GIT:斯坦福大学提出应对复杂变换的不变性提升方法 | ICLR 2022
论文对长尾数据集中的复杂变换不变性进行了研究,发现不变性在很大程度上取决于类别的图片数量,实际上分类器并不能将从大类中学习到的不变性转移到小类中。为此,论文提出了GIT生成模型,从数据集中学习到类无关的复杂变换,从而在训练时对小类进行有效增强,整体效果不错
来源:晓飞的算法工程笔记 公众号
论文: Do Deep Networks Transfer Invariances Across Classes?

- 论文地址:https://arxiv.org/abs/2203.09739
- 论文代码:https://github.com/AllanYangZhou/generative-invariance-transfer
Introduction
优秀的泛化能力需要模型具备忽略不相关细节的能力,比如分类器应该对图像的目标是猫还是狗进行响应,而不是背景或光照条件。换句话说,泛化能力需要包含对复杂但不影响预测结果的变换的不变性。在给定足够多的不同图片的情况下,比如训练数据集包含在大量不同背景下的猫和狗的图像,深度神经网络的确可以学习到不变性。但如果狗类的所有训练图片都是草地背景,那分类器很可能会误判房子背景中的狗为猫,这种情况往往就是不平衡数据集存在的问题。
类不平衡在实践中很常见,许多现实世界的数据集遵循长尾分布,除几个头部类有很多图片外,而其余的每个尾部类都有很少的图片。因此,即使长尾数据集中图片总量很大,分类器也可能难以学习尾部类的不变性。虽然常用的数据增强可以通过增加尾部类中的图片数量和多样性来解决这个问题,但这种策略并不能用于模仿复杂变换,如更换图片背景。需要注意的是,像照明变化之类的许多复杂变换是类别无关的,能够类似地应用于任何类别的图片。理想情况下,经过训练的模型应该能够自动将这些不变性转为类无关的不变性,兼容尾部类的预测。
论文通过实验观察分类器跨类迁移学习到的不变性的能力,从结果中发现即使经过过采样等平衡策略后,神经网络在不同类别之间传递学习到的不变性也很差。例如,在一个长尾数据集上,每个图片都是随机均匀旋转的,分类器往往对来自头部类的图片保持旋转不变,而对来自尾部类的图片则不保持旋转不变。
为此,论文提出了一种更有效地跨类传递不变性的简单方法。首先训练一个input conditioned但与类无关的生成模型,该模型用于捕获数据集的复杂变换,隐藏了类信息以便鼓励类之间的变换转移。然后使用这个生成模型来转换训练输入,类似于学习数据增强来训练分类器。论文通过实验证明,由于尾部类的不变性得到显著提升,整体分类器对复杂变换更具不变性,从而有更好的测试准确率。
Measuring Invariance Transfer In Class-Imbalanced Datasets
论文先对不平衡场景中的不变性进行介绍,随后定义一个用于度量不变性的指标,最后再分析不变性与类别大小之间的关系。
Setup:Classification,Imbalance,and Invariances
定义输入\((x,y)\),标签\(y\)属于\(\{1,\cdots,C\}\),\(C\)为类别数。定义训练后的模型的权值\(w\),用于预测条件概率\(\tilde{P}_w(y=j|x)\),分类器将选择概率最大的类别\(j\)作为输出。给定训练集\(\{(x^{(i)}, y^{(i)})\}^N_{i=1}\sim \mathbb{P}_{train}\),通过经验风险最小化(ERM)来最小化训练样本的平均损失。但在不平衡场景下,由于\(\{y^{(i)}\}\)的分布不是均匀的,导致ERM在少数类别上表现不佳。
在现实场景中,最理想的是模型在所有类别上都表现得不错。为此,论文采用类别平衡的指标来评价分类器,相当于测试分布\(\mathbb{P}_{test}\)在\(y\)上是均匀的。
为了分析不变性,论文假设\(x\)的复杂变换分布为\(T(\cdot|x)\)。对于不影响标签的复杂变换,论文希望分类器是不变的,即预测的概率不会改变:

Measuring Learned Invariacnes
为了度量分类器学习不变性的程度,论文定义了原输入和变换输入之间的期望KL散度(eKLD):

这是一个非负数,eKLD越低代表不变性程度就越高,对\(T\)完全不变的分类器的eKLD为0。如果有办法采样\(x^{'}\sim T(\cdot|x)\),就能计算训练后的分类器的eKLD。此外,为了研究不变性与类图片数量的关系,可以通过分别计算类特定的eKLD进行分析,即将公式2的\(x\)限定为类别\(j\)所属。
计算eKLD的难点在于复杂变化分布\(T\)的获取。对于大多数现实世界的数据集而言,其复杂变化分布是不可知的。为此,论文通过选定复杂分布来生成数据集,如RotMNIST数据集。与数据增强不同,这种生成方式是通过变换对数据集进行扩充,而不是在训练过程对同一图片应用多个随机采样的变换。
论文以Kuzushiji-49作为基础,用三种不同的复杂变换生成了三个不同的数据集:图片旋转(K49-ROT-LT)、不同背景强度(K49-BG-LT)和图像膨胀或侵蚀(K49-DIL-LT)。为了使数据集具有长尾分布(LT),先从大到小随机选择类别,然后有选择地减少类别的图片数直到数量分布符合参数为2.0的Zipf定律,同时强制最少的类为5张图片。重复以上操作30次,构造30个不同的长尾数据集。每个长尾数据集有7864张图片,最多的类有4828张图片,最小的类有5张图片,而测试集则保持原先的不变。
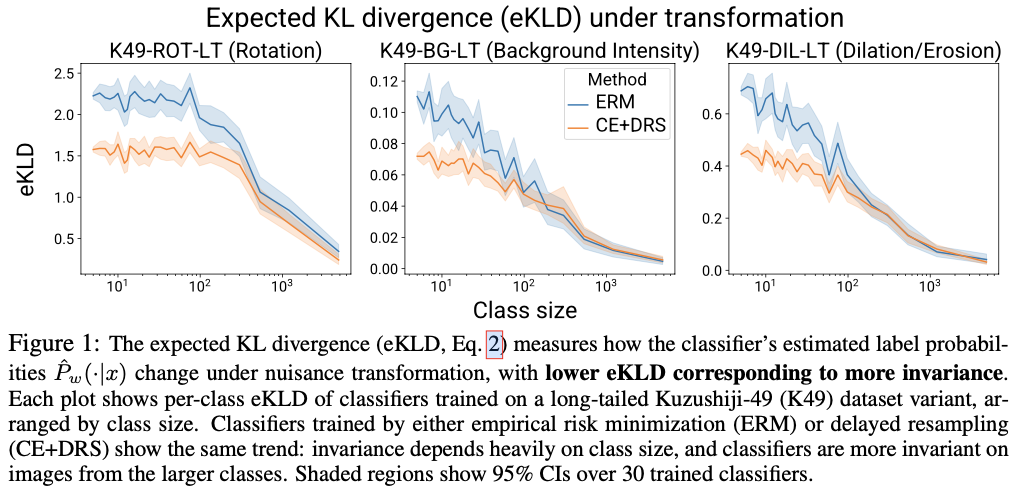
训练方面,采用标准ERM和CE+DRS两种方法,其中CE+DRS基于交叉熵损失进行延迟的类平衡重采样。DRS在开始阶段跟ERM一样随机采样,随后再切换为类平衡采样进行训练。论文为每个训练集进行两种分类器的训练,随后计算每个分类器每个类别的eKLD指标。结果如图1所示,可以看到两个现象:
- 在不同变化数据集上,不变性随着类图片数减少都降低了。这表明虽然复杂变换是类无关的,但在不平衡数据集上,模型无法在类之间传递学习到的不变性。
- 对于图片数量相同的类,使用CE+DRS训练的分类器往往会有较低的eKLD,即更好的不变性。但从曲线上看,DRS仍有较大的提升空间,还没达到类别之间一致的不变性。
Trasnferring Invariances with Generative Models
从前面的分析可以看到,长尾数据集的尾部类对复杂变换的不变性较差。下面将介绍如何通过生成式不变性变换(GIT)来显式学习数据集中的复杂变换分布\(T(\cdot|x)\),进而在类间转移不变性。
Learning Nuisance Transformations from Data
如果有数据集实际相关的复杂变换的方法,可以直接将其用作数据增强来加强所有类的不变性,但在实践中很少出现这种情况。于是论文提出GIT,通过训练input conditioned的生成模型\(\tilde{T}(\cdot|x)\)来近似真实的复杂变换分布\(T(\cdot|x)\)。

论文参考了多模态图像转换模型MUNIT来构造生成模型,该类模型能够从数据中学习到多种复杂变换,然后对输入进行变换生成不同的输出。论文对MUNIT进行了少量修改,使其能够学习单数据集图片之间的变换,而不是两个不同域数据集之间的变换。从图2的生成结果来看,生成模型能够很好地捕捉数据集中的复杂变换,即使是尾部类也有不错的效果。需要注意的是,MUNIT是非必须的,也可以尝试其它可能更好的方法。
在训练好生成模型后,使用GIT作为真实复杂变换的代理来为分类器进行数据增强,希望能够提高尾部类对复杂变换的不变性。给定训练输入\(\{(x^{(i)}, y^{(i)})\}^{|B|}_{i=1}\),变换输入\(\tilde{x}^{(i)}\gets \tilde{T}(\cdot|x^{(i)})\),保持标签不变。这样的变换能够提高分类器在训练期间的输入多样性,特别是对于尾部类。需要注意的是,batch可以搭配任意的采样方法(Batch Sampler),比如类平衡采样器。此外,还可以有选择地进行增强,避免由于生成模型的缺陷损害性能的可能性,比如对数量足够且不变性已经很好的头部类不进行增强。

在训练中,论文设置阈值\(K\),仅图片数量少于\(K\)的类进行数据增强。此外,仅对每个batch的\(p\)比例进行增强。\(p\)一般取0.5,而\(K\)根据数据集可以设为20-500,整体逻辑如算法1所示。
GIT Improves Invariance on Smaller Classes

论文基于算法1进行了实验,将Batch Sampler设为延迟重采样(DRS),Update Classifier使用交叉熵梯度更新,整体模型标记为\(CE+DRS+GIT(all classes)\)。all classes表示禁用阈值\(K\),仅对K49数据集使用。作为对比,Oracle则是用于构造生成数据集的真实变换。从图3的对比结果可以看到,GIT能够有效地增强尾部类的不变性,但同时也损害了图片充裕的头部类的不变性,这表明了阈值\(K\)的必要性。
Experiment
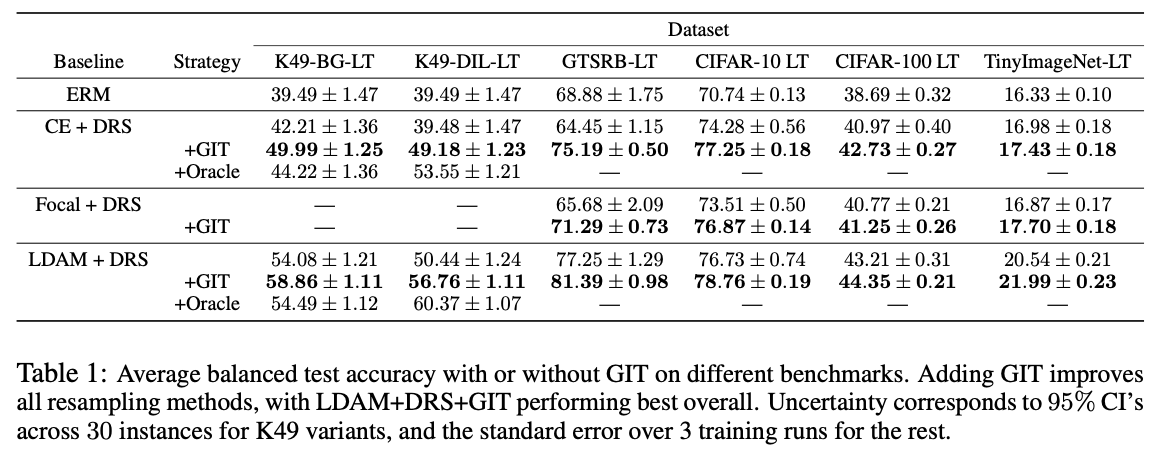
不同训练策略搭配GIT的效果对比。

在GTSRB和CIFAR数据集上的变换输出。

CIFAR-10上每个类的准确率。

对比实验,包括阈值\(K\)对性能的影响,GTSRB-LT, CIFAR-10 LT和CIFAR-100 LT分别取25、500和100。这里的最好性能貌似都比RandAugment差点,有可能是因为论文还没对实验进行调参,而是直接复用了RandAugment的实验参数。这里比较好奇的是,如果在训练生成模型的时候加上RandAugment,说不定性能会更好。
Conclusion
论文对长尾数据集中的复杂变换不变性进行了研究,发现不变性在很大程度上取决于类别的图片数量,实际上分类器并不能将从大类中学习到的不变性转移到小类中。为此,论文提出了GIT生成模型,从数据集中学习到类无关的复杂变换,从而在训练时对小类进行有效增强,整体效果不错。
如果本文对你有帮助,复杂点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

GIT:斯坦福大学提出应对复杂变换的不变性提升方法 | ICLR 2022的更多相关文章
- Deep Learning 9_深度学习UFLDL教程:linear decoder_exercise(斯坦福大学深度学习教程)
前言 实验内容:Exercise:Learning color features with Sparse Autoencoders.即:利用线性解码器,从100000张8*8的RGB图像块中提取颜色特 ...
- Deep Learning 8_深度学习UFLDL教程:Stacked Autocoders and Implement deep networks for digit classification_Exercise(斯坦福大学深度学习教程)
前言 1.理论知识:UFLDL教程.Deep learning:十六(deep networks) 2.实验环境:win7, matlab2015b,16G内存,2T硬盘 3.实验内容:Exercis ...
- 斯坦福大学Andrew Ng教授主讲的《机器学习》公开课观后感[转]
近日,在网易公开课视频网站上看完了<机器学习>课程视频,现做个学后感,也叫观后感吧. 学习时间 从2013年7月26日星期五开始,在网易公开课视频网站上,观看由斯坦福大学Andrew Ng ...
- 斯坦福大学自然语言处理第四课“语言模型(Language Modeling)”
http://52opencourse.com/111/斯坦福大学自然语言处理第四课-语言模型(language-modeling) 一.课程介绍 斯坦福大学于2012年3月在Coursera启动了在 ...
- 斯坦福大学机器学习,EM算法求解高斯混合模型
斯坦福大学机器学习,EM算法求解高斯混合模型.一种高斯混合模型算法的改进方法---将聚类算法与传统高斯混合模型结合起来的建模方法, 并同时提出的运用距离加权的矢量量化方法获取初始值,并采用衡量相似度的 ...
- 院校-国外-美国:斯坦福大学( Stanford)
ylbtech-院校-国外-美国:斯坦福大学( Stanford) 斯坦福大学(Stanford University),全名小利兰·斯坦福大学(Leland Stanford Junior Univ ...
- CS229 斯坦福大学机器学习复习材料(数学基础) - 线性代数
CS229 斯坦福大学机器学习复习材料(数学基础) - 线性代数 线性代数回顾与参考 1 基本概念和符号 1.1 基本符号 2 矩阵乘法 2.1 向量-向量乘法 2.2 矩阵-向量乘法 2.3 矩阵- ...
- Deep Learning 19_深度学习UFLDL教程:Convolutional Neural Network_Exercise(斯坦福大学深度学习教程)
理论知识:Optimization: Stochastic Gradient Descent和Convolutional Neural Network CNN卷积神经网络推导和实现.Deep lear ...
- Deep Learning 13_深度学习UFLDL教程:Independent Component Analysis_Exercise(斯坦福大学深度学习教程)
前言 理论知识:UFLDL教程.Deep learning:三十三(ICA模型).Deep learning:三十九(ICA模型练习) 实验环境:win7, matlab2015b,16G内存,2T机 ...
- Deep Learning 12_深度学习UFLDL教程:Sparse Coding_exercise(斯坦福大学深度学习教程)
前言 理论知识:UFLDL教程.Deep learning:二十六(Sparse coding简单理解).Deep learning:二十七(Sparse coding中关于矩阵的范数求导).Deep ...
随机推荐
- mantis如何更改用户密码
从MantisBT版本开始,创建用户后,必须由用户通过确认邮件进行修改密码,而管理员无权对用户的密码进行修改.这对于配置mail不成功的情况下很不方便. 以下配置就可以让管理员轻松管理用户的密 ...
- java怎么打印一个对象的内存地址
在Java一般使用HashCode来代表对象的地址,但是两个相同的对象就不行了,两个相同的对象的hashcode是相同的. 如果要对比两个相同的对象的地址可以使用,System.identityHas ...
- Java JVM——6.本地方法接口
本地方法接口 什么是本地方法? 简单地讲,一个 Native Method 就是一个Java调用非Java代码的接囗.一个 Native Method 是这样一个Java方法:该方法的实现由非Java ...
- 【Docker】.Net Core 结合Nlog集成ELK框架(Elasticsearch , Logstash, Kibana) (五)
之前有项目有用过ELK做过日志架构,不过是非docker形式安装的,今天来探究一下ELK的容器化技术 Elasticsearch 是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动 ...
- MIG是如何向DDR中写入数据的
1.1 先来看看信号线的描述 我们以X16的器件为例,下面的截图来自 镁光的官方手册 https://media-www.micron.com/-/media/client/global/doc ...
- macOS Monterey 与以下电脑兼容下载操作流程解析
有时在开发iOS应用时我们时常遇到各种情况,比如手机升级了Xcode不支持这时候需要安装xcode但是xcode需要依奈相应系统本人小编整理了这种情况无法解决问题. 首相打开苹果标志进入到下面界面 进 ...
- 适配http分发Directory.Build.props文件,需要替换默认的微软sdk:8.0映像
背景 我们是把Directory.Build.props及其Import的文件,都放在http://dev.amihome.cn 那么docker build的时候,也是需要下载Directory.B ...
- 【Azure Webjob + Redis】WebJob一直链接Azure Redis一直报错 Timeout Exception
问题描述 运行在App Service上的Webjob连接Azure Redis出现Timeout Exception. 错误截图: 参考Azure Redis对于超时问题的排查建议, 在修改Min ...
- 【Azure Service Fabric】关于Service Fabric的相关问题
问题一:Service Fabric 是否支持Private Link? 在Azure Private Endpoint文档中,罗列出了 Azure 上支持 Private Link 的服务.Serv ...
- UI自动化测试中图片验证码的处理?
首先定位验证码image的元素,然后通过element.screenshot('a.png')截图保存到本地,通过第三方接口识别本地图片验证码