hdfs的读写数据流
hdfs的读:
hdfs的读写数据流的更多相关文章
- HDFS 文件读写过程
HDFS 文件读写过程 HDFS 文件读取剖析 客户端通过调用FileSystem对象的open()来读取希望打开的文件.对于HDFS来说,这个对象是分布式文件系统的一个实例. Distributed ...
- hdfs api读写文写件个人练习
看下hdfs的读写原理,主要是打开FileSystem,获得InputStream or OutputStream: 那么主要用到的FileSystem类是一个实现了文件系统的抽象类,继承来自org. ...
- HDFS04 HDFS的读写流程
HDFS的读写流程(面试重点) 目录 HDFS的读写流程(面试重点) HDFS写数据流程 网络拓扑-节点距离计算 机架感知(副本存储节点的选择) HDFS的读数据流程 HDFS写数据流程 客服端把D: ...
- HDFS的读写流程——宏观与微观
HDFS的读写流程--宏观与微观 HDFS:分布式文件系统,负责存放数据 分布式文件系统:就是将我们的数据放到多台电脑上存储. 写数据:就是将客户端上的数据上传到HDFS 宏观过程 客户端向HDFS发 ...
- HDFS中的读写数据流
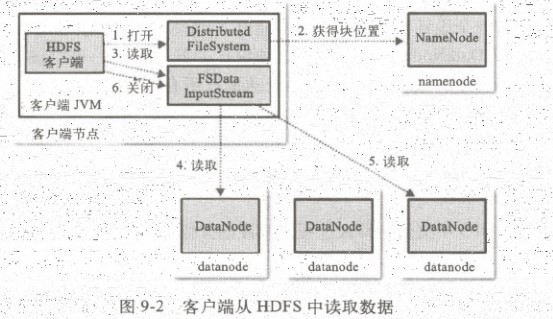
1.文件的读取 在客户端执行读取操作时,客户端和HDFS交互过程以及NameNode和各DataNode之间的数据流是怎样的?下面将围绕图1进行具体讲解. 图 1 客户端从HDFS中读取数据 1)客户 ...
- 【Hadoop】二、HDFS文件读写流程
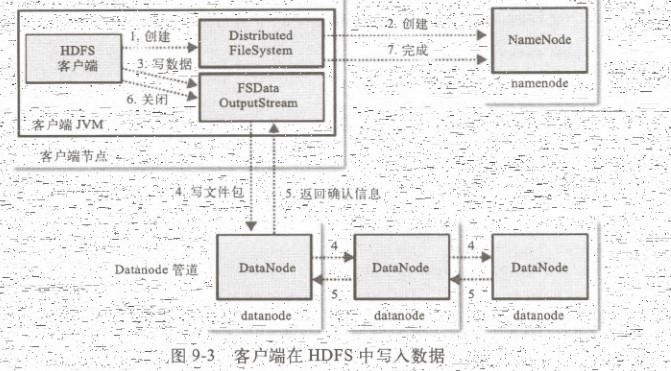
(二)HDFS数据流 作为一个文件系统,文件的读和写是最基本的需求,这一部分我们来了解客户端是如何与HDFS进行交互的,也就是客户端与HDFS,以及构成HDFS的两类节点(namenode和dat ...
- hadoop笔记-hdfs文件读写
概念 文件系统 磁盘进行读写的最小单位:数据块,文件系统构建于磁盘之上,文件系统的块大小是磁盘块的整数倍. 文件系统块一般为几千字节,磁盘块一般512字节. hdfs的block.pocket.chu ...
- 大数据系列2:Hdfs的读写操作
在前文大数据系列1:一文初识Hdfs中,我们对Hdfs有了简单的认识. 在本文中,我们将会简单的介绍一下Hdfs文件的读写流程,为后续追踪读写流程的源码做准备. Hdfs 架构 首先来个Hdfs的架构 ...
- HDFS文件读写过程
参考自<Hadoop权威指南> [http://www.cnblogs.com/swanspouse/p/5137308.html] HDFS读文件过程: 客户端通过调用FileSyste ...
随机推荐
- 浅谈php生成静态页面
一.引 言 在速度上,静态页面要比动态页面的比方php快很多,这是毫无疑问的,但是由于静态页面的灵活性较差,如果不借助数据库或其他的设备保存相关信息的话,整体的管理上比较繁琐,比方修改编辑.比方阅读权 ...
- canvas弹动
弹动,和缓动类似,不过是在终点前反复运动几次达到反弹的效果,具体的算法就是用目标点(target)和物体(mouse)的距离乘以系数累加至坐标上,这样就会有简单的弹动效果,但是一般的弹动效果都是慢慢变 ...
- 正确遍历ElasticSearch索引
1:ElasticSearch的查询过程 2:由ES查询模式引起的深度分页问题 3:如何正确遍历索引中的数据 ElasticSearch的查询过程 es的数据查询分两步: 第一步是的结果是获取满足查询 ...
- UML类图详解
下面是类图的实例: (注:飞翔接口那里应为空心三角形) UML中类图实例 接口:空心圆+直线(唐老鸭类实现了‘讲人话’):依赖:虚线+箭头(动物和空气的关系):关联:实线+箭头(企鹅需要知道气候才迁移 ...
- 真正高效的SQLSERVER分页查询(多种方案)
Sqlserver数据库分页查询一直是Sqlserver的短板,闲来无事,想出几种方法,假设有表ARTICLE,字段ID.YEAR...(其他省略),数据53210条(客户真实数据,量不大),分页查询 ...
- 【poj1694】 An Old Stone Game
http://poj.org/problem?id=1694 (题目链接) 题意 一棵树,现在往上面放石子.对于一个节点x,只有当它的直接儿子都放满石子时,才能将它直接儿子中的一个石子放置x上,并回收 ...
- ng-show与ng-if区别
<p>ng-show and ng-if : </p> <div ng-show="isShow">ng-show是否显示</div> ...
- sqlserver text/ntext 字段读取
sqlserver ntext 字段在读取时返回值 net.sourceforge.jtds.jdbc.ClobImpl@555bc78f 需要在连接数据库的URL后边加上";useLOBs ...
- ubuntu sudo update与upgrade的作用及区别
ubuntu sudo update与upgrade的作用及区别 入门linux的同志,刚开始最迫切想知道的,大概一个是中文输入法,另一个就是怎么安装软件.本文主要讲一下LINUX安装软件方面的特点. ...
- UITableView的添加、删除、移动操作
#pragma mark -----表视图的移动操作----- //移动的第一步也是需要将表视图的编辑状态打开 //2.指定哪些行可以进行移动 - (BOOL)tableView:(UITableVi ...