Mysql慢sql优化
Mysql慢sql优化
index
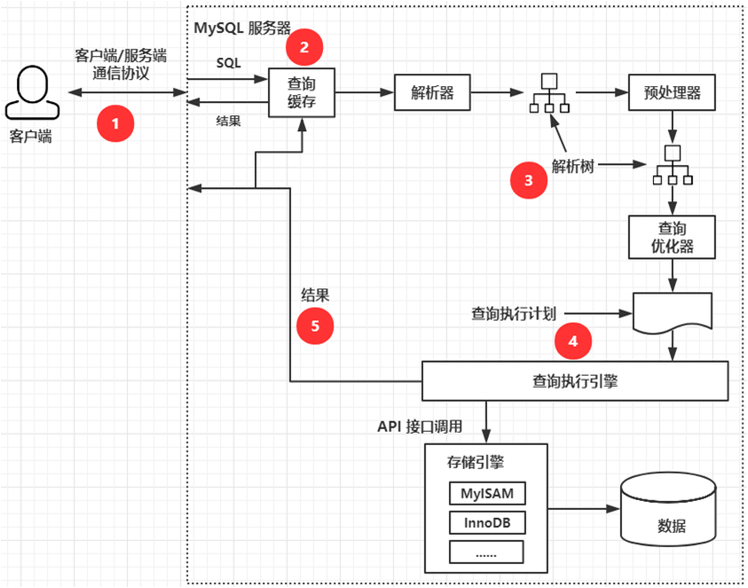
1.MySQL的执行过程
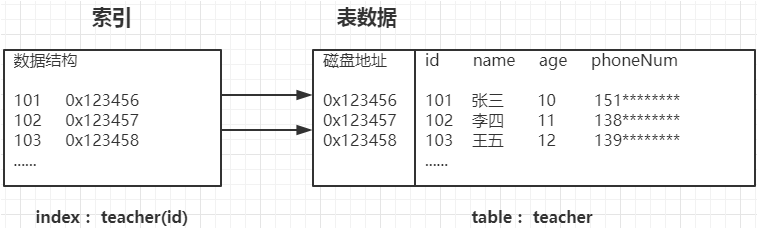
2.索引的定义
3.MySQL执行计划explain or desc
4.索引使用/创建规则
5.弊端
6.设计规范
7.SQL建议
1. MySQL 的执行过程
2.索引的定义
3.MySQL执行计划 explain or desc


3.MySQL执行计划
使用 explain 了解并优化执行计划,非常重要;
执行计划的 id
select 查询的序列号,标识执行的顺序
id 相同,执行顺序由上至下
id 不同,如果是子查询,id 的序号会递增,id 值越大优先级越高,越先被执行
执行计划的 select_type
查询的类型,主要是用于区分普通查询、联合查询、子查询等。
SIMPLE:简单的 select 查询,查询中不包含子查询或者 union
PRIMARY:查询中包含子部分,最外层查询则被标记为 primary
SUBQUERY/MATERIALIZED:SUBQUERY 表示在 select 或 where 列表中包含了子查询,MATERIALIZED:表示 where 后面 in 条件的子查询
UNION:表示 union 中的第二个或后面的 select 语句
UNION RESULT:union 的结果
执行计划的 table
查询涉及到的表。
直接显示表名或者表的别名
<unionM,N> 由 ID 为 M,N 查询 union 产生的结果
<subqueryN> 由 ID 为 N 查询产生的结果
执行计划的 type
访问类型,SQL 查询优化中一个很重要的指标,结果值从好到坏依次是:system > const > eq_ref > ref > range > index > ALL。
system:系统表,少量数据,往往不需要进行磁盘IO
const:常量连接
eq_ref:主键索引(primary key)或者非空唯一索引(unique not null)等值扫描
ref:非主键非唯一索引等值扫描
range:范围扫描
index:索引树扫描
ALL:全表扫描(full table scan)
执行计划 possible_keys
查询过程中有可能用到的索引。
执行计划 key
实际使用的索引,如果为 NULL ,则没有使用索引。
执行计划 rows
根据表统计信息或者索引选用情况,大致估算出找到所需的记录所需要读取的行数。
执行计划 filtered
表示返回结果的行数占需读取行数的百分比, filtered 的值越大越好。
执行计划 Extra
十分重要的额外信息。
Using filesort:MySQL 对数据使用一个外部的文件内容进行了排序,而不是按照表内的索引进行排序读取。
Using temporary:使用临时表保存中间结果,也就是说 MySQL 在对查询结果排序时使用了临时表,常见于order by 或 group by。
Using index:表示 SQL 操作中使用了覆盖索引(Covering Index),避免了访问表的数据行,效率高。
Using index condition:表示 SQL 操作命中了索引,但不是所有的列数据都在索引树上,还需要访问实际的行记录。
Using where:表示 SQL 操作使用了 where 过滤条件。
Select tables optimized away:基于索引优化 MIN/MAX 操作或者 MyISAM 存储引擎优化 COUNT(*) 操作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即可完成优化。
Using join buffer (Block Nested Loop):表示 SQL 操作使用了关联查询或者子查询,且需要进行嵌套循环计算。
https://www.cnblogs.com/yinjw/p/11864477.html
4. 索引使用规则
应尽量避免全表扫描,首先应考虑在 WHERE 及 ORDER BY 涉及的列上建立索引
应尽量避免在 WHERE 子句中使用 OR 来连接条件,建议可以使用UNION合并查询
多个OR的字句没有用到索引,改写成UNION的形式再试图与索引匹配。如果查询需要用到联合索引,用UNION all执行的效率更高
在使用or的时候,要求or前后字段都有索引.
应尽量避免在 WHERE 子句中对字段进行 NULL 值判断
应尽量避免在 WHERE 子句中使用!=或<>操作符 MySQL只有对以下操作符才使用索引:<,<=,=,>,>=,BETWEEN,IN,以及某些时候的LIKE。
如果在 WHERE 子句中使用参数,也会导致全表扫描
应尽量避免在 WHERE 子句中对字段进行表达式操作
应尽量避免在where子句中对字段进行函数操作
任何对列的操作都将导致表扫描,它包括数据库函数、计算表达式等等,查询时要尽可能将操作移至等号右边。
demo
SELECT * FROM record WHERE SUBSTRING(card_no,1,4)='5378' (13秒)
SELECT * FROM record WHERE amount/30< 1000 (11秒)
SELECT * FROM record WHERE CONVERT(CHAR(10),DATE,112)='19991201' (10秒)
SELECT * FROM record WHERE card_no LIKE '5378%' (< 1秒)
SELECT * FROM record WHERE amount< 1000*30 (< 1秒)
SELECT * FROM record WHERE DATE= '1999/12/01' (< 1秒)
GROUP BY 提高GROUP BY语句的效率, 可以通过将不需要的记录在GROUP BY 之前过滤掉.下面两个查询返回相同结果
低效:
SELECT JOB , AVG(SAL)
FROM EMP
GROUP BY JOB
HAVING JOB =’PRESIDENT’ OR JOB =’MANAGER’
高效:
SELECT JOB , AVG(SAL)
FROM EMP
WHERE JOB =’PRESIDENT’ OR JOB =’MANAGER’
GROUP BY JOB
IN 和 NOT IN 也要慎用,否则会导致全表扫描,对于连续的数值,能用 BETWEEN 就不要用 IN 了
很多时候用 EXISTS 代替 IN 是一个好的选择: SELECT num FROM a WHERE num IN(SELECT num FROM b).
用下面的语句替换: SELECT num FROM a WHERE EXISTS(SELECT 1 FROM b WHERE num=a.num)
在IN后面值的列表中,将出现最频繁的值放在最前面,出现得最少的放在最后面,减少判断的次数(按优先级的顺序来)
like查询 SELECT id FROM t WHERE NAME LIKE '%abc%' 或者select id FROM t WHERE NAME LIKE '%abc'
若要提高效率,可以考虑全文检索。而select id FROM t WHERE NAME LIKE ‘abc%’ 才用到索引
blob和text字段仅支持前缀索引.
在使用like的时候,以%开头,即"%***"的时候无法使用索引;
在join时条件字段类型不一致的时候,mysql无法使用索引;
联合索引 如果该索引是联合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用
加上时间范围索引来缩小时间范围,数据量大会导致全表扫描
适当的情形下使用GROUP BY而不是DISTINCT,在WHERE, GROUP BY和ORDER BY子句中使用有索引的列,
保持索引简单,不在多个索引中包含同一个列,有时候MySQL会使用错误的索引,对于这种情况使用USE INDEX,IGNORE INDEX, FORCE INDEX
4.索引创建规则
表的主键、外键必须有索引;
经常与其他表进行连接的表,在连接字段上应该建立索引;
经常出现在Where子句中的字段,特别是大表的字段,应该建立索引;
索引应该建在选择性高的字段上;
索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引; (超长文本)
复合索引的建立需要进行仔细分析,尽量考虑用单字段索引代替; (不建议复合索引)
正确选择复合索引中的主列字段,一般是选择性较好的字段; (复合索引的第一个字段是高频使用的列,才会使用到该索引)
复合索引的几个字段是否经常同时以AND方式出现在Where子句中?单字段查询是否极少甚至没有?如果是,则可以建立复合索引;否则考虑单字段索引;
如果复合索引中包含的字段经常单独出现在Where子句中,则分解为多个单字段索引; (拆分复合索引的原因)
如果复合索引所包含的字段超过3个,那么仔细考虑其必要性,考虑减少复合的字段; (不建议超过3个字段)
如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引; (复合索引的重复)
频繁进行数据操作的表,不要建立太多的索引; (影响对添加,修改的操作)
删除无用的索引,避免对执行计划造成负面影响; (索引不是越多越好)
表上建立的每个索引都会增加存储开销,索引对于插入、删除、更新操作也会增加处理上的开销。另外,过多的复合索引,在有单字段索引的情况下,一般都是没有存在价值的;相反,还会降低数据增加删除时的性能,特别是对频繁更新的表来说,负面影响更大。
尽量不要对数据库中某个含有大量重复的值的字段建立索引。(枚举字段等,常量字段等)
5.弊端
索引固然可以提高相应的 SELECT 的效率,但同时也降低了 INSERT 及 UPDATE 的效率
一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
应尽可能的避免更新 clustered 索引数据列
6.设计规范
尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销,数值型数据被处理起来的速度要比文本类型快得多
字段 但大多数时候应该使用NOT NULL,或者使用一个特殊的值,如0,-1作为默 认值。
所有字段都得有默认值,尽量避免null。 应该尽量把字段设置为NOT NULL,这样在将来执行查询的时候,数据库不用去比较NULL值。
尽可能的使用 VARCHAR/NVARCHAR 代替 CHAR/NCHAR (固定长度的), 因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
触发器 最好不要使用触发器,触发一个触发器,执行一个触发器事件本身就是一个耗费资源的过程;如果能够使用约束实现的,尽量不要使用触发器;不要为不同的触发事件(Insert,Update和Delete)使用相同的触发器;不要在触发器中使用事务型代码。
主键 我们应该为数据库里的每张表都设置一个ID做为其主键,而且最好的是一个INT型的(推荐使用UNSIGNED),并设置上自动增加的AUTO_INCREMENT标志
MySQL查询可以启用高速查询缓存。当同一个查询被执行多次时,从缓存中提取数据和直接从数据库中返回数据快很多。
MYISAM: 应用时以读和插入操作为主,只有少量的更新和删除,并且对事务的完整性,并发性要求不是很高的。
Innodb:事务处理,以及并发条件下要求数据的一致性。除了插入和查询外,包括很多的更新和删除。(Innodb有效地降低删除和更新导致的锁定)。对于支持事务的InnoDB类型的表来说,影响速度的主要原因是AUTOCOMMIT默认设置是打开的,而且程序没有显式调用BEGIN 开始事务,导致每插入一条都自动提交,严重影响了速度。可以在执行sql前调用begin,多条sql形成一个事物(即使autocommit打开也可以),将大大提高性能。
小表 数据库中的表越小,在它上面执行的查询也就会越快。
优化表的数据类型,选择合适的数据类型: 原则:更小通常更好,简单就好,所有字段都得有默认值,尽量避免null。
7.SQL建议
最好不要使用select * 返回所有,用具体的字段列表代替“*”,不要返回用不到的任何字段。
尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
使用表的别名(Alias):当在SQL语句中连接多个表时,请使用表的别名并把别名前缀于每个Column上,可以减少解析的时间并减少那些由Column歧义引起的语法错误。
常见的简化规则如下:不要有超过5个以上的表连接(JOIN),考虑使用临时表或表变量存放中间结果。少用子查询,视图嵌套不要过深,一般视图嵌套不要超过2个为宜。
将需要查询的结果预先计算好放在表中,查询的时候再Select。或者在service层处理。尽量将数据的处理工作放在服务器上,减少网络的开销
count函数 尽量使用exists代替select COUNT(1)来判断是否存在记录,count函数只有在统计表中所有行数时使用,而且count(1)比count(*)更有效率。
尽量使用“>=”,不要使用“>”。
批处理 当有一批处理的插入或更新时,用批量插入或批量更新,绝不会一条条记录的去更新!
存储过程 在所有的存储过程中,能够用SQL语句的,不建议用循环去实现!
数据记录限定:当只要一行数据时使用 LIMIT 1 MySQL数据库引擎会在找到一条数据后停止搜索,而不是继续往后查下一条符合记录的数据。
Mysql慢sql优化的更多相关文章
- mysql的sql优化案例
前言 mysql的sql优化器比较弱,选择执行计划貌似很随机. 案例 一.表结构说明mysql> show create table table_order\G***************** ...
- 我的mysql数据库sql优化原则
原文 我的mysql数据库sql优化原则 一.前提 这里的原则 只是针对mysql数据库,其他的数据库 某些是殊途同归,某些还是存在差异.我总结的也是mysql普遍的规则,对于某些特殊情况得特殊对待. ...
- MySQL之SQL优化详解(二)
目录 MySQL之SQL优化详解(二) 1. SQL的执行顺序 1.1 手写顺序 1.2 机读顺序 2. 七种join 3. 索引 3.1 索引初探 3.2 索引分类 3.3 建与不建 4. 性能分析 ...
- 基于MySQL 的 SQL 优化总结
文章首发于我的个人博客,欢迎访问.https://blog.itzhouq.cn/mysql1 基于MySQL 的 SQL 优化总结 在数据库运维过程中,优化 SQL 是 DBA 团队的日常任务.例行 ...
- 【MySQL】SQL优化系列之 in与range 查询
首先我们来说下in()这种方式的查询 在<高性能MySQL>里面提及用in这种方式可以有效的替代一定的range查询,提升查询效率,因为在一条索引里面,range字段后面的部分是不生效的. ...
- mysql索引sql优化方法、步骤和经验
MySQL索引原理及慢查询优化 http://blog.jobbole.com/86594/ 细说mysql索引 https://www.cnblogs.com/chenshishuo/p/50300 ...
- (1.10)SQL优化——mysql 常见SQL优化
(1.10)常用SQL优化 insert优化.order by 优化 1.insert 优化 2.order by 优化 [2.1]mysql排序方式: (1)索引扫描排序:通过有序索引扫描直接返回有 ...
- MySQL之SQL优化详解(一)
目录 慢查询日志 1. 慢查询日志开启 2. 慢查询日志设置与查看 3.日志分析工具mysqldumpslow 序言: 在我面试很多人的过程中,很多人谈到SQL优化都头头是道,建索引,explai ...
- Mysql的SQL优化指北
概述 在一次和技术大佬的聊天中被问到,平时我是怎么做Mysql的优化的?在这个问题上我只回答出了几点,感觉回答的不够完美,所以我打算整理一次SQL的优化问题. 要知道怎么优化首先要知道一条SQL是怎么 ...
- BATJ解决千万级别数据之MySQL 的 SQL 优化大总结
引用 在数据库运维过程中,优化 SQL 是 DBA 团队的日常任务.例行 SQL 优化,不仅可以提高程序性能,还能减低线上故障的概率. 目前常用的 SQL 优化方式包括但不限于:业务层优化.SQL 逻 ...
随机推荐
- 深信服智能边缘计算平台与 OpenYurt 落地方案探索与实践
简介:本文将介绍边缘计算落地的机遇与挑战,以及边缘容器开源项目 OpenYurt 在企业生产环境下的实践方案. 作者:赵震,深信服云计算开发工程师,OpenYurt 社区 Member 编者案:在 ...
- Flink 在顺丰的应用实践
简介: 顺丰基于 Flink 建设实时数仓的思路,引入 Hudi On Flink 加速数仓宽表,以及实时数仓平台化建设的实践. 本⽂由社区志愿者苗文婷整理,内容源⾃顺丰科技大数据平台研发工程师龙逸 ...
- [FAQ] 快速上手 Final Cut Pro X 的入门教程
FinalCutPro视频剪辑 基本操作教学,看下面的视频作为一个大致了解.另外遇到其它问题再针对性搜索解决即可. > 在线CF靶场 射击消除烦闷 Link:https://www.cnblog ...
- dotnet 6 使用 DependentHandle 关联对象生命周期
本文将告诉大家在 dotnet 6 新加入的 System.Runtime.DependentHandle 的类型的使用方法,通过 DependentHandle 可以实现将某个对象的引用生命周期和另 ...
- WPF 在 .NET Core 3.1.19 版本 触摸笔迹偏移问题
在更新到 .NET 6 发布之前的,在 2021.11.02 的 .NET Core 版本,都会存在此问题.在 WPF 应用里面,如果在高 DPI 下,进行触摸书写,此时的笔迹将会偏移.核心原因是在这 ...
- Windows 对全屏应用的优化
全屏应用对应的是窗口模式应用,全屏应用指的是整个屏幕都是被咱一个应用独占了,屏幕上没有显示其他的应用,此时的应用就叫全屏应用.如希沃白板这个程序.本文主要告诉大家从微软官方的文档以及考古了解到的 Wi ...
- C语言的指针不能与数组之前的内存进行比较
标准允许指向数组元素的指针与指向数组最后一个元素后面的那个内存位置的指针进行比较,但是不允许与指向数组第一个元素之前的那个内存位置的指针进行比较. 案例一 #define DATAMAX 5 int ...
- 密钥存储在过时的 trusted.gpg 密钥环中(/etc/apt/trusted.gpg)
密钥存储在过时的 trusted.gpg 密钥环中(/etc/apt/trusted.gpg) 问题: 解决: cd /etc/opt sudo cp trusted.gpg trusted.gpg. ...
- SQL如何删除所有字段都相同的重复数据?
SQL Server数据库:有时候在处理数据时会遇到不加主键的表,导致数据表内出现了一模一样的数据,刚开始第一时间想到的方式是,把两条数据全部删除,然后再插入一条,但是这种可能数据量比较少的话,还可以 ...
- 从油猴脚本管理器的角度审视Chrome扩展
从油猴脚本管理器的角度审视Chrome扩展 在之前一段时间,我需要借助Chrome扩展来完成一个需求,当时还在使用油猴脚本与浏览器扩展之间调研了一波,而此时恰好我又有一些做的还可以的油猴脚本 TKSc ...