 的数组中的元素是在初始化时一次性全部创建的,所以这些元素的内存地址大概率是连续的。消费者在消费时,是遵循空间局部性原理的。消费完第一个Event 时,很快就会消费第二个 Event,而在消费第一个 Event 时,CPU 会把内存中的第一个 Event 的后面的 Event 也加载进 Cache 中,这样当消费第二个 Event 时,它已经在 CPU Cache 中了,所以就不需要从内存中加载了,这样也可以大大提升性能。
6.2 避免伪共享
6.2.1 一个伪共享的例子
如下代码所示,定义了一个 Pointer 类,它有2个 long 类型的成员变量x、y,然后在 main 方法中其中2个线程分别对同一个 Pointer 对象的x和y自增 100000000 次,最后统计下方法耗时,在我本机电脑上测试多次,平均约为3600ms。
public class Pointer {
volatile long x;
volatile long y;
@Override
public String toString() {
return new StringJoiner(", ", Pointer.class.getSimpleName() + "[", "]")
.add("x=" + x)
.add("y=" + y)
.toString();
}
}public static void main(String[] args) throws InterruptedException {
Pointer pointer = new Pointer();
int num = 100000000;
long start = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
for(int i = 0; i < num; i++){
pointer.x++;
}
});
Thread t2 = new Thread(() -> {
for(int i = 0; i < num; i++){
pointer.y++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(System.currentTimeMillis() - start);
System.out.println(pointer);
}接着将 Pointer 类修改如下:在变量x和y之间插入7个 long 类型的变量,仅此而已,接着继续通过上述的 main 方法统计耗时,平均约为500ms。可以看到,修改前的耗时是修改后(避免了伪共享)的7倍多。那么什么是伪共享,为什么避免了伪共享能有这么大的性能提升呢?
public class Pointer {
volatile long x;
long p1, p2, p3, p4, p5, p6, p7;
volatile long y;
@Override
public String toString() {
return new StringJoiner(", ", Pointer.class.getSimpleName() + "[", "]")
.add("x=" + x)
.add("y=" + y)
.toString();
}
}6.2.2 避免伪共享为什么可以提升性能
内存的访问速度是远远慢于 CPU 的,为了高效利用 CPU,在 CPU 和内存之间加了缓存,称为 CPU Cache。为了提高性能,需要更多地从 CPU Cache 里获取数据,而不是从内存中获取数据。CPU Cache 加载内存里的数据,是以缓存行(通常为64字节)为单位加载的。Java 的 long 类型是8字节,因此一个缓存行可以存放8个 long 类型的变量。
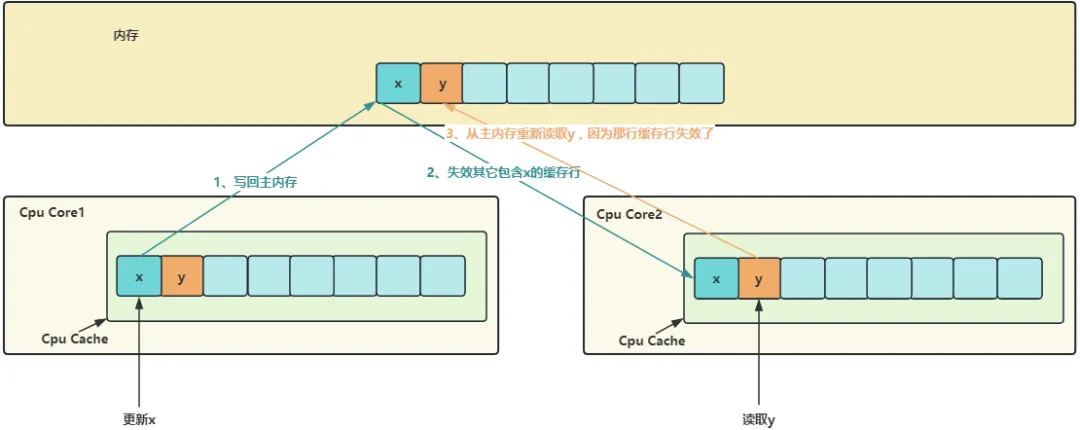
但是,这种加载带来了一个坏处,如上述例子所示,假设有一个 long 类型的变量x,另外还有一个 long 类型的变量y紧挨着它,那么当加载x时也会加载y。如果此时 CPU Core1 的线程在对x进行修改,另一个 CPU Core2 的线程却在对y进行读取。当前者修改x时,会把x和y同时加载到 CPU Core1 对应的 CPU Cache 中,更新完后x和其它所有包含x的缓存行都将失效。而当 CPU Core2 的线程读取y时,发现这个缓存行已经失效了,需要从主内存中重新加载。
这就是伪共享,x和y不相干,但是却因为x的更新导致需要重新从主内存读取,拖慢了程序性能。解决办法之一就是如上述示例中所做,在x和y之间填充7个 long 类型的变量,保证x和y不会被加载到同一个缓存行中去。Java8 中也增加了新的注解@Contended(JVM加上启动参数-XX:-RestrictContended 才会生效),也可以避免伪共享。
6.2.3 Disruptor 中使用伪共享的场景
Disruptor 中使用 Sequence 类的 value 字段来表示生产/消费进度,可以看到在该字段前后各填充了7个 long 类型的变量,来避免伪共享。另外,向 RingBuffer 内部的数组、
SingleProducerSequencer 等也使用了该技术。
class LhsPadding {
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding {
protected volatile long value;
}
class RhsPadding extends Value {
protected long p9, p10, p11, p12, p13, p14, p15;
}6.3 无锁
生产者生产数据时,需要入队。消费者消费数据时,需要出队。入队时,不能覆盖没有消费的元素。出队时,不能读取没有写入的元素。因此,Disruptor 中需要维护一个入队索引(生产者数据生产到哪里,对应 AbstractSequencer 中的 cursor )和一个出队索引(所有消费者中消费进度最小的序号)。
Disruptor 中最复杂的是入队操作,下面以多生产者(MultiProducerSequencer)的 next(n) 方法(申请n个序号)为例分析下 Disruptor 是如何实现无锁操作的。代码如下所示,判断下是否有足够的序号(空余位置),如果没有,就让出 CPU 使用权,然后重新判断。如果有,则使用 CAS 设置 cursor(入队索引)。
public long next(int n) {
do {
// cursor类似于入队索引, 指的是上次生产到这里
current = cursor.get();
// 目标是再生产n个
next = current + n;
// 前文分析过, 用于判断消费者是否已经追上生产进度, 生产者能否申请到n个序号
long wrapPoint = next - bufferSize;
// 获取缓存的上一次的消费进度
long cachedGatingSequence = gatingSequenceCache.get();
// 第一步:空间不足就继续等待
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > current) {
// 重新计算下所有消费者里的最小消费进度
long gatingSequence = Util.getMinimumSequence(gatingSequences, current);
// 依然没有足够的空间, 让出CPU使用权
if (wrapPoint > gatingSequence) {
LockSupport.parkNanos(1);
continue;
}
// 更新下最新的最小的消费进度
gatingSequenceCache.set(gatingSequence);
}
// 第二步:看见空间足够时尝试CAS竞争空间
else if (cursor.compareAndSet(current, next)) {
break;
}
} while (true);
return next;
}6.4 支持批量消费定义 Event
这个比较好理解,在前文分析消费数据的逻辑时介绍了,消费者会获取下最大可用的序号,然后批量消费这些消息。
七、Disruptor 在i主题业务中的使用
很多开源项目都使用了 Disruptor,比如日志框架 Log4j2 使用它来实现异步日志。HBase、Storm 等项目中也使用了到了 Disruptor。vivo 的 i主题业务也使用了 Disruptor,下面简单介绍下它的2个使用场景。
7.1 监控数据上报
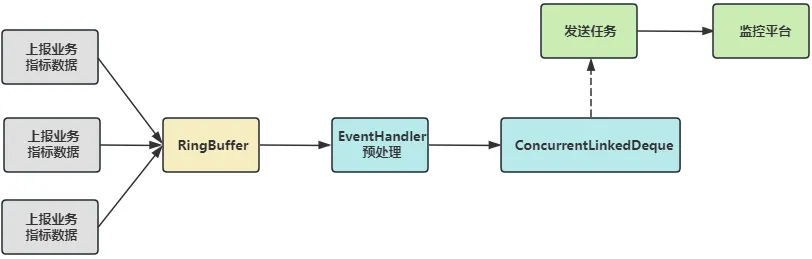
业务监控系统对于企业来说非常重要,可以帮助企业及时发现和解决问题,可以方便的检测业务指标数据,改进业务决策,从而保证业务的可持续发展。i主题使用 Disruptor(多生产者单消费者)来暂存待上报的业务指标数据,然后有定时任务不断提取数据上报到监控平台,如下图所示。
7.2 本地缓存 key 统计分析
i主题业务中大量使用了本地缓存,为了统计本地缓存中key 的个数(去重)以及每种缓存模式 key 的数量,考虑使用 Disruptor 来暂存并消费处理数据。因为业务代码里很多地方涉及到本地缓存的访问,也就是说,生产者是多线程的。考虑到消费处理比较简单,而如果使用多线程消费的话又涉及到加锁同步,因此消费者采用单线程模式。
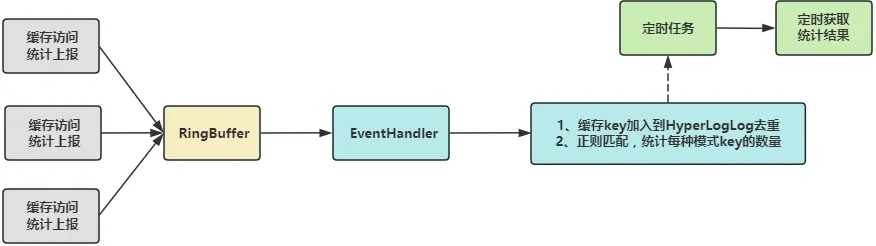
整体流程如下图所示,首先在缓存访问工具类中增加缓存访问统计上报的调用,缓存访问数据进入到 RingBuffer 后,单线程消费者使用 HyperLogLog 来去重统计不同 key的个数,使用正则匹配来统计每种模式key的数量。然后有异步任务定时获取统计结果,进行展示。
需要注意的是,因为 RingBuffer 队列大小是固定的,如果生产者生产过快而消费者消费不过来,如果使用 next 方法申请序号,如果剩余空间不够会导致生产者阻塞,因此建议使用 tryPublishEvent 方法去发布数据,它内部是使用 tryNext 方法申请序号,该方法如果申请不到可用序号会抛出异常,这样生产者感知到了就可以做兼容处理,而不是阻塞等待。
八、使用建议
Disruptor 是基于生产者消费者模式,如果生产快消费慢,就会导致生产者无法写入数据。因此,不建议在 Disruptor 消费线程中处理耗时较长的业务。
一个 EventHandler 对应一个线程,一个线程只服务于一个 EventHandler。Disruptor 需要为每一个EventHandler(EventProcessor) 创建一个线程。因此在创建 Disruptor 时不推荐传入指定的线程池,而是由 Disruptor 自身根据 EventHandler 数量去创建对应的线程。
生产者调用 next 方法申请序号时,如果获取不到可用序号会阻塞,这一点需要注意。推荐使用 tryPublishEvent 方法,生产者在申请不到可用序号时会立即返回,不会阻塞业务线程。
如果使用 next 方法申请可用序号,需要确保在 finally 方法中调用 publish 真正发布数据。
合理设置等待策略。消费者在获取不到数据时会根据设置的等待策略进行等待,BlockingWaitStrategry 是最低效的策略,但其对 CPU消耗最小。YieldingWaitStrategy 有着较低的延迟、较高的吞吐量,以及较高 CPU 占用率。当 CPU 数量足够时,可以使用该策略。
九、总结
本文首先通过对比 JDK 中内置的线程安全的队列和Disruptor 的特点,引入了高性能无锁内存队列 Disruptor。接着介绍了 Disruptor 的核心概念和基本使用,使读者对 Disruptor 建立起初步的认识。接着从源码和原理角度介绍了 Disruptor 的核心实现以及高性能原理(空间预分配、避免伪共享、无锁、支持批量消费)。其次,结合i主题业务介绍了 Disruptor 在实践中的应用。最后,基于上述原理分析及应用实战,总结了一些 Disruptor 最佳实践策略。
参考文章:
https://time.geekbang.org/column/article/132477
https://lmax-exchange.github.io/disruptor/
高性能无锁队列 Disruptor 核心原理分析及其在i主题业务中的应用的更多相关文章
- 高性能无锁队列 Disruptor 初体验
原文地址: haifeiWu和他朋友们的博客 博客地址:www.hchstudio.cn 欢迎转载,转载请注明作者及出处,谢谢! 最近一直在研究队列的一些问题,今天楼主要分享一个高性能的队列 Disr ...
- DPDK 无锁队列Ring Library原理(学习笔记)
参考自DPDK官方文档原文:http://doc.dpdk.org/guides-20.02/prog_guide/ring_lib.html 针对自己的理解做了一些辅助解释. 1 前置知识 1.1 ...
- DIOCP开源项目-Delphi高性能无锁队列(lock-free)
最近想在DIOCP中加入任务调度线程,DIOCP的工作线程作为生产者(producer)将接受到的数据对象,投递到任务调度线程中,然后统一进行分配.然而这一切都需要一个队列, 这几天都在关注无锁队列. ...
- Erlang运行时中的无锁队列及其在异步线程中的应用
本文首先介绍 Erlang 运行时中需要使用无锁队列的场合,然后介绍无锁队列的基本原理及会遇到的问题,接下来介绍 Erlang 运行时中如何通过“线程进度”机制解决无锁队列的问题,并介绍 Erlang ...
- HashMap的原理与实 无锁队列的实现Java HashMap的死循环 red black tree
http://www.cnblogs.com/fornever/archive/2011/12/02/2270692.html https://zh.wikipedia.org/wiki/%E7%BA ...
- zeromq源码分析笔记之无锁队列ypipe_t(3)
在上一篇中说到了mailbox_t的底层实际上使用了管道ypipe_t来存储命令.而ypipe_t实质上是一个无锁队列,其底层使用了yqueue_t队列,ypipe_t是对yueue_t的再包装,所以 ...
- 高性能消息队列 CKafka 核心原理介绍(上)
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:闫燕飞 1.背景 Ckafka是基础架构部开发的高性能.高可用消息中间件,其主要用于消息传输.网站活动追踪.运营监控.日志聚合.流式 ...
- 基于无锁队列和c++11的高性能线程池
基于无锁队列和c++11的高性能线程池线程使用c++11库和线程池之间的消息通讯使用一个简单的无锁消息队列适用于linux平台,gcc 4.6以上 标签: <无> 代码片段(6)[ ...
- EasyDarwin开源流媒体服务器高性能设计之无锁队列
本文来自EasyDarwin团队Fantasy(fantasy(at)easydarwin.org) 一. EasyDarwin任务队列实现 EasyDarwin的任务队列是通过OSQueue类来组织 ...
- DIOCP开源项目-高效稳定的服务端解决方案(DIOCP + 无锁队列 + ZeroMQ + QWorkers) 出炉了
[概述] 自从上次发布了[DIOCP开源项目-利用队列+0MQ+多进程逻辑处理,搭建稳定,高效,分布式的服务端]文章后,得到了很多朋友的支持和肯定.这加大了我的开发动力,经过几个晚上的熬夜,终于在昨天 ...
随机推荐
- SpringBoot+Selenium模拟用户操作浏览器
Selenium Selenium是一个用于Web应用程序自动化测试的开源工具套件.它主要用于以下目的: 浏览器自动化:Selenium能够模拟真实用户在不同浏览器(如Chrome.Firefox.I ...
- ODPS 不用循环生成连续日期
生成 20230801 ~ 20230831之间的每一天的sql代码怎么写? 只要一行代码. 一行代码: select TO_CHAR(DATEADD(TO_DATE(bizdate,'yyyymmd ...
- uboot load address、entry point、 bootm address以及kernel运行地址的意义及联系
按各地址起作用的顺序,uboot引导linux内核启动涉及到以下地址: load address: entry point: 这两个地址是mkimage时指定的 bootm address:bootm ...
- selenium窗口之间的切换
import time from selenium.webdriver import Edge from selenium.webdriver.common.by import By from sel ...
- SD中的VAE,你不能不懂
什么是VAE? VAE,即变分自编码器(Variational Autoencoder),是一种生成模型,它通过学习输入数据的潜在表示来重构输入数据. 在Stable Diffusion 1.4 或 ...
- jsp+servlet+mysql-----------批量删除
jsp: <div class="result-wrap"> <form action="${pageContext.request.contextPa ...
- require模块化 AMD和CMD
在CommonJS中,有一个全局性方法require(),用于加载模块.假定有一个数学模块math.js,就可以像下面这样加载. 1 var math = require('math'); 然后,就可 ...
- 基于Docker安装项目管理工具禅道
禅道是通用的项目管理软件 完整支持敏捷项目模型.瀑布项目模型.看板模型 内置项目集.产品.项目和执行四个管理框架 支持CMMI标准的落地实施 下载镜像 docker pull easysoft/zen ...
- IstioCon 回顾 | 网易数帆的 Istio 推送性能优化经验
在 IstioCon2022 上,网易数帆资深架构师方志恒从企业生产落地实践的视角分享了多年 Istio 实践经验,介绍了 Istio 数据模型,xDS 和 Istio 推送的关系,网易数帆遇到的性能 ...
- django 中的collectstatic
django 中的collectstatic 在Django中,"collectstatic"是一个管理命令,用于收集和复制项目中的静态文件到一个指定的静态文件目录,以便于部署. ...