ETL之apache hop数据增量同步功能
ETL增量数据抽取CDC
概念:Change Data Capture,变化的数据捕获,也称:【增量数据抽取】(名词解释)
CDC是一种实现数据的增量抽取解决方案,是实现【ETL整体解决方案】中的一项子方案/子问题。(对CDC的定位)
如何捕获变化的数据是增量抽取的关键,对捕获方法一般有2点要求:
- 准确性:能够将业务系统中的变化数据准确地捕获到;
- 性能:尽量减少对业务系统造成太大的压力,影响现有业务。
2 CDC 常见解决方案
按CDC方案的任一操作是否对数据源系统产生影响(性能、功能等),分为:【侵入式CDC】、【非侵入式CDC】
按CDC方案所抽取的数据与数据源系统的变化数据是否在规定时间内同步,分为:【同步CDC】、【异步CDC】
一、侵入式
1、基于触发器
创建中间表,编写触发器或者在后端服务插入增删改的操作记录
2、基于时间戳
区分插入操作和更新操作:只有当源系统包含了插入时间戳和更新时间戳两个字段,才能区别插入和更新,否则无法区分。
删除记录的操作:不能捕获到删除操作,除非是逻辑删除,即记录没有真的删除,只是做了逻辑上的标志。
多次更新检测:如果在一次同步周期内,数据被更新了多次,只能同步最后一次更新操作,中间的更新操作都丢失了。
实时能力:时间戳和基于序列的数据抽取一般适用于批量操作,不适合于实时场景下的数据加载。
二、非侵入式
3、基于快照
1基于快照的CDC可检测到插入、更新和删除的数据 (相比基于时间戳的CDC的优点)
2需要大量存储空间来保存快照
4、基于日志
源数据库会把每个插入、更新、删除操作记录到日志里。
通过分析已经发生的事件提交(commit)的日志记录来得到增量数据信息,有一定的时间延迟。
【特点】复杂、异步、非侵入式
参考文档:
https://zhuanlan.zhihu.com/p/362471672
https://www.cnblogs.com/johnnyzen/p/12781942.html
基于以上的几种增量同步方式优缺点,采用第一种基于触发器方式
本文中的示例是源数据库Sql Server 数据库的数据同步到目标数据库MySql数据库中,被同步的源数据库为Test,Schema 为innovator,表名为MyTable
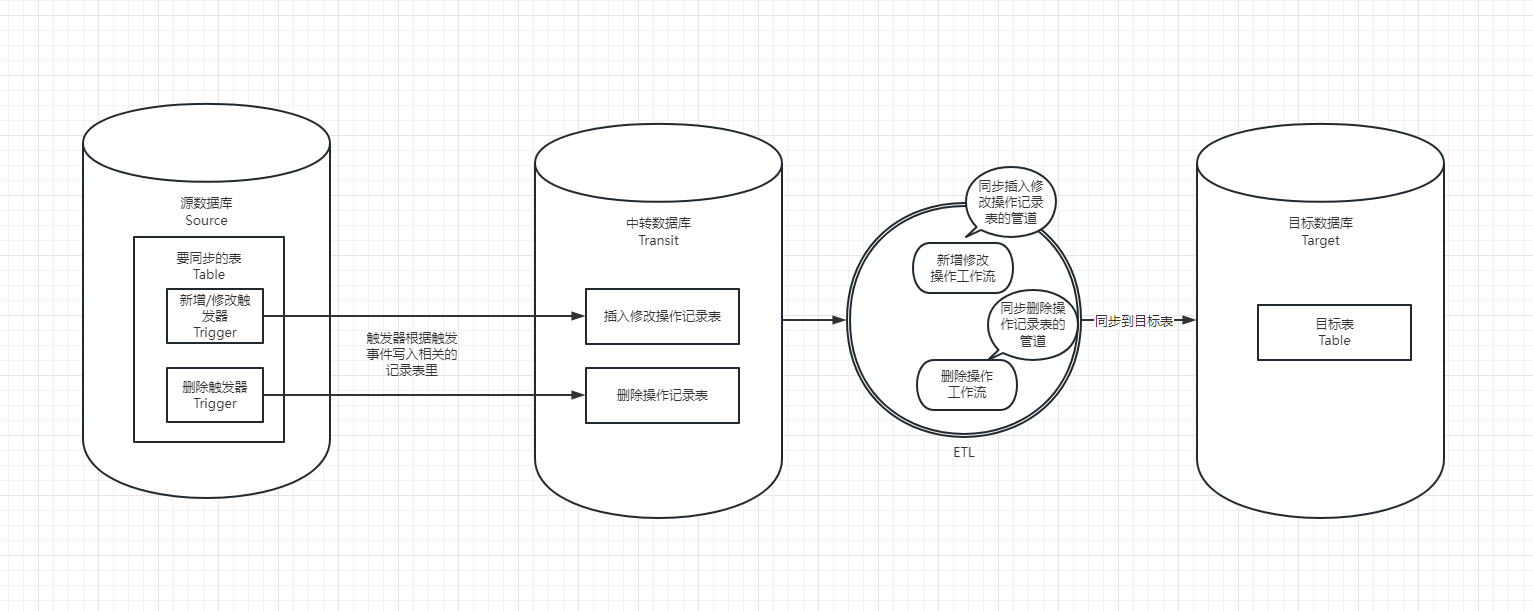
流程示意图
一、在数据库层面上的系列操作
表的创建SQL如下
CREATE TABLE [innovator].[MyTable] (
[Id] char(32) COLLATE Chinese_PRC_CI_AS NOT NULL PRIMARY KEY ,
[Name] nvarchar(255) COLLATE Chinese_PRC_CI_AS NOT NULL,
[CreatedTime] datetime NOT NULL,
)
1、建立SQL Server中间数据库temp_db,需要同步的所有表放在dbo下
2、创建需要同步的中间表,比如 ,中间表的表名addOrEdit_MyTable,字段和源表一样
-- 只复制基础表结构不复制索引触发器
SELECT * INTO temp_db.dbo.addOrEdit_MyTable FROM Test.innovator.MyTable WHERE 1 = 0;
3、创建需要同步删除的中间表Table_Delete
CREATE TABLE [dbo].[Table_Delete] (
[Id] char(32) COLLATE Chinese_PRC_CI_AS NOT NULL PRIMARY KEY,
[TableName] nvarchar(255) COLLATE Chinese_PRC_CI_AS NOT NULL,
[DeletedTime] datetime NOT NULL,
)
4、在源数据库Test里的MyTable表里创建两个触发器
(1) 插入修改触发器
CREATE TRIGGER [innovator].[insertUpdateTrigger_MyTable]
ON [innovator].[MyTable]
WITH EXECUTE AS CALLER
FOR INSERT, UPDATE
AS
BEGIN
-- Type the SQL Here.
--检查插入或更新的数据在A表中是否存在,有则更新,无则添加
if EXISTS(select 1 from temp_db.dbo.addOrEdit_MyTable as A,inserted as B where A.id=B.id)
UPDATE A set
A.Name=B.Name,A.CreatedTime=B.CreatedTime
from temp_db.dbo.addOrEdit_MyTable A join inserted B on A.id= B.id
else
insert into temp_db.dbo.addOrEdit_MyTable select * from inserted
END
(2) 删除触发器
CREATE TRIGGER [innovator].[deleteTrigger_MyTable]
ON [innovator].[MyTable]
WITH EXECUTE AS CALLER
FOR DELETE
AS
BEGIN
-- Type the SQL Here.
insert into temp_db.dbo.Table_Delete select Id ,'MyTable' as TableName, GETDATE() as DeletedTime from deleted;
END
(3) 触发器图片参考

5、创建Mysql目标数据库 Test_Mysql,字符集选择为utf8mb4
-- CREATE DATABASE Test_Mysql DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_chinese_ci;
CREATE DATABASE IF NOT EXISTS Test_Mysql DEFAULT CHARSET utf8mb4 COLLATE utf8mb4_general_ci;
6、在Test_Mysql数据库里创建表MyTable
DROP TABLE IF EXISTS `MyTable`;
CREATE TABLE `MyTable` (
`Id` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`Name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`CreatedTime` datetime(0) NOT NULL,
PRIMARY KEY (`ID`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
7、可能存在触发器中不能访问temp_db数据库,解决如下:
-- 1、查询所有数据库信息
SELECT name, database_id, is_trustworthy_on FROM sys.databases
-- 2、修改 SQL Server 的实例是否信任该数据库以及其中的内容(注意:必须是 sysadmin 固定服务器角色的成员才能设置此选项。)
ALTER DATABASE temp_db set TRUSTWORTHY ON
-- 3、查询系统所有用户
SELECT name FROM Sysusers
-- 4、给用户innovator_regular授权访问temp_db数据库
ALTER AUTHORIZATION ON DATABASE::temp_db TO innovator_regular
二、在apache hop上编写工作流和管道
这里偷点懒,不想再写一遍这些管道和工作流,拿之前写的截个图
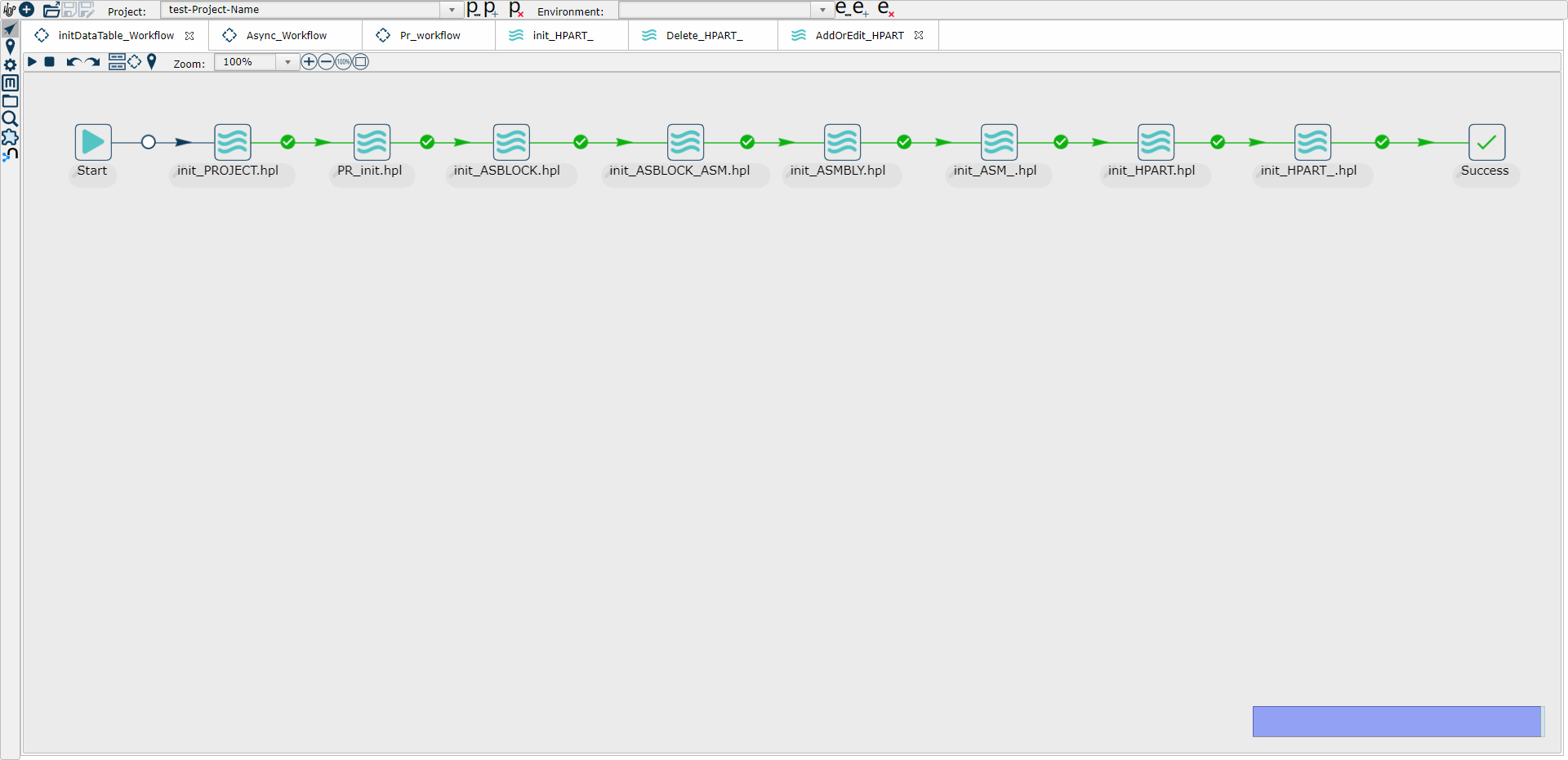
1、编写源表数据第一次全量同步到目标表的管道,命名为Init_MyTable(比如下面示意图中的Init_HPART_)
(1) Table input就是源数据库Sql Server里的表,Insert/update 里就是被插入修改同步操作的目标MySql表
(2) Table input 示例图
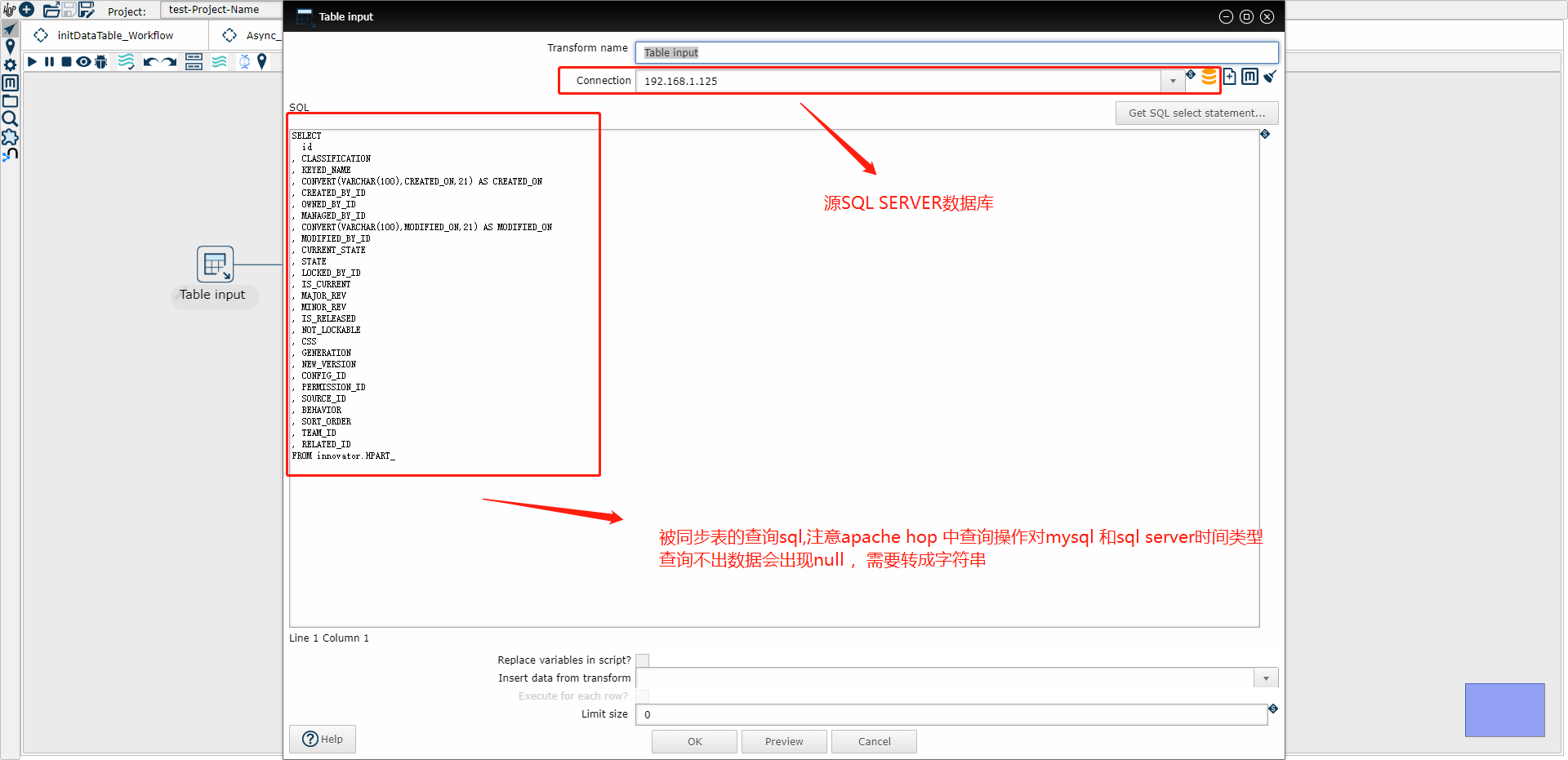
把上图的示例sql改为下面的
SELECT
Id,
Name,
CONVERT(VARCHAR(100),CreatedTime,21) AS CreatedTime
FROM innovator.MyTable
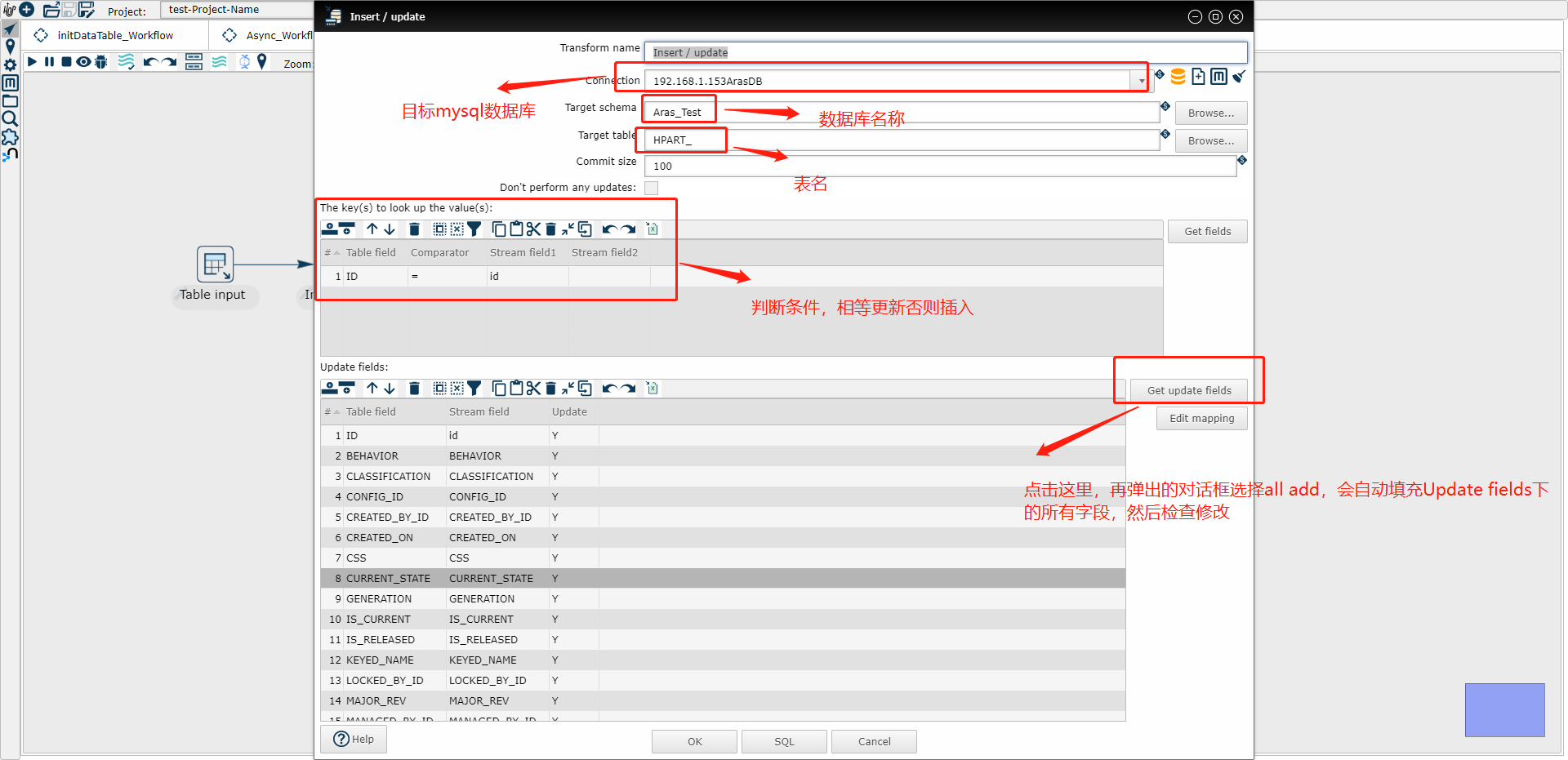
(3) Insert/update 示例图
2、编写源表数据第一次全量同步到目标表的初始化工作流,命名为Init_Wrokflow(比如下面示意图中的InitDataTable_Wrokflow) (只执行一次)
3、编写增量同步添加修改操作的管道,命名为AddOrEdit_MyTable(比如下面示意图中的PR_AddOrEdit)
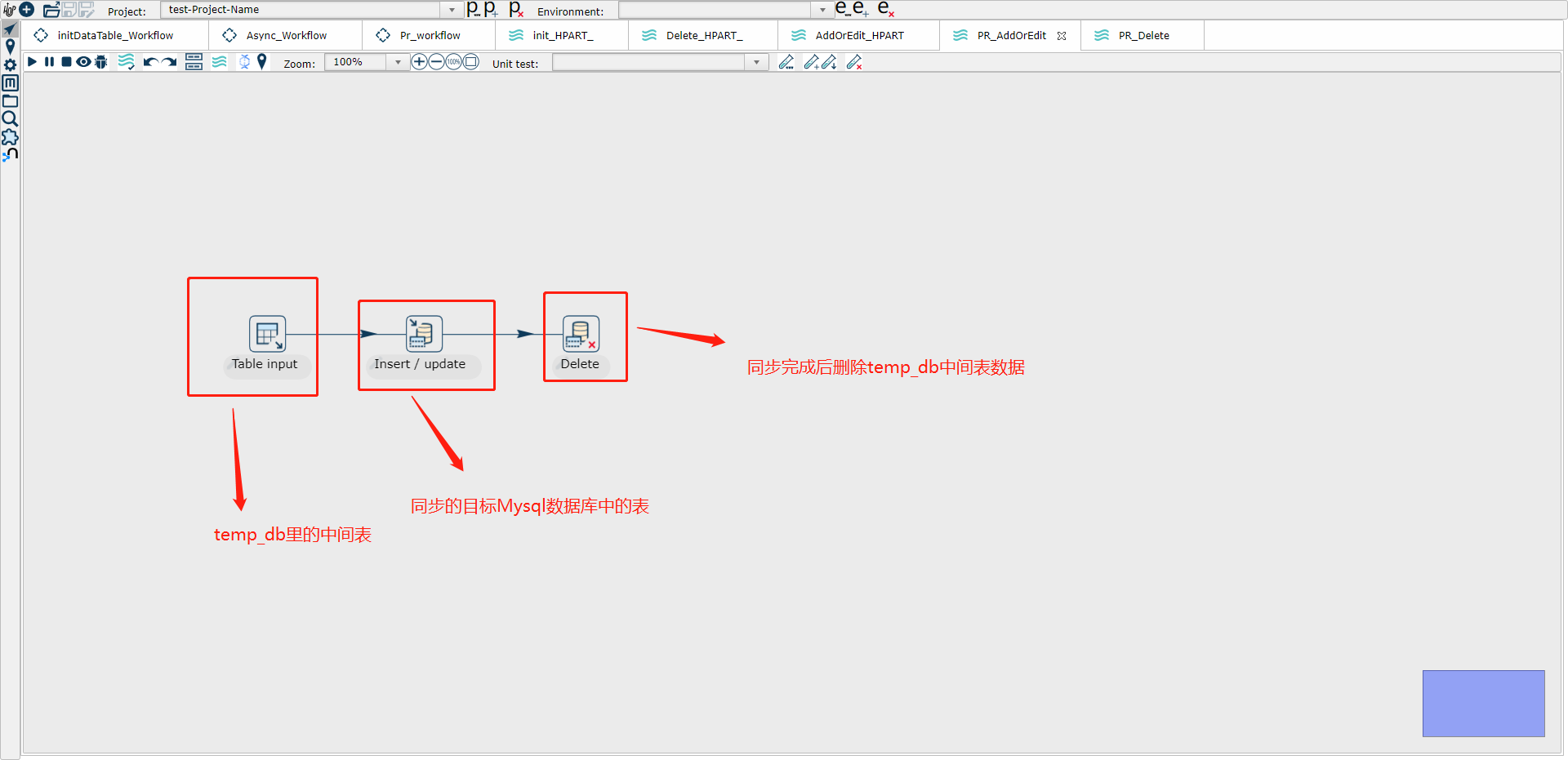
(1) Table input 示例图
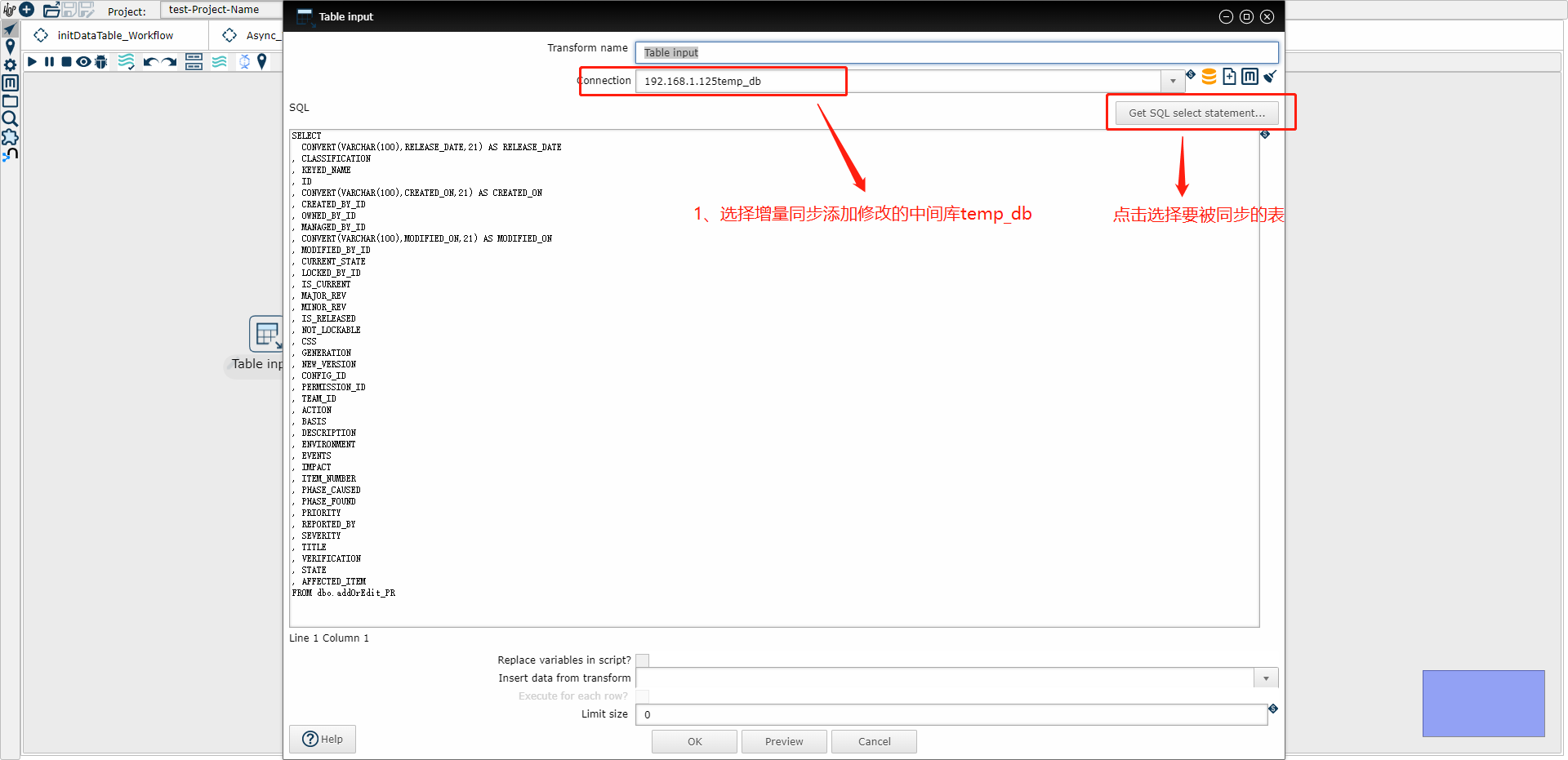
把上图的示例sql改为下面的
SELECT
Id,
Name,
CONVERT(VARCHAR(100),CreatedTime,21) AS CreatedTime
FROM dbo.addOrEdit_MyTable
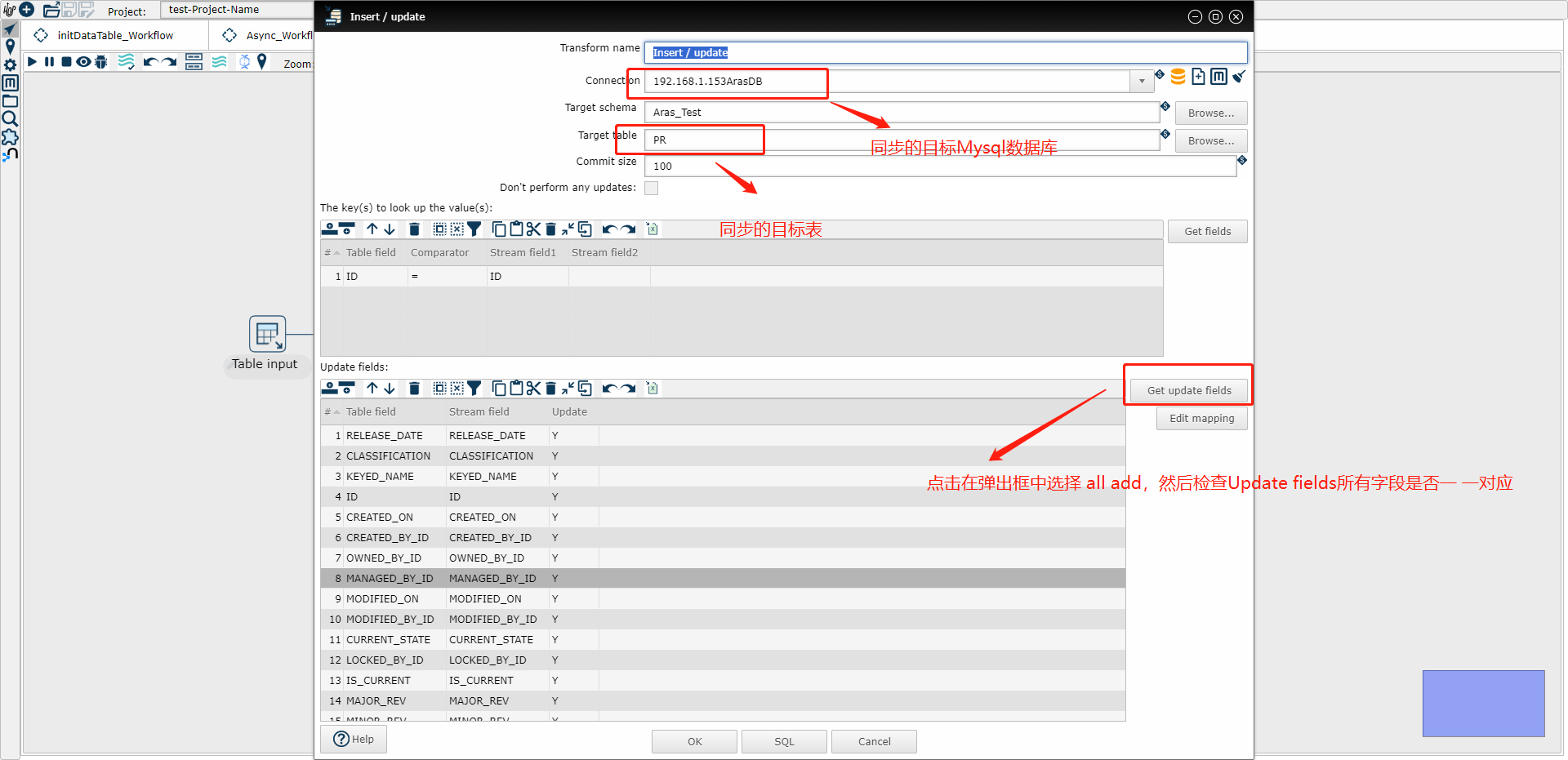
(2) Insert/update 示例图
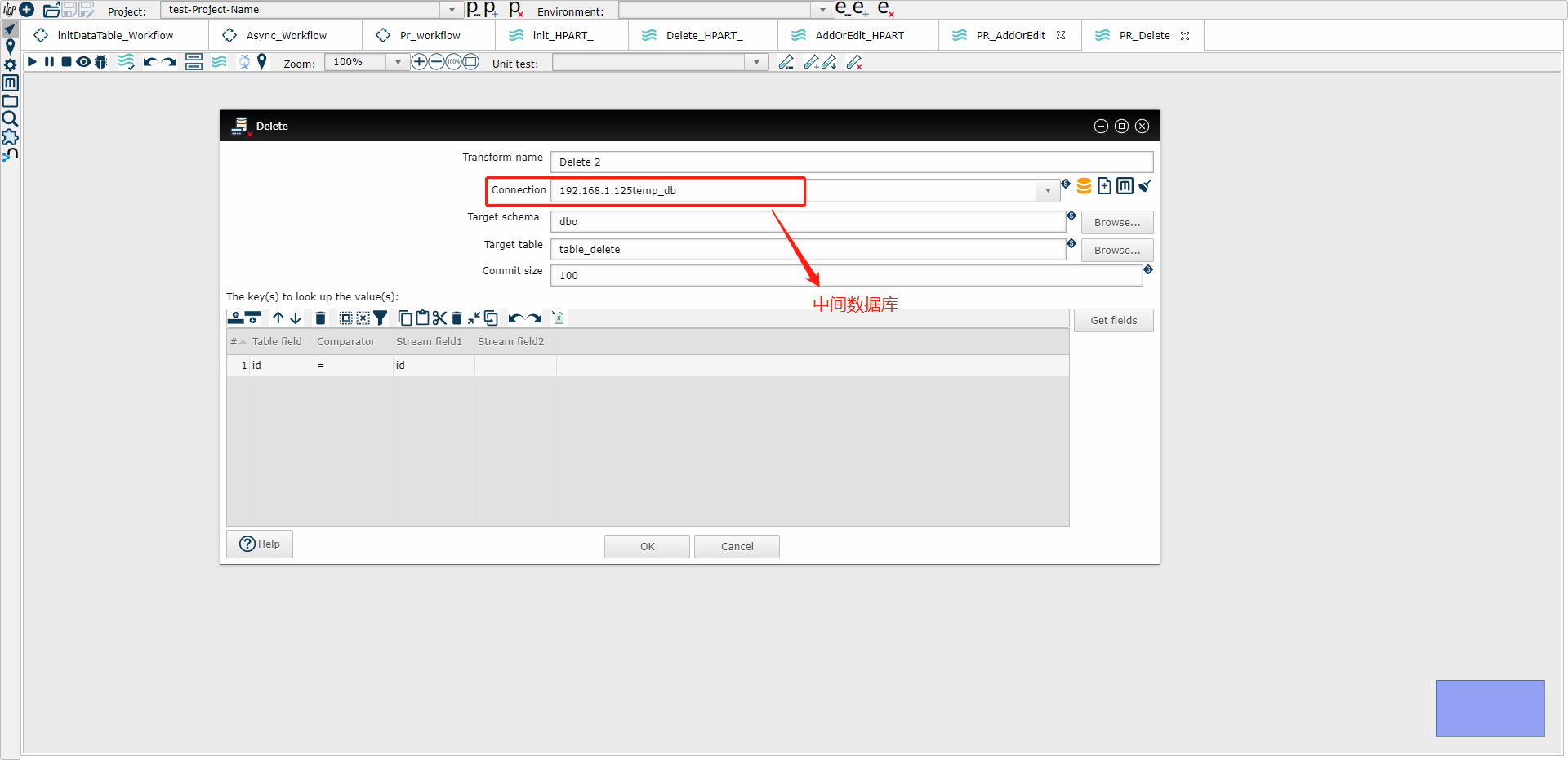
(3) Delete 示例图
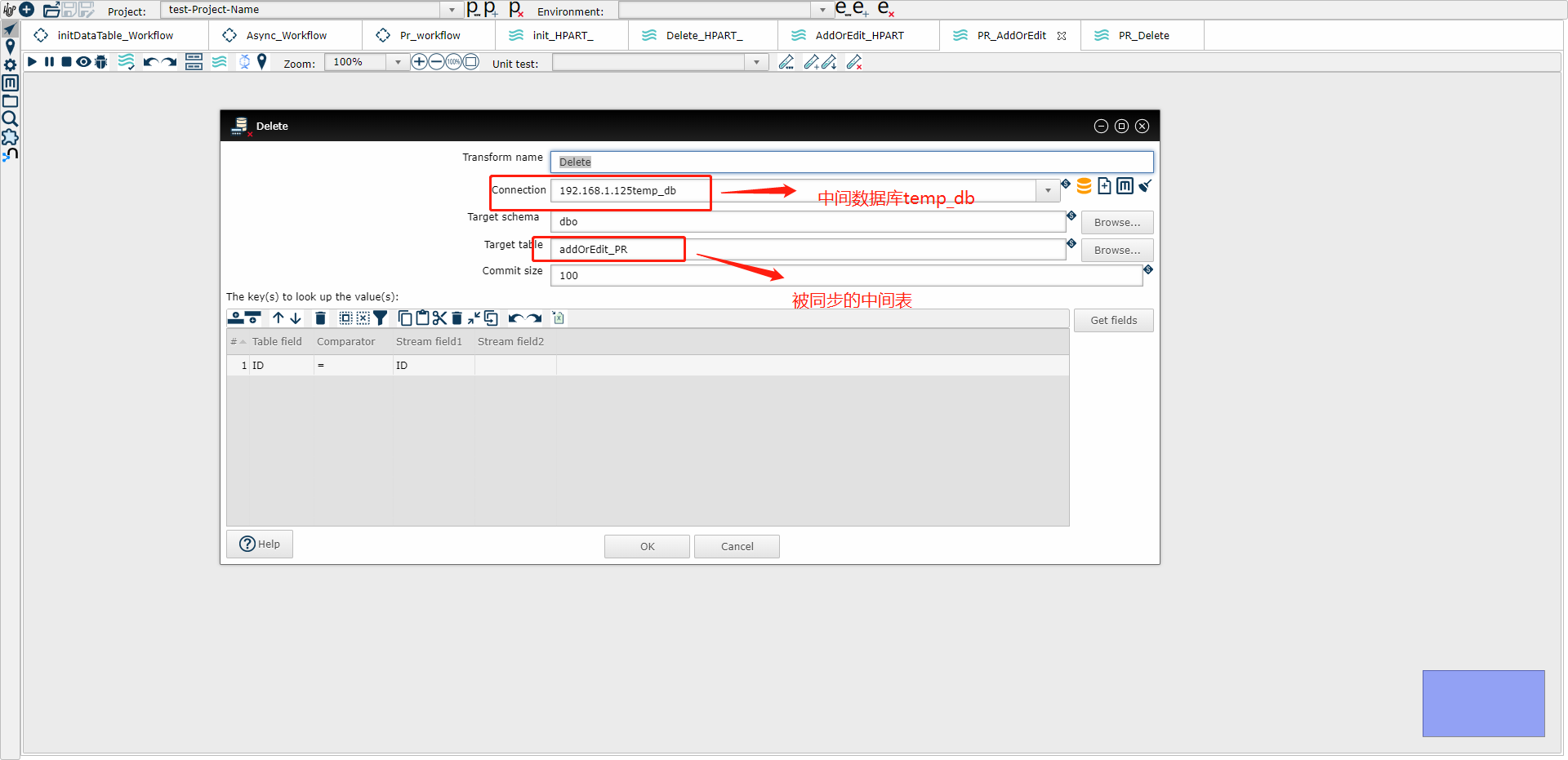
4、编写增量同步删除操作的管道,命名为Delete_MyTable(比如下面示意图中的PR_Delete)
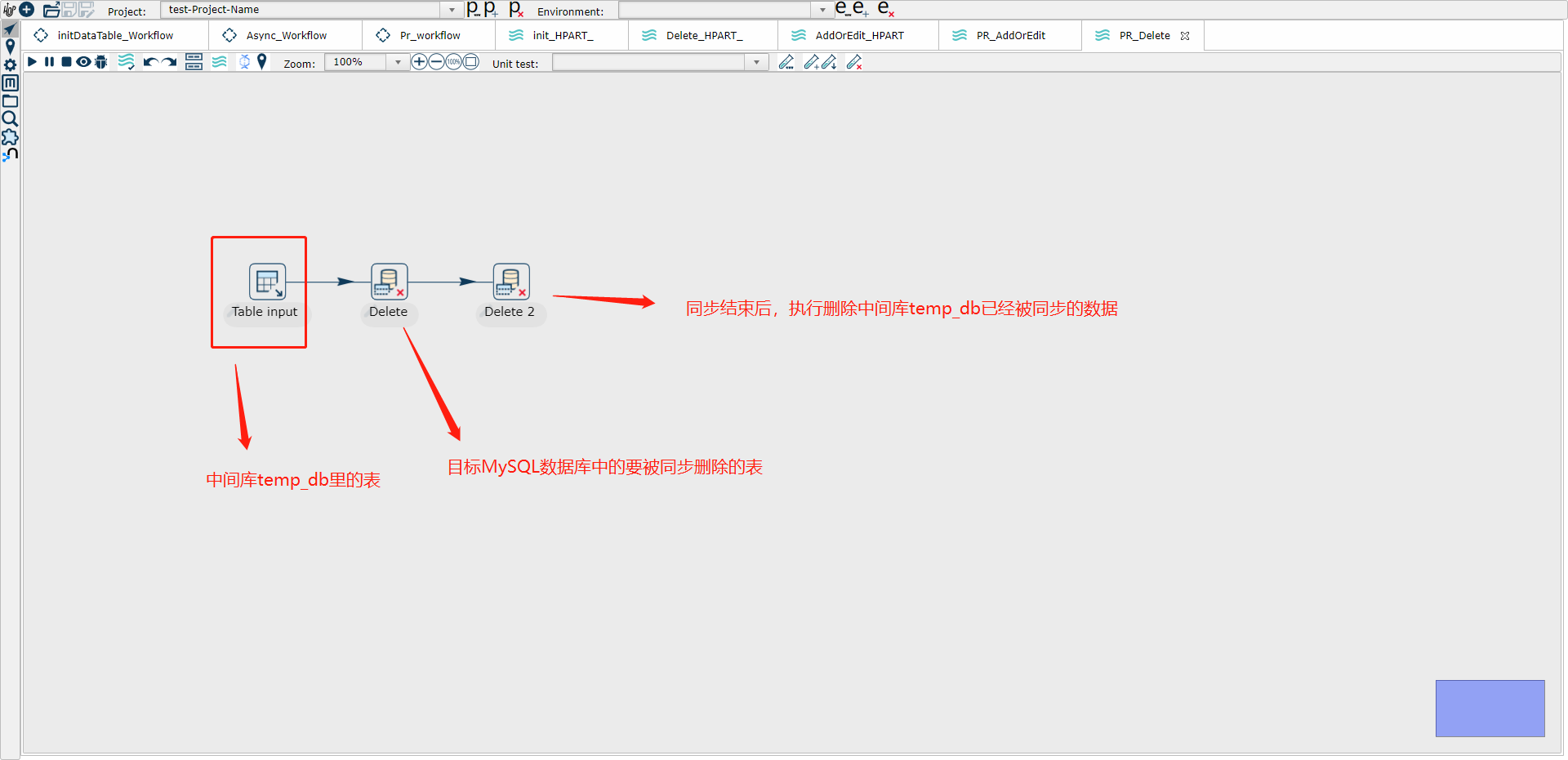
(1) Table input 示例图
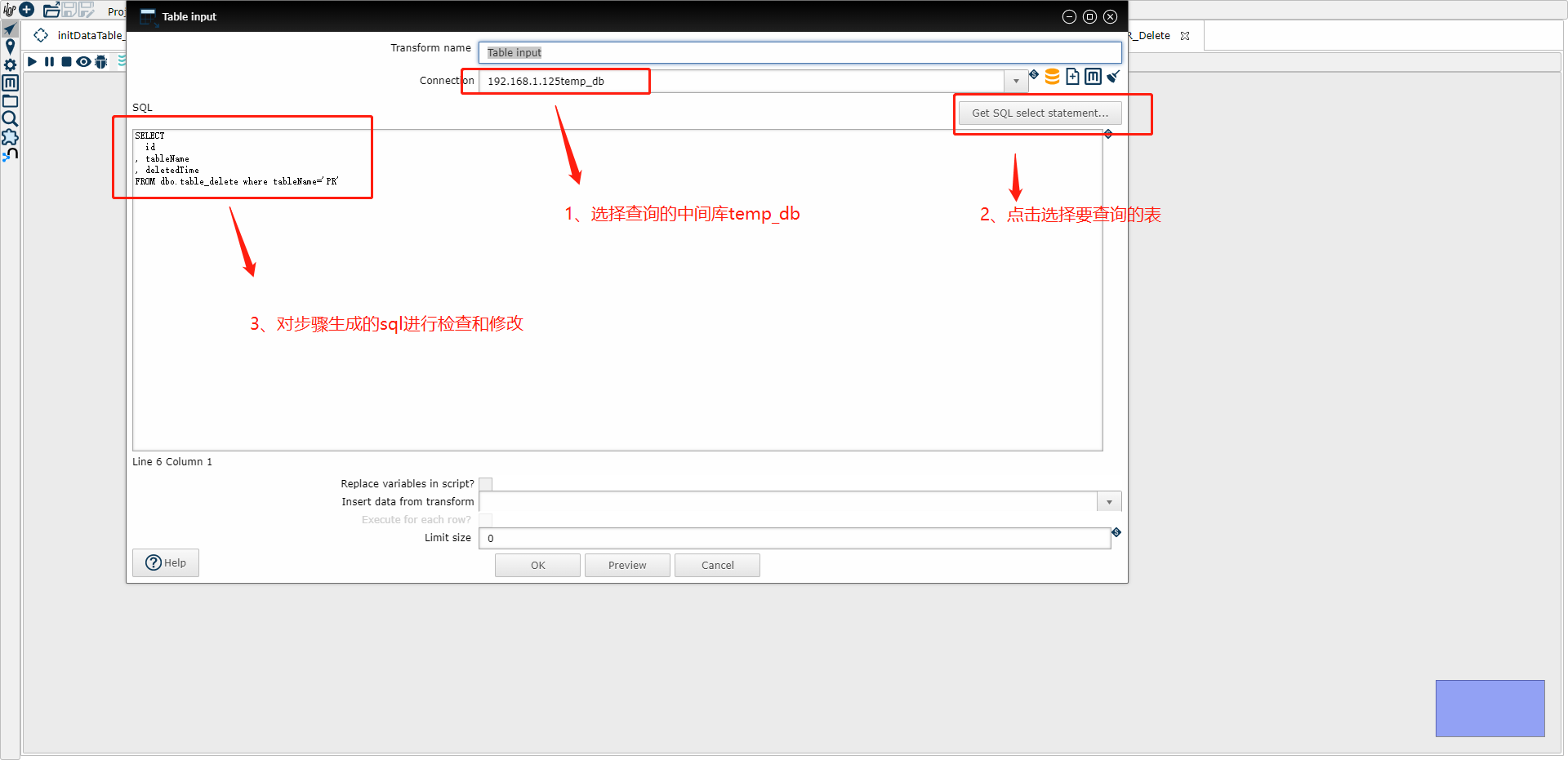
这里Sql改为
SELECT Id,TableName,DeletedTime FROM dbo.Table_Delete where TableName='MyTable'
(2) Delete 示例图
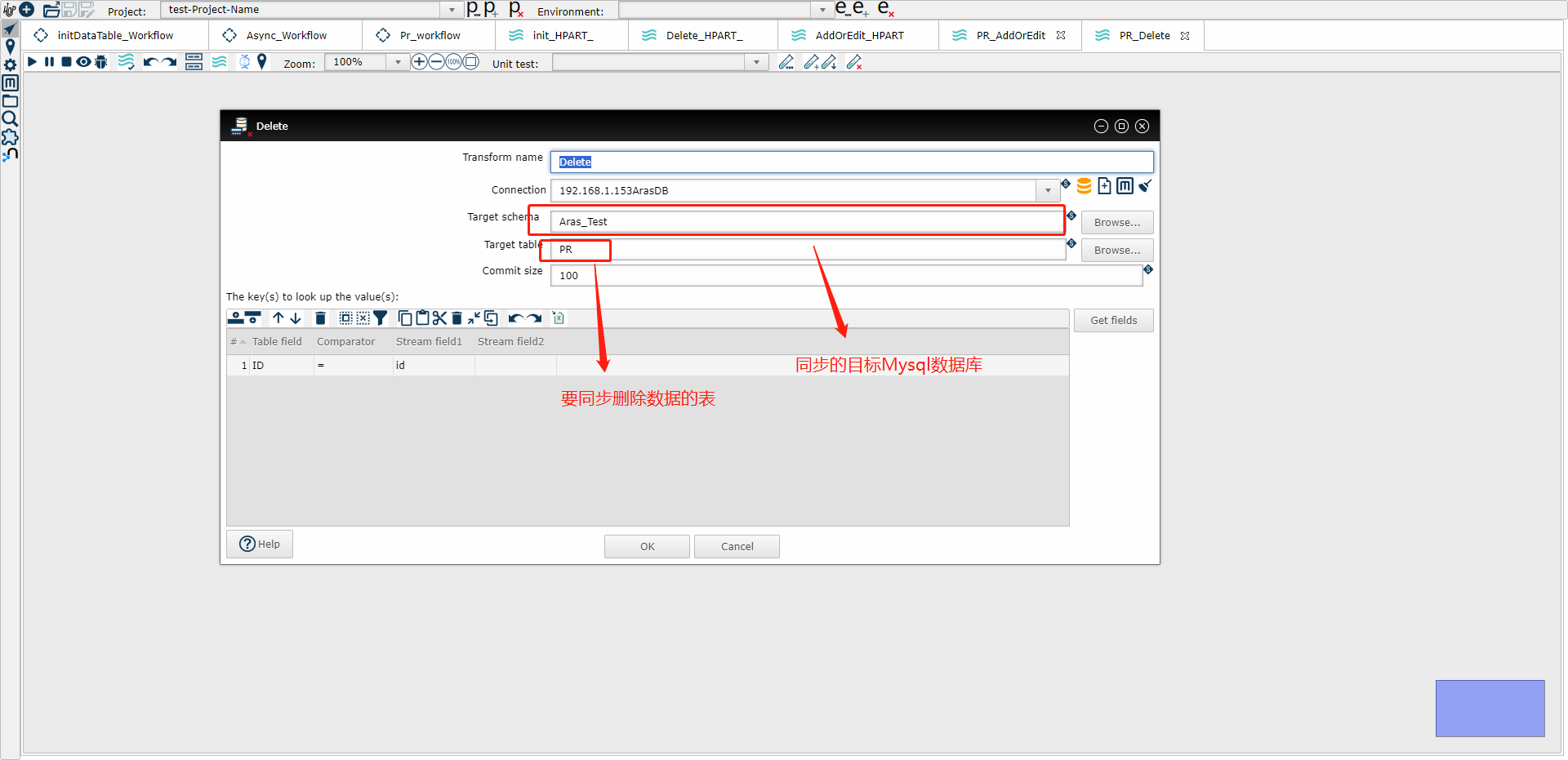
(3) Delete2 示例图
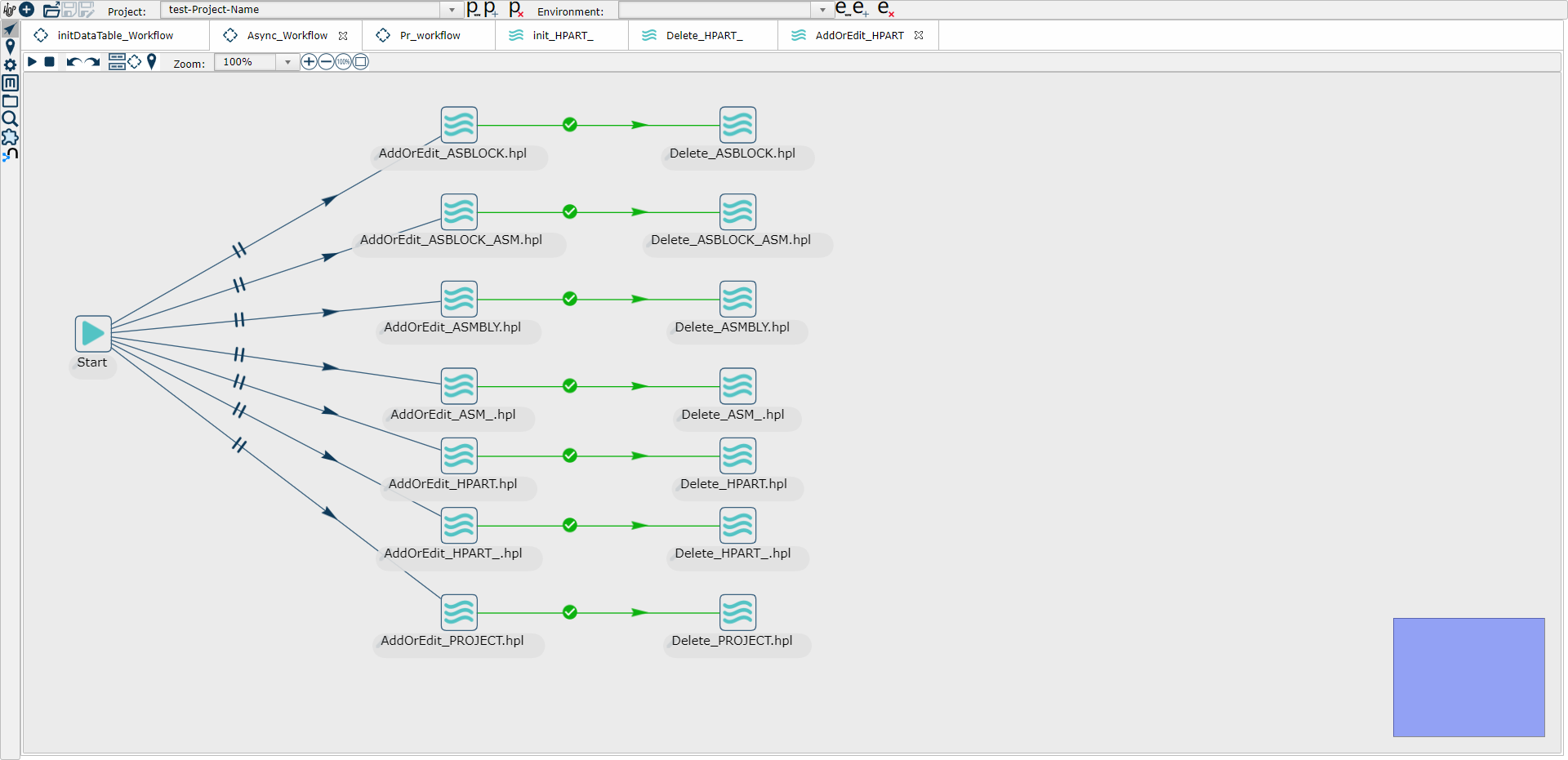
5、编写增量同步的工作流,命名为MyTable_Workflow(比如下面示意图中的PR_workflow)(定时执行)
其中 PR_AddOrEdit.hpl就是步骤3中的同步添加修改操作的管道,PR_Delete.hpl就是步骤四中的增量同步删除操作的管道
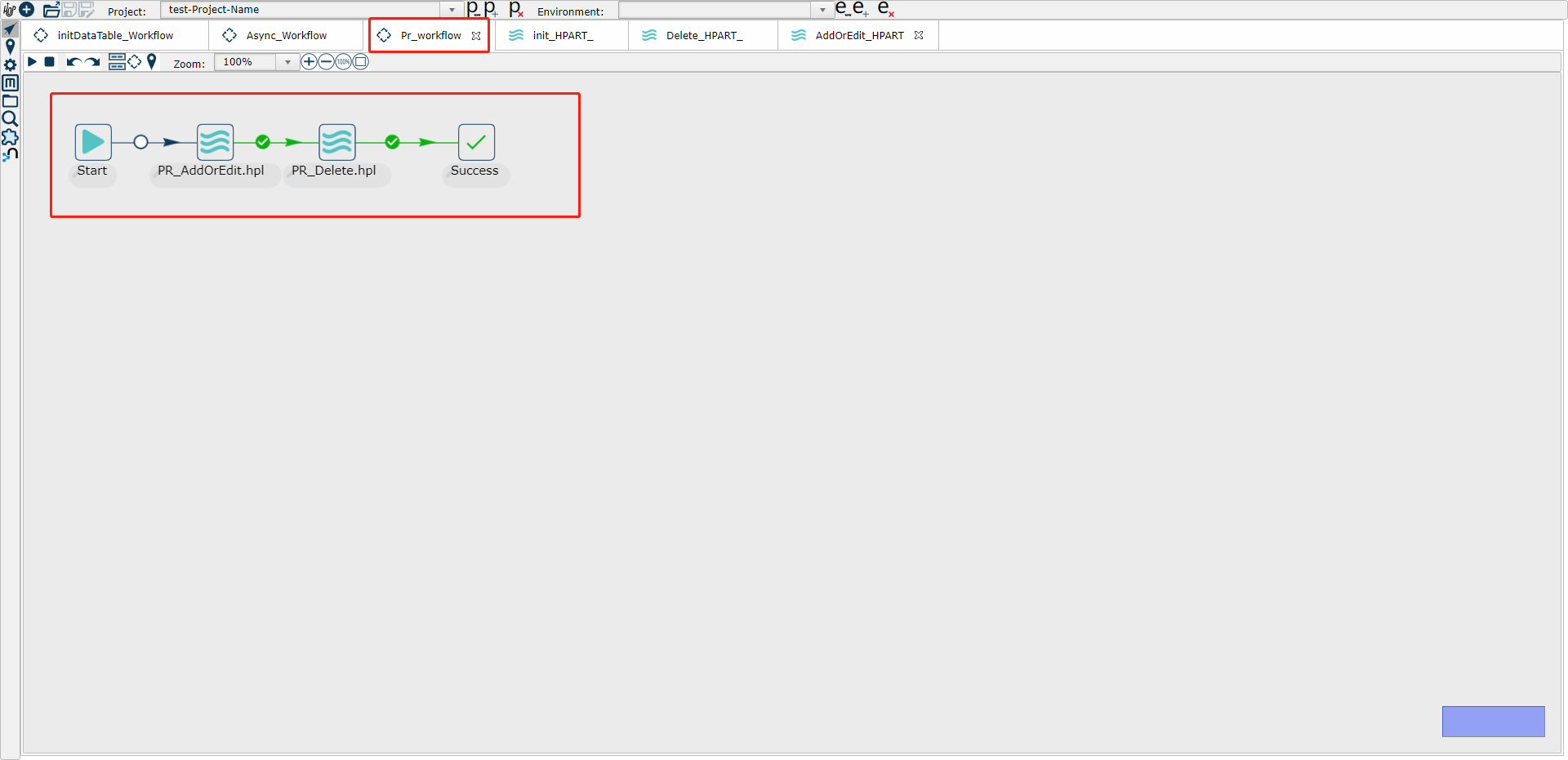
(1) Start定时执行示意图
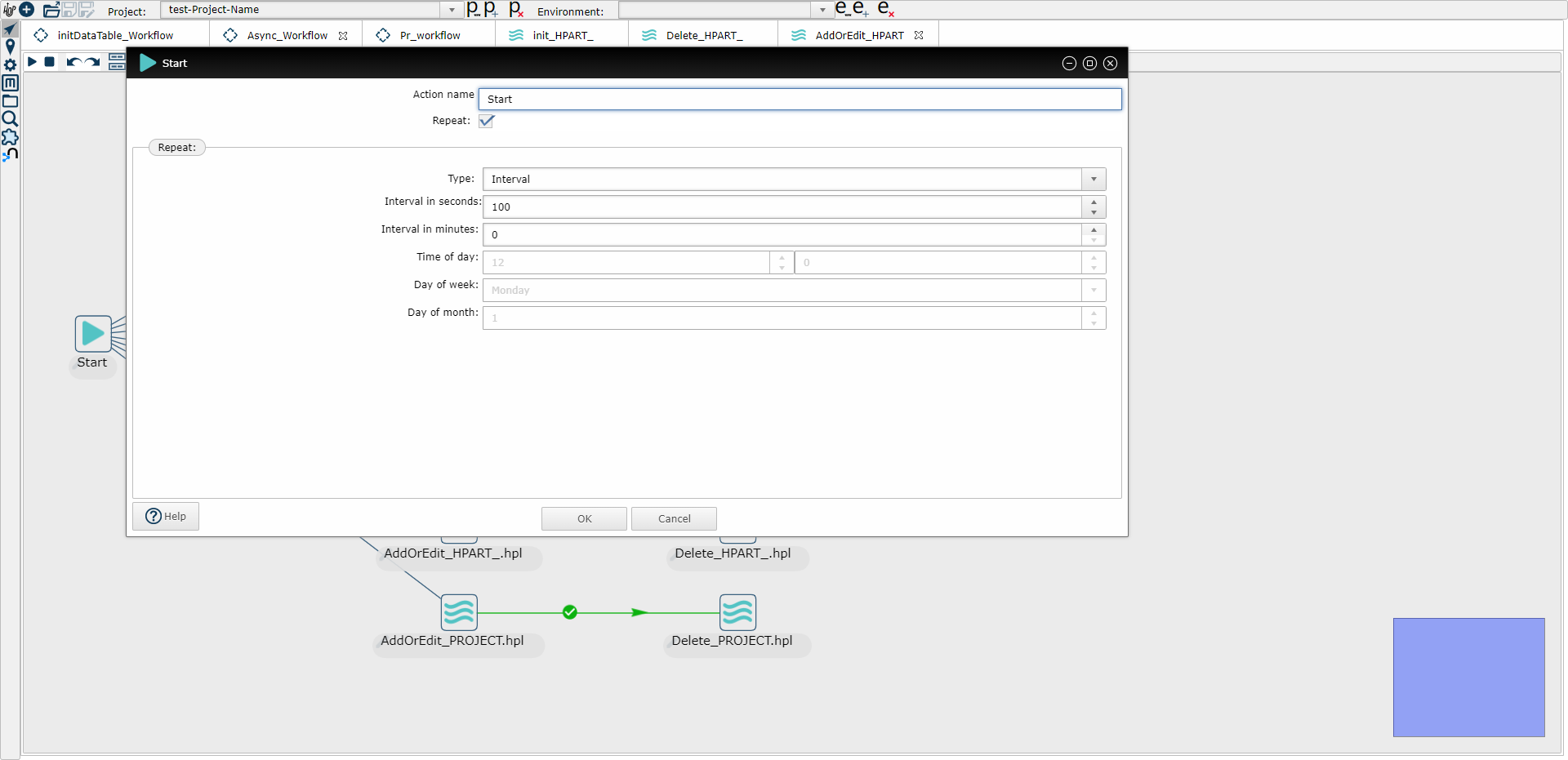
(2) 工作流并行执行各个管道任务示意图
以上是基于触发器模式增量数据同步的hop web设计、建模,下一步需要在生产环境中执行设计的工作流/管道文件
Hop Web ,Hop Gui fat client 是帮助数据工程师通过可视化方式设计数据清洗流程的。
Hop run是本地命令行,来执行设计好的数据清洗流程的。
Hop server是管理和执行本地或远程的数据清洗流程的
也可以使用Apache Airflow等非自带工具,来执行。
ETL之apache hop数据增量同步功能的更多相关文章
- 实战!Spring Boot 整合 阿里开源中间件 Canal 实现数据增量同步!
大家好,我是不才陈某~ 数据同步一直是一个令人头疼的问题.在业务量小,场景不多,数据量不大的情况下我们可能会选择在项目中直接写一些定时任务手动处理数据,例如从多个表将数据查出来,再汇总处理,再插入到相 ...
- Rsync + Sersync 实现数据增量同步
部分引用自:https://blog.csdn.net/tmchongye/article/details/68956808 一.什么是Rsync? Rsync(Remote Synchronize) ...
- kafka源码系列之mysql数据增量同步到kafka
一,架构介绍 生产中由于历史原因web后端,mysql集群,kafka集群(或者其它消息队列)会存在一下三种结构. 1,数据先入mysql集群,再入kafka 数据入mysql集群是不可更改的,如何再 ...
- 【kafka】JDBC connector进行表数据增量同步过程中的源表与目标表时间不一致问题解决
〇.参考资料 一.现象 1.Oracle源表数据 2.PG同步后的表数据 3.现象 时间不一致,差了8个小时 4.查看对应的connector信息 (1)source { "connecto ...
- 实现从Oracle增量同步数据到GreenPlum
简介: GreenPlum是一个基于PostgreSQL数据库开发的MPP架构的数据库仓库,适用于OLAP系统,支持50PB(1PB=1000TB)级海量数据的存储和处理. 背景: 目前有一个业务是需 ...
- (转)Linux系统sersync数据实时同步
Linux系统sersync数据实时同步 原文:http://blog.csdn.net/mingongge/article/details/52985259 前面介绍了以守护进程的方式传输或同步数据 ...
- Linux之sersync数据实时同步
sersync其实是利用inotify和rsync两种软件技术来实现数据实时同步功能的,inotify是用于监听sersync所在服务器上的文件变化,结合rsync软件来进行数据同步,将数据实时同步给 ...
- PG TO Oracle 增量同步-外部表
背景 最近在负责公司数据Oracle转PG:老平台数据库:Oracle11g:新平台数据库:PostgreSQL12.由于平台统计规则有变动:所以正在推广的游戏数据无法全部迁移过来:只能在老平台上运行 ...
- ETL中的数据增量抽取机制
ETL中的数据增量抽取机制 ( 增量抽取是数据仓库ETL(extraction,transformation,loading,数据的抽取.转换和装载)实施过程中需要重点考虑的问 题.在ETL过 ...
- MySQL数据实时增量同步到Kafka - Flume
转载自:https://www.cnblogs.com/yucy/p/7845105.html MySQL数据实时增量同步到Kafka - Flume 写在前面的话 需求,将MySQL里的数据实时 ...
随机推荐
- 2021-05-31:怎么判断n个数俩俩互质?比如7,8,9任意两个数最大公约数是1,所以7,8,9两两互质。比如8,9
2021-05-31:怎么判断n个数俩俩互质?比如7,8,9任意两个数最大公约数是1,所以7,8,9两两互质.比如8,9,10不是两两互质,因为8和10的最大公约数是2. 福大大 答案2021-05- ...
- ModuleNotFoundError: No module named 'pyecharts'
ModuleNotFoundError: No module named 'pyecharts' 解决: pip install pyecharts
- OpenStack云平台部署
前言:本次部署采用系统的是Centos 8-Stream版,存储库为OpenStack-Victoria版,除基础配置,五大服务中的时间同步服务,七大组件中的nova服务,neutron服务,cind ...
- jmeter如何保存变量到结果jtl文件里
将变量保存到结果jtl文件里,可以方便的在generate报告时,自行取用jtl中的变量进行展示,实现过程如下: 1.打开jmeter/bin目录下的jmeter.properties文件,将变量名加 ...
- flutter 中使用 WebView加载H5页面异常net:ERR_CLEARTEXT_NOT_PERMITTED
最近有个flutter项目中根据搜索结果跳转到相应的H5页面发现老是报错,曾现在闲暇拉出来解决哈 先来看一个搜索功能的测试 已进入详情页面就提示错误,尴尬了. 只有去检测代码了撒 Search.dar ...
- linux 条件语句和逻辑判断
目录 一.条件判断 二.逻辑判断 三.if和case 四.七个实验 一.条件判断 1.test测试 test [ 条件表达式 ] -e:测试目录是否存在 -d:测试是否为目录 -f:是否为文件 ...
- SpringIOC和SpringAOP
作为一个Spring使用者条件: 拥有深入的Spring框架知识和开发经验,能够熟练地运用Spring框架来构建复杂的应用程序. 了解Spring框架的核心概念和设计思想,如控制反转(IoC).依赖注 ...
- Spring Cloud开发实践(七): 集成Consul配置中心
目录 Spring Cloud开发实践(一): 简介和根模块 Spring Cloud开发实践(二): Eureka服务和接口定义 Spring Cloud开发实践(三): 接口实现和下游调用 Spr ...
- 数据科学工具 Jupyter Notebook 教程(二)
Jupyter Notebook 是一个把代码.图像.注释.公式和作图集于一处,实现可读性分析的交互式笔记本工具.借助所谓的内核(Kernel)的概念,Jupyter Notebook 可以同时支持包 ...
- uniapp主题切换功能的方式终结篇(全平台兼容)
前面我已经给大家介绍了两种主题切换的方式,每种方式各有自己的优势与缺点,例如"scss变量+vuex"方式兼容好但不好维护与扩展,"scss变量+require" ...