scrapy框架中Spiders用法
scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据
总的来说spider就是定义爬取的动作以及分析某个网页
工作流程分析
- 以初始的URL初始化Request,并设置回调函数,当该request下载完毕并返回时,将生成response,并作为参数传给回调函数. spider中初始的requesst是通过start_requests()来获取的。start_requests()获取 start_urls中的URL,并以parse以回调函数生成Request
- 在回调函数内分析返回的网页内容,可以返回Item对象,或者Dict,或者Request,以及是一个包含三者的可迭代的容器,返回的Request对象之后会经过Scrapy处理,下载相应的内容,并调用设置的callback函数
- 在回调函数内,可以通过lxml,bs4,xpath,css等方法获取我们想要的内容生成item
- 最后将item传递给Pipeline处理
我们以通过简单的分析源码来理解
我通常在写spiders下写爬虫的时候,我们并没有写start_requests来处理start_urls中的url,这是因为我们在继承的scrapy.Spider中已经写过了,我们可以点开scrapy.Spider查看分析
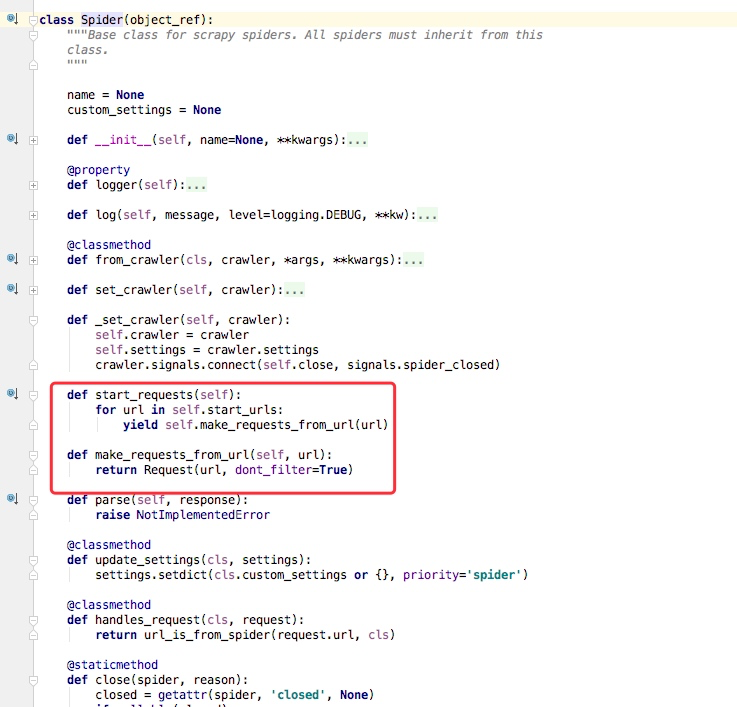
通过上述代码我们可以看到在父类里这里实现了start_requests方法,通过make_requests_from_url做了Request请求
如下图所示的一个例子,parse回调函数中的response就是父类列start_requests方法调用make_requests_from_url返回的结果,并且在parse回调函数中我们可以继续返回Request,如下属代码中yield Request()并设置回调函数。

spider内的一些常用属性
我们所有自己写的爬虫都是继承与spider.Spider这个类
name
定义爬虫名字,我们通过命令启动的时候用的就是这个名字,这个名字必须是唯一的
allowed_domains
包含了spider允许爬取的域名列表。当offsiteMiddleware启用时,域名不在列表中URL不会被访问
所以在爬虫文件中,每次生成Request请求时都会进行和这里的域名进行判断
start_urls
起始的url列表
这里会通过spider.Spider方法中会调用start_request循环请求这个列表中每个地址。
custom_settings
自定义配置,可以覆盖settings的配置,主要用于当我们对爬虫有特定需求设置的时候
设置的是以字典的方式设置:custom_settings = {}
from_crawler
这是一个类方法,我们定义这样一个类方法,可以通过crawler.settings.get()这种方式获取settings配置文件中的信息,同时这个也可以在pipeline中使用
start_requests()
这个方法必须返回一个可迭代对象,该对象包含了spider用于爬取的第一个Request请求
这个方法是在被继承的父类中spider.Spider中写的,默认是通过get请求,如果我们需要修改最开始的这个请求,可以重写这个方法,如我们想通过post请求
make_requests_from_url(url)
这个也是在父类中start_requests调用的,当然这个方法我们也可以重写
parse(response)
这个其实默认的回调函数
负责处理response并返回处理的数据以及跟进的url
该方法以及其他的Request回调函数必须返回一个包含Request或Item的可迭代对象
scrapy框架中Spiders用法的更多相关文章
- Python爬虫从入门到放弃(十五)之 Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
- Python之爬虫(十七) Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
- 5-----Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 1.以初始的URL初始化Request, ...
- scrapy框架中Download Middleware用法
scrapy框架中Download Middleware用法 Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给sp ...
- Scrapy框架中选择器的用法【转】
Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法 请给作者点赞 --> 原文链接 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpa ...
- scrapy框架中Item Pipeline用法
scrapy框架中item pipeline用法 当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的pyt ...
- scrapy框架中选择器的用法
scrapy框架中选择器的用法 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中 ...
- Scrapy框架中的CrawlSpider
小思考:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法二: ...
- Scrapy框架中的xpath选择
不同于我们普通爬虫获取xpath,scrapy获得xpath对象获取他的值语法 一.xpath对象获取值 xpath对象..extract() 二.Scrapy框架独有的xpath取值方式 利用hre ...
随机推荐
- C++中指针和指针变量
指针和指针变量的理解: #include<iostream> using namespace std; int main() { int n; int * m; m = &n; n ...
- PHP截取中英文混合字符
<?php //////////////////////////////////////////////////////////////////// // PHP截取中英文及标点符号混合的字符串 ...
- mycat的事务支持情况
中秋国庆一共12天,玩的有点嗨,完全没想工作的事情- -.回来赶紧补补.看了一下mycat关于事务的支持情况,做一下记录. 说mycat的事务支持之前,先说说XA协议,即分布式事务.指的是TM(事务管 ...
- uglifyjs2全局混淆
从git克隆uglifyjs2源码后,进入目录: npm link 编译并安装uglifyjs2成功,就可以直接调用uglifyjs命令了.但是在进行全局混淆时出现了问题,虽然指定了文件topvar. ...
- {{badmatch, {error, eexist}}
今天在编译cowboy工程在resolve release build时提示编译错误:{{badmatch, {error, eexist}} 后经调查可能是因为rebar的bug导致的,可是删除_b ...
- 在KitKat(Android 4.4.2) 推送网址给手机
弱者才会回避问题. 最近想把网址推送给手机实现后台下载,打算故技重施,用短信传送然后中断广播的方法实现隐蔽传送.试了半天发现怎么现在拦不住短信了.查了一下才发现原来Android4.4增加了一个安全机 ...
- Asterisk 通话过程中执行动作(即applicationmap )的使用方法和电话转会议的实现
asterisk在正常通话过程中执行拨号计划中动作是通过feature.conf中的[applicationmap ]下定义的,举例如下: nway-start => *0,callee,M ...
- hdu 最短路模板题 java
最短路 Problem Description 在每年的校赛里,所有进入决赛的同学都会获得一件很漂亮的t-shirt.但是每当我们的工作人员把上百件的衣服从商店运回到赛场的时候,却是非常累的!所以现在 ...
- linux学习 三 redhat
1: 查看redhat版本号. 2: 防火墙中加入8080 查看防火墙状态,root用户登录,执行命令systemctl status firewalld 开启防火墙:systemctl star ...
- Volley(一)
为什么使用Volley Android提供了两个HTTP库给开发者来进行实现一个HTTP请求,一个是AndroidHttpClient (从apache HttpClient拓展而来),另一个是Htt ...