爬虫之scrapy工作流程
Scrapy是什么?
scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量代码,就能够快速的抓取到数据内容。Scrapy 使用了 Twisted['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
异步与非阻塞的区别:异步:调用在发出之后,这个调用就直接返回,不管有无结果。
非阻塞:关注的是程序在等待调用结果(消息,返回值)时的状态,指在不能立刻得到结果之前,该调用不会阻塞当前线程。

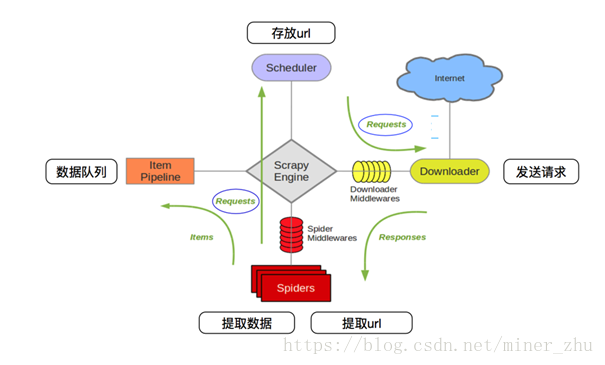
scrapy详细工作流程:
1.首先Spiders(爬虫)将需要发送请求的url(requests)经ScrapyEngine(引擎)交给Scheduler(调度器)。
2.Scheduler(排序,入队)处理后,经ScrapyEngine,DownloaderMiddlewares(可选,主要有User_Agent, Proxy代理)交给Downloader。
3.Downloader向互联网发送请求,并接收下载响应(response)。将响应(response)经ScrapyEngine,SpiderMiddlewares(可选)交给Spiders。
4.Spiders处理response,提取数据并将数据经ScrapyEngine交给ItemPipeline保存(可以是本地,可以是数据库)。
5.提取url重新经ScrapyEngine交给Scheduler进行下一个循环。直到无Url请求程序停止结束。
Scrapy主要包括了以下组件:
- 引擎(Scrapy): 用来处理整个系统的数据流处理, 触发事务(框架核心)
- 调度器(Scheduler): 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader): 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders): 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline): 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares): 位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 爬虫中间件(Spider Middlewares): 介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件(Scheduler Middewares): 介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
爬虫之scrapy工作流程的更多相关文章
- scrapy 工作流程
Scrapy的整个数据处理流程由Scrapy引擎进行控制,其主要的运行方式为: 引擎打开一个域名,蜘蛛处理这个域名,然后获取第一个待爬取的URL. 引擎从蜘蛛那获取第一个需要爬取的URL,然后作为请求 ...
- scrapy工作流程
整个scrapy流程,我们可以用去超市取货的过程来比喻一下 两个采购员小王和小李开着采购车,来到一个大型商场采购公司月饼.到了商场之后,小李(spider)来到商场前台,找到服务台小花(引擎)并对她说 ...
- Scrapy项目结构分析和工作流程
新建的空Scrapy项目: spiders目录: 负责存放继承自scrapy的爬虫类.里面主要是用于分析response并提取返回的item或者是下一个URL信息,每个Spider负责处理特定的网站或 ...
- Linux企业级项目实践之网络爬虫(2)——网络爬虫的结构与工作流程
网络爬虫是捜索引擎抓取系统的重要组成部分.爬虫的主要目的是将互联网上的网页下载到本地形成一个或联网内容的镜像备份. 一个通用的网络爬虫的框架如图所示:
- Python 爬虫之 Scrapy 分布式原理以及部署
Scrapy分布式原理 关于Scrapy工作流程 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享 ...
- scrapy核心组件工作流程和post请求
一 . 五大核心组件的工作流程 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返 ...
- Scrapy中的核心工作流程以及POST请求
五大核心组件工作流程 post请求发送 递归爬取 五大核心组件工作流程 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, ...
- 一篇文章教会你理解Scrapy网络爬虫框架的工作原理和数据采集过程
今天小编给大家详细的讲解一下Scrapy爬虫框架,希望对大家的学习有帮助. 1.Scrapy爬虫框架 Scrapy是一个使用Python编程语言编写的爬虫框架,任何人都可以根据自己的需求进行修改,并且 ...
- Scrapy五大核心组件工作流程
一.Scrapy五大核心组件工作流程 1.核心组件 # 引擎(Scrapy) 对整个系统的数据流进行处理, 触发事务(框架核心). # 调度器(Scheduler) 用来接受引擎发过来的请求. 由过滤 ...
随机推荐
- NET Core项目部署
NET Core项目部署到linux(Centos7) 阅读目录 1.开篇说明 2.Jexus简单说明 3.Visual Studio 2015本地发布并且测试 4.配置Jexus并且部署.NET C ...
- Hadoop实战项目:小文件合并
项目背景 在实际项目中,输入数据往往是由许多小文件组成,这里的小文件是指小于HDFS系统Block大小的文件(默认128M),早期的版本所定义的小文件是64M,这里的hadoop-2.2.0所定义的小 ...
- Code First 2
在codefirst一中也说了Mapping是实体与数据库的纽带,model通过Mapping映射到数据库,我们可以从数据库的角度来分析?首先是映射到数据库,这个是必须的.数据库里面一般包括表.列.约 ...
- 选择控件js插件和使用方法
记录一下 选择控件js插件 /* * 滚动控件,包含地址选择.时间选择.自定义单选 */ //js_inputbox input 输入框 //js_pickviewselect 下拉单项选择 //js ...
- Eclipse 主题(Theme)配置
< 程序员大牛必备的装逼神器 > 一个牛逼的程序员,除了有牛逼的技术,还要有高逼格的风格,说白了,就和人一样,单是内在美还不行,必须外表也要美,就好比,一个乞丐,他内在美,但是全身臭气熏天 ...
- SpringMVC注解方式与文件上传
目录: springmvc的注解方式 文件上传(上传图片,并显示) 一.注解 在类前面加上@Controller 表示该类是一个控制器在方法handleRequest 前面加上 @RequestMap ...
- Android获取res目录下图片的uri
Uri.parse("android.resource://" + getApplicationContext().getPackageName() + "/" ...
- LINQ新添知识
linquser.ExecuteCommand("TRUNCATE TABLE Board"); linquser.ExecuteCommand("DELET ...
- Core Data stack
https://developer.apple.com/library/content/documentation/DataManagement/Devpedia-CoreData/coreDataS ...
- [学习笔记] C++ 历年试题解析(一)--判断题
少说话.. 程序题链接:https://www.cnblogs.com/aoru45/p/9898691.html 14级试题---选择题 1. 引用在声明时必须对其初始化,以绑定某个已经存在的变量( ...