Python——第五章:pickle模块
序列化:把对象转化成二进制字节
反序列化:把二进制字节转化回对象
Pickle模块的常见用法:
Pickle.dunps 把对象(数据)转化成字节
Pickle.loads 把字节转化回对象(数据)
Pickle.dunp 把对象序列化成字节之后写入到文件
Pickle.load 把文件中的字节反序列化成对象在Python中,序列化和反序列化是将数据结构转换为字节流或其他可存储或传输的格式,以及将字节流或其他格式还原为原始数据结构的过程。
序列化(Serialization)pickle.dumps方法
序列化通常涉及将数据结构转换为字节流或字符串的过程,以便将其保存到文件、数据库或通过网络传输。
pickle.dumps(obj, protocol=None, *, fix_imports=True, buffer_callback=None):
- 作用:将一个对象序列化为一个字节对象。
- 使用场景:通常用于在内存中处理对象,比如将对象传递给网络通信、存储到数据库,或在需要字节对象的地方使用。
- 返回值:返回序列化后的字节对象。
序列化(Serialization)pickle.dump方法
pickle.dump(obj, file, protocol=None, *, fix_imports=True, buffer_callback=None):
- 作用:将一个对象序列化并写入文件。
- 使用场景:通常用于将对象保存到文件,以便稍后再读取和使用。
- 参数
file是文件对象,用于写入序列化的数据。 - 无返回值,数据被写入到文件中。
选择使用哪个函数取决于你的具体需求和场景。
pickle.dumps 主要用于在内存中进行对象序列化,返回字节对象。
pickle.dump 主要用于将序列化后的数据写入文件,存储到磁盘。
反序列化(Deserialization)pickle.loads方法
反序列化是将字节流或其他格式还原为原始数据结构的过程。
pickle.loads主要对应pickle.dumps 。用于在内存中进行序列化和反序列化,分别将对象转换为字节对象和将字节对象还原为对象。
pickle.loads(bytes_object, *, fix_imports=True, encoding="ASCII", errors="strict", buffers=None):
loads是load string的缩写,用于将字符串(字节流)反序列化为对象。- 参数
bytes_object是要反序列化的字节对象。 - 返回值是反序列化后的对象。
反序列化(Deserialization)pickle.load方法
pickle.load 主要对应pickle.dump。用于与文件之间进行序列化和反序列化,分别将对象写入文件和从文件中读取序列化的数据并还原为对象。
pickle.load(file, *, fix_imports=True, encoding="ASCII", errors="strict", buffers=None):
load是load from file的缩写,用于从文件中读取序列化的数据并反序列化为对象。- 参数
file是文件对象。 - 返回值是反序列化后的对象。
案例1:网络传输
pickle.dumps()将列表序列化为字节流,才可以进行网络传输(因为网络底层只认识字节)
import pickle
dic = {"name": "admin", "password": 123}
bs = pickle.dumps(dic)
print(bs)
#运行结果
b'\x80\x04\x95!\x00\x00\x00\x00\x00\x00\x00}\x94(\x8c\x04name\x94\x8c\x05admin\x94\x8c\x08password\x94K{u.'pickle.loads()将网络传输过来的字节,重新还原回原始的数据结构。
bs= b'\x80\x04\x95!\x00\x00\x00\x00\x00\x00\x00}\x94(\x8c\x04name\x94\x8c\x05admin\x94\x8c\x08password\x94K{u.'
dic = pickle.loads(bs)
print(dic, type(dic))
#运行结果
{'name': 'admin', 'password': 123} <class 'dict'>案例2:文件存储
pickle.dumps() 用于将字典 data 序列化为二进制字节流,并将其写入文件 'data.pkl'。
import pickle
data = {'name': 'John', 'age': 30, 'city': 'New York'}
# 序列化
serialized_data = pickle.dumps(data)
with open('data.pkl', 'wb') as file:
file.write(serialized_data)pickle.loads() 用于将字节流反序列化为原始的数据结构。
import pickle
# 从文件中读取序列化的数据
with open('data.pkl', 'rb') as file:
serialized_data = file.read()
# 反序列化
loaded_data = pickle.loads(serialized_data)
print(loaded_data)需要注意的是,pickle 不是唯一的序列化方法。在实际应用中,你可能还会遇到其他格式,比如 JSON(使用 json 模块)、XML、或者 Protocol Buffers 等,取决于你的需求和使用场景。
反面案例3:
dic = {"name": "admin", "password": 123}
f = open("data.txt", mode="w", encoding="utf-8")
f.write(dic)
#运行结果
f.write(dic)
TypeError: write() argument must be str, not dict #write() 方法中传递的参数必须是字符串(str),而不能是字典(dict)如果你强制转化成字符串去存储这个字典,str(dic)虽然执行会成功
dic = {"name": "admin", "password": 123}
f = open("data.txt", mode="w", encoding="utf-8")
f.write(str(dic))但是当你重新读取f.read()文件的时候,读取出来的结果依旧是字符串(str),而不是字典(dict)
f = open("data.txt", mode="r", encoding="utf-8")
s = f.read()
print(s, type(s))
#运行结果,依旧是字符串类型
{'name': 'admin', 'password': 123} <class 'str'>这样,你就不能像字典一样进行关键字取值、循环等操作。
为了解决这个问题,你还得使用eval()进行特殊处理
f = open("data.txt", mode="r", encoding="utf-8")
s = f.read()
d = eval(s)
print(d, type(d))
#运行结果
{'name': 'admin', 'password': 123} <class 'dict'>但是,使用 eval() 函数来解析字符串是一个潜在的安全风险,因为它可以执行任意的 Python 代码,可能导致代码注入或执行恶意代码的风险。强烈建议避免使用 eval() 来解析未知或不可信来源的数据。
在你的情况下,如果你知道文件中包含的是一个合法的字典表示形式,更安全的方法是使用 json 模块来加载 JSON 数据:
import json
with open("data.txt", mode="r", encoding="utf-8") as f:
json_str = f.read()
loaded_dict = json.loads(json_str)
print(loaded_dict, type(loaded_dict))这样,你可以确保加载的数据是一个有效的 JSON 格式,而且不会执行任意的代码。
如果你依然需要处理 Python 字典表示形式而非 JSON,可以使用 ast.literal_eval() 而非 eval(),因为 literal_eval() 更安全,只会解析字面常量,而不会执行任意代码。不过,使用 JSON 通常是更好的选择。
案例4:
把数据存储到文件中最合理的方案就是使用pickle.dump()
dic = {"name": "admin", "password": 123}
with open("data.txt", mode="wb") as f: # f = open("data.txt", mode="wb")
pickle.dump(dic, f)序列化存储后的文件我们打开后看到的是这样的乱码
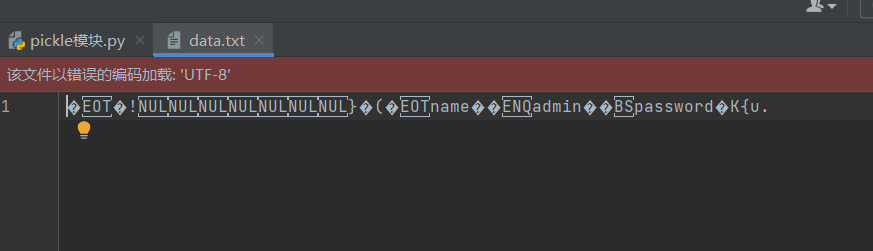
读取序列化的文件使用pickle.load()
with open("data.txt", mode="rb") as f: # f = open("data.txt", mode="rb")
dic = pickle.load(f)
print(dic, type(dic))
#执行结果
{'name': 'admin', 'password': 123} <class 'dict'>Python——第五章:pickle模块的更多相关文章
- Python第五章__模块介绍,常用内置模块
Python第五章__模块介绍,常用内置模块 欢迎加入Linux_Python学习群 群号:478616847 目录: 模块与导入介绍 包的介绍 time &datetime模块 rando ...
- 简学Python第五章__模块介绍,常用内置模块
Python第五章__模块介绍,常用内置模块 欢迎加入Linux_Python学习群 群号:478616847 目录: 模块与导入介绍 包的介绍 time &datetime模块 rando ...
- python(6)- json和pickle模块
这是用于序列化的两个模块: json: 用于字符串和python数据类型间进行转换 pickle: 用于python特有的类型和python的数据类型间进行转换 Json模块提供了四个功能:dumps ...
- python学习_应用pickle模块封装和拆封数据对象
学习文件数据处理的时候了解到有pickle模块,查找官方文档学习了一些需要用到的pickle内容. 封装是一个将Python数据对象转化为字节流的过程,拆封是封装的逆操作,将字节文件或字节对象中的字节 ...
- Python数据存储:pickle模块的使用讲解
在机器学习中,我们常常需要把训练好的模型存储起来,这样在进行决策时直接将模型读出,而不需要重新训练模型,这样就大大节约了时间.Python提供的pickle模块就很好地解决了这个问题,它可以序列化对象 ...
- python数据持久存储-pickle模块
pickle模块实现了基本的数据序列和反序列化.pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,通过pickle模块的反序列化操作,能够从文件中创建上一次程序保存的对象. 接 ...
- Python第五章实验报告
一.实验项目名称:<零基础学Python>第五章实战.实例以及两道作业题 二.实验目的和要求:了解和掌握操作字符串的方法和正则表达式的应用 三.实验环境:IDLE(Python 3.9 6 ...
- python 之 json 与pickle 模块
序例化:将对象转换为可通过网络传输或可以存储到本地磁盘的数据格式(如:XML.JSON或特定格式的字节串)的过程称为序列化:反之,则称为反序列化. 1.[JSON] import json dic={ ...
- 那些年被我坑过的Python——道阻且长(第五章实用模块讲解)
random模块 我的随机验证吗程序: 首先保证了字母和数字出现的概率是50% VS 50%,其次是可以订制输出多少位 def Captcha(size): Captcha_list = [] for ...
- python第五周:模块、标准库
模块相关知识: 定义:用来从逻辑上组织python代码(变量.函数.类.逻辑:实现一个功能)本质就是以.py结尾的python文件(文件名:test.py,对应的模块名:test) 附注:包:是用来从 ...
随机推荐
- LDA主题模型讲解及代码Python实现
目录 1. LDA主题模型详解 1.1 Beta/Dirichlet 分布的一个性质 1.2 LDA-math-MCMC 1.2.1 重要理解 1.3 Gibbs Sampling 2. 所需工具库 ...
- Jenkins 命令执行 -- jetty 敏感信息泄露 --(CVE-2021-2816)&&(CVE-2017-1000353)&&(CVE-2018-1000861)
Jenkins 命令执行 -- jetty 敏感信息泄露 --(CVE-2021-2816)&&(CVE-2017-1000353)&&(CVE-2018-100086 ...
- 前端三件套系例之CSS——CSS3基础布局
文章目录 css基础布局 1.布局相关的标签 2.盒子模型 2-1 什么是盒子模型 2-2 margin外边距 2-3 padding内填充 2-4 案例 3.浮动(float) 3-1 什么是浮动 ...
- 推荐免费的svn空间(SVN代码托管)
推荐免费的svn空间(SVN代码托管) 最近研究了国内和国外的免费svn空间,SVN代码托管,SVN在线,代码托管中心,有所心得. 1.http://www.svn999.com/ [推荐]国内的,免 ...
- sqlserver在设计表结构时,如何选择字段的数据类型
在设计表结构时,选择适当的字段数据类型是非常重要的,它会直接影响数据库的性能.存储空间和数据的完整性.以下是在 SQL Server 中选择字段数据类型时的一些建议和理由: 1. 整数类型:在 SQL ...
- 记一次有趣的 buffer overflow detected 问题分析
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 环境说明 无 前言 在我开发的一个实验和学习库中,在很久 ...
- client-go实战之九:手写一个kubernetes的controller
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本文是<client-go实战> ...
- Maven 项目工程
maven打包java --jar1.安装jdk2.安装maven --安装非常简单 网上教程很多,此步骤忽略-- 3.配置jdk/maven环境变量 # java_jdk export JAVA ...
- Android-Java-反序列化JSON
import com.google.gson.Gson; import com.google.gson.reflect.TypeToken; String jsonStr= WebAPIOperato ...
- Ubuntu16.04 设置jar开机自启脚本
1.编写脚本 后缀 ".sh" #! /bin/sh ### BEGIN INIT INFO # Provides: start-adb-connect-manager # Re ...