【图论#02】岛屿系列题(数量、周长、最大面积),flood fill算法的代码实现与优化
岛屿数量
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
输入:grid = [
["1","1","1","1","0"],
["1","1","0","1","0"],
["1","1","0","0","0"],
["0","0","0","0","0"]
]
输出:1
示例 2:
输入:grid = [
["1","1","0","0","0"],
["1","1","0","0","0"],
["0","0","1","0","0"],
["0","0","0","1","1"]
]
输出:3
思路
flood fill泛洪算法+dfs
首先我们使用两层for循环遍历二维数组grid,当遇到'1'的时候,标记遇到了“岛屿”,此时岛屿数量加1
然后触发dfs,先将当前位置(是'1')设为'0',在遇到'1'的位置的上下左右搜索。如果碰到'1',说明该位置仍是目前发现的岛屿的一部分陆地,将其改为'0',如果碰到'0'就不管,说明该位置是水不是陆地。
上述操作就是flood fill中的“同化”操作
dfs结束后,当前位置的上下左右都变成了'0'(包括当前位置本身),然后for循环会继续向后遍历,直到再次碰到'1'(即陆地),然后通过一样的方法统计陆地数量并使用dfs同化。
当二维数组grid遍历完成,那么岛屿的数量也就统计完成了。
疑问
以下是解答1,该代码可以通过测试
class Solution {
public:
int row, col;
int dx[4] = {-1,0,1,0};//如果记不住,可以假设一个(1,1),然后通过加减1来确定对应偏移量
int dy[4] = {0,-1,0,1};
int numIslands(vector<vector<char>>& grid) {
int res = 0;
row = grid.size();//行
col = grid[0].size();//列
for(int x = 0; x < row; ++x){//遍历grid,寻找陆地'1'
for(int y = 0; y < col; ++y){
if(grid[x][y] == '1'){//找到陆地之后,同化其上下左右四个方向的区域为'0'
dfs(grid, x, y);//调用递归实现
res++;//记录岛屿数量
}
}
}
return res;
}
void dfs(vector<vector<char>>& grid, int x, int y){
grid[x][y] = '0';
for(int i = 0; i < 4; ++i){//循环四次,使用偏移量计算出当前位置的上下左右位置的坐标
int nx = x + dx[i];
int ny = y + dy[i];
if(nx >= 0 && nx < row && ny >= 0 && ny < col && grid[nx][ny] == '1'){
dfs(grid, nx, ny);//这里其实已经给递归设置了结束条件,如果不满足上面的if的话是不会进入递归的
}
}
}
};
下面是我的解答代码,我也使用了同样的思想,但是为什么我的代码会超时
#include <ratio>
class Solution {
public:
void dfs(vector<vector<char> >& grid, int x, int y, int row, int col){
//递归终止条件
if(x < 0 || x >= row || y < 0 || y >= col || grid[x][y] == '0') return;
//单层处理逻辑
grid[x][y] = '0';
dfs(grid, x - 1, y, row, col);
dfs(grid, x + 1, y, row, col);
dfs(grid, x, y - 1, row, col);
dfs(grid, x, y + 1, row, col);
return;
}
int solve(vector<vector<char> >& grid) {
// write code here
if(grid.size() == 0) return 0;
int row = grid.size();
int col = grid[0].size();
int res = 0;
for(int x = 0; x < row; ++x){
for(int y = 0; y < col; ++y){
if(grid[x][y] == '1'){
res += 1;
dfs(grid, x, y, row, col);
}
}
}
return res;
}
};
原因
这个主要是代码实现的问题,思路是一样的,都是基于flood fill泛洪算法+dfs实现
我的代码中,递归中遍历的东西太多,加上递归深度比较深,所以出现了栈溢出的问题
例如,在实现flood fill中"同化"操作时,我的代码需要对上下左右进行四次递归才能将所有情况尝试一遍,这就产生了巨大的开销
优化
使用偏移量来简化对四个方向的搜索
用dx和dy数组来表示上下左右四个方向的偏移量。通过对当前位置 (x, y) 分别加上 dx[i] 和 dy[i],可以得到该方向的相邻位置 (nx, ny)。
for(int i = 0; i < 4; ++i){
int nx = x + dx[i];//由当前位置坐标加上偏移量计算得到的上下左右的坐标
int ny = y + dy[i];
if(nx >= 0 && nx < row && ny >= 0 && ny < col && grid[nx][ny] == '1'){
dfs(grid, nx, ny);
}
}
这样优化之后,我们只需要循环4次,计算四个方向的坐标,然后每次调用一个递归函数就可以实现对四个方向的搜索
减少了递归深度
举个例子来说明,假设当前位置为
(1, 1),则根据dx和dy数组中的元素,可以得到下面四个相邻位置:
- 上方位置:
(1 + dx[0], 1 + dy[0]) = (1 - 1, 1 + 0) = (0, 1)- 左方位置:
(1 + dx[1], 1 + dy[1]) = (1 + 0, 1 - 1) = (1, 0)- 下方位置:
(1 + dx[2], 1 + dy[2]) = (1 + 1, 1 + 0) = (2, 1)- 右方位置:
(1 + dx[3], 1 + dy[3]) = (1 + 0, 1 + 1) = (1, 2)可以看到,通过不同的
dx[i]和dy[i]组合,可以分别表示上下左右四个方向的移动。其中,
dx[0] = -1代表向上移动,dx[1] = 0代表向左移动,dx[2] = 1代表向下移动,dx[3] = 0代表向右移动。类似地,
dy[0] = 0、dy[1] = -1、dy[2] = 0、dy[3] = 1分别对应着上下左右四个方向的纵向偏移量。
岛屿周长
给定一个 row x col 的二维网格地图 grid ,其中:grid[i][j] = 1 表示陆地, grid[i][j] = 0 表示水域。
网格中的格子 水平和垂直 方向相连(对角线方向不相连)。整个网格被水完全包围,但其中恰好有一个岛屿(或者说,一个或多个表示陆地的格子相连组成的岛屿)。
岛屿中没有“湖”(“湖” 指水域在岛屿内部且不和岛屿周围的水相连)。格子是边长为 1 的正方形。网格为长方形,且宽度和高度均不超过 100 。计算这个岛屿的周长。
示例 1:
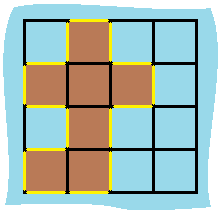
输入:grid = [[0,1,0,0],[1,1,1,0],[0,1,0,0],[1,1,0,0]]
输出:16
解释:它的周长是上面图片中的 16 个黄色的边
示例 2:
输入:grid = [[1]]
输出:4
示例 3:
输入:grid = [[1,0]]
输出:4
思路
与岛屿数量类似,仍然可以基于flood fill的思想去做,但是我们这里要考虑一些别的事情
同化操作
这里在进行同化时,不能再将方格值修改为0,因为0在题意中是不可遍历的。因此我们可以将同化过的方格标记为2
统计周长
周长如何进行统计呢?其实可以把所有方格可能出现的情况枚举出来即可
假设遍历到当前方格A
- A往某个方向走碰到网格边界,该方向上A的周长加1;
- A往某个方向走碰到水,该方向上A的周长加1;
- A往某个方向走碰到陆地 ,该方向上A的周长不增加;(还没到陆地边界)
代码
代码实现上,仍然使用岛屿数量中的优化版本框架
但是,由于我们需要统计周长,因此dfs需要有返回值
周长统计的几种情况作为递归的结束条件即可
class Solution {
public:
int row, col;
int dx[4] = {-1, 0, 1, 0};
int dy[4] = {0, -1, 0, 1};
int islandPerimeter(vector<vector<int>>& grid) {
row = grid.size();
col = grid[0].size();
int res = 0; // 初始化周长为0
for (int x = 0; x < row; ++x) {
for (int y = 0; y < col; ++y) {
if (grid[x][y] == 1) { // 题目限制只有一个岛屿
res = dfs(grid, x, y); // 递归计算岛屿周长
}
}
}
return res;
}
int dfs(vector<vector<int>>& grid, int x, int y) {
// 从岛屿方格往网格边界走,周长加1
if (!(x >= 0 && x < row && y >= 0 && y < col)) {
return 1;
}
if (grid[x][y] == 0) {//从岛屿方格往水走,周长加1
return 1;
}
if (grid[x][y] != 1) {//如果当前方格就是水,那么结束递归,因为水无法遍历
return 0;
}
grid[x][y] = 2; // 将访问过的方格标记为2
int perimeter = 0;
for (int i = 0; i < 4; ++i) { // 循环四次,使用偏移量计算出当前位置的上下左右位置的坐标
int nx = x + dx[i];
int ny = y + dy[i];
perimeter += dfs(grid, nx, ny); // 累加周长
}
return perimeter;
}
};
注意:
- dfs中,需要使用周长统计的几种情况作为结束条件
岛屿最大面积
给你一个大小为 m x n 的二进制矩阵 grid。
岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在 水平或者竖直的四个方向上 相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。
岛屿的面积是岛上值为 1 的单元格的数目。
计算并返回 grid 中最大的岛屿面积。如果没有岛屿,则返回面积为 0 。
示例 1:
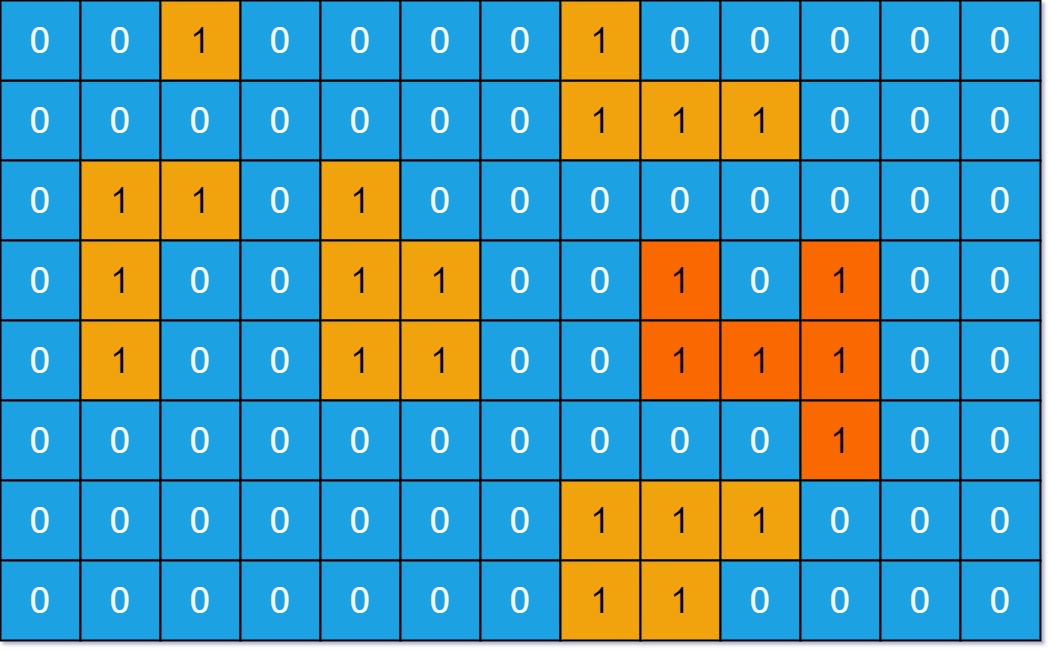
输入:grid = [[0,0,1,0,0,0,0,1,0,0,0,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,1,1,0,1,0,0,0,0,0,0,0,0],[0,1,0,0,1,1,0,0,1,0,1,0,0],[0,1,0,0,1,1,0,0,1,1,1,0,0],[0,0,0,0,0,0,0,0,0,0,1,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,0,0,0,0,0,0,1,1,0,0,0,0]]
输出:6
解释:答案不应该是 11 ,因为岛屿只能包含水平或垂直这四个方向上的 1 。
示例 2:
输入:grid = [[0,0,0,0,0,0,0,0]]
输出:0
思路
因为网格是由多个小格子组成的,每个格子是正方形,因此每个方格的面积是1
因此计算岛屿面积只需要累加遇到的陆地方格的数量即可,所以本题在底层上和岛屿数量是一样的
使用flood fill遍历网格,当遇到陆地时,我们触发递归使其返回当前陆地以及四周区域陆地(如果有)的面积
代码
这里的递归函数也需要返回值,逻辑如下:
如果调用递归函数后发现当前方格是陆地,那么记录当前面积至累加值,然后递归遍历其四周
如果不是陆地,则结束递归
class Solution {
public:
int dx[4] = {-1,0,1,0};
int dy[4] = {0,-1,0,1};
int row, col;
int maxAreaOfIsland(vector<vector<int>>& grid) {
int res = 0;
int area = 0;
row = grid.size();
col = grid[0].size();
for(int x = 0; x < row; ++x){
for(int y = 0; y < col; ++y){
if(grid[x][y] == 1){
area = dfs(grid, x, y);
res = max(res, area);
}
}
}
return res;
}
int dfs(vector<vector<int>>& grid, int x, int y){
if(x >= 0 && x < row && y >= 0 && y < col && grid[x][y] == 1){//遇到陆地触发递归
grid[x][y] = 0;//同化
int area = 1;//面积初始值肯定是1
for(int i = 0; i < 4; ++i){//递归遍历陆地四周
int nx = x + dx[i];
int ny = y + dy[i];
area += dfs(grid, nx, ny); //累加陆地面积
}
return area;
}
//不是陆地就结束递归
return 0;
}
};
注意:这里写dfs时,递归终止条件是当前方格是否是陆地
【图论#02】岛屿系列题(数量、周长、最大面积),flood fill算法的代码实现与优化的更多相关文章
- 【LeetCode动态规划#11】打家劫舍系列题(涉及环结构和树形DP的讨论)
打家劫舍 力扣题目链接(opens new window) 你是一个专业的小偷,计划偷窃沿街的房屋.每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻 ...
- 分布式ID系列(5)——Twitter的雪法算法Snowflake适合做分布式ID吗
介绍Snowflake算法 SnowFlake算法是国际大公司Twitter的采用的一种生成分布式自增id的策略,这个算法产生的分布式id是足够我们我们中小公司在日常里面的使用了.我也是比较推荐这一种 ...
- 《zw版·Halcon-delphi系列原创教程》简单的令人发指,只有10行代码的车牌识别脚本
<zw版·Halcon-delphi系列原创教程>简单的令人发指,只有10行代码的车牌识别脚本 简单的令人发指,只有10行代码的车牌识别脚本 人脸识别.车牌识别是opencv当中 ...
- 计算概论(A)/基础编程练习2(8题)/3:计算三角形面积
#include<stdio.h> #include<math.h> int main() { // 声明三角形的三个顶点坐标和面积 float x1, y1, x2, y2, ...
- 数据挖掘系列 (1) 关联规则挖掘基本概念与 Aprior 算法
转自:http://www.cnblogs.com/fengfenggirl/p/associate_apriori.html 数据挖掘系列 (1) 关联规则挖掘基本概念与 Aprior 算法 我计划 ...
- 【ABAP系列】SAP ABAP 为表维护生成器创建事务代码
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[ABAP系列]SAP ABAP 为表维护生成器 ...
- [易学易懂系列|rustlang语言|零基础|快速入门|(16)|代码组织与模块化]
[易学易懂系列|rustlang语言|零基础|快速入门|(16)|代码组织与模块化] 实用知识 代码组织与模块化 我们知道,在现代软件开发的过程中,代码组织和模块化是应对复杂性的一种方式. 今天我们来 ...
- Java练习 SDUT-3339_计算长方形的周长和面积(类和对象)
计算长方形的周长和面积(类和对象) Time Limit: 1000 ms Memory Limit: 65536 KiB Problem Description 设计一个长方形类Rect,计算长方形 ...
- 【DTOJ】1001:长方形周长和面积
DTOJ 1001:长方形周长和面积 解题报告 2017.11.05 第一版 ——由翱翔的逗比w原创 题目信息: 题目描述 已知长方形的长和宽,求长方形的周长和面积? 输入 一行:空格隔开的两个整 ...
- 数据挖掘入门系列教程(四点五)之Apriori算法
目录 数据挖掘入门系列教程(四点五)之Apriori算法 频繁(项集)数据的评判标准 Apriori 算法流程 结尾 数据挖掘入门系列教程(四点五)之Apriori算法 Apriori(先验)算法关联 ...
随机推荐
- [转帖]程序运行崩溃(segfault)的排查方法
这篇博文记录的非常详细:https://blog.csdn.net/zhaohaijie600/article/details/45246569 我的笔记: 写的C++程序老是运行两三天就挂了,关键是 ...
- [转帖]天行健,国产CPU当自强不息
https://baijiahao.baidu.com/s?id=1699201892754975586 本页面的文字和图像允许在CC-BY-SA 3.0协议四和GNU自由文档许可证下修改和再使用 ...
- [转帖] Linux命令拾遗-剖析工具
https://www.cnblogs.com/codelogs/p/16060472.html 简介# 这是Linux命令拾遗系列的第五篇,本篇主要介绍Linux中常用的线程与内存剖析工具,以及更高 ...
- 可插拔组件设计机制—SPI
作者:京东物流 孔祥东 1.SPI 是什么? SPI 的全称是Service Provider Interface,即提供服务接口:是一种服务发现机制,SPI 的本质是将接口实现类的全限定名配置在文件 ...
- echarts api的介绍
参考的地址:https://echarts.apache.org/zh/api.html echarts.init echarts.init(dom?: HTMLDivElement|HTMLCanv ...
- Windows 10 关闭搜索栏中“热门搜索”的显示。
Windows 10 关闭搜索栏中"热门搜索"的显示. 任务栏取消"显示搜索突出显示"的设置可能无法取消"热门搜索"的显示, 这就需要您尝试 ...
- 树状数组(区间修改&&区间查询)
#include<bits/stdc++.h> #define int long long using namespace std; int n,m,x,x1,y,z; int a[100 ...
- ActiveReports报表行号
=RunningValue(Fields!字段名称.Value, CountDistinct, "矩表分组名称") RunningValue(Fields!区域.Value, Co ...
- 加速tortoisegit的show log,减少等待时间
KMSID: 81703 是否同步到KM: 是 是否原创: 是 标签: 游戏开发 允许复制: 是 允许评论: 是 允许导出PDF: 是 职业库分类KMS: 游戏-游戏程序 查看权限KMS:网易正式员工 ...
- TienChin 新建业务菜单
首先是移动菜单,参考下图将菜单移动到下图结构: 我这里将系统监控,系统工具都移动到了系统管理下面,并且排了个序,将多级菜单放在了一起,这样看起来更加的清晰. 修改一下系统管理(100)与TienChi ...