推荐系统中的注意力机制——阿里深度兴趣网络(DIN)
参考:
https://zhuanlan.zhihu.com/p/51623339
https://arxiv.org/abs/1706.06978
注意力机制顾名思义,就是模型在预测的时候,对用户不同行为的注意力是不一样的,“相关”的行为历史看重一些,“不相关”的历史甚至可以忽略。那么这样的思想反应到模型中也是直观的。
如果按照之前的做法,我们会一碗水端平的考虑所有行为记录的影响,对应到模型中就是我们会用一个average pooling层把用户交互过的所有商品的embedding vector平均一下形成这个用户的user vector,机灵一点的工程师最多加一个time decay,让最近的行为产生的影响大一些,那就是在做average pooling的时候按时间调整一下权重。
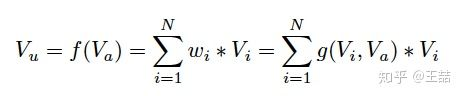
上式中, 是用户的embedding向量,
是候选广告商品的embedding向量,
是用户u的第i次行为的embedding向量,因为这里用户的行为就是浏览商品或店铺,所以行为的embedding的向量就是那次浏览的商品或店铺的embedding向量。
因为加入了注意力机制, 从过去
的加和变成了
的加权和,
的权重
就由
与
的关系决定,也就是上式中的
,不负责任的说,这个
的加入就是本文70%的价值所在。
那么 这个函数到底采用什么比较好呢?看完下面的架构图自然就清楚了。
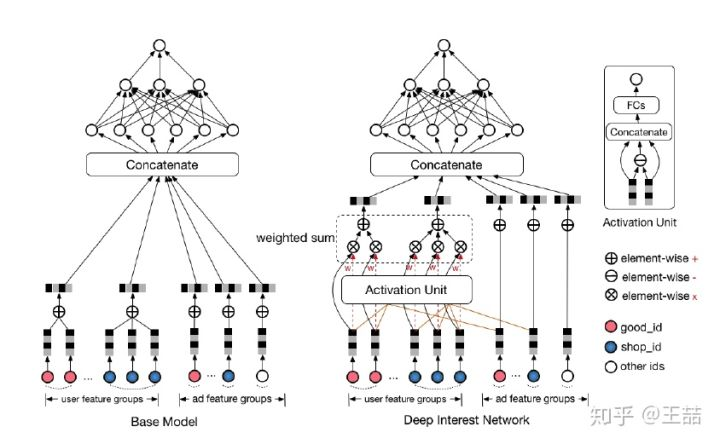
相比原来这个标准的深度推荐网络(Base model),DIN在生成用户embedding vector的时候加入了一个activation unit层,这一层产生了每个用户行为 的权重,下面我们仔细看一下这个权重是怎么生成的,也就是
是如何定义的。
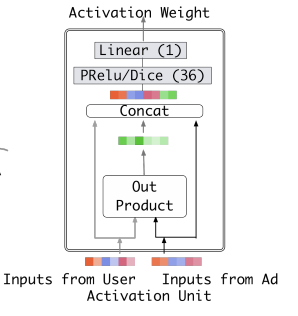
传统的Attention机制中,给定两个item embedding,比如u和v,通常是直接做点积uv或者uWv,其中W是一个|u|x|v|的权重矩阵,但这篇paper中阿里显然做了更进一步的改进,着重看上图右上角的activation unit,首先是把u和v以及u v的element wise差值向量合并起来作为输入,然后喂给全连接层,最后得出权重,这样的方法显然损失的信息更少。但如果你自己想方便的引入attention机制的话,不妨先从点积的方法做起尝试一下,因为这样连训练都不用训练。
再稍微留意一下这个架构图中的红线,你会发现每个ad会有 good_id, shop_id 两层属性,shop_id只跟用户历史中的shop_id序列发生作用,good_id只跟用户的good_id序列发生作用,这样做的原因也是显而易见的。
论文里面,activation unit结构:
activation units are applied on the user behavior features, which performs as a weighted sum pooling to adaptively calculate user representation $v_U$ given a candidate ad A:
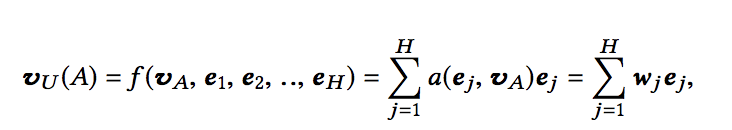
where ${e_1, e_2, ..., e_H }$ is the list of embedding vectors of behaviors of user $U$ with length of H, $v_A$ is the embedding vector of ad A.
如果说上面的部分是文70%的价值所在,那么余下30%应该还有这么几点:
- 用GAUC这个离线metric替代AUC
- 用Dice方法替代经典的PReLU激活函数
- 介绍一种Adaptive的正则化方法
- 介绍阿里的X-Deep Learning深度学习平台
PReLU激活函数:
 其中,$p(s) = I(s > 0)$
其中,$p(s) = I(s > 0)$
Dice方法:
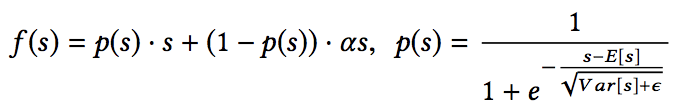
Dice can be viewed as a generalization of PReLu. The key idea of Dice is to adaptively adjust the rectified point according to distribution of input data, whose value is set to be the mean of input. Besides, Dice controls smoothly to switch between the two channels. When $E(s) = 0 $ and $Var[s] = 0 $, Dice degenerates into PReLU.
GAUC:
因为auc反映的是整体样本间的一个排序能力,而在计算广告领域,我们实际要衡量的是不同用户对不同广告之间的排序能力, 实际更关注的是同一个用户对不同广告间的排序能力。group auc实际是计算每个用户的auc,然后加权平均,最后得到group auc,这样就能减少不同用户间的排序结果不太好比较这一影响
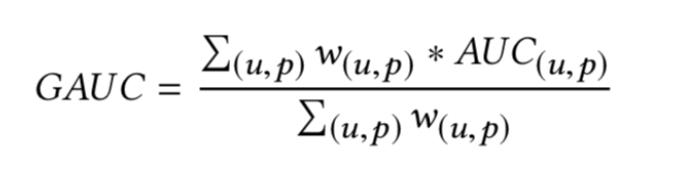 实际处理时权重一般可以设为每个用户view的次数,或click的次数,而且一般计算时,会过滤掉单个用户全是正样本或负样本的情况。
实际处理时权重一般可以设为每个用户view的次数,或click的次数,而且一般计算时,会过滤掉单个用户全是正样本或负样本的情况。
实现代码: https://github.com/qiaoguan/deep-ctr-prediction/blob/master/DeepCross/metric.py
阅读论文:
基线模型: embedding & MLP
$Embedding Layer: $
For the $i-th$ feature group of $t_i$ ($t_i$ 是 $K_i$ 维向量,可能有一个或多个项是1), let $W_i = [w^i_1 , ...,w^i_j , ...,w^i_{K_i} ] ∈ R^{D×K_i} $ represent the $i-th$ embedding dictionary, where $w^i_j ∈ R^D $ is an embedding vector with dimensionality of D. Embedding operation follows the table lookup mechanism。
embedding机制:
1、If $t_i$ is one-hot vector with $j-th$ element $t_i[j] = 1 $, the embedded representation of $t_i$ is a single embedding vector $e_i = w^i_j $.
2、If $t_i$ is multi-hot vector with $t_i[j] = 1 $ for $j ∈ {i_1, i_2, ...,i_k }$, the embedded representation of $t_i$ is a list of embedding vectors: ${e_{i_1} , e_{i_2} , ...e_{i_k} } = {w^i_{i1} ,w^i_{i2} , ...w^i_{ik} }$.
$Pooling layer and Concat layer: $
The number of non-zero values for multi-hot behavioral feature vector $t_i$ varies across instances, causing the lengths of the corresponding list of embedding vectors to be variable. As fully connected networks can only handle fixed-length inputs, it is a common practice to transform the list of embedding vectors via a pooling layer to get a fixed-length vector:
$e_i = pooling(e_{i_1} , e_{i_2}, ...e{i_k} )$
Both embedding and pooling layers operate in a group-wise manner, mapping the original sparse features into multiple fixedlength representation vectors. Then all the vectors are concatenated together to obtain the overall representation vector for the instance
$MLP:$
Given the concatenated dense representation vector, fully connected layers are used to learn the combination of features automatically. Recently developed methods focus on designing structures of MLP for better information extraction.
推荐系统中的注意力机制——阿里深度兴趣网络(DIN)的更多相关文章
- 推荐系统---深度兴趣网络DIN&DIEN
深度学习在推荐系统.CTR预估领域已经有了广泛应用,如wide&deep.deepFM模型等,今天介绍一下由阿里算法团队提出的深度兴趣网络DIN和DIEN两种模型 paper DIN:http ...
- [论文阅读]阿里DIN深度兴趣网络之总体解读
[论文阅读]阿里DIN深度兴趣网络之总体解读 目录 [论文阅读]阿里DIN深度兴趣网络之总体解读 0x00 摘要 0x01 论文概要 1.1 概括 1.2 文章信息 1.3 核心观点 1.4 名词解释 ...
- [阿里DIN] 深度兴趣网络源码分析 之 整体代码结构
[阿里DIN] 深度兴趣网络源码分析 之 整体代码结构 目录 [阿里DIN] 深度兴趣网络源码分析 之 整体代码结构 0x00 摘要 0x01 文件简介 0x02 总体架构 0x03 总体代码 0x0 ...
- 阿里深度兴趣网络模型paper学习
论文地址:Deep Interest Network for Click-Through Rate ... 这篇论文来自阿里妈妈的精准定向检索及基础算法团队.文章提出的Deep Interest Ne ...
- [阿里DIN] 深度兴趣网络源码分析 之 如何建模用户序列
[阿里DIN] 深度兴趣网络源码分析 之 如何建模用户序列 目录 [阿里DIN] 深度兴趣网络源码分析 之 如何建模用户序列 0x00 摘要 0x01 DIN 需要什么数据 0x02 如何产生数据 2 ...
- 深度兴趣网络DIN-SIEN-DSIN
看看阿里如何在淘宝做推荐,实现"一人千物千面"的用户多样化兴趣推荐,首先总结下DIN.DIEN.DSIN: 传统深度学习在推荐就是稀疏到embedding编码,变成稠密向量,喂给N ...
- [好文mark] 深度学习中的注意力机制
https://cloud.tencent.com/developer/article/1143127
- [论文阅读]阿里DIEN深度兴趣进化网络之总体解读
[论文阅读]阿里DIEN深度兴趣进化网络之总体解读 目录 [论文阅读]阿里DIEN深度兴趣进化网络之总体解读 0x00 摘要 0x01论文概要 1.1 文章信息 1.2 基本观点 1.2.1 DIN的 ...
- [阿里DIEN] 深度兴趣进化网络源码分析 之 Keras版本
[阿里DIEN] 深度兴趣进化网络源码分析 之 Keras版本 目录 [阿里DIEN] 深度兴趣进化网络源码分析 之 Keras版本 0x00 摘要 0x01 背景 1.1 代码进化 1.2 Deep ...
随机推荐
- python - 接口自动化测试 - HttpRequest - 接口测试类封装
# -*- coding:utf-8 -*- ''' @project: ApiAutoTest @author: Jimmy @file: http_request.py @ide: PyCharm ...
- 聊聊、Spring 数据源
平时开发中我们每天都会跟数据库打交道,页面上显示的数字,图片,语音,等等都存在某个地方,而我们就是要从那个地方拿到我们想要的.现在存储数据的方式越来越多,多种多样,但用的最多的还是关系数据库.Spri ...
- 配置kubectl客户端通过token方式访问kube-apiserver
使用的变量 本文档用到的变量定义如下: $ export MASTER_IP=XX.XX.XX.XX # 替换为 kubernetes master VIP $ export KUBE_APISERV ...
- Windows 7中安装SQL2005提示IIS未安装 解决办法 .(转载)
在Windows 7系统中安装SQL Server 2005时,可能会收到一个警告:提示IIS未安装或者未启用.在通过“控制面板”的“打开或关闭Windows功能”按默认设置安装IIS后,发现仍有这个 ...
- 实战小项目之IMX6 VPU使用
项目简介 基于官方的demo进行修改,限于能力问题,并没有将功能代码完全从官方的demo中分离出来,还是基于原来的框架进行修改,做了一些简单的封装,我做的工作如下: 使用自己的采集程序 定义6中工作模 ...
- [oldboy-django][5python基础][高级特性]generator生成器
# 生成器基础 - 定义 在循环的时候不断推算下一个元素的值,而不是一下子创建空间存储所有元素,这样节省空间. 并且在适当的条件结束循环,这种一边循环一边计算的机制,称为generator生成器 - ...
- php 不重新编译增加openssl扩展
安装openssl和开发包 yum install openssl openssl-devel 跳转到PHP源码下的openssl cd /usr/local/src/php-5.5.27/ext/o ...
- [ZZOJ#31]类欧几里得
[ZZOJ#31]类欧几里得 试题描述 这是一道模板题. 给出 \(a, b, c, n\),请你求出 \(\sum_{x=0}^n{\lfloor \frac{a \cdot x + b}{c} \ ...
- 优化Angularjs的$watch方法
Angularjs的$watch相信大家都知道,而且也经常使用,甚至,你还在为它的某些行为感到恼火.比如,一进入页面,它就会调用一次,我明明希望它在我初始化之后,值再次变动才调用.这种行为给我们带来许 ...
- shell 条件表达式
1.条件测试的常用语法如下 1.test 测试表达式 2.[ 测试表达式 ] #两边需要有空格 3.[[ 测试表达式 ]] 4.(( 测试表达式 )) 说明: 第一种和第二种是等价的,第三种是扩展的t ...