基于JuiceFS 的低成本 Elasticsearch 云上备份存储
杭州火石创造是国内专注于产业大数据的数据智能服务商,为了解决数据存储及高效服务客户需求,选择了 Elasticsearch 搜索引擎进行云上存储。基于性能和成本的考虑,在阿里云选择用本地 SSD ECS 机型自建集群。但由于是自建集群,如何同步解决数据备份问题并实现最优成本呢?
1.背景介绍
Elasticsearch 的数据备份是通过快照机制实现的。为了完成集群的快照,需要依赖一个共享存储系统,即所有节点需要挂载到共享存储的同一个目录,并且每个节点对此目录需有读写权限,最初我们使用 NAS(即 NFS)来实现备份,这个方案也已经稳定运行多年。
在此,我还是再强调一下数据备份重要性。很多小伙伴误认为 Elasticsearch 具备副本机制,只要配置多副本就不怕数据丢失,为什么还要备份呢?需要指出是:再多的副本禁不住一个 DELETE 误操作;而且副本机制也要平衡成本,是在一定程度内的冗余,超过阈值一样会造成数据丢失,备份是业务持续性重要保障,有备才能无患!
云上成本的持续优化是运维人员始终面临的挑战。Snowflake 使用 S3 存储在成本效率方面给了我们很大的触动。接触到 JuiceFS 后,我们认为这是一款非常不错的存储产品。本着循序渐进原则,备份存储是一个非常不错的切入点,于是便有了基于 JuiceFS 来构建通用低成本云上备份存储解决方案,并着手实践。
2.成本比对
本文的标题就是低成本,成本低在哪里呢,我们用数据说话,以 10T NAS 和 OSS 资源包价格对比如下表所示:
| 资源型别 | 原价(元/年) | 折扣价(元/年) |
|---|---|---|
| NAS存储-通用型 | 36,864 | 27,648 |
| OSS-标准本地冗余 | 13,272 | 9,954 |
如果使用 OSS 替代 NAS,成本降低为原来 36%,接近 1/3,降本效果可谓显著,冲这咱就必须干!
等下,其他成本呢?JuiceFS 社区版还需要元数据存储,确实,这个也是需要计算成本。但是这年头,谁家的云上没有一个共享或者辅助用 RDS,作为备份系统,对 IO 的随机读写需求不高,这里咱就共享一个 MySQL RDS 来作为元数据存储。
3.部署过程
部署过程基本参照 JuiceFS 的官方文档完成,具体分成了三个步骤:
3.1 安装
安装过程很简单,一条命令搞定。默认是在安装 /usr/local/bin 下,考虑到不是所有的操作系统都是将该目录作为 PATH 的默认路径,从更加通用和省事的角度,我建议安装到 /usr/sbin 目录下,执行安装命令:
curl -sSL https://d.juicefs.com/install | sh - /usr/sbin
注意:该命令在所有的节点都要执行(所有的节点都要安装)
3.2 创建文件系统
有两个前置步骤这里略过:
OSS 的 Bucket 及 AK 的准备这里略过,创建的 Bucket 名为:
juicefs-backup;元数据存储因为使用了 MySQL,库及账号的创建也略过,创建的库名和用户名均为:juicefs。
有个小插曲,因为元数据使用了 MySQL,官方文档快速上手及元数据引擎最佳实践两个章节找不到参考和范例,有 PostgreSQL 没有 MySQL,开始我照猫画虎参照 PostgreSQL 写法,提示语法不对,最后在参考-如何设置元数据引擎章节找到了相关说明:
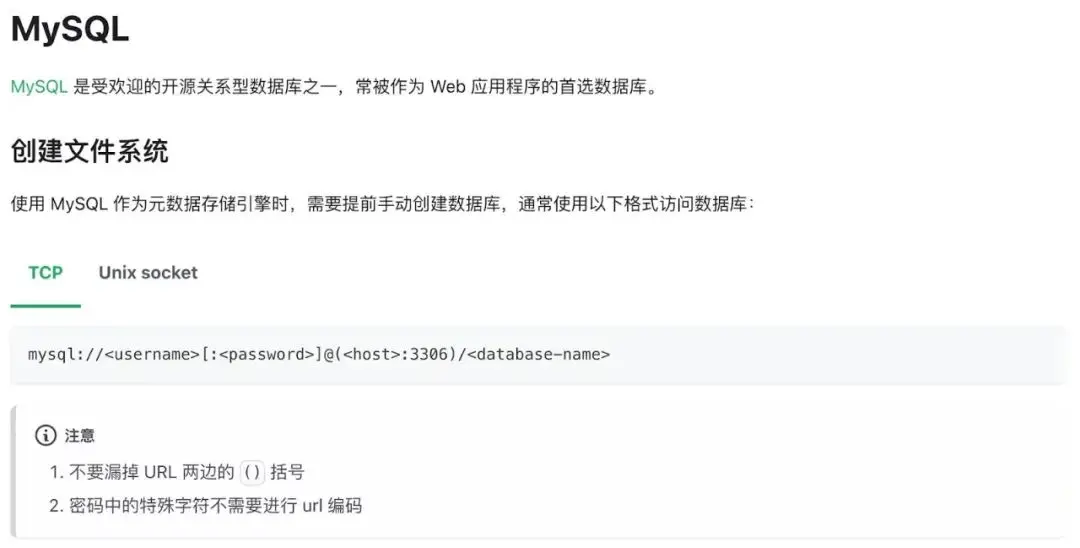
为啥要加这个括号我不是很理解,只能表示不明觉厉。不过建议官方文档元数据引擎最佳实践环节增加 MySQL 章节,这样前后可以呼应,方便读者查阅。
最终我的创建命令如下:
juicefs format \
--storage oss \
--bucket juicefs-backup.oss-cn-hangzhou-internal.aliyuncs.com \
--access-key 【KEY】 \
--secret-key 【SECRET】 \
mysql://juicefs:【PASSWORD】@(【RDS-URL】:3306)/juicefs \
elasticsearch
注意:
- 本条命令只需要在任一节点执行一次
- 【KEY】【SECRET】【PASSWORD】【RDS-URL】需要更换为实际值
3.3 挂载文件系统
挂载命令如下:
juicefs mount \
--update-fstab \
--background \
--writeback \
--cache-dir /data/juicefs-cache \
--cache-size 10240 \
-o user_id=$(id -u elasticsearch) \
mysql://juicefs:【PASSWORD】@\(【RDS-URL】:3306\)/juicefs \
/backup
挂载相关参数说明如下:
--update-fstab:更新/etc/fstab,这样节点重启后,会自动挂载。--writeback:把数据写入本地缓存后再写到 OSS,提升备份效率,作为备份用途建议开启。--cache-dir /data/juicefs-cache和--cache-size 10240:在 Elasticsearch 存储 SSD 上划出 10G 作为缓存(默认值是 100GB,考虑到成本因素,选用了 10GB),提高读写性能。-o user_id=$(id -u elasticsearch): 允许 elasticsearch 用户读写,经咨询官方工程师,这个参数不指定也可以。
注意:
- 本条命令需要在每个节点执行一次
- 【PASSWORD】【RDS-URL】需要更换为实际值
3.4 设置挂载目录权限
最后要确保挂载的目录能被 Elasticsearch 读写
chown elasticsearch:elasticsearch /backup
注意:本条命令需要在任一节点执行一次即可
3.5 注册Elasticsearch 快照仓库
首先需要在 Elasticsearch 的配置文件 elasticsearch.yaml 中配置 path.repo ,比如:
path:
repo:
- /backup
注意:每个节点都需要修改配置,修改后需要重启服务
每个节点重启后,可以通过 Kibana 或者使用 Elasticsearch Snapshot API 注册。
PUT _snapshot/es-backup
{
"type": "fs",
"settings": {
"location": "'/backup'",
"compress": "true",
"max_snapshot_bytes_per_sec": "100m",
"max_restore_bytes_per_sec": "100m"
}
}
参数说明:
es-bakup是快照仓库的名称,可自定义compress是否启用压缩,我们是启用,可以节约空间占用max_snapshot_bytes_per_sec/max_restore_bytes_per_sec最大快照及恢复的速度根据自己的情况设置,我们设定为:100M/秒
最后,具体备份实施的操作这里就不再细写,可参考Elasticsearch 官方文档。
4. 踩坑经历
完成上述准备工作后,本来满心欢喜坐等备份成功,不想却出现了新事物尝试路上必有姿势:踩坑!
在备份点创建过程中出现了个别节点的权限异常问题,这个就碰到分布式集群读写共享存储的共性问题:不同节点进程的 username 和 id 是否完全一致?解决这个问题一般有两个思路:
不动现有的环境,通过用户映射的方式来解决这个问题,毫无疑问,这当然是最佳的方式。但是我翻了好几遍官方文档,并尝试根据节点 Elasticsearch 用户不同的 id 来挂载(见3.3 挂载命令),验证结果挂载的文件系统的用户属性还是取决于实际进程;于是就想到了 NFS 文件系统有个参数叫
all_squash,即将所有的用户都映射到一个特定的用户比如 nobody 上,但是很遗憾,JiuceFS 目前只能实现 root_squash,做不到 all_squash ,此问题最后反馈了 JuiceFS 的开发人员,详见 Github 上的 PR。改变现有的环境,使所有的 Elasticsearch 用户的 id 保持一致,得益于 Elasticsearch 优秀的容灾迁移能力,最终我通过在特定节点重装了一下 Elasticserach 来解决这个问题(最后发现其实这个问题的产生源于 Elasticsearch 和 kibana 安装先后顺序)。
5.结语
通过上述步骤及措施的实施,最后 Elasticsearch 快照备份方案最终实现并持续运作,备份的效率也完全不输 NAS 存储。
本文以分布式集群备份为例,其方案完全可以用在其他各种单机系统备份中,同时借助 JuiceFS 广泛的数据存储和元数据引擎的适配性,也可以使其成为一个通用的低成本云上备份存储解决方案。
希望这篇内容能够对你有一些帮助,如果有其他疑问欢迎加入 JuiceFS 社区与大家共同交流。
基于JuiceFS 的低成本 Elasticsearch 云上备份存储的更多相关文章
- Kubernetes 降本增效标准指南 | 基于K8s 扩展机制构建云上成本控制系统
作者 王玉君,腾讯云后台高级开发工程师,负责腾讯云原生系统开发及建设. 晏子怡,腾讯云容器产品经理,在K8s弹性伸缩.资源管理领域有丰富的实战经验. 导语 Kubernetes 作为 IaaS 和 P ...
- 云上大数据存储:探究 JuiceFS 与 HDFS 的异同
HDFS 作为 Hadoop 提供存储组件,已经成为大数据生态里面数据存储最常用的选择,通常在机房环境部署. JuiceFS 是一个基于对象存储的分布式文件系统,用户可以在云上快速地搭建按需扩容的弹性 ...
- 基于ECS搭建云上博客
场景介绍 本文为您介绍如何基于ECS搭建云上博客. 背景知识 本场景主要涉及以下云产品和服务: 云服务器ECS 云服务器(Elastic Compute Service,简称ECS)是阿里云提供的性能 ...
- 基于ECS搭建云上博客(云小宝码上送祝福,免费抽iphone13任务详解)
码上送祝福,带云小宝回家 做任务免费抽iphone13,还可得阿里云新春限量手办 日期:2021.12.27-2022.1.16 云小宝地址:https://developer.aliyun.com/ ...
- 乾象投资:基于JuiceFS 构建云上量化投研平台
背景 乾象投资 Metabit Trading 成立于2018年,是一家以人工智能为核心的科技型量化投资公司.核心成员毕业于 Stanford.CMU.清北等高校.目前,管理规模已突破 30 亿元人民 ...
- 金山云:基于 JuiceFS 的 Elasticsearch 温冷热数据管理实践
01 Elasticsearch 广泛使用带来的成本问题 Elasticsearch(下文简称"ES")是一个分布式的搜索引擎,还可作为分布式数据库来使用,常用于日志处理.分析和搜 ...
- AI场景存储优化:云知声超算平台基于 JuiceFS 的存储实践
云知声是一家专注于语音及语言处理的技术公司.Atlas 超级计算平台是云知声的计算底层基础架构,为云知声在 AI 各个领域(如语音.自然语言处理.视觉等)的模型迭代提供训练加速等基础计算能力.Atla ...
- 云知声: 基于 JuiceFS 的超算平台存储实践
云知声从一家专注于语音及语言处理的技术公司,现在技术栈已经发展到具备图像.自然语言处理.信号等全栈式的 AI 能力,是国内头部人工智能独角兽企业.公司拥抱云计算,在智慧医疗.智慧酒店.智慧教育等方面都 ...
- 阿里云基于OSS的云上统一数据保护方案2.0技术解析
近年来,随着越来越多的企业从传统经济向数字经济转型,云已经渐渐成为数据经济IT新常态.核心业务系统上云,云上的业务创新,这些都产生了大量的业务数据,这些数据也成为了企业最重要的资产.资源. 阿里云基于 ...
- 阿里云基于OSS的云上统一数据保护方案2.0正式发布
近年来,随着越来越多的企业从传统经济向数字经济转型,云已经渐渐成为数据经济IT新常态.核心业务系统上云,云上的业务创新,这些都产生了大量的业务数据,这些数据也成为了企业最重要的资产.资源.阿里云基于O ...
随机推荐
- 更快的训练和推理: 对比 Habana Gaudi®2 和英伟达 A100 80GB
通过本文,你将学习如何使用 Habana Gaudi2 加速模型训练和推理,以及如何使用 Optimum Habana 训练更大的模型.然后,我们展示了几个基准测例,包括 BERT 预训练.Stabl ...
- Redis从入门到放弃(7):主从复制
1.概念 主从复制是Redis的一项重要特性,用于将一个Redis服务器(Master主节点)的数据复制到其他Redis服务器(Slave从节点),以实现数据的高可用性和读写分离.数据的复制是单向的, ...
- Python生成30万条Excel 测试数据
使用Python生成30万条Excel 测试数据 from openpyxl import Workbook from concurrent.futures import ThreadPoolExec ...
- Spark RDD惰性计算的自主优化
原创/朱季谦 RDD(弹性分布式数据集)中的数据就如final定义一般,只可读而无法修改,若要对RDD进行转换或操作,那就需要创建一个新的RDD来保存结果.故而就需要用到转换和行动的算子. Spark ...
- Unity UGUI的Slider(滑动条)件组的介绍及使用
Unity UGUI的Slider(滑动条)件组的介绍及使用 1. 什么是Slider组件? Slider(滑动条)是Unity UGUI中的一种常用UI组件用,于在用户界面中实现滑动选择的功能.通过 ...
- GPT-4 到底能帮你干点啥?
目录 1. 从哪儿聊起呢 2. 潮起潮退 3. 遇强则强,遇我则-- 3.1 玩法一:辅助技能提升 3.2 镜头背后的故事 3.3 玩法二:综合"技术选型" 3.4 镜头背后的故事 ...
- LeetCode155:最小栈,最简单的中等难度题,时间击败100%,内存也低于官方
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 最近运气不错,在LeetCode上白捡一道送 ...
- 微信Native支付(扫码支付)商户配置
0.需要从商户平台获取/设置的配置 公众号appId 商户号 APIv3密钥 证书序列号 证书密钥 1.扫码登录商户平台 网址:https://pay.weixin.qq.com/ 2.确认已开通Na ...
- Solution -「洛谷 P2044」「NOI 2012」随机数生成器
Description Link. 给你一个递推式,让你求某一项的值模上 \(g\). Solution 这道题正解是矩阵.我这里给出一种分治的做法. 题目中说 $\ \ \ \ \ \ \ $ $\ ...
- 记一次 .NET某新能源MES系统 非托管泄露
一:背景 1. 讲故事 前些天有位朋友找到我,说他们的程序有内存泄露,跟着我的错题集也没找出是什么原因,刚好手头上有一个 7G+ 的 dump,让我帮忙看下是怎么回事,既然找到我了那就给他看看吧,不过 ...