数据挖掘机器学习[二]---汽车交易价格预测详细版本{EDA-数据探索性分析}
题目出自阿里天池赛题链接:零基础入门数据挖掘 - 二手车交易价格预测-天池大赛-阿里云天池
相关文章:
数据挖掘机器学习---汽车交易价格预测详细版本[二]{EDA-数据探索性分析}
数据挖掘机器学习---汽车交易价格预测详细版本[三]{特征工程、交叉检验、绘制学习率曲线与验证曲线}
数据挖掘机器学习---汽车交易价格预测详细版本[四]{嵌入式特征选择(XGBoots,LightGBM),模型调参(贪心、网格、贝叶斯调参)}
数据挖掘机器学习---汽车交易价格预测详细版本[五]{模型融合(Stacking、Blending、Bagging和Boosting)}
数据挖掘机器学习[七]---2021研究生数学建模B题空气质量预报二次建模求解过程
前言
因为文档是去年弄的,很多资料都有点找不到了,我尽可能写的详细。后面以2021年研究生数学建模B题为例【空气质量预报二次建模】再进行一个教学。
1.题目讲解
数据来自 Ebay Kleinanzeigen 报废的二手车,数量超过 370,000,包含 20 列变量信息,为了保证 比赛的公平性,将会从中抽取 10 万条作为训练集,5 万条作为测试集 A,5 万条作为测试集 B。同时会对名称、车辆类型、变速箱、model、燃油类型、品牌、公里数、价格等信息进行脱敏。
一般而言,对于数据在比赛界面都有对应的数据概况介绍(匿名特征除外),说明列的性质特征。了解列的性质会有助于我们对于数据的理解和后续分析。 Tip:匿名特征,就是未告知数据列所属的性质的特征列。
train.csv
- name - 汽车编码
- regDate - 汽车注册时间
- model - 车型编码
- brand - 品牌
- bodyType - 车身类型
- fuelType - 燃油类型
- gearbox - 变速箱
- power - 汽车功率
- kilometer - 汽车行驶公里
- notRepairedDamage - 汽车有尚未修复的损坏
- regionCode - 看车地区编码
- seller - 销售方
- offerType - 报价类型
- creatDate - 广告发布时间
- price - 汽车价格
- v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13','v_14'(根据汽车的评论、标签等大量信息得到的embedding向量)【人工构造 匿名特征】
数字全都脱敏处理,都为label encoding形式,即数字形式
1.1 预测指标
一般问题评价指标说明:
什么是评估指标:
评估指标即是我们对于一个模型效果的数值型量化。(有点类似与对于一个商品评价打分,而这是针对于模型效果和理想效果之间的一个打分)
一般来说分类和回归问题的评价指标有如下一些形式:
分类算法常见的评估指标如下:
- 对于二类分类器/分类算法,评价指标主要有accuracy, [Precision,Recall,F-score,Pr曲线],ROC-AUC曲线。
- 对于多类分类器/分类算法,评价指标主要有accuracy, [宏平均和微平均,F-score]。
对于回归预测类常见的评估指标如下:
- 平均绝对误差(Mean Absolute Error,MAE),均方误差(Mean Squared Error,MSE),平均绝对百分误差(Mean Absolute Percentage Error,MAPE),均方根误差(Root Mean Squared Error), R2(R-Square)
平均绝对误差 平均绝对误差(Mean Absolute Error,MAE):平均绝对误差,其能更好地反映预测值与真实值误差的实际情况,其计算公式如下:

分析赛题
- 此题为传统的数据挖掘问题,通过数据科学以及机器学习深度学习的办法来进行建模得到结果。
- 此题是一个典型的回归问题。
- 主要应用xgb、lgb、catboost,以及pandas、numpy、matplotlib、seabon、sklearn、keras等等数据挖掘常用库或者框架来进行数据挖掘任务。
- 通过EDA来挖掘数据的联系和自我熟悉数据。
2.EDA-数据探索性分析
- 载入各种数据科学以及可视化库:
- 数据科学库 pandas、numpy、scipy;
- 可视化库 matplotlib、seabon;
- 其他;
- 载入数据:
- 载入训练集和测试集;
- 简略观察数据(head()+shape);
- 数据总览:
- 通过describe()来熟悉数据的相关统计量
- 通过info()来熟悉数据类型
- 判断数据缺失和异常
- 查看每列的存在nan情况
- 异常值检测
- 了解预测值的分布
- 总体分布概况(无界约翰逊分布等)
- 查看skewness and kurtosis
- 查看预测值的具体频数
- 特征分为类别特征和数字特征,并对类别特征查看unique分布
- 数字特征分析
- 相关性分析
- 查看几个特征得 偏度和峰值
- 每个数字特征得分布可视化
- 数字特征相互之间的关系可视化
- 多变量互相回归关系可视化
- 类型特征分析
- unique分布
- 类别特征箱形图可视化
- 类别特征的小提琴图可视化
- 类别特征的柱形图可视化类别
- 特征的每个类别频数可视化(count_plot)
在jupyter notenook下运行!!!!
#安装相应库
pip install missingno -i https://pypi.tuna.tsinghua.edu.cn/simple
.....#coding:utf-8
#导入warnings包,利用过滤器来实现忽略警告语句。
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno2.1 导入数据
path = './data/'
## 1) 载入训练集和测试集;
Train_data = pd.read_csv(path+'train.csv', sep=' ')
Test_data = pd.read_csv(path+'testA.csv', sep=' ')## 2) 简略观察数据(head()+shape)
Train_data.head().append(Train_data.tail())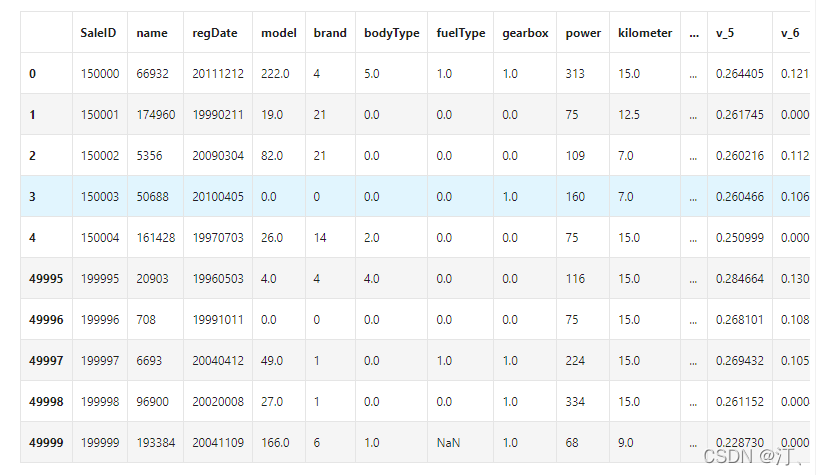
Train_data.shape
(150000, 31)
Test_data.head().append(Test_data.tail())要养成看数据集的head()以及shape的习惯,这会让你每一步更放心,导致接下里的连串的错误, 如果对自己的pandas等操作不放心,建议执行一步看一下,这样会有效的方便你进行理解函数并进行操作。
2.2总览数据概况
- describe种有每列的统计量,个数count、平均值mean、方差std、最小值min、中位数25% 50% 75% 、以及最大值 看这个信息主要是瞬间掌握数据的大概的范围以及每个值的异常值的判断,比如有的时候会发现999 9999 -1 等值这些其实都是nan的另外一种表达方式,有的时候需要注意下
- info 通过info来了解数据每列的type,有助于了解是否存在除了nan以外的特殊符号异常
## 1) 通过describe()来熟悉数据的相关统计量
Train_data.describe()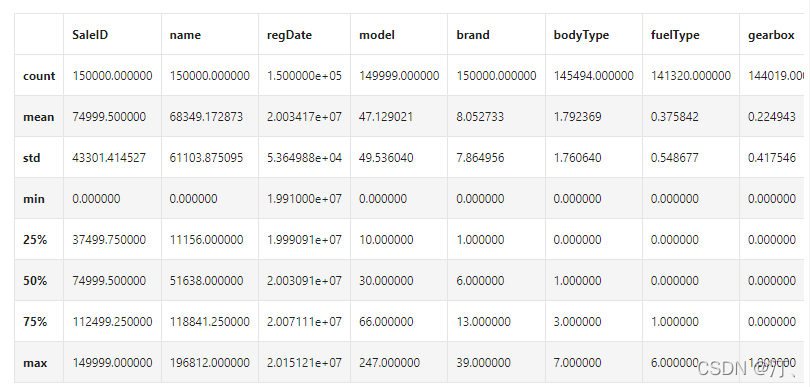
## 2) 通过info()来熟悉数据类型
Train_data.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150000 entries, 0 to 149999
Data columns (total 31 columns):
SaleID 150000 non-null int64
name 150000 non-null int64
regDate 150000 non-null int64
model 149999 non-null float64
brand 150000 non-null int64
bodyType 145494 non-null float64
fuelType 141320 non-null float64
gearbox 144019 non-null float64
power 150000 non-null int64
kilometer 150000 non-null float64
notRepairedDamage 150000 non-null object2.3 判断数据缺失和异常
## 1) 查看每列的存在nan情况
Train_data.isnull().sum()SaleID 0
,name 0
,regDate 0
,model 1
,brand 0
,bodyType 4506
,fuelType 8680
,gearbox 5981
,power 0
,kilometer 0
,notRepairedDamage 0
,regionCode 0
,seller 0
,offerType 0
,creatDate 0
,price 0
,v_0 0
,v_1 0
,v_2 0
,v_3 0
,v_4 0
,v_5 0
,v_6 0
,v_7 0
,v_8 0
,v_9 0
,v_10 0
,v_11 0
,v_12 0
,v_13 0
,v_14 0
,dtype: int64# nan可视化
missing = Train_data.isnull().sum()
missing = missing[missing > 0]
missing.sort_values(inplace=True)
missing.plot.bar()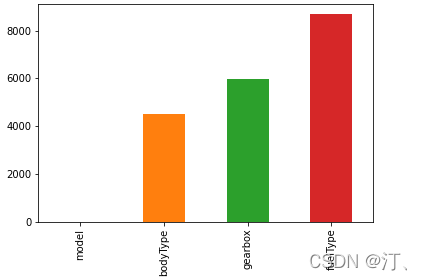
通过以上两句可以很直观的了解哪些列存在 “nan”, 并可以把nan的个数打印,主要的目的在于 nan存在的个数是否真的很大,如果很小一般选择填充,如果使用lgb等树模型可以直接空缺,让树自己去优化,但如果nan存在的过多、可以考虑删掉
# 可视化看下缺省值
msno.matrix(Train_data.sample(250))
msno.bar(Train_data.sample(1000))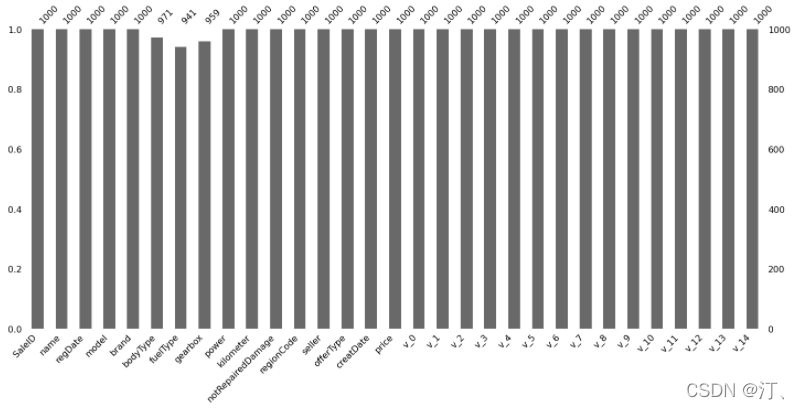
## 2) 查看异常值检测
Train_data.info()
regDate 150000 non-null int64
model 149999 non-null float64
brand 150000 non-null int64
bodyType 145494 non-null float64
fuelType 141320 non-null float64
gearbox 144019 non-null float64
power 150000 non-null int64
kilometer 150000 non-null float64
notRepairedDamage 150000 non-null object
可以发现除了notRepairedDamage 为object类型其他都为数字 这里我们把他的几个不同的值都进行显示就知道了Train_data['notRepairedDamage'].value_counts()
0.0 111361
,- 24324
,1.0 14315
,Name: notRepairedDamage, dtype: int64
可以看出来‘ - ’也为空缺值,因为很多模型对nan有直接的处理,这里我们先不做处理,先替换成nan
Train_data['notRepairedDamage'].replace('-', np.nan, inplace=True)
Train_data['notRepairedDamage'].value_counts()
0.0 111361
,1.0 14315
,Name: notRepairedDamage, dtype: int64
Train_data.isnull().sum()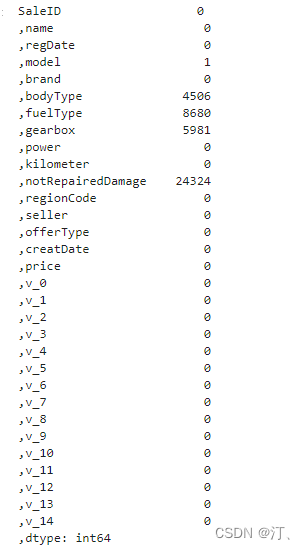
以下两个类别特征严重倾斜,一般不会对预测有什么帮助,故这边先删掉,当然你也可以继续挖掘,但是一般意义不大
Train_data["seller"].value_counts()
0 149999
,1 1
,Name: seller, dtype: int64
Train_data["offerType"].value_counts()
0 150000
,Name: offerType, dtype: int64
del Train_data["seller"]
del Train_data["offerType"]2.4 了解预测值的分布【约翰逊分布、峰度偏度】
## 1) 总体分布概况(无界约翰逊分布等)
import scipy.stats as st
y = Train_data['price']
plt.figure(1); plt.title('Johnson SU')
sns.distplot(y, kde=False, fit=st.johnsonsu)
plt.figure(2); plt.title('Normal')
sns.distplot(y, kde=False, fit=st.norm)
plt.figure(3); plt.title('Log Normal')
sns.distplot(y, kde=False, fit=st.lognorm)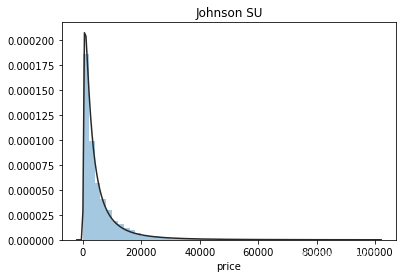
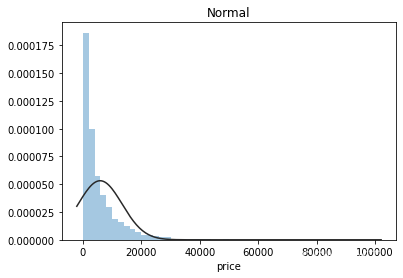
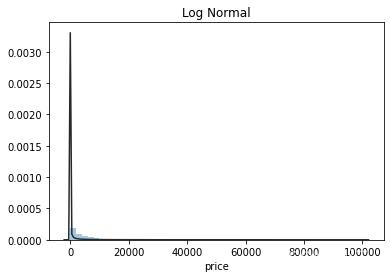
价格不服从正态分布,所以在进行回归之前,它必须进行转换。虽然对数变换做得很好,但最佳拟合是无界约翰逊分布
## 2) 查看skewness and kurtosis
sns.distplot(Train_data['price']);
print("Skewness: %f" % Train_data['price'].skew())
print("Kurtosis: %f" % Train_data['price'].kurt())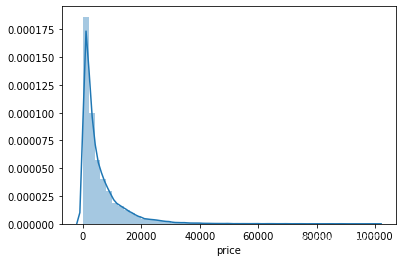
Train_data.skew(), Train_data.kurt()
sns.distplot(Train_data.skew(),color='blue',axlabel ='Skewness')
sns.distplot(Train_data.kurt(),color='orange',axlabel ='Kurtness')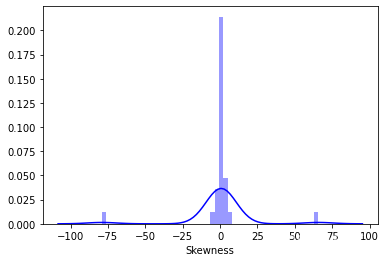
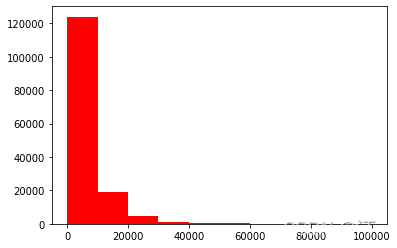
## 3) 查看预测值的具体频数
plt.hist(Train_data['price'], orientation = 'vertical',histtype = 'bar', color ='red')
plt.show()查看频数, 大于20000得值极少,其实这里也可以把这些当作特殊得值(异常值)直接用填充或者删掉,再前面进行
# log变换 z之后的分布较均匀,可以进行log变换进行预测,这也是预测问题常用的trick
plt.hist(np.log(Train_data['price']), orientation = 'vertical',histtype = 'bar', color ='red')
plt.show()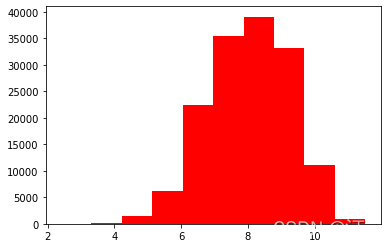
2.5 特征分为类别特征和数字特征,并对类别特征查看unique分布
# 分离label即预测值
Y_train = Train_data['price']
# 这个区别方式适用于没有直接label coding的数据
# 这里不适用,需要人为根据实际含义来区分
# 数字特征
# numeric_features = Train_data.select_dtypes(include=[np.number])
# numeric_features.columns
# # 类型特征
# categorical_features = Train_data.select_dtypes(include=[np.object])
# categorical_features.columns
numeric_features = ['power', 'kilometer', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13','v_14' ]
categorical_features = ['name', 'model', 'brand', 'bodyType', 'fuelType', 'gearbox', 'notRepairedDamage', 'regionCode',]
# 特征nunique分布
for cat_fea in categorical_features:
print(cat_fea + "的特征分布如下:")
print("{}特征有个{}不同的值".format(cat_fea, Train_data[cat_fea].nunique()))
print(Train_data[cat_fea].value_counts())数字特征分析
numeric_features.append('price')
numeric_features
Train_data.head()
['power',
, 'kilometer',
, 'v_0',
, 'v_1',
, 'v_2',
, 'v_3',
, 'v_4',
, 'v_5',
, 'v_6',
, 'v_7',
, 'v_8',
, 'v_9',
, 'v_10',
, 'v_11',
, 'v_12',
, 'v_13',
, 'v_14',
, 'price']
2.5.1 相关性分析【热力图】
## 1) 相关性分析
price_numeric = Train_data[numeric_features]
correlation = price_numeric.corr()
print(correlation['price'].sort_values(ascending = False),'\n')
f , ax = plt.subplots(figsize = (7, 7))
plt.title('Correlation of Numeric Features with Price',y=1,size=16)
sns.heatmap(correlation,square = True, vmax=0.8)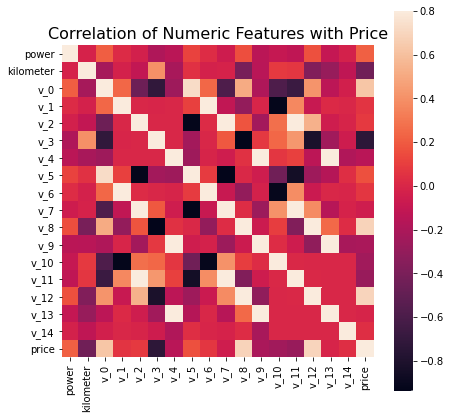
2.5.2 偏度和峰值
del price_numeric['price']
## 2) 查看几个特征得 偏度和峰值
for col in numeric_features:
print('{:15}'.format(col),
'Skewness: {:05.2f}'.format(Train_data[col].skew()) ,
' ' ,
'Kurtosis: {:06.2f}'.format(Train_data[col].kurt())
)
power Skewness: 65.86 Kurtosis: 5733.45
kilometer Skewness: -1.53 Kurtosis: 001.14
v_0 Skewness: -1.32 Kurtosis: 003.99
v_1 Skewness: 00.36 Kurtosis: -01.75
v_2 Skewness: 04.84 Kurtosis: 023.86
v_3 Skewness: 00.11 Kurtosis: -00.42
v_4 Skewness: 00.37 Kurtosis: -00.20
v_5 Skewness: -4.74 Kurtosis: 022.93
v_6 Skewness: 00.37 Kurtosis: -01.74
v_7 Skewness: 05.13 Kurtosis: 025.85
v_8 Skewness: 00.20 Kurtosis: -00.64
v_9 Skewness: 00.42 Kurtosis: -00.32
v_10 Skewness: 00.03 Kurtosis: -00.58
v_11 Skewness: 03.03 Kurtosis: 012.57
v_12 Skewness: 00.37 Kurtosis: 000.27
v_13 Skewness: 00.27 Kurtosis: -00.44
v_14 Skewness: -1.19 Kurtosis: 002.39
price Skewness: 03.35 Kurtosis: 019.002.5.3 每个数字特征得分布可视化
## 3) 每个数字特征得分布可视化
f = pd.melt(Train_data, value_vars=numeric_features)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False)
g = g.map(sns.distplot, "value")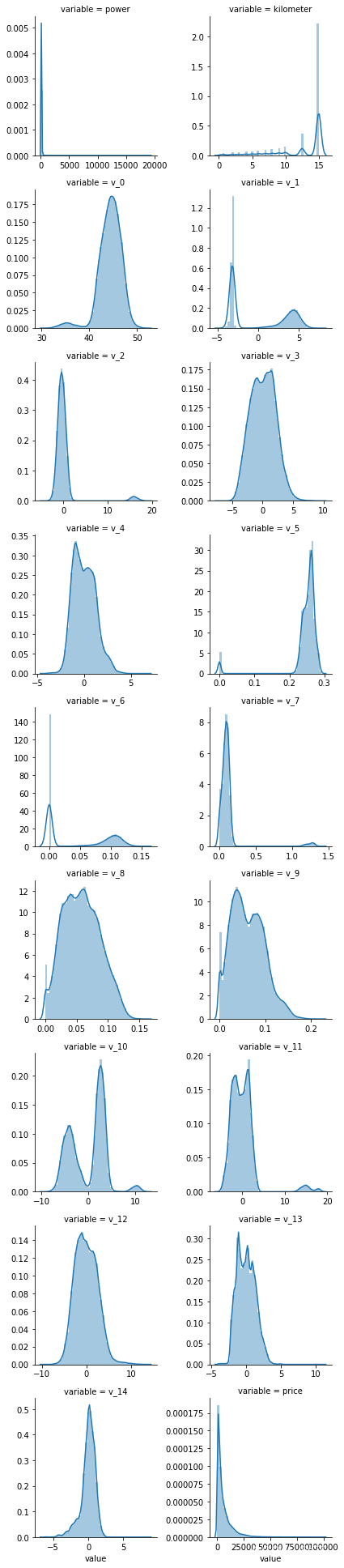
2.5.4 数字特征相互之间的关系可视化
## 4) 数字特征相互之间的关系可视化
sns.set()
columns = ['price', 'v_12', 'v_8' , 'v_0', 'power', 'v_5', 'v_2', 'v_6', 'v_1', 'v_14']
sns.pairplot(Train_data[columns],size = 2 ,kind ='scatter',diag_kind='kde')
plt.show()
2.5.5 多变量互相回归关系可视化
## 5) 多变量互相回归关系可视化
fig, ((ax1, ax2), (ax3, ax4), (ax5, ax6), (ax7, ax8), (ax9, ax10)) = plt.subplots(nrows=5, ncols=2, figsize=(24, 20))
# ['v_12', 'v_8' , 'v_0', 'power', 'v_5', 'v_2', 'v_6', 'v_1', 'v_14']
v_12_scatter_plot = pd.concat([Y_train,Train_data['v_12']],axis = 1)
sns.regplot(x='v_12',y = 'price', data = v_12_scatter_plot,scatter= True, fit_reg=True, ax=ax1)
v_8_scatter_plot = pd.concat([Y_train,Train_data['v_8']],axis = 1)
sns.regplot(x='v_8',y = 'price',data = v_8_scatter_plot,scatter= True, fit_reg=True, ax=ax2)
v_0_scatter_plot = pd.concat([Y_train,Train_data['v_0']],axis = 1)
sns.regplot(x='v_0',y = 'price',data = v_0_scatter_plot,scatter= True, fit_reg=True, ax=ax3)
power_scatter_plot = pd.concat([Y_train,Train_data['power']],axis = 1)
sns.regplot(x='power',y = 'price',data = power_scatter_plot,scatter= True, fit_reg=True, ax=ax4)
v_5_scatter_plot = pd.concat([Y_train,Train_data['v_5']],axis = 1)
sns.regplot(x='v_5',y = 'price',data = v_5_scatter_plot,scatter= True, fit_reg=True, ax=ax5)
v_2_scatter_plot = pd.concat([Y_train,Train_data['v_2']],axis = 1)
sns.regplot(x='v_2',y = 'price',data = v_2_scatter_plot,scatter= True, fit_reg=True, ax=ax6)
v_6_scatter_plot = pd.concat([Y_train,Train_data['v_6']],axis = 1)
sns.regplot(x='v_6',y = 'price',data = v_6_scatter_plot,scatter= True, fit_reg=True, ax=ax7)
v_1_scatter_plot = pd.concat([Y_train,Train_data['v_1']],axis = 1)
sns.regplot(x='v_1',y = 'price',data = v_1_scatter_plot,scatter= True, fit_reg=True, ax=ax8)
v_14_scatter_plot = pd.concat([Y_train,Train_data['v_14']],axis = 1)
sns.regplot(x='v_14',y = 'price',data = v_14_scatter_plot,scatter= True, fit_reg=True, ax=ax9)
v_13_scatter_plot = pd.concat([Y_train,Train_data['v_13']],axis = 1)
sns.regplot(x='v_13',y = 'price',data = v_13_scatter_plot,scatter= True, fit_reg=True, ax=ax10)
2.6 类别特征分析【类别特征箱形图可视化】
## 1) unique分布
for fea in categorical_features:
print(Train_data[fea].nunique())
categorical_features
## 2) 类别特征箱形图可视化
# 因为 name和 regionCode的类别太稀疏了,这里我们把不稀疏的几类画一下
categorical_features = ['model',
'brand',
'bodyType',
'fuelType',
'gearbox',
'notRepairedDamage']
for c in categorical_features:
Train_data[c] = Train_data[c].astype('category')
if Train_data[c].isnull().any():
Train_data[c] = Train_data[c].cat.add_categories(['MISSING'])
Train_data[c] = Train_data[c].fillna('MISSING')
def boxplot(x, y, **kwargs):
sns.boxplot(x=x, y=y)
x=plt.xticks(rotation=90)
f = pd.melt(Train_data, id_vars=['price'], value_vars=categorical_features)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False, size=5)
g = g.map(boxplot, "value", "price")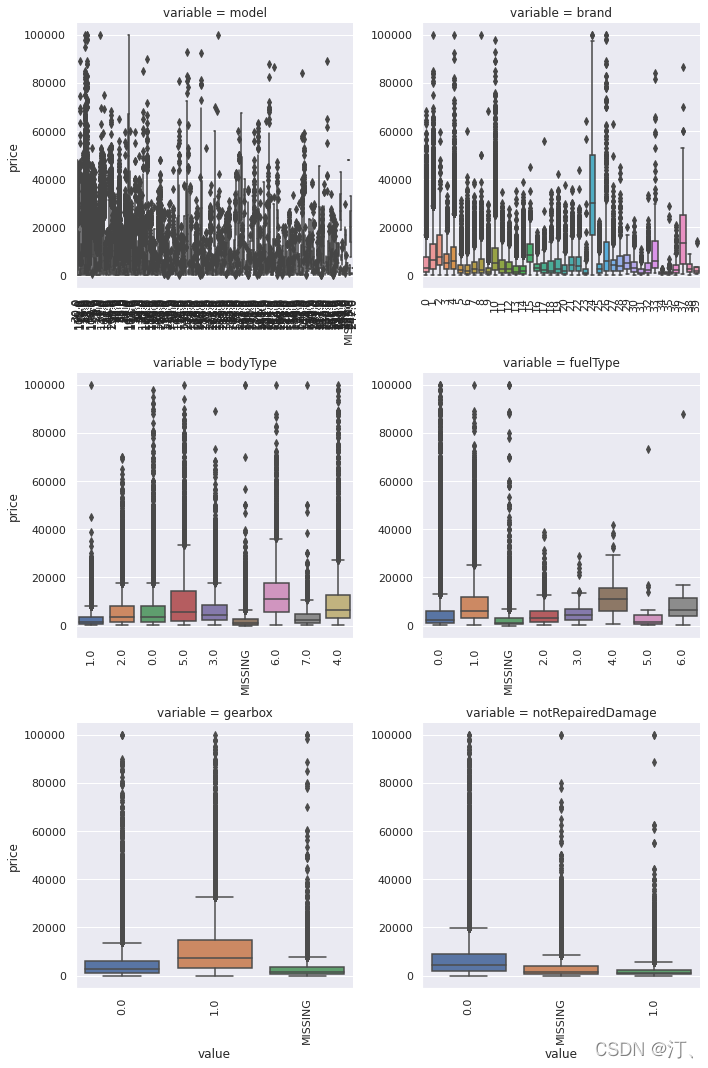
2.7类别特征的小提琴图可视化
## 3) 类别特征的小提琴图可视化
catg_list = categorical_features
target = 'price'
for catg in catg_list :
sns.violinplot(x=catg, y=target, data=Train_data)
plt.show()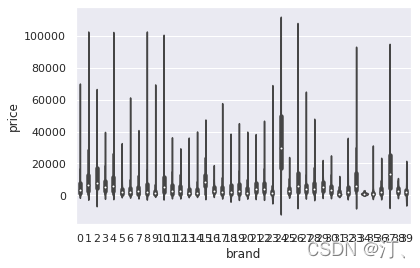
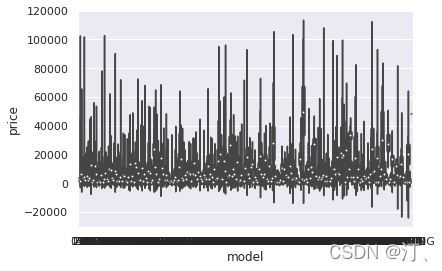
categorical_features = ['model',
'brand',
'bodyType',
'fuelType',
'gearbox',
'notRepairedDamage']2.8 类别特征的柱形图可视化
## 4) 类别特征的柱形图可视化
def bar_plot(x, y, **kwargs):
sns.barplot(x=x, y=y)
x=plt.xticks(rotation=90)
f = pd.melt(Train_data, id_vars=['price'], value_vars=categorical_features)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False, size=5)
g = g.map(bar_plot, "value", "price")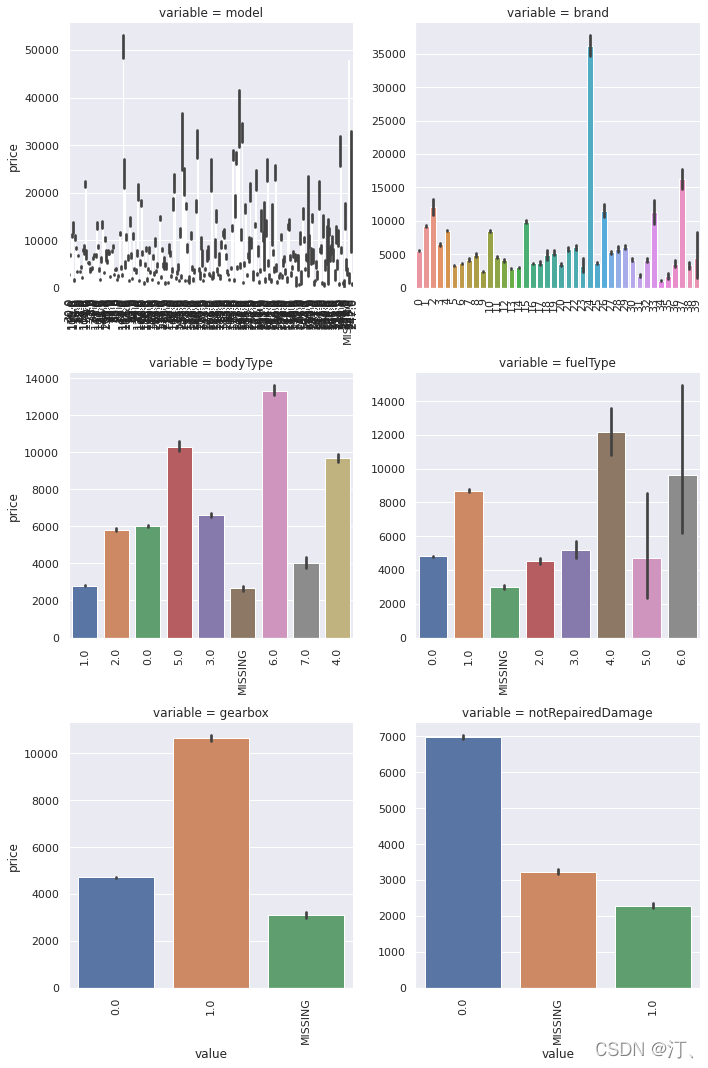
2.9 类别特征的每个类别频数可视化(count_plot)
## 5) 类别特征的每个类别频数可视化(count_plot)
def count_plot(x, **kwargs):
sns.countplot(x=x)
x=plt.xticks(rotation=90)
f = pd.melt(Train_data, value_vars=categorical_features)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False, size=5)
g = g.map(count_plot, "value")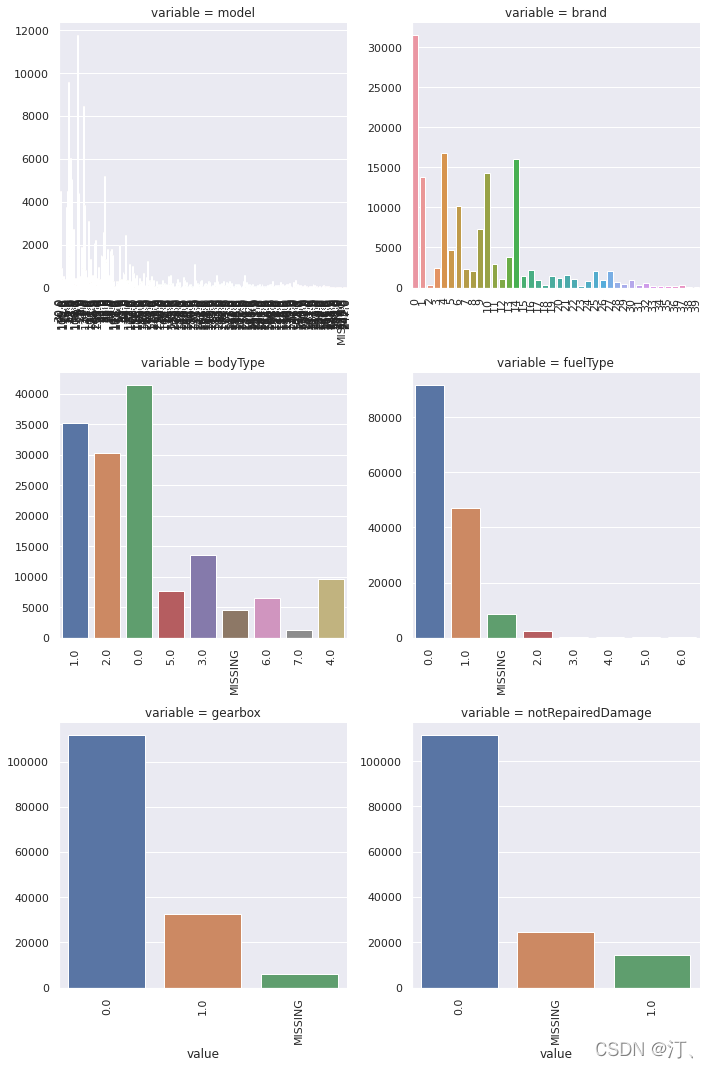
3.经验总结
所给出的EDA步骤为广为普遍的步骤,在实际的不管是工程还是比赛过程中,这只是最开始的一步,也是最基本的一步。
接下来一般要结合模型的效果以及特征工程等来分析数据的实际建模情况,根据自己的一些理解,查阅文献,对实际问题做出判断和深入的理解。
最后不断进行EDA与数据处理和挖掘,来到达更好的数据结构和分布以及较为强势相关的特征
数据探索在机器学习中我们一般称为EDA(Exploratory Data Analysis):
是指对已有的数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索,通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法。
数据探索有利于我们发现数据的一些特性,数据之间的关联性,对于后续的特征构建是很有帮助的。
对于数据的初步分析(直接查看数据,或.sum(), .mean(),.descirbe()等统计函数)可以从:样本数量,训练集数量,是否有时间特征,是否是时许问题,特征所表示的含义(非匿名特征),特征类型(字符类似,int,float,time),特征的缺失情况(注意缺失的在数据中的表现形式,有些是空的有些是”NAN”符号等),特征的均值方差情况。
分析记录某些特征值缺失占比30%以上样本的缺失处理,有助于后续的模型验证和调节,分析特征应该是填充(填充方式是什么,均值填充,0填充,众数填充等),还是舍去,还是先做样本分类用不同的特征模型去预测。
对于异常值做专门的分析,分析特征异常的label是否为异常值(或者偏离均值较远或者事特殊符号),异常值是否应该剔除,还是用正常值填充,是记录异常,还是机器本身异常等。
对于Label做专门的分析,分析标签的分布情况等。
进步分析可以通过对特征作图,特征和label联合做图(统计图,离散图),直观了解特征的分布情况,通过这一步也可以发现数据之中的一些异常值等,通过箱型图分析一些特征值的偏离情况,对于特征和特征联合作图,对于特征和label联合作图,分析其中的一些关联性
数据挖掘机器学习[二]---汽车交易价格预测详细版本{EDA-数据探索性分析}的更多相关文章
- 零基础入门数据挖掘——二手车交易价格预测:baseline
零基础入门数据挖掘 - 二手车交易价格预测 赛题理解 比赛要求参赛选手根据给定的数据集,建立模型,二手汽车的交易价格. 赛题以预测二手车的交易价格为任务,数据集报名后可见并可下载,该数据来自某交易平台 ...
- 二手车价格预测 | 构建AI模型并部署Web应用 ⛵
作者:韩信子@ShowMeAI 数据分析实战系列:https://www.showmeai.tech/tutorials/40 机器学习实战系列:https://www.showmeai.tech/t ...
- 【机器学习入门与实践】数据挖掘-二手车价格交易预测(含EDA探索、特征工程、特征优化、模型融合等)
[机器学习入门与实践]数据挖掘-二手车价格交易预测(含EDA探索.特征工程.特征优化.模型融合等) note:项目链接以及码源见文末 1.赛题简介 了解赛题 赛题概况 数据概况 预测指标 分析赛题 数 ...
- 机器学习实战二:波士顿房价预测 Boston Housing
波士顿房价预测 Boston housing 这是一个波士顿房价预测的一个实战,上一次的Titantic是生存预测,其实本质上是一个分类问题,就是根据数据分为1或为0,这次的波士顿房价预测更像是预测一 ...
- 人工智能大数据,公开的海量数据集下载,ImageNet数据集下载,数据挖掘机器学习数据集下载
人工智能大数据,公开的海量数据集下载,ImageNet数据集下载,数据挖掘机器学习数据集下载 ImageNet挑战赛中超越人类的计算机视觉系统微软亚洲研究院视觉计算组基于深度卷积神经网络(CNN)的计 ...
- ML.NET 示例:回归之价格预测
写在前面 准备近期将微软的machinelearning-samples翻译成中文,水平有限,如有错漏,请大家多多指正. 如果有朋友对此感兴趣,可以加入我:https://github.com/fei ...
- 机器学习二 逻辑回归作业、逻辑回归(Logistic Regression)
机器学习二 逻辑回归作业 作业在这,http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2016/Lecture/hw2.pdf 是区分spam的. 57 ...
- TensorFlow-Bitcoin-Robot:一个基于 TensorFlow LSTM 模型的 Bitcoin 价格预测机器人
简介 TensorFlow-Bitcoin-Robot:一个基于 TensorFlow LSTM 模型的 Bitcoin 价格预测机器人. 文章包括一下几个部分: 1.为什么要尝试做这个项目? 2.为 ...
- TensorFlow-Bitcoin-Robot:一个基于 TensorFlow LSTM 模型的 Bitcoin 价格预测机器人。
简介 TensorFlow-Bitcoin-Robot:一个基于 TensorFlow LSTM 模型的 Bitcoin 价格预测机器人. 文章包括一下几个部分: 1.为什么要尝试做这个项目? 2.为 ...
- weixin.com域名易主 传交易价格仅次360.com
据业内人士透露,weixin.com双拼域名今日易主,交易价格在几千万级别,有传闻其交易价格仅次于360.com. 从whois信息查看可知,weixin.com域名信息今日发生变更,目前域名的持有者 ...
随机推荐
- ZK--简介,部署
官网:https://zookeeper.apache.org/ 本文zk版本:3.7.0 一.简介 ZooKeeper 是一个高可用的分布式数据管理与系统协调软件,它可以为分布式应用提供状态同步.配 ...
- POJ2965 The Pilots Brothers' refrigerator (精妙方法秒杀DFS BFS)
这道题和算法进阶指南的一道题解法一样,必须另操作为奇数.见证明过程 证明:要使一个为'+'的符号变为'-',必须其相应的行和列的操作数为奇数;可以证明,如果'+'位置对应的行和列上每一个位置都进行一次 ...
- Codeforces Round #734 (Div. 3) A~D1 个人题解
比赛链接:Here 1551A. Polycarp and Coins (签到) 题意: 我们有任意个面额为 \(1\) 和 \(2\) 的硬币去支付 \(n\) 元账单, 现在请问怎么去分配数额使得 ...
- Educational Codeforces Round 104 (Rated for Div. 2) A-E 个人题解
比赛链接 1487A. Arena n 个 Hero,分别有 \(a_i\) 的初始等级.每次两个 Hero 战斗时:等级相同无影响,否则等级高的英雄等级+1.直到某个英雄等级到了 \(100^{50 ...
- C#通过泛型实现对子窗体的不同操作
private void button1_Click(object sender, EventArgs e) { FormOperate<object>();//调用FormOperate ...
- shell脚本(8)-流程控制if
一.单if语法 1.语法格式: if [ condition ] #condition值为 then commands fi 2.举例: [root@localhost test20210725]# ...
- java进阶(30)--Hashtable集合与Properties集合
一.Hashtable简介 1.HashMap与Hashtable区别 Hashtable的key与value均不能为空,而HashMap均可以 2.Hashtable方法带有Synchronized ...
- java进阶(24)--ArrayList集合、LinkList集合、Vector集合
一.基础 1.ArrayList集合底层是Object[]数组 2.默认容量10(优先:Add第一个元素,初始化未0,jdk13) 3.构造方法:无参(默认).有参 4.ArrayList集合扩容比例 ...
- BTC-协议
BTC-协议 一个去中心化的数字货币要解决两个问题 1.谁有权发行货币 比特币的发行是由挖矿决定的(coinbase transaction 唯一一个产生新币的途径)比特币通过挖矿来决定货币的发行权, ...
- 以太网链路连接 和 ISIS/OSPF等路由协议关系
转载请注明出处: 以太网链路连接和ISIS/OSPF协议之间存在关联和区别 关联: 以太网链路连接是指通过以太网物理媒介(如电缆)将网络设备进行连接,使它们可以交换数据. ISIS(Intermedi ...